一、概念及其介绍
希尔排序和插入排序很相似,有点像插入排序的升级版本。
希尔排序是希尔(Donald Shell)于1959年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破O(n2)的第一批算法之一。
希尔排序也是一种插入排序算法,只不过在插入排序上突破了结界,达到了另一种顶峰的存在,这种顶峰使得时间复杂度变成 O(n^(1.3-2))
希尔排序是通过分组+插入
二、复杂度
希尔排序时间复杂度是 O(n^(1.3-2)),空间复杂度为常数阶 O(1)。希尔排序没有时间复杂度为 O(n(logn)) 的快速排序算法快 ,因此对中等大小规模表现良好,但对规模非常大的数据排序不是最优选择,总之比一般 O(n^2 ) 复杂度的算法快得多。
三、过程演示
希尔排序目的为了加快速度改进了插入排序,交换不相邻的元素对数组的局部进行排序,并最终用插入排序将局部有序的数组排序。
在此我们选择增量 step = length / 2,缩小增量以 step = step / 2 的方式,用序列 {n/2,(n/2)/2…1} 来表示。
下面借用菜鸟教程的图
(1)初始增量第一趟 step = length / 2 = 4
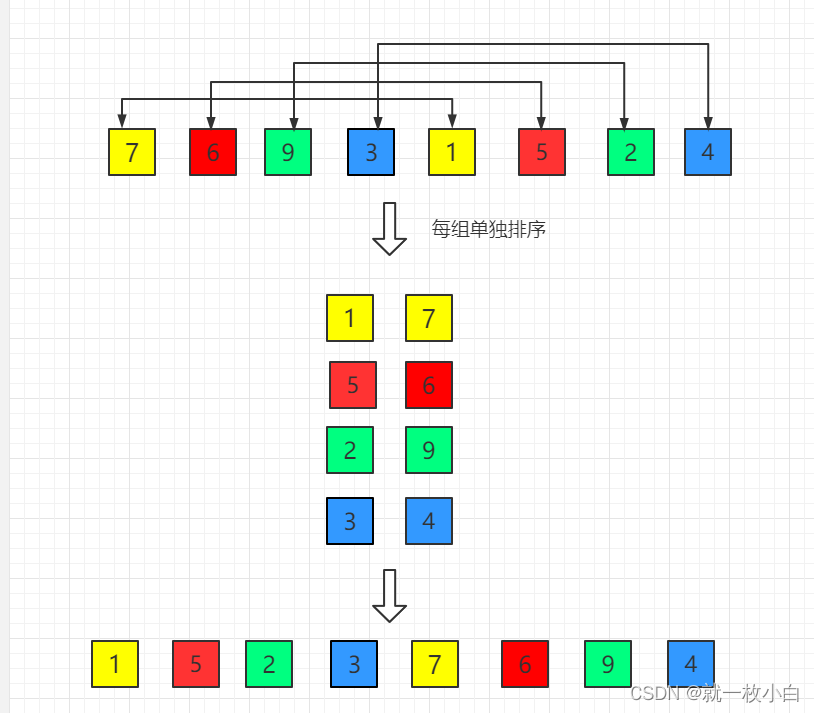
(2)第二趟,增量缩小为 2:step = step / 2
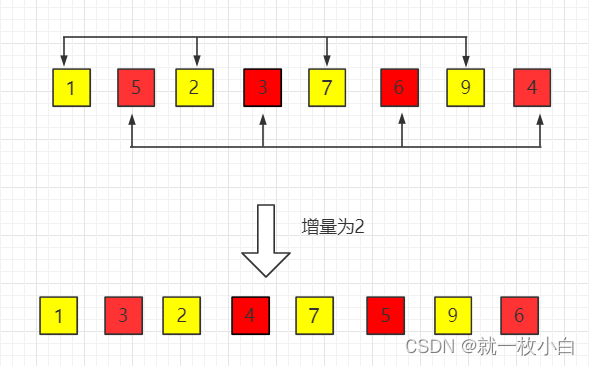
(3)第三趟,增量缩小为 1:step = step / 2。得到最终排序结果

代码实现
void shell_sort(int a[], int n) {
//首先枚举增量
for(int step = n / 2; step >= 1; step /= 2){
//在当前增量下,查找当前元素a[i]应该被插入的位置
for(int i = step; i < n; i++) {
int temp = a[i];//记录当前元素的值
int j;//j代表:以当前步长分割的数组的下标,所以不是"j - 1",而是"j - 增量"也就是"j - step"
//当前元素与前一个增量的元素作比较,如果小于前一个,那么就向后移动元素
for(j = i; j - step >= 0 && temp < a[j - step]; j -= step) {
a[j] = a[j - step];
}
//循环退出之后,也就是找到了当前元素应该放入的位置
//把比较元素放到当前下标,相当于插入
a[j] = temp;
}
}
}