1 复杂度来源——高性能
对性能孜孜不倦的追求是整个人类技术不断发展的根本驱动力。例如计算机,从电子管计算机到晶体管计算机再到集成电路计算机,运算性能从每秒几次提升到每秒几亿次。但伴随性能越来越高,相应的方法和系统复杂度也是越来越高。现代的计算机CPU集成了几亿颗晶体管,逻辑复杂度和制造复杂度相比最初的晶体管计算机,根本不可同日而语。
软件系统也存在同样的现象。最近几十年软件系统性能飞速发展,从最初的计算机只能进行简单的科学计算,到现在Google能够支撑每秒几万次的搜索。与此同时,软件系统规模也从单台计算机扩展到上万台计算机;从最初的单用户单工的字符界面Dos操作系统,到现在的多用户多工的Windows 10图形操作系统。
当然,技术发展带来了性能上的提升,不一定带来复杂度的提升。例如,硬件存储从纸带—>磁带—>磁盘—>SSD,并没有显著带来系统复杂度的增加。因为新技术会逐步淘汰旧技术,这种情况下我们直接用新技术即可,不用担心系统复杂度会随之提升。只有哪些并不是用来取代旧技术,而且开辟了一个全新领域的技术,才会给软件系统带来复杂度,因为软件系统在设计的时候就需要在这些技术之间进行判断选择或者组合。就像汽车的发明无法取代火车,飞机的出现也并不能完全取代火车,所以我们在出行的时候,需要考虑选择汽车、火车还是飞机,这个选择的过程就比较复杂了,要考虑价格、时间、速度、舒适度等各种因素。
软件系统中高性能带来的复杂度主要体现在两方面,一方面是单台计算机内部为了高性能带来的复杂度;另一方面是多台计算机集群为了高性能带来的复杂度。
1.1 单机复杂度
计算机内部复杂度最关键的地方就是操作系统。计算机性能的发展本质上是悠硬件发展驱动的,尤其是CPU的性能发展。著名的“摩尔定律”表明了CPU的处理能力每隔18个月就能翻一倍;而将硬件性能充分发挥出来的关键就是操作系统,所以操作系统本身其实也是跟随硬件的发展而发展的,操作系统是软件系统的运行环境,操作系统的复杂度直接决定了软件系统的复杂度。
操作系统和性能相关的就是进程和线程。最早的计算机没有操作系统,只有输入、计算和输出功能。这样的处理性能效率很低。
为解决手工操作带来的低效,批处理应运而生,批处理简单来说就是先把要执行的指令预先写下来,形成一个指令清单,然后交给计算机执行,执行过程中无须等待人工手工操作,这样性能就有了很大的提升。
虽然批处理能大大提升处理性能,但有一个很明显的缺点:计算机一次只能执行一个任务,如果某个任务需要从I/O设备(例如磁带)读取大量的数据,在I/O操作的过程中,CPU其实是空闲的,浪费了部分资源。
为进一步提升性能,人们发明了“进程”,用进程来对应一个任务,每个任务都有自己的独立内存空间,进程间互不相关,由操作系统来进行调度。此时的CPU还没有多核和多线程的概念,为了达到多进程并行的目的,采取了分时的方式。同时,进程间通信的各种方式被设计出来,包括管道、消息队列、信号量、共享存储等。多进程让多任务能够并行处理,但本身缺点:单个进程内部只能串行处理,而实际上很多进程内部的子任务并不要求是严格按照时间顺序来执行的,也需要并行处理。
为解决进程的缺点,人们发明了线程,线程是进程内部的子任务,但这些子任务都共享同一份进程数据。为保证数据的正确性,又发明了互斥锁机制。有了多线程后,操作系统调度的最小单位就变成了线程,而进程变成了操作系统分配资源的最小单位。多进程多线程虽让多任务并行处理的性能大大提升,但本质还是分时系统,并不能做到真正意义上的多任务并行。实现真正意义上的多任务并行:目前这样的解决方案有 3 种:SMP(Symmetric Multi-Processor,对称多处理器结构)、NUMA(Non-Uniform Memory Access,非一致存储访问结构)、MPP(Massive Parallel Processing,海量并行处理结构)。目前主流方案是SMP方案。
操作系统发展到现在,如果我们要完成一个高性能的软件系统,需要考虑如多进程、多线程、进程间通信、多线程并发等技术点,而且这些技术并不是最新的就是最好的,也不是非此即彼的选择。在做架构设计的时候,需要花费很大的精力来结合业务进行分析、判断、选择、组合,这个过程同样很复杂。
1.2 集群复杂度
虽然,计算机操作系统和硬件的发展已经很快了,但是在进入互联网时代后,业务的发展速度远远更超前了。例如:
2016 年“双 11”支付宝每秒峰值达 12 万笔支付。
2017 年春节微信红包收发红包每秒达到 76 万个
单机的性能无法支撑业务需求的增长,必须采用机器集群的方式来达到高性能。但是,通过大量的机器来提升性能,并不仅仅是增加机器这么简单,下面是针对几种方式的加单分析:
1.2.1 任务分配:
任务分配的意思是指,每台机器都可以处理完整的业务任务,不同的任务分配到不同的机器上执行。
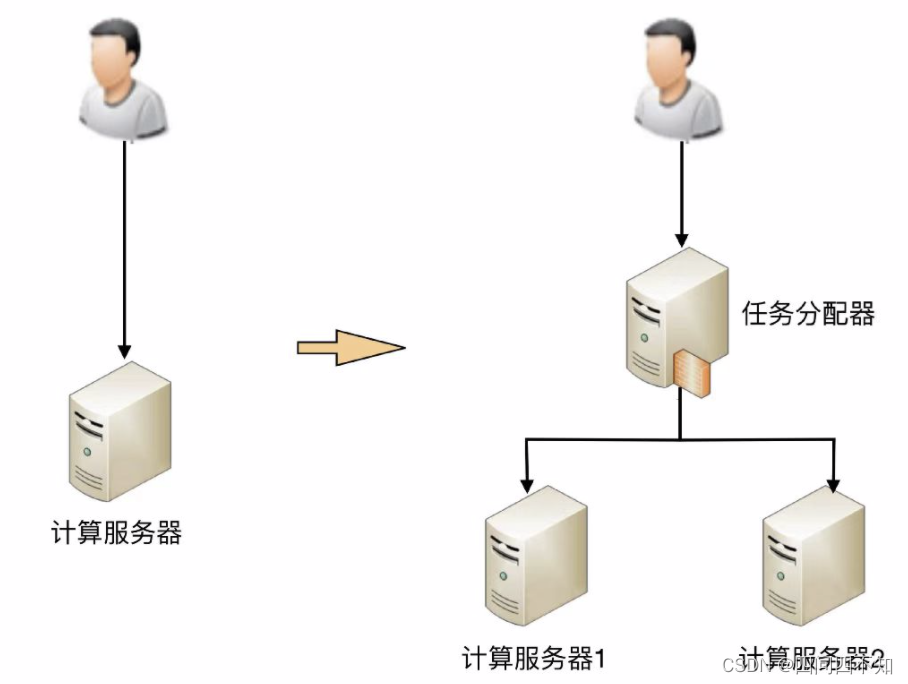
例如:从最简单的一台服务器变两台服务器:
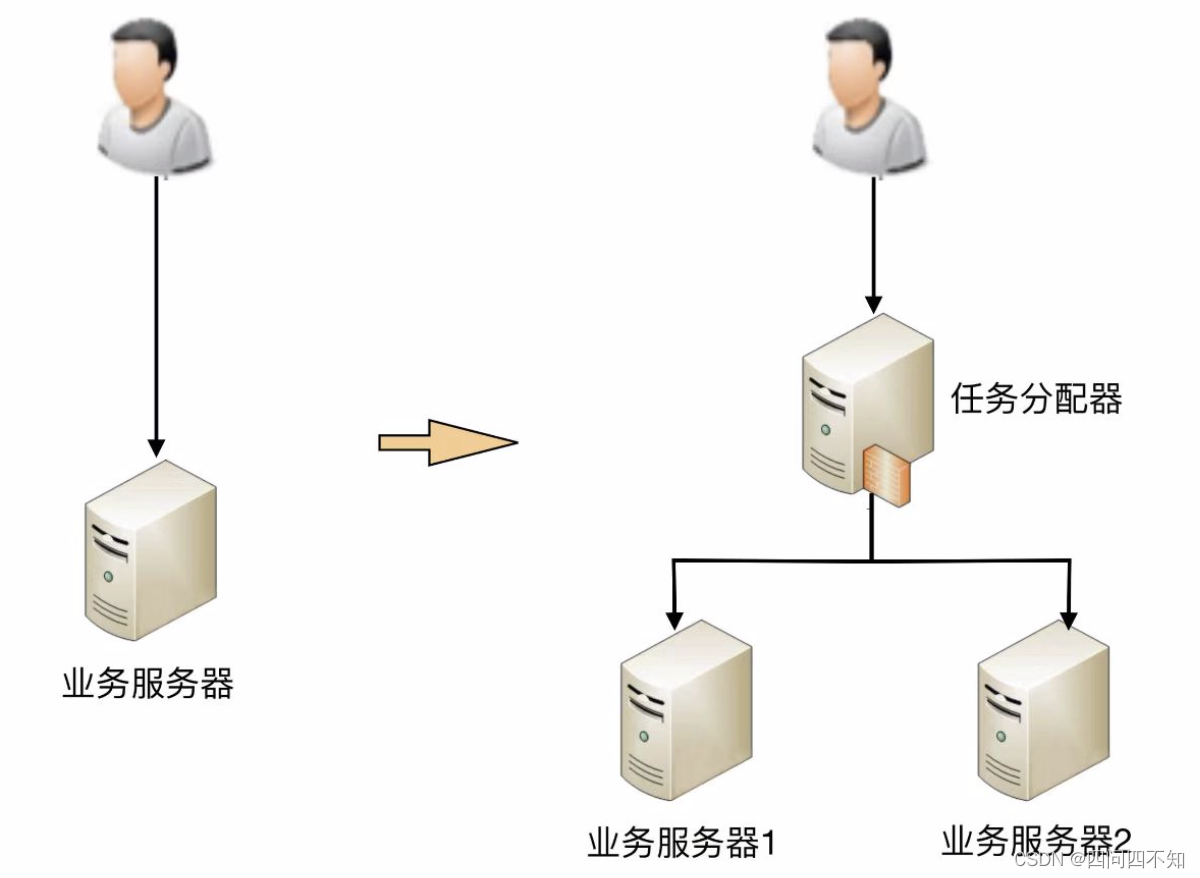
此时架构上明显要复杂多了,主要体现在:
需要增加一个任务分配器,这个分配器可能是硬件网络设备(例如,F5、交换机等),可能是软件网络设备(例如,LVS),也可能是负载均衡软件(例如,Nginx、HAProxy),还可能是自己开发的系统。选择合适的任务分配器也是一件复杂的事情,需要综合考虑性能、成本、可维护性、可用性等各方面的因素。
任务分配器和真正的业务服务器之间有连接和交互(即图中任务分配器到业务服务器的连接线),需要选择合适的连接方式,并且对连接进行管理。例如,连接建立、连接检测、连接中断后如何处理等。
任务分配器需要增加分配算法。例如,是采用轮询算法,还是按权重分配,又或者按照负载进行分配。如果按照服务器的负载进行分配,则业务服务器还要能够上报自己的状态给任务分配器。
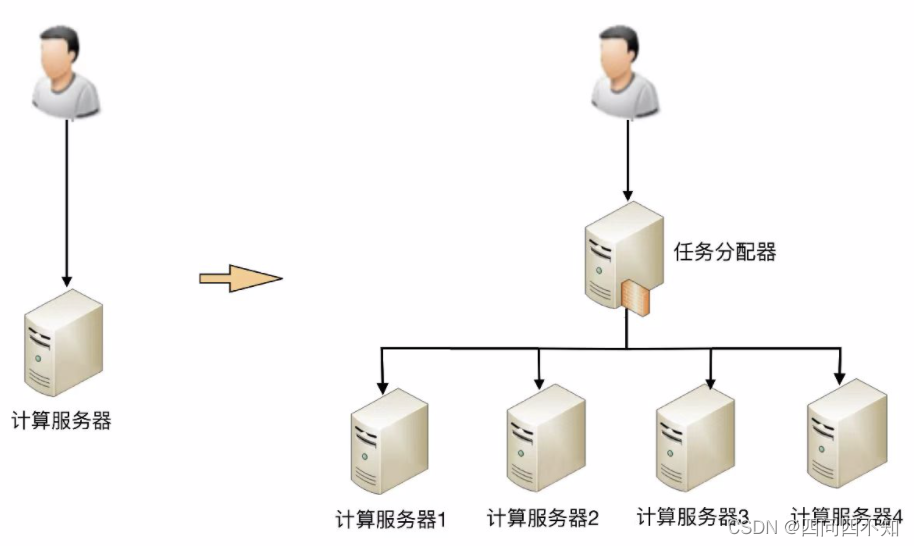
假设性能要求继续提高,要求每秒提升到10万次:
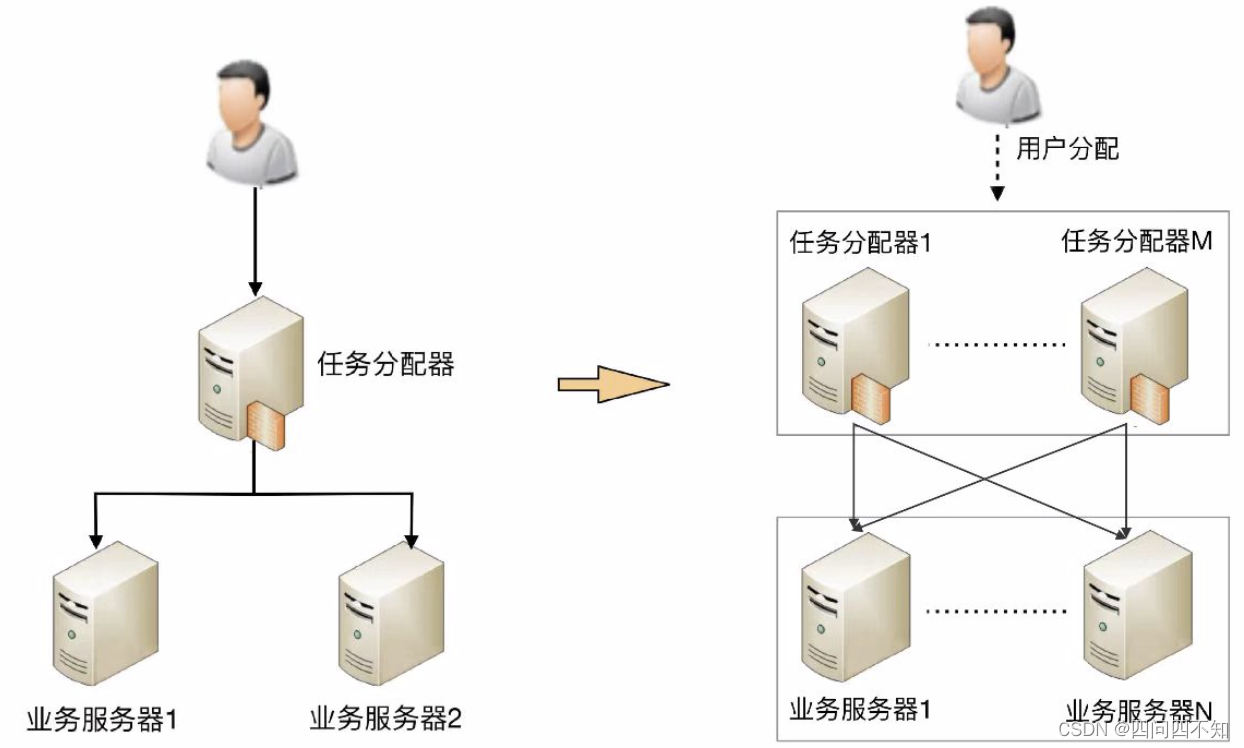
这个架构比 2 台业务服务器的架构要复杂,主要体现在:
任务分配器从 1 台变成了多台(对应图中的任务分配器 1 到任务分配器 M),这个变化带来的复杂度就是需要将不同的用户分配到不同的任务分配器上(即图中的虚线“用户分配”部分),常见的方法包括 DNS 轮询、智能 DNS、CDN(Content Delivery Network,内容分发网络)、GSLB 设备(Global Server Load Balance,全局负载均衡)等。
任务分配器和业务服务器的连接从简单的“1 对多”(1 台任务分配器连接多台业务服务器)变成了“多对多”(多台任务分配器连接多台业务服务器)的网状结构。
机器数量从 3 台扩展到 30 台(一般任务分配器数量比业务服务器要少,这里我们假设业务服务器为 25 台,任务分配器为 5 台),状态管理、故障处理复杂度也大大增加。
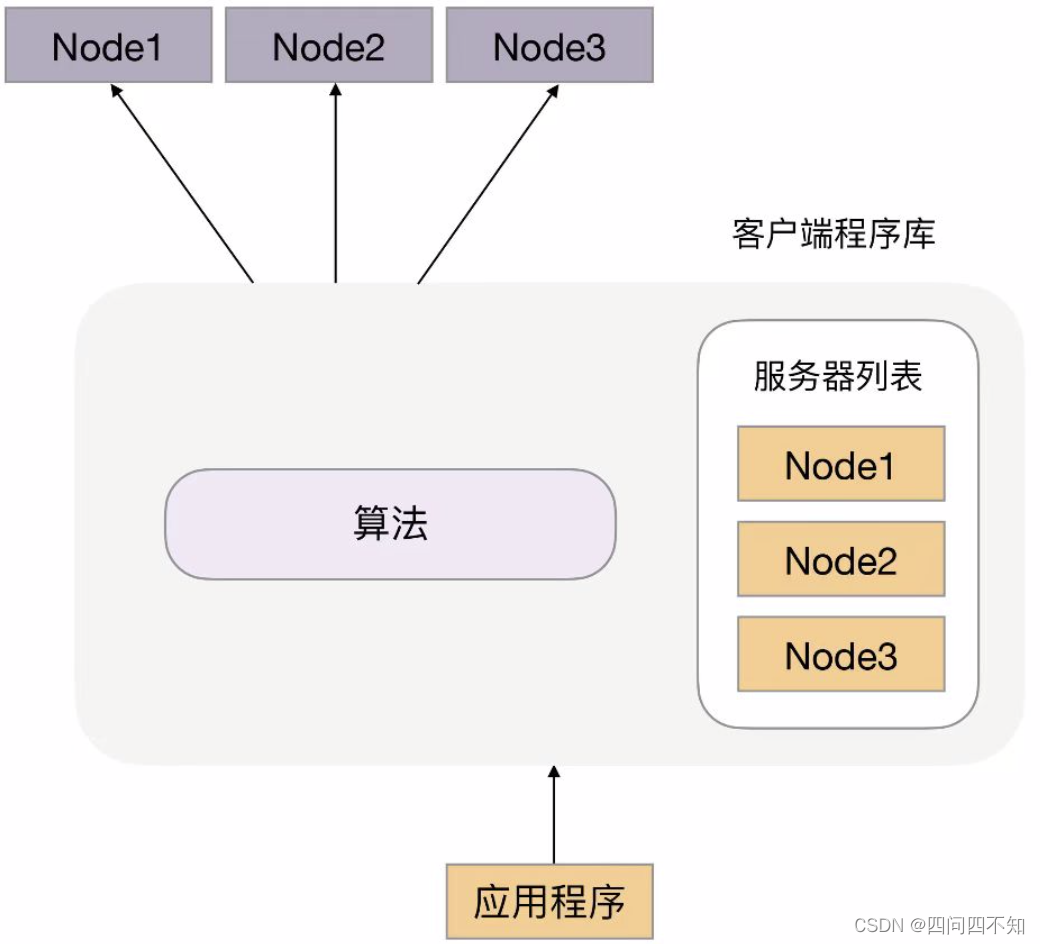
上面这两个例子都是以业务处理为例,实际上“任务”涵盖的范围很广,可以指完整的业务处理,也可以单指某个具体的任务。例如,“存储”“运算”“缓存”等都可以作为一项任务,因此存储系统、运算系统、缓存系统都可以按照任务分配的方式来搭建架构。此外,“任务分配器”也并不一定只能是物理上存在的机器或者者一个独立运行的程序,也可以是嵌入在其他程序中的算法,例如 Memcache 的集群架构。
1.2.2 任务分解
通过任务分配的方式,能够突破单台机器处理性能的瓶颈,通过增加更多的机器来满足业务的性能需求,但如果业务本身也越来越复杂,单纯只通过任务分配的方式来扩展性能,收益会越来越低。
为了能够继续提升性能,我们需要采取第二种方式:任务分解。
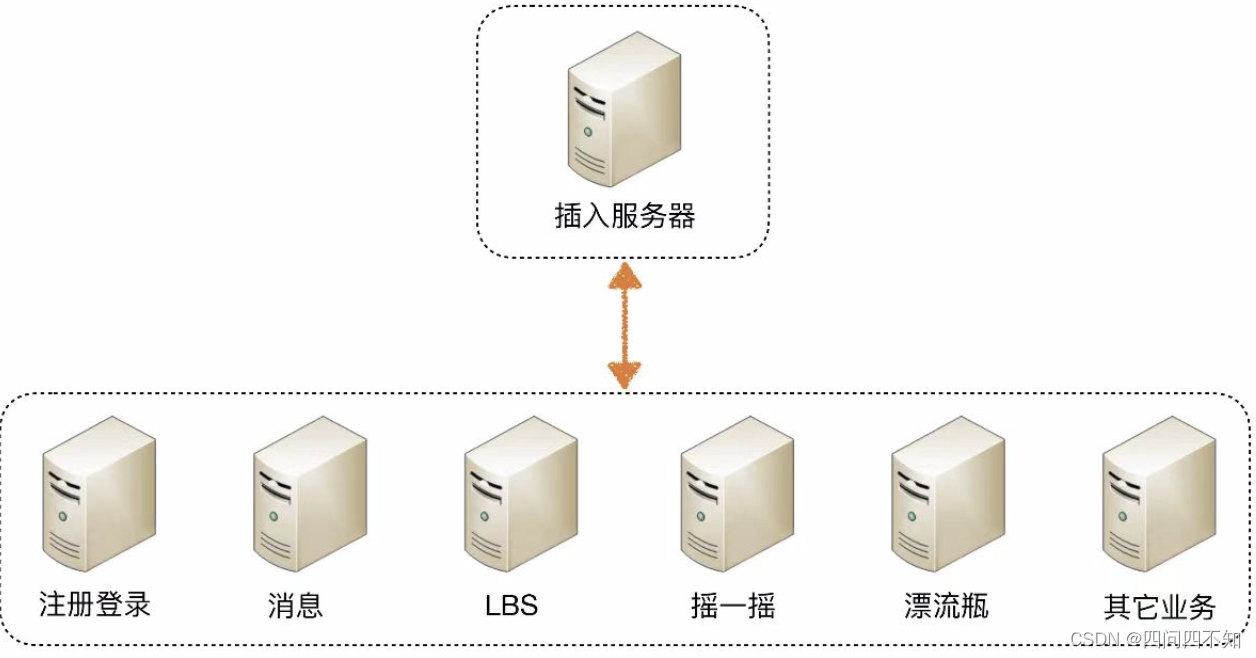
那为何通过任务分解就能够提升性能呢?
1)简单的系统更加容易做到高性能
系统的功能越简单,影响性能的点就越少,就更加容易进行有针对性的优化。而系统很复杂的情况下,首先是比较难以找到关键性能点,因为需要考虑和验证的点太多;其次是即使花费很大力气找到了,修改起来也不容易。
2)可以针对单个任务进行扩展
当各个逻辑任务分解到独立的子系统后,整个系统的性能瓶颈更加容易发现,而且发现后只需要针对有瓶颈的子系统进行性能优化或者提升,不需要改动整个系统,风险会小很多。
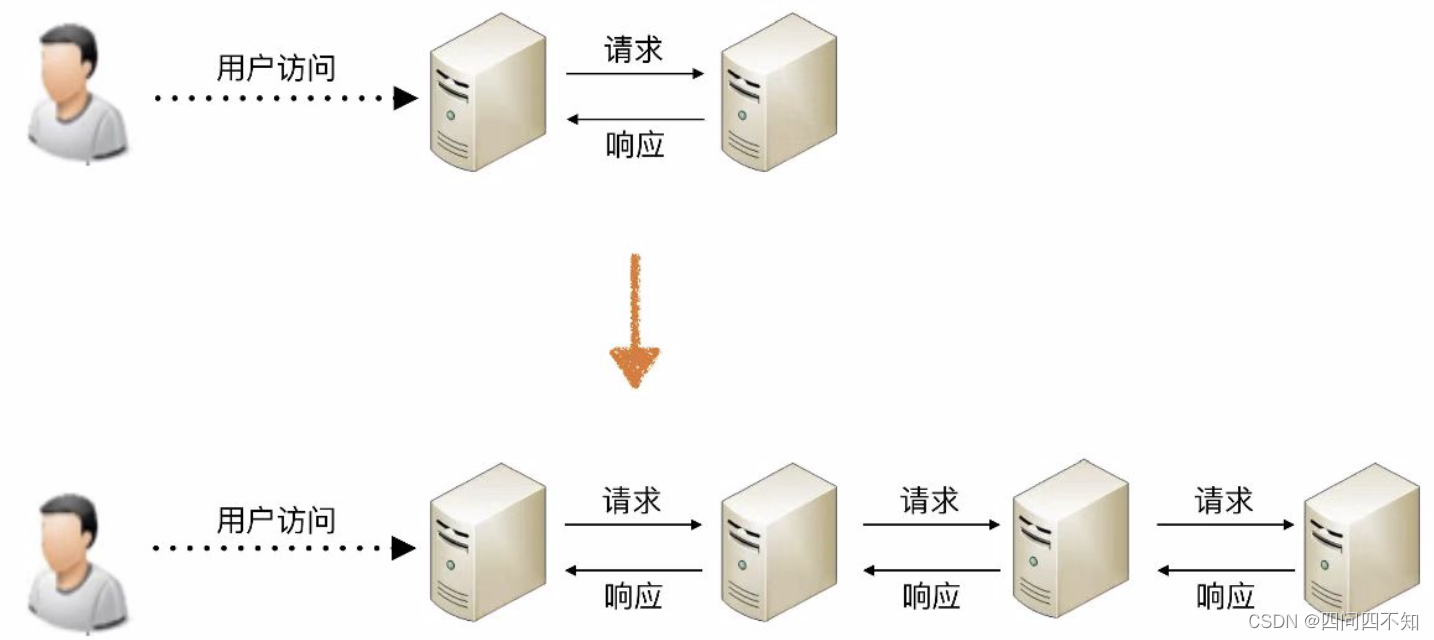
从图中可以看出,当系统拆分2个子系统的时候,用户访问需要1次系统间的请求和1次响应;当系统拆分为4个子系统的时候,系统间的请求次数从1次增长到3次;假如继续拆分下去为100个子系统,为了完成某次用户访问,系统间的请求次数变成了99次。
所以系统拆分可能在某种程度上提升业务处理性能,但提升有限,因为最终决定业务处理性能的还是业务逻辑本身。
因此,任务分解带来的性能收益有一个度,如何把握好这个度非常关键。
2 复杂度来源——高可用
高可用的定义如下,
系统无中断地执行其功能的能力,代表系统的可用性程度,是进行系统设计时的准则之一。
这个定义的关键在于“无中断”,但恰好难点也在“无中断”上面,因为无论是单个硬件还是单个软件,都不可能做到无中断,硬件会出故障,软件会有 bug;硬件会逐渐老化,软件会越来越复杂和庞大……
除了硬件和软件本质上无法做到“无中断”,外部环境导致的不可用更加不可避免、不受控制。例如,断电、水灾、地震,这些事故或者灾难也会导致系统不可用,而且影响程度更加严重,更加难以预测和规避。
所以,系统的高可用方案五花八门,但万变不离其宗,本质上都是通过“冗余”来实现高可用。通俗点来讲,就是一台机器不够就两台,两台不够就四台;一个机房可能断电,那就部署两个机房;一条通道可能故障,那就用两条,两条不够那就用三条(移动、电信、联通一起上)。高可用的“冗余”解决方案,单纯从形式上来看,和之前讲的高性能是一样的,都是通过增加更多机器来达到目的,但其实本质上是有根本区别的:高性能增加机器目的在于“扩展”处理性能;高可用增加机器目的在于“冗余”处理单元。
通过冗余增强了可用性,但同时也带来了复杂性。
2.1 计算高可用
这里的“计算”指的是业务的逻辑处理。计算有一个特点就是无论在哪台机器上进行计算,同样的算法和输入数据,产出的结果都是一样的,所以将计算从一台机器迁移到另外一台机器,对业务并没有什么影响。既然如此,计算高可用的复杂度体现在哪里呢?我以最简单的单机变双机为例进行分析。先来看一个单机变双机的简单架构示意图。
你可能会发现,这个双机的架构图和上期“高性能”讲到的双机架构图是一样的,因此复杂度也是类似的,具体表现为:
需要增加一个任务分配器,选择合适的任务分配器也是一件复杂的事情,需要综合考虑性能、成本、可维护性、可用性等各方面因素。
任务分配器和真正的业务服务器之间有连接和交互,需要选择合适的连接方式,并且对连接进行管理。例如,连接建立、连接检测、连接中断后如何处理等。
任务分配器需要增加分配算法。例如,常见的双机算法有主备、主主,主备方案又可以细分为冷备、温备、热备。
上面这个示意图只是简单的双机架构,我们再看一个复杂一点的高可用集群架构。
这个高可用集群相比双机来说,分配算法更加复杂,可以是 1 主 3 备、2 主 2 备、3 主 1 备、4 主 0 备,具体应该采用哪种方式,需要结合实际业务需求来分析和判断,并不存在某种算法就一定优于另外的算法。例如,ZooKeeper 采用的就是 1 主多备,而 Memcached 采用的就是全主 0 备。
2.2 存储高可用
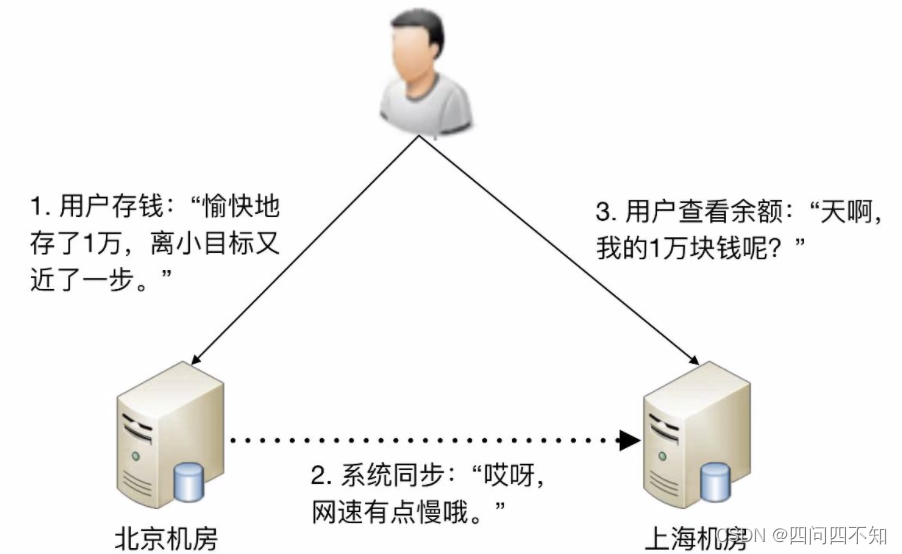
对于需要存储数据的系统来说,整个系统的高可用设计关键点和难点就在于“存储高可用”。存储与计算相比,有一个本质上的区别:将数据从一台机器搬到到另一台机器,需要经过线路进行传输。线路传输的速度是毫秒级别,同一机房内部能够做到几毫秒;分布在不同地方的机房,传输耗时需要几十甚至上百毫秒。例如,从广州机房到北京机房,稳定情况下 ping 延时大约是 50ms,不稳定情况下可能达到 1s 甚至更多。
虽然毫秒对于人来说几乎没有什么感觉,但是对于高可用系统来说,就是本质上的不同,这意味着整个系统在某个时间点上,数据肯定是不一致的。按照“数据 + 逻辑 = 业务”这个公式来套的话,数据不一致,即使逻辑一致,最后的业务表现就不一样了。
以最经典的银行储蓄业务为例,假设用户的数据存在北京机房,用户存入了 1 万块钱,然后他查询的时候被路由到了上海机房,北京机房的数据没有同步到上海机房,用户会发现他的余额并没有增加 1 万块。想象一下,此时用户肯定会背后一凉,马上会怀疑自己的钱被盗了,然后赶紧打客服电话投诉,甚至打 110 报警,即使最后发现只是因为传输延迟导致的问题,站在用户的角度来说,这个过程的体验肯定很不好。
除了物理上的传输速度限制,传输线路本身也存在可用性问题,传输线路可能中断、可能拥塞、可能异常(错包、丢包),并且传输线路的故障时间一般都特别长,短的十几分钟,长的几个小时都是可能的。例如,2015 年支付宝因为光缆被挖断,业务影响超过 4 个小时;2016 年中美海底光缆中断 3 小时等。在传输线路中断的情况下,就意味着存储无法进行同步,在这段时间内整个系统的数据是不一致的。
综合分析,无论是正常情况下的传输延迟,还是异常情况下的传输中断,都会导致系统的数据在某个时间点或者时间段是不一致的,而数据的不一致又会导致业务问题;但如果完全不做冗余,系统的整体高可用又无法保证,所以存储高可用的难点不在于如何备份数据,而在于如何减少或者规避数据不一致对业务造成的影响。
分布式领域里面有一个著名的 CAP (Consistency一致性,Availability可用性,Partition tolerance分区容错性)定理,从理论上论证了存储高可用的复杂度。也就是说,存储高可用不可能同时满足“一致性、可用性、分区容错性”,最多满足其中两个,这就要求我们在做架构设计时结合业务进行取舍。
2.3 高可用状态决策
无论是计算高可用还是存储高可用,其基础都是“状态决策”,即系统需要能够判断当前的状态是正常还是异常,如果出现了异常就要采取行动来保证高可用。如果状态决策本身都是有错误或者有偏差的,那么后续的任何行动和处理无论多么完美也都没有意义和价值。但在具体实践的过程中,恰好存在一个本质的矛盾:通过冗余来实现的高可用系统,状态决策本质上就不可能做到完全正确。下面我基于几种常见的决策方式进行详细分析。
2.3.1. 独裁式
独裁式决策指的是存在一个独立的决策主体,我们姑且称它为“决策者”,负责收集信息然后进行决策;所有冗余的个体,我们姑且称它为“上报者”,都将状态信息发送给决策者。

独裁式的决策方式不会出现决策混乱的问题,因为只有一个决策者,但问题也正是在于只有一个决策者。当决策者本身故障时,整个系统就无法实现准确的状态决策。如果决策者本身又做一套状态决策,那就陷入一个递归的死循环了。
2.3.2. 协商式
协商式决策指的是两个独立的个体通过交流信息,然后根据规则进行决策,最常用的协商式决策就是主备决策。
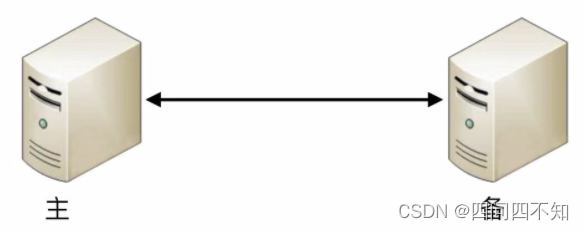
这个架构的基本协商规则可以设计成:
- 2台服务器启动时都是备机。
- 2台服务器建立连接。
- 2台服务器交换状态信息。
- 某1台服务器做出决策,成为主机;另一台服务器继续保持备机身份。
协商式决策的架构不复杂,规则也不复杂,其难点在于,如果两者的信息交换出现问题(比如主备连接中断),此时状态决策应该怎么做。
如果备机在连接中断的情况下认为主机故障,那么备机需要升级为主机,但实际上此时主机并没有故障,那么系统就出现了两个主机,这与设计初衷(1 主 1 备)是不符合的。
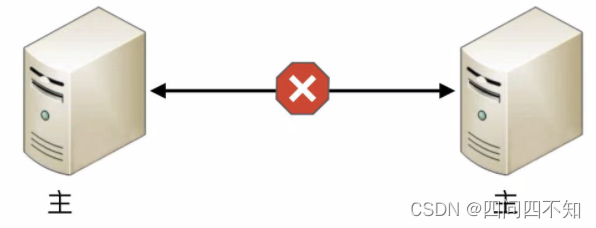
如果备机在连接中断的情况下不认为主机故障,则此时如果主机真的发生故障,那么系统就没有主机了,这同样与设计初衷(1 主 1 备)是不符合的。
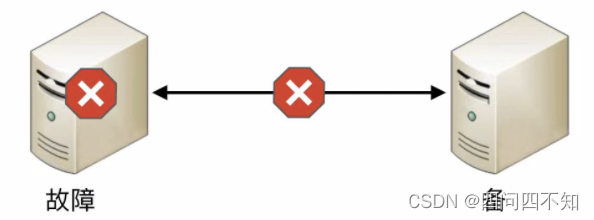
如果为了规避连接中断对状态决策带来的影响,可以增加更多的连接。例如,双连接、三连接。这样虽然能够降低连接中断对状态带来的影响(注意:只能降低,不能彻底解决),但同时又引入了这几条连接之间信息取舍的问题,即如果不同连接传递的信息不同,应该以哪个连接为准?实际上这也是一个无解的答案,无论以哪个连接为准,在特定场景下都可能存在问题。
综合分析,协商式状态决策在某些场景总是存在一些问题的。
2.3.3. 民主式
民主式决策指的是多个独立的个体通过投票的方式来进行状态决策。例如,ZooKeeper 集群在选举 leader 时就是采用这种方式。
民主式决策和协商式决策比较类似,其基础都是独立的个体之间交换信息,每个个体做出自己的决策,然后按照“多数取胜”的规则来确定最终的状态。不同点在于民主式决策比协商式决策要复杂得多,ZooKeeper 的选举算法 ZAB,绝大部分人都看得云里雾里,更不用说用代码来实现这套算法了。
除了算法复杂,民主式决策还有一个固有的缺陷:脑裂。这个词来源于医学,指人体左右大脑半球的连接被切断后,左右脑因为无法交换信息,导致各自做出决策,然后身体受到两个大脑分别控制,会做出各种奇怪的动作。例如:当一个脑裂患者更衣时,他有时会一只手将裤子拉起,另一只手却将裤子往下脱。脑裂的根本原因是,原来统一的集群因为连接中断,造成了两个独立分隔的子集群,每个子集群单独进行选举,于是选出了 2 个主机,相当于人体有两个大脑了。
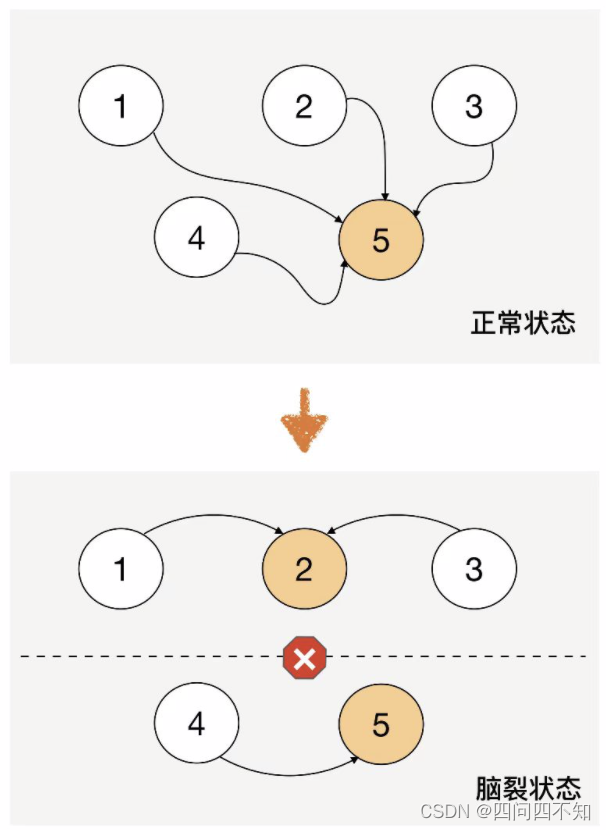
从图中可以看到,正常状态的时候,节点 5 作为主节点,其他节点作为备节点;当连接发生故障时,节点 1、节点 2、节点 3 形成了一个子集群,节点 4、节点 5 形成了另外一个子集群,这两个子集群的连接已经中断,无法进行信息交换。按照民主决策的规则和算法,两个子集群分别选出了节点 2 和节点 5 作为主节点,此时整个系统就出现了两个主节点。这个状态违背了系统设计的初衷,两个主节点会各自做出自己的决策,整个系统的状态就混乱了。
为了解决脑裂问题,民主式决策的系统一般都采用“投票节点数必须超过系统总节点数一半”规则来处理。如图中那种情况,节点 4 和节点 5 形成的子集群总节点数只有 2 个,没有达到总节点数 5 个的一半,因此这个子集群不会进行选举。这种方式虽然解决了脑裂问题,但同时降低了系统整体的可用性,即如果系统不是因为脑裂问题导致投票节点数过少,而真的是因为节点故障(例如,节点 1、节点 2、节点 3 真的发生了故障),此时系统也不会选出主节点,整个系统就相当于宕机了,尽管此时还有节点 4 和节点 5 是正常的。
综合分析,无论采取什么样的方案,状态决策都不可能做到任何场景下都没有问题,但完全不做高可用方案又会产生更大的问题,如何选取适合系统的高可用方案,也是一个复杂的分析、判断和选择的过程。
3 复杂度来源——可扩展性
可扩展性指,系统为了应对将来需求变化而提供的一种扩展能力,当有新的需求出现时,系统不需要或者仅需要少量修改就可以支持,无须整个系统重构或者重建。
由于软件系统固有的多变性,新的需求总会不断提出来,因此可扩展性显得尤其重要。在软件开发领域,面向对象思想的提出,就是为了解决可扩展性带来的问题;后来的设计模式,更是将可扩展性做到了极致。得益于设计模式的巨大影响力,几乎所有的技术人员对于可扩展性都特别重视。
设计具备良好可扩展性的系统,有两个基本条件:正确预测变化、完美封装变化。但要达成这两个条件,本身也是一件复杂的事情,我来具体分析一下。
3.1 预测变化
软件系统与硬件或者建筑相比,有一个很大的差异:软件系统在发布后还可以不断地修改和演进,这就意味着不断有新的需求需要实现。如果新需求能够不改代码甚至少改代码就可以实现,那当然是皆大欢喜的,否则来一个需求就要求系统大改一次,成本会非常高,程序员心里也不爽(改来改去),产品经理也不爽(做得那么慢),老板也不爽(那么多人就只能干这么点事)。因此作为架构师,我们总是试图去预测所有的变化,然后设计完美的方案来应对,当下一次需求真正来临时,架构师可以自豪地说:这个我当时已经预测到了,架构已经完美地支持,只需要一两天工作量就可以了!
然而理想是美好的,现实却是复杂的。有一句谚语,“唯一不变的是变化”,如果按照这个标准去衡量,架构师每个设计方案都要考虑可扩展性。例如,架构师准备设计一个简单的后台管理系统,当架构师考虑用 MySQL 存储数据时,是否要考虑后续需要用 Oracle 来存储?当架构师设计用 HTTP 做接口协议时,是否要考虑要不要支持 ProtocolBuffer?甚至更离谱一点,架构师是否要考虑 VR 技术对架构的影响从而提前做好可扩展性?如果每个点都考虑可扩展性,架构师会不堪重负,架构设计也会异常庞大且最终无法落地。但架构师也不能完全不做预测,否则可能系统刚上线,马上来新的需求就需要重构,这同样意味着前期很多投入的工作量也白费了。
同时,“预测”这个词,本身就暗示了不可能每次预测都是准确的,如果预测的事情出错,我们期望中的需求迟迟不来,甚至被明确否定,那么基于预测做的架构设计就没什么作用,投入的工作量也就白费了。
综合分析,预测变化的复杂性在于:
- 1)不能每个设计点都考虑可扩展性。
- 2)不能完全不考虑可扩展性。
- 3)所有的预测都存在出错的可能性。
对于架构师来说,如何把握预测的程度和提升预测结果的准确性,是一件很复杂的事情,而且没有通用的标准可以简单套上去,更多是靠自己的经验、直觉,所以架构设计评审的时候经常会出现两个设计师对某个判断争得面红耳赤的情况,原因就在于没有明确标准,不同的人理解和判断有偏差,而最终又只能选择一个判断。
另外预测尽量遵循2年法则,即只预测2年内的可能变化,不要试图预测5年甚至10年后的变化。
3.2 应对变化
假设架构师经验非常丰富,目光非常敏锐,看问题非常准,所有的变化都能准确预测,是否意味着可扩展性就很容易实现了呢?也没那么理想!因为预测变化是一回事,采取什么方案来应对变化,又是另外一个复杂的事情。即使预测很准确,如果方案不合适,则系统扩展一样很麻烦。
3.2.1 方案一:提炼出“变化层”和“稳定层”
第一种应对变化的常见方案是:将“变化”封装在一个“变化层”,将不变的部分封装在一个独立的“稳定层”。这种方案的核心思想是通过变化层来隔离变化。
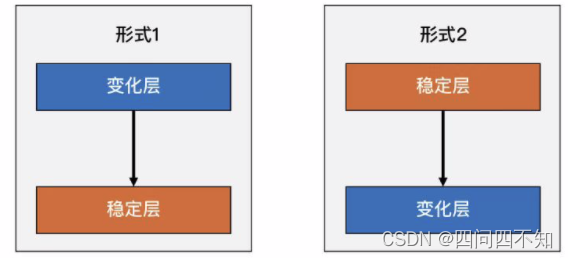
无论是变化层依赖稳定层,还是稳定层依赖变化层都是可以的,需要根据具体业务情况来设计。例如,如果系统需要支持 XML、JSON、ProtocolBuffer 三种接入方式,那么最终的架构就是上面图中的“形式 1”架构;如果系统需要支持 MySQL、Oracle、DB2 数据库存储,那么最终的架构就变成了“形式 2”的架构了。
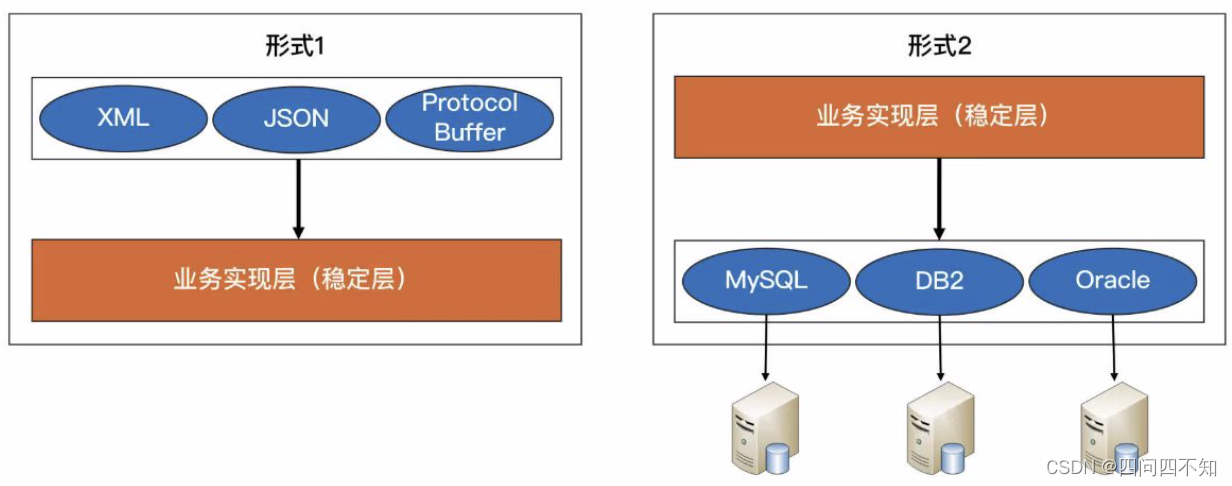
无论采取哪种形式,通过剥离变化层和稳定层的方式应对变化,都会带来两个主要的复杂性相关的问题。
变化层和稳定层如何拆分?
对于哪些属于变化层,哪些属于稳定层,很多时候并不是像前面的示例(不同接口协议或者不同数据库)那样明确,不同的人有不同的理解,导致架构设计评审的时候可能吵翻天。
变化层和稳定层之间的接口如何设计?
对于稳定层来说,接口肯定是越稳定越好;但对于变化层来说,在有差异的多个实现方式中找出共同点,并且还要保证当加入新的功能时原有的接口设计不需要太大修改,这是一件很复杂的事情。例如,MySQL 的 REPLACE INTO 和 Oracle 的 MERGE INTO 语法和功能有一些差异,那存储层如何向稳定层提供数据访问接口呢?是采取 MySQL 的方式,还是采取 Oracle 的方式,还是自适应判断?如果再考虑 DB2 的情况呢?相信你看到这里就已经能够大致体会到接口设计的复杂性了。
3.2.2 方案二:提炼出“抽象层”和“实现层”
第二种常见的应对变化的方案是:提炼出一个“抽象层”和一个“实现层”。方案二的核心思想就是通过实现层来封装变化。
因为抽象层的接口是稳定的不变的,我们可以基于抽象层的接口来实现统一的处理规则,而实现层可以根据具体业务需要定制开发,当加入新的功能时,只需要增加新的实现,无须修改抽象层。这种方案典型的实践就是设计模式和规则引擎。考虑到绝大部分技术人员对设计模式都非常熟悉,我以设计模式为例来说明这种方案的复杂性。
以设计模式的“装饰者”模式来分析,下面是装饰者模式的类关系图。
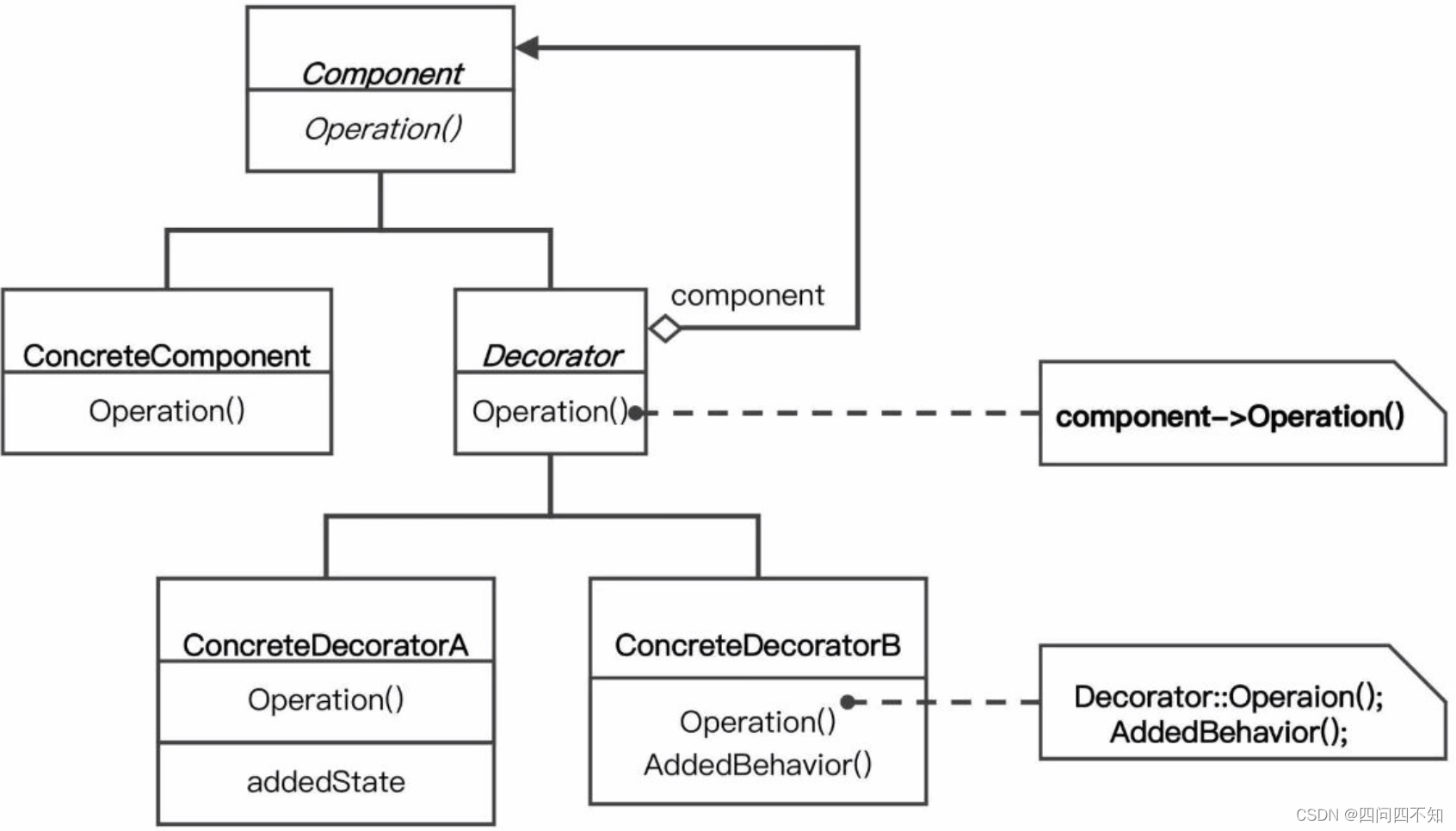
图中的 Component 和 Decorator 就是抽象出来的规则,这个规则包括几部分:
- Component 和 Decorator 类。
- Decorator 类继承 Component 类。
- Decorator 类聚合了 Component 类。
这个规则一旦抽象出来后就固定了,不能轻易修改。例如,把规则3去掉,就无法实现装饰者模式的目的了。装饰者模式相比传统的继承来实现功能,确实灵活很多。例如,《设计模式》中装饰者模式的样例“TextView”类的实现,用了装饰者之后,能够灵活地给 TextView 增加额外更多功能,比如可以增加边框、滚动条、背景图片等,这些功能上的组合不影响规则,只需要按照规则实现即可。但装饰者模式相对普通的类实现模式,明显要复杂多了。本来一个函数或者一个类就能搞定的事情,现在要拆分成多个类,而且多个类之间必须按照装饰者模式来设计和调用。
规则引擎和设计模式类似,都是通过灵活的设计来达到可扩展的目的,但“灵活的设计”本身就是一件复杂的事情,不说别的,光是把 23 种设计模式全部理解和备注,都是一件很困难的事情。
3.2.3 1写2抄3重构原则
在Martin Fowler的经典书籍《重构》中给出一个“Rule of three”原则,即1写2抄3重构原则。
针对该原则,以对接第三方钱包为例,
- 1写:选择微信钱包对接时,不需要考虑太多可扩展性,直接快速对照微信支付的API对接即可,因为业务是否能做起来还不确定。
- 2抄:后续如果业务发展不错,决定要接入支付宝,此时还是可以不考虑可扩展性,直接把原来微信支付接入的代码拷贝过来,然后对照支付宝的API,快速修改上线。
- 3重构:因为业务发展不错,为了方便更多用户,决定接入银联云闪付,此时需要考虑重构,参考设计模式的模版方法和策略模式将支付对接的功能进行封装。
4 复杂度来源——低成本、安全、规模
4.1 低成本
当我们的架构方案只涉及几台或者十几台服务器时,一般情况下成本并不是我们重点关注的目标,但如果架构方案涉及几百上千甚至上万台服务器,成本就会变成一个非常重要的架构设计考虑点。例如,A 方案需要 10000 台机器,B 方案只需要 8000 台机器,单从比例来看,也就节省了 20% 的成本,但从数量来看,B 方案能节省 2000 台机器,1 台机器成本预算每年大约 2 万元,这样一年下来就能节省 4000 万元,4000 万元成本不是小数目,给 100 人的团队发奖金每人可以发 40 万元了,这可是算得上天价奖金了。通过一个架构方案的设计,就能轻松节约几千万元,不但展现了技术的强大力量,也带来了可观的收益,对于技术人员来说,最有满足感的事情莫过于如此了。
当我们设计“高性能”“高可用”的架构时,通用的手段都是增加更多服务器来满足“高性能”和“高可用”的要求;而低成本正好与此相反,我们需要减少服务器的数量才能达成低成本的目标。因此,低成本本质上是与高性能和高可用冲突的,所以低成本很多时候不会是架构设计的首要目标,而是架构设计的附加约束。也就是说,我们首先设定一个成本目标,当我们根据高性能、高可用的要求设计出方案时,评估一下方案是否能满足成本目标,如果不行,就需要重新设计架构;如果无论如何都无法设计出满足成本要求的方案,那就只能找老板调整成本目标了。
低成本给架构设计带来的主要复杂度体现在,往往只有“创新”才能达到低成本目标。这里的“创新”既包括开创一个全新的技术领域(这个要求对绝大部分公司太高),也包括引入新技术,如果没有找到能够解决自己问题的新技术,那么就真的需要自己创造新技术了。
类似的新技术例子很多,我来举几个。
- NoSQL(Memcache、Redis 等)的出现是为了解决关系型数据库无法应对高并发访问带来的访问压力。
- 全文搜索引擎(Sphinx、Elasticsearch、Solr)的出现是为了解决关系型数据库 like 搜索的低效的问题。
- Hadoop 的出现是为了解决传统文件系统无法应对海量数据存储和计算的问题。
我再来举几个业界类似的例子。
- Facebook 为了解决 PHP 的低效问题,刚开始的解决方案是 HipHop PHP,可以将 PHP 语言翻译为 C++ 语言执行,后来改为 HHVM,将 PHP 翻译为字节码然后由虚拟机执行,和 Java 的 JVM 类似。
- 新浪微博将传统的 Redis/MC + MySQL 方式,扩展为 Redis/MC + SSD Cache + MySQL 方式,SSD Cache 作为 L2 缓存使用,既解决了 MC/Redis 成本过高,容量小的问题,也解决了穿透 DB 带来的数据库访问压力(来源:http://www.infoq.com/cn/articles/weibo-platform-archieture )。
- Linkedin 为了处理每天 5 千亿的事件,开发了高效的 Kafka 消息系统。
其他类似将 Ruby on Rails 改为 Java、Lua + redis 改为 Go 语言实现的例子还有很多。
无论是引入新技术,还是自己创造新技术,都是一件复杂的事情。引入新技术的主要复杂度在于需要去熟悉新技术,并且将新技术与已有技术结合起来;创造新技术的主要复杂度在于需要自己去创造全新的理念和技术,并且新技术跟旧技术相比,需要有质的飞跃。
相比来说,创造新技术复杂度更高,因此一般中小公司基本都是靠引入新技术来达到低成本的目标;而大公司更有可能自己去创造新的技术来达到低成本的目标,因为大公司才有足够的资源、技术和时间去创造新技术。
4.2 安全
安全本身是一个庞大而又复杂的技术领域,并且一旦出问题,对业务和企业形象影响非常大。例如:
2016 年雅虎爆出史上最大规模信息泄露事件,逾 5 亿用户资料在 2014 年被窃取。
2016 年 10 月美国遭史上最大规模 DDoS 攻击,东海岸网站集体瘫痪。
2013 年 10 月,为全国 4500 多家酒店提供网络服务的浙江慧达驿站网络有限公司,因安全漏洞问题,致 2 千万条入住酒店的客户信息泄露,由此导致很多敲诈、家庭破裂的后续事件。
正因为经常能够看到或者听到各类安全事件,所以大部分技术人员和架构师,对安全这部分会多一些了解和考虑。
从技术的角度来讲,安全可以分为两类:一类是功能上的安全,一类是架构上的安全。
4.2.1. 功能安全
例如,常见的 XSS 攻击、CSRF 攻击、SQL 注入、Windows 漏洞、密码破解等,本质上是因为系统实现有漏洞,黑客有了可乘之机。黑客会利用各种漏洞潜入系统,这种行为就像小偷一样,黑客和小偷的手法都是利用系统或家中不完善的地方潜入,并进行破坏或者盗取。因此形象地说,功能安全其实就是“防小偷”。
从实现的角度来看,功能安全更多地是和具体的编码相关,与架构关系不大。现在很多开发框架都内嵌了常见的安全功能,能够大大减少安全相关功能的重复开发,但框架只能预防常见的安全漏洞和风险(常见的 XSS 攻击、CSRF 攻击、SQL 注入等),无法预知新的安全问题,而且框架本身很多时候也存在漏洞(例如,流行的 Apache Struts2 就多次爆出了调用远程代码执行的高危漏洞,给整个互联网都造成了一定的恐慌)。所以功能安全是一个逐步完善的过程,而且往往都是在问题出现后才能有针对性的提出解决方案,我们永远无法预测系统下一个漏洞在哪里,也不敢说自己的系统肯定没有任何问题。换句话讲,功能安全其实也是一个“攻”与“防”的矛盾,只能在这种攻防大战中逐步完善,不可能在系统架构设计的时候一劳永逸地解决。
4.2.2. 架构安全
如果说功能安全是“防小偷”,那么架构安全就是“防强盗”。强盗会直接用大锤将门砸开,或者用炸药将围墙炸倒;小偷是偷东西,而强盗很多时候就是故意搞破坏,对系统的影响也大得多。因此架构设计时需要特别关注架构安全,尤其是互联网时代,理论上来说系统部署在互联网上时,全球任何地方都可以发起攻击。传统的架构安全主要依靠防火墙,防火墙最基本的功能就是隔离网络,通过将网络划分成不同的区域,制定出不同区域之间的访问控制策略来控制不同信任程度区域间传送的数据流(类似RBAC,Role-Based Access Control,基于角色的访问控制)。例如,下图是一个典型的银行系统的安全架构。
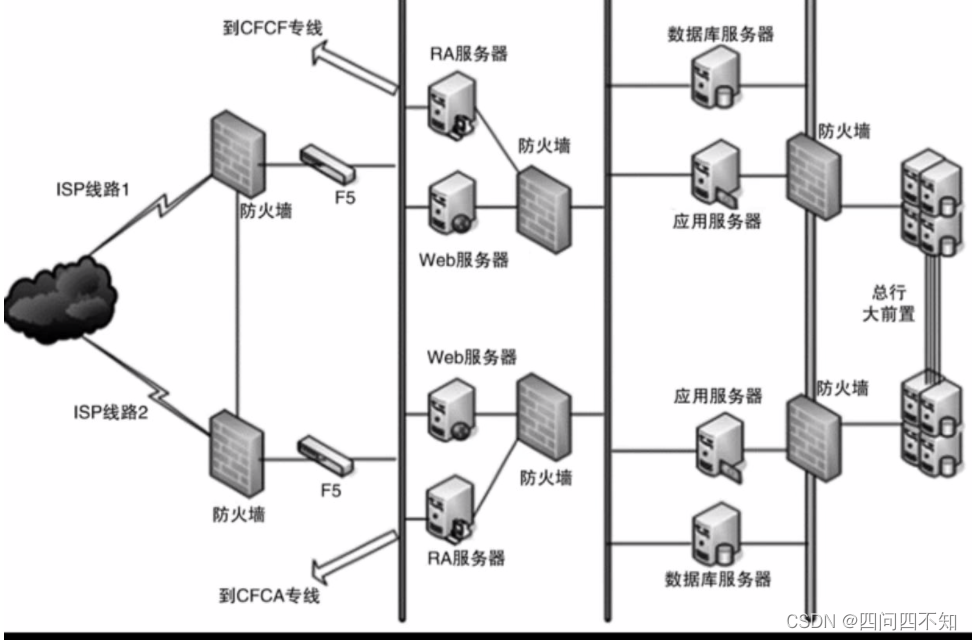
从图中你可以看到,整个系统根据不同的分区部署了多个防火墙来保证系统的安全。
防火墙的功能虽然强大,但性能一般,所以在传统的银行和企业应用领域应用较多。但在互联网领域,防火墙的应用场景并不多。因为互联网的业务具有海量用户访问和高并发的特点,防火墙的性能不足以支撑;尤其是互联网领域的 DDoS(Distributed Denial of Service,分布式拒绝访问服务攻击,也称泛洪攻击)攻击,轻则几 GB,重则几十 GB。2016 年知名安全研究人员布莱恩·克莱布斯(Brian Krebs)的安全博客网站遭遇 DDoS 攻击,攻击带宽达 665Gbps,是目前在网络犯罪领域已知的最大的拒绝服务攻击。这种规模的攻击,如果用防火墙来防,则需要部署大量的防火墙,成本会很高。例如,中高端一些的防火墙价格 10 万元,每秒能抗住大约 25GB 流量,那么应对这种攻击就需要将近 30 台防火墙,成本将近 300 万元,这还不包括维护成本,而这些防火墙设备在没有发生攻击的时候又没有什么作用。也就是说,如果花费几百万元来买这么一套设备,有可能几年都发挥不了任何作用。
就算是公司对钱不在乎,一般也不会堆防火墙来防 DDoS 攻击,因为 DDoS 攻击最大的影响是大量消耗机房的出口总带宽。不管防火墙处理能力有多强,当出口带宽被耗尽时,整个业务在用户看来就是不可用的,因为用户的正常请求已经无法到达系统了。防火墙能够保证内部系统不受冲击,但用户也是进不来的。对于用户来说,业务都已经受到影响了,至于是因为用户自己进不去,还是因为系统出故障,用户其实根本不会关心。
基于上述原因,互联网系统的架构安全目前并没有太好的设计手段来实现,更多地是依靠运营商或者云服务商强大的带宽和流量清洗的能力,较少自己来设计和实现。
4.3 规模
很多企业级的系统,既没有高性能要求,也没有双中心高可用要求,也不需要什么扩展性,但往往我们一说到这样的系统,很多人都会脱口而出:这个系统好复杂!为什么这样说呢?关键就在于这样的系统往往功能特别多,逻辑分支特别多。特别是有的系统,发展时间比较长,不断地往上面叠加功能,后来的人由于不熟悉整个发展历史,可能连很多功能的应用场景都不清楚,或者细节根本无法掌握,面对的就是一个黑盒系统,看不懂、改不动、不敢改、修不了,复杂度自然就感觉很高了。
规模带来复杂度的主要原因就是“量变引起质变”,当数量超过一定的阈值后,复杂度会发生质的变化。常见的规模带来的复杂度有:
1.功能越来越多,导致系统复杂度指数级上升
例如,某个系统开始只有 3 大功能,后来不断增加到 8 大功能,虽然还是同一个系统,但复杂度已经相差很大了,具体相差多大呢?
我以一个简单的抽象模型来计算一下,假设系统间的功能都是两两相关的,系统的复杂度 = 功能数量 + 功能之间的连接数量,通过计算我们可以看出:
3 个功能的系统复杂度 = 3 + 3 = 6
8 个功能的系统复杂度 = 8 + 28 = 36
可以看出,具备 8 个功能的系统的复杂度不是比具备 3 个功能的系统的复杂度多 5,而是多了 30,基本是指数级增长的,主要原因在于随着系统功能数量增多,功能之间的连接呈指数级增长。下图形象地展示了功能数量的增多带来了复杂度。
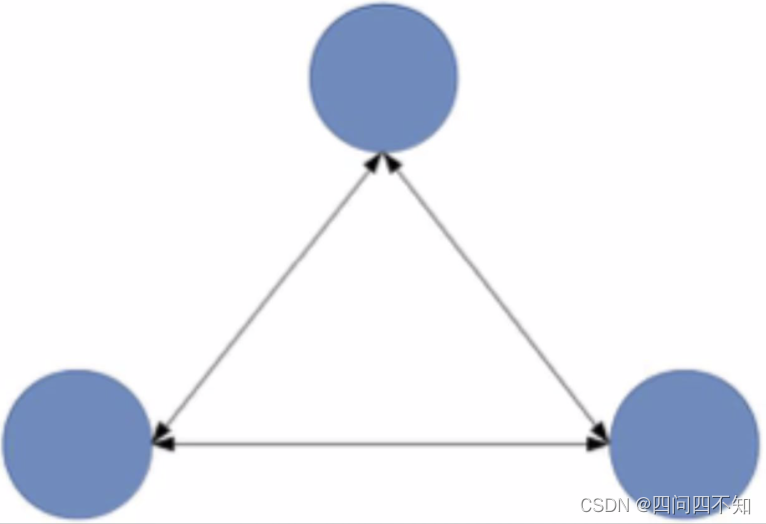
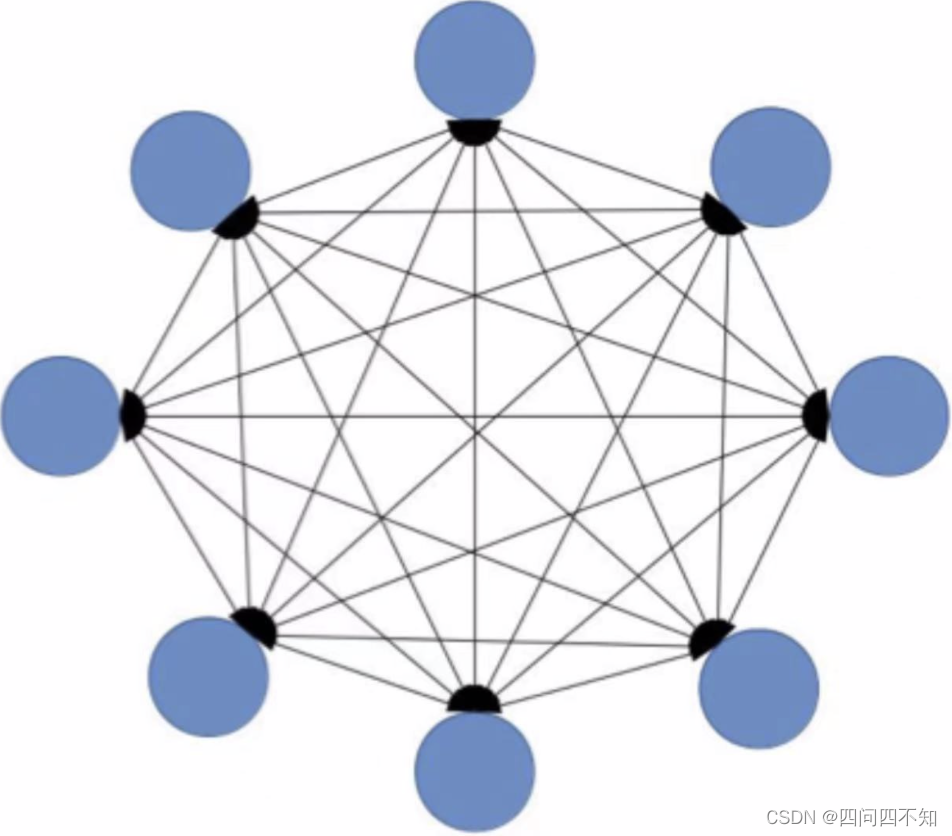
通过肉眼就可以很直观地看出,具备 8 个功能的系统复杂度要高得多。
2.数据越来越多,系统复杂度发生质变
与功能类似,系统数据越来越多时,也会由量变带来质变,最近几年火热的“大数据”就是在这种背景下诞生的。大数据单独成为了一个热门的技术领域,主要原因就是数据太多以后,传统的数据收集、加工、存储、分析的手段和工具已经无法适应,必须应用新的技术才能解决。目前的大数据理论基础是 Google 发表的三篇大数据相关论文,其中 Google File System 是大数据文件存储的技术理论,Google Bigtable 是列式数据存储的技术理论,Google MapReduce 是大数据运算的技术理论,这三篇技术论文各自开创了一个新的技术领域。
即使我们的数据没有达到大数据规模,数据的增长也可能给系统带来复杂性。最典型的例子莫过于使用关系数据库存储数据,我以 MySQL 为例,MySQL 单表的数据因不同的业务和应用场景会有不同的最优值,但不管怎样都肯定是有一定的限度的,一般推荐在 5000 万行左右。如果因为业务的发展,单表数据达到了 10 亿行,就会产生很多问题,例如:
添加索引会很慢,可能需要几个小时,这几个小时内数据库表是无法插入数据的,相当于业务停机了。
修改表结构和添加索引存在类似的问题,耗时可能会很长。
即使有索引,索引的性能也可能会很低,因为数据量太大。
数据库备份耗时很长。
……
因此,当 MySQL 单表数据量太大时,我们必须考虑将单表拆分为多表,这个拆分过程也会引入更多复杂性,例如:
拆表的规则是什么?
以用户表为例:是按照用户 id 拆分表,还是按照用户注册时间拆表?拆完表后查询如何处理?
以用户表为例:假设按照用户 id 拆表,当业务需要查询学历为“本科”以上的用户时,要去很多表查询才能得到最终结果,