要理解python是如何解析网页的,首先要理解什么是网页解析器。
简单的说就是用来解析html网页的工具,准确的说:它是一个HTML网页信息提取工具,就是从html网页中解析提取出“我们需要的有价值的数据”或者“新的URL链接”的工具。
解析HTML:
- 层次化的数据
- 有多个解析HTML的第三方库,例如:LXML,BeautifulSoup,HTMLParser等等。
- 解析HTML面临的问题:没有统一的标准、很多网页并没有遵循HTML文档
我们知道爬虫的原理无非是把目标网址的内容下载下来存储到内存中,这个时候它的内容其实是一堆HTML,然后再对这些HTML内容进行解析,按照自己的想法提取出想要的数据。
今天主要讲讲Python中解析网页HTML内容的四种方法:
- BeautifulSoup
- lxml的XPath
- requests-html
- 正则表达式
其中BeautifulSoup和XPath是python中解析网页常用的两个库,对于新手来说是利器,零基础小白建议先打好Python基础再去上手爬虫会容易一些。
**“零基础如何学Python”**在csdn看到过一篇比较好的文章,讲的很实用,大家伙可以移步去看看,链接分享在下方。
1、BeautifulSoup
大名鼎鼎的BeautifulSoup库,在Pyhton的HTML解析库里属于重量级的库。
安装途径:
pip install beautifulsoup4
解析的第一步,是构建一个BeautifulSoup对象。
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html_doc, 'html.parser')
第二个参数表示解析器,BeautifulSoup支持以下多种解释器:

BeautifulSoup对应一个HTML/XML文档的全部内容;

BeautifulSoup类的基本元素

任何存在于HTML语法中的标签都可以用soup.访问获得,当HTML文档中存在多个相同对应内容时,soup.返回第一个。
每个都有自己的名字,通过.name获取,字符串类型
Tag的attrs:一个可以有0或多个属性,字典类型
NavigableString可以跨越多个层次
1)访问标签
通过点号操作符,可以直接访问文档中的特定标签,示例:
>>> soup = BeautifulSoup(html_doc, 'lxml')
>>> soup.head
<head><title>The Dormouse's story</title></head>
>>> soup.head.title
<title>The Dormouse's story</title>
>>> soup.a
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
这样的方式每次只会返回文档中的第一个标签,对于多个标签,则通过find_all方法返回多个标签构成的列表。
>>> soup.find_all('a')
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
>>> soup.find_all('a')[0]
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
还可以在find方法中添加过滤条件,更加精确的定位元素。
# 通过text进行筛选
>>> soup.find_all('a', text='Elsie')
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
# 通过属性和值来进行筛选
>>> soup.find_all('a', attrs={'id':'link1'})
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
# 上述写法的简便写法,只适合部分属性
>>> soup.find_all('a', id='link1')
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
```
# 使用CSS选择器
# 注意class后面加下划线
>>> soup.find_all('p', class_='title')
[<p class="title"><b>The Dormouse's story</b></p>]
2)访问标签内容和属性
通过name和string可以访问标签的名字和内容,通过get和中括号操作符则可以访问标签中的属性和值。
>>> soup.a
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
>>> soup.a['class']
['sister']
>>> soup.a.get('class')
['sister']
>>> soup.a.name
'a'
>>> soup.a.string
'Elsie'
结合定位元素和访问属性的方法,可以方便快捷的提取对应元素,提高解析html的便利性。
使用Beautiful Soup库解析网页
import requests
import chardet
from bs4 import BeautifulSoup
ua = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) Chrome/65.0.3325.181'}
rqg=requests.get(url,headers=ua,timeout=3.0)
rqg.encoding = chardet.detect(rqg.content)['encoding'] #requests请求过程
#初始化HTML
html = rqg.content.decode('utf-8')
soup = BeautifulSoup(html, 'lxml') #生成BeautifulSoup对象
print('输出格式化的BeautifulSoup对象:',soup.prettify())
print('名为title的全部子节点:',soup.find_all("title"))
print('title子节点的文本内容:',soup.title.string)
print('使用get_text()获取的文本内容:',soup.title.get_text())
target = soup.find_all('ul',class_='menu') #按照css类名完全匹配
target = soup.find_all(id='menu') #传入关键字id,搜索符合条件的节点
target = soup.ul.find_all('a') #所有名称为a的节点
BeautifulSoup解析内容同样需要将请求和解析分开,从代码清晰程度来讲还将就,不过在做复杂的解析时代码略显繁琐,总体来讲用起来还不错,看个人喜好吧。
爬虫的基本技能最重要的两点:如何抓取数据?如何解析数据?我们要活学活用,在不同的时候利用最有效的工具去完成我们的目的。
工具是其次,学习不要主末颠倒了,我上面分享的那篇文章也有提到过这个问题(链接有放在下方),要明确你学习的最终目的是什么?
点此查看:零基础学Python有什么建议?
2、lxml的XPath
lxml这个库同时支持HTML和XML的解析,支持XPath解析方式,解析效率挺高,不过我们需要熟悉它的一些规则语法才能使用。
使用xpath需要从lxml库中导入etree模块,还需要使用HTML类对需要匹配的HTML对象进行初始化。
import requests
import chardet
from lxml import etree
ua = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) Chrome/65.0.3325.181'}
rqg=requests.get(url,headers=ua,timeout=3.0)
rqg.encoding = chardet.detect(rqg.content)['encoding'] #requests请求过程
#初始化HTML
html = rqg.content.decode('utf-8')
html = etree.HTML(html,parser=etree.HTMLParser(encoding='utf-8'))
安装途径:
pip install lxml
Xpath常用表达式
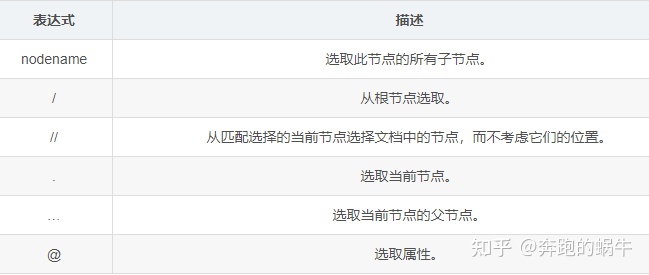
使用表达式定位head和title节点
result = html.xpath('head') #通过名称定位head节点
result1 = html.xpath('/html/head/title') #按节点层级定位title节点
result2 = html.xpath('//title') #另一种方式定位title节点
Xpath谓语常用的表达式
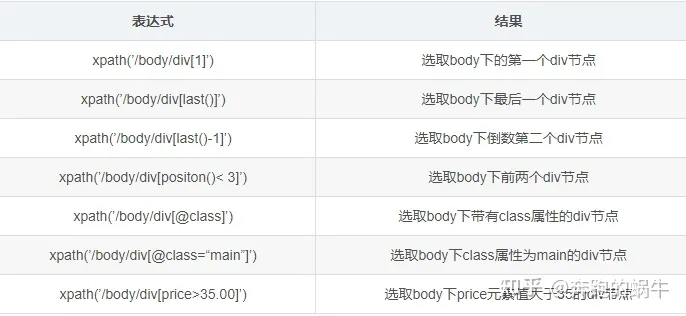
使用谓语定位head和ul节点
result1 = html.xpath('//header[@class]') #定位header节点
result2 = html.xpath('//ul[@id="menu"]') #定位ul节点
定位并获取title节点内的文本内容
title = html.xpath('//title/text()')
提取ul节点下的所有文本文件和链接地址
connect = html.xpath('//ul[starts-with(@id,"me")]/li//a/text()') #需for循环输出文本文件
url_list = html.xpath('//ul[starts-with(@id,"me")]/li//a/@href') #需for循环输出链接地址
XPath的解析语法稍显复杂,不过熟悉了语法的话也不失为一种优秀的解析手段。
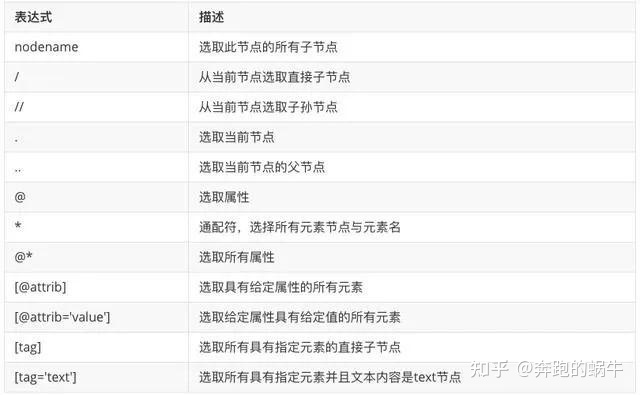
常用的语法规则
示例:
import requests
from lxml import etree
url = "https://movie.douban.com/"
ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240"
with requests.request('GET',url,headers = {'User-agent':ua}) as res:
content = res.text #获取HTML的内容
html = etree.HTML(content) #分析HTML,返回DOM根节点
#path = //div[@class='billboard-bd']//td//a/text()
orders = html.xpath("//div[@class='billboard-bd']//tr/td[@class='order']/text()")
titles = html.xpath( "//div[@class='billboard-bd']//td//a/text()") #使用xpath函数,返回文本列表
print(orders)
print(titles)
ans = dict(zip(orders,titles)) #豆瓣电影之本周排行榜
for k,v in ans.items():
print(k,v)
3、requests-html
我们知道 requests 只负责网络请求,不会对响应结果进行解析,因此可以把 requests-html 理解为可以解析 HTML 文档的 requsts 库。
requests-html 的代码量非常少,都是基于现有的框架进行二次封装,开发者使用时可更方便调用,它依赖于 PyQuery、requests、lxml 等库。
安装途径:
pip install requests-html
需要注意的是这个库目前只支持python3.6版本;
requests-html 具有以下特性:
- 完全支持 JavaScript
- CSS 选择器
- XPath 选择器
- 模拟用户代理(如同真正的网络浏览器)
- 自动跟踪重定向
- 连接池和 cookie 持久化
requests-html默认使用session保持的请求方式,且其返回内容是一个带有丰富方法的对象。
获取一个随机User-Agent
不用每次在请求头里面去复制user-agent;
# 自动生成一个useragent,默认为谷歌浏览器风格
user_agent = requests_html.user_agent()
对JavaScript的支持是requests-html最大的亮点,会用到render函数,需要注意的是第一次使用这个方法,它会先下载Chromium,然后使用Chromium来执行代码,但是下载的时候可能需要一个梯子,这里就先不展开讨论了。
学过requests库的看到requests-html的api应该会很熟悉,使用方法基本一致,不同的是使用requests编写爬虫时,要先把网页爬取下来,然后再交给BeautifulSoup等一些html解析库,现在可以直接解析了。
示例:
from requests_html import HTMLSession
session = HTMLSession()
def parse():
r = session.get('http://www.qdaily.com/')
# 获取首页新闻标签、图片、标题、发布时间
for x in r.html.find('.packery-item'):
yield {
'tag': x.find('.category')[0].text,
'image': x.find('.lazyload')[0].attrs['data-src'],
'title': x.find('.smart-dotdotdot')[0].text if x.find('.smart-dotdotdot') else x.find('.smart-lines')[0].text,
'addtime': x.find('.smart-date')[0].attrs['data-origindate'][:-6]
}
通过简短的几行代码,就可以把整个首页的文章抓取下来。
示例中使用的几个方法:
① find( ) 可以接收两个参数:
第一个参数可以是class名称或ID第二个参数first=True时,只选取第一条数据
② text 获取元素的文本内容
③ attrs 获取元素的属性,返回值是个字典
④ html 获取元素的html内容
使用requests-html来解析内容的好处在于作者都高度封装过了,连请求返回内容的编码格式转换也自动做了,完全可以让代码逻辑更简单直接,更专注于解析工作本身。
4、正则表达式
正则表达式通常被用来检索、替换那些符合某个模式的文本,所以我们可以利用这个原理来提取我们想要的信息。
使用正则表达式, 需要导入re模块,该模块为Python提供了完整的正则表达式功能。
严格的字符匹配示例:
- 查找
import re
example_obj = "1. A small sentence. - 2. Another tiny sentence. "
re.findall('sentence',example_obj)#第一个参数为想要查找的字符,第二个参数为被查找的句子
re.search('sentence',example_obj)
re.sub('sentence','SENTENCE',example_obj)
re.match('.*sentence',example_obj)
注意:python只支持re模块进行正则表达式的书写
import re
string = "1. A small sentence. - 2. Another tiny sentence."
- findall():该方法一般用的比较多
re.findall('sentence',string)#把所有符合要求的提取出来
>>>['sentence', 'sentence']
- search()
re.search('sentence',string)#只返回一个位置(第一个找到就停止搜索)可能遍历更快
>>><_sre.SRE_Match object; span=(11, 19), match='sentence'>
- match()
re.match('sentence',string)#该方法必须被查询语句的首字母就为查询字段,此时才会有相应结果的返回
- 替换:sub(pattern, repl, string)
- 删除:将repl的参数换为空 ‘ ’
使用正则表达式查找网页内容中的title内容:
import requests
import chardet
import re
ua = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) Chrome/65.0.3325.181'}
rqg=requests.get(url,headers=ua,timeout=3.0)
rqg.encoding = chardet.detect(rqg.content)['encoding'] #requests请求过程
title_pattern = r'(?<=<title>).*?(?=</title>)'
title_com = re.compile(title_pattern,re.M|re.S) #接受规则
title_search = re.search(title_com,rqg.text) #使用正则表达式
使用正则表达式无法很好的定位特定节点并获取其中的链接和文本内容,而使用Xpath和Beautiful Soup能较为便利的实现这个功能。
正则就是编写麻烦,理解不容易,但是匹配效率很高,不过现在有很多现成的HTMl内容解析库之后,不太推荐再手动用正则来对内容进行匹配了,麻烦费时费力。
5、小结:
(1)正则表达式匹配不推荐,因为已经有很多现成的库可以直接用,不需要我们去大量定义正则表达式,还没法复用,尝试过正则表达式的小白就能体会,使用正则表达式来筛选网页内容是有多费劲,而且总是感觉效果不太好。
(2)BeautifulSoup是基于DOM的方式,简单的说就是会在解析时把整个网页内容加载到DOM树里,内存开销和耗时都比较高,处理海量内容时不建议使用。
BeautifulSoup不需要结构清晰的网页内容,因为它可以直接找到我们想要的标签,如果对于一些HTML结构不清晰的网页,它比较适合。
(3)XPath是基于SAX的机制来解析,不会像BeautifulSoup去加载整个内容到DOM里,而是基于事件驱动的方式来解析内容,更加轻巧。
不过XPath要求网页结构需要清晰,而且开发难度比DOM解析的方式高一点,推荐在需要解析效率时使用。
(4)requests-html 是比较新的一个库,高度封装且源码清晰,它直接整合了大量解析时繁琐复杂的操作,同时支持DOM解析和XPath解析两种方式,灵活方便,可以尝试。
除了以上介绍到几种网页内容解析方式之外还有很多解析手段,这里就暂不一一介绍了。