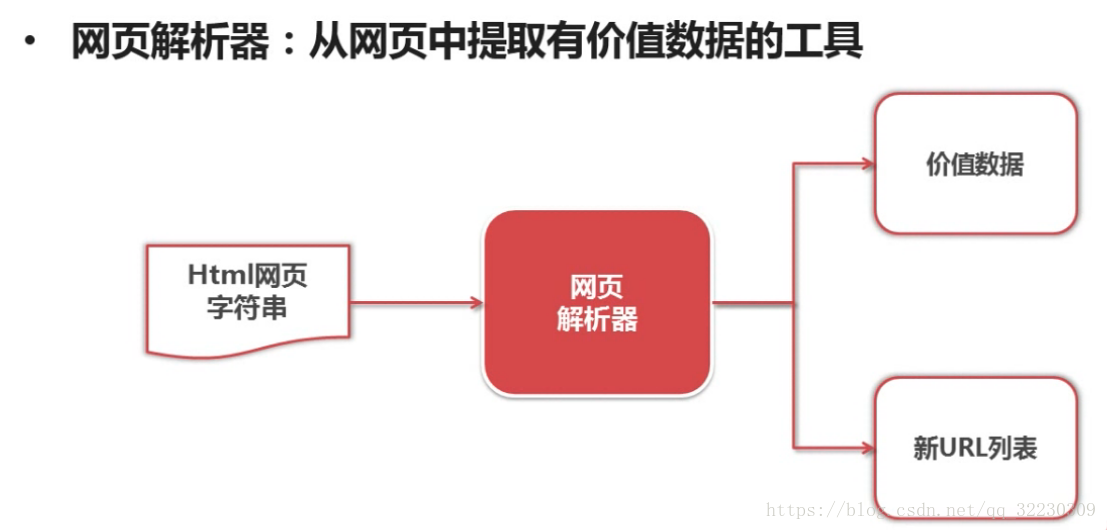
网页解析器:是从网页中提取有价值数据的工具
python 有四种网页解析器:
1 正则表达式:模糊匹配解析
2 html.parser:结构化解析
3 Beautiful Soup :结构化解析
4 lxml:结构化解析
其中 Beautiful Soup 功能很强大,有html.parse和 lxml的解析器.
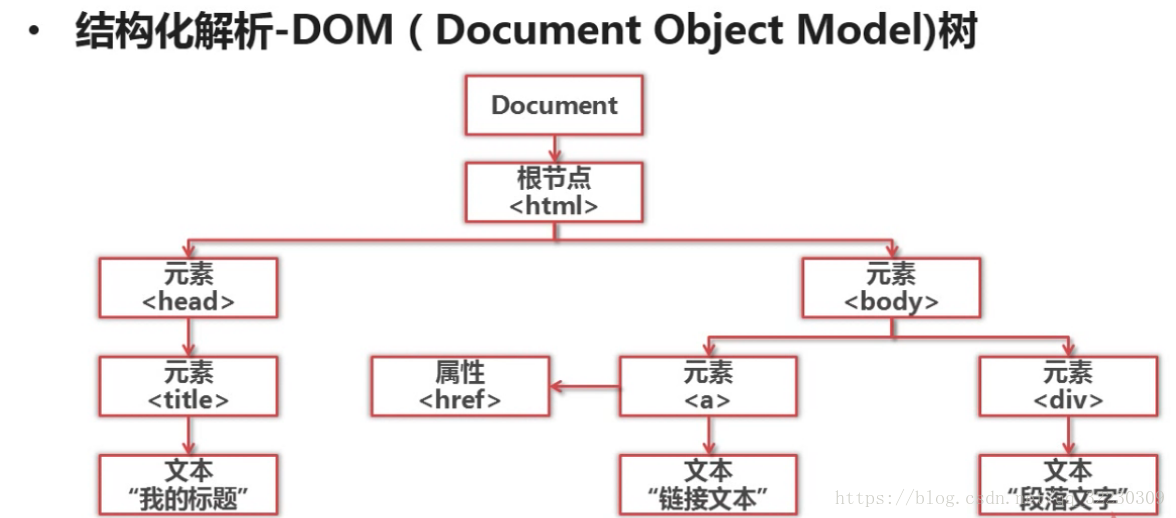
结构化解析-DOM(Document Object Model)树
下载 beautifulSoup
pip install beautifulsoup4
beautifulSoup 语法:
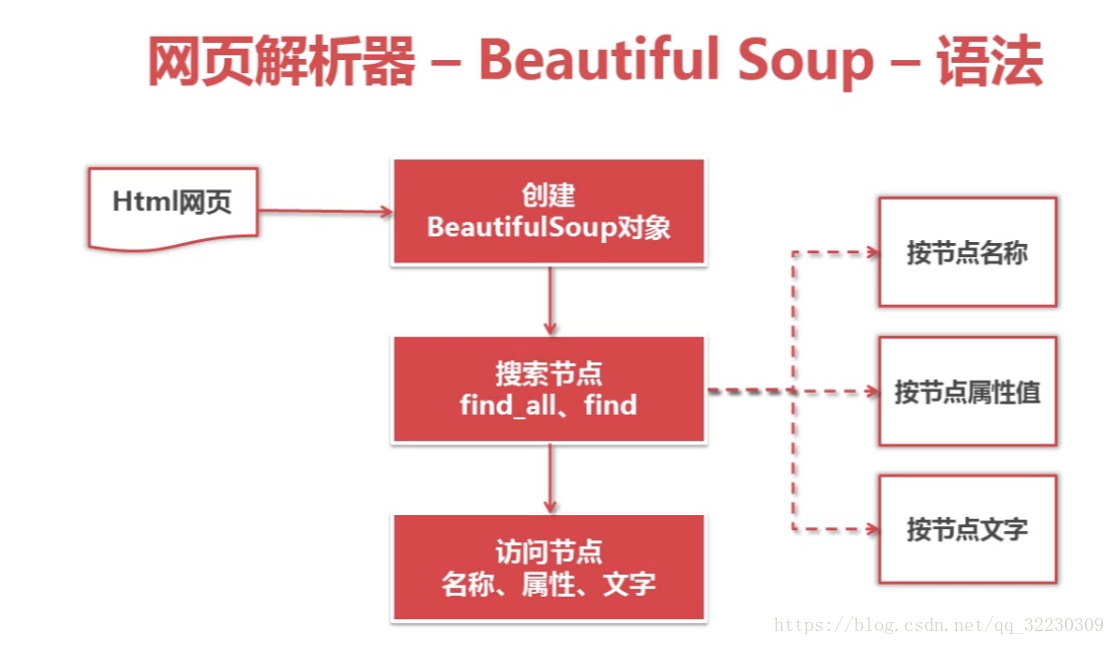
其中find_all方法会搜索满足要求的所有节点
find方法只会搜索第一个满足要求的节点
节点的介绍:

一 创建beautifulSoup对象

二 搜索节点
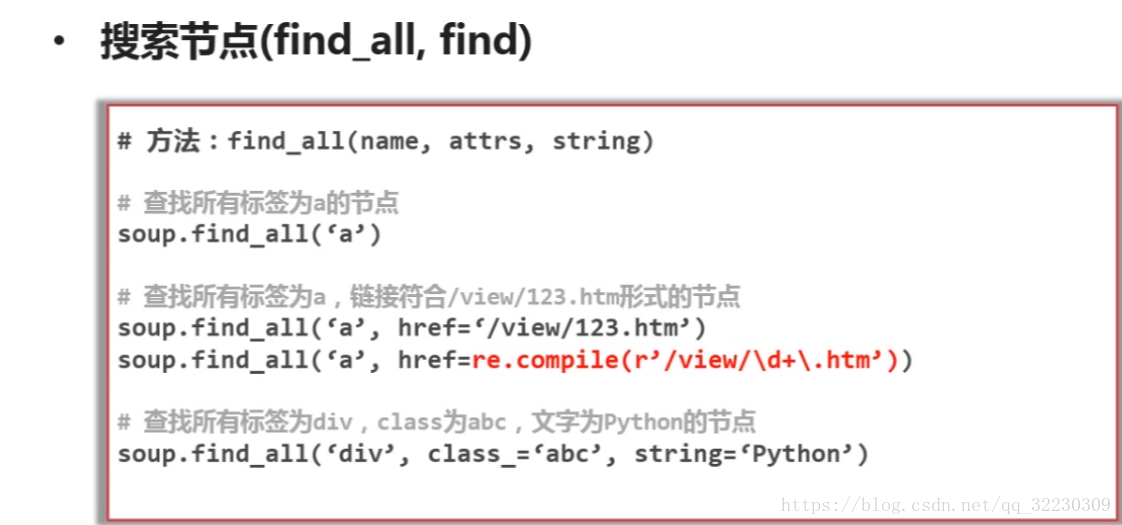
其中beautifulSoup有个强大的功能是 可以传入正则表达式来匹配的内容.
class_ 这里加一个下划线是因为避免与python关键字冲突所以用一个下划线.
三 访问节点信息

实例测试:
from bs4 import BeautifulSoup
import re
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup=BeautifulSoup(html_doc,'html.parser',from_encoding='utf-8')
print('获取所有链接')
links=soup.find_all('a')
for link in links :
print (link.name, link['href'],link.get_text())
print('获取Lacie链接')
linknode=soup.find_all('a',href='http://example.com/lacie')
for link in linknode :
print (link.name, link['href'],link.get_text())
print('正则匹配')
linknode=soup.find_all('a',href=re.compile(r'ill'))
for link in linknode :
print (link.name, link['href'],link.get_text())
print('获取P')
pnode=soup.find_all('p',class_='title')
for link in pnode :
print (link.name,link.get_text())
学习自:慕课网.