希尔排序
一.希尔排序的算法思想
希尔排序为属于插入排序的一种优化版本,在某些特定的情况下会让排序效率大大提升,它是一种不稳定的排序算法,它实现的基本思想是:将一个数组,按照一定的步长进行分治,分治之后再对分治出来的数组进行插入排序.
二.希尔排序的实现流程图
首先创建好一个数组
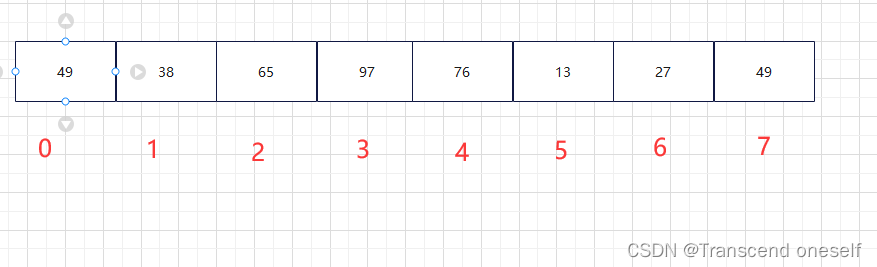
希尔排序的初始步长就是数组长度的一半,所以在使用希尔排序时,我们要先把数组的长度计算出来,当数组的长度为奇数时,我们的步长值向下取整就好了,比如长度为9,那么初始步长就是9/2向下取整就取得步长为4
第一趟循环
此刻我们的数组的长度是8,所以本次初始步长为8//2=4
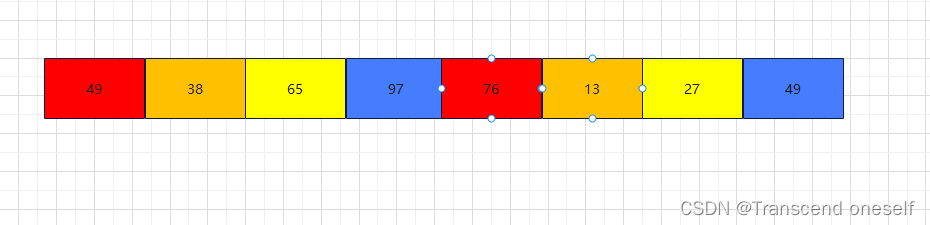
可以看到,当步长等于4时,会分治出4个子表,同颜色的为一个子表,然后通过插入排序对这四个子表进行排序
排序完后数据表为:

第二躺循环
此时我们就要再次把初始长度折半
所以此时的step = step/2=4/2=2
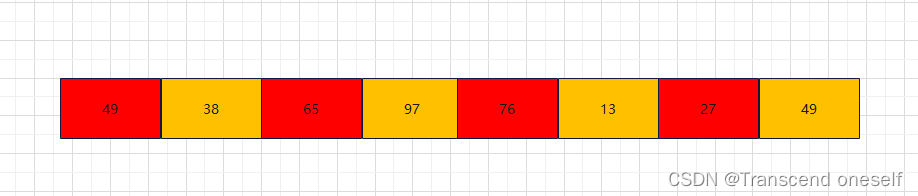
可以看到,当步长等于2时,会分治出2个子表,同颜色的为一个子表,然后通过插入排序对这2个子表进行排序
排序完后数据表为:

第三躺循环
此时我们就要再次把初始长度折半
所以此时的step = step/2=2/2=1
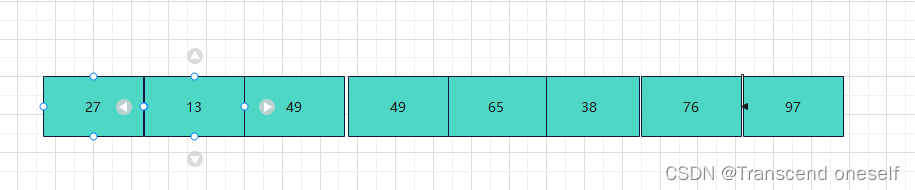
可以看到,当步长等于1时,会分治出1个子表,同颜色的为一个子表,然后通过插入排序对这1个子表进行排序
排序完后数据表为:

第四次循环步长就会开始小于0,此是分治的循环就要停止了,其实步长为1是就是将整个数组一次插入循环
三伪代码实现
void xier_sort(int arr[], int sz)
{
int step = 0;
int temp = 0;
int i, j;
for (step = sz / 2; step > 0; step /= 2)
{
for (i = temp; i < sz; i++)
{
temp = arr[i];//拿到第一个子表的值;
for (j = i - temp; j >= 0 && arr[j] > temp; j -= temp)
{
arr[j + temp] = arr[j];
}
arr[j + temp] = temp;//这里其实就相当于放在了j的位置,因为上面for循环有一个j-=temp变量递减,这里加一个temp抵消上面的-temp
}
}
}
四.代码思路
代码思路:定义step变量用来控制步长来分治数组.temp就是一个临时变量,他是用在做插入排序时需要的一个暂存单元,其实这里也可以用一个哨兵(arr[0]作为一个暂存单元)的写法,第一层循环就是用来对数组进行分治的,里面的两层循环就是实现了一个插入排序的效果若大家对插入排序还有不解之惑,可以看我上一篇插入排序的文章
插入排序文章链接:http://t.csdn.cn/EFLEk
五.时间复杂度和空间复杂度
时间复杂度:希尔排序的时间复杂度与增量(即,步长 step )的选取有关。例如,当增量为 1 时,希尔排序退化成了直接插入排序,此时的时间复杂度为 O(n),而Hibbard增量的希尔排序的时间复杂度为 O(n3/2)。
空间复杂度:O(1)
稳定性:由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以希尔排序是不稳定的。
五.总结:
希尔排序是直接插入排序的一种优化,可以用于数据量比较大的数组排序,从上面的时间复杂度可以分析得出,越是大的数组,越能体现出希尔排序的高效