目标检测任务非常有趣且具有挑战性。有些任务非常复杂,需要更多数据才能有所产出。但在这篇文章中,我将展示一个符号检测的小任务,它可以用更少的数据完成。该项目的目的是使用计算机视觉技术从一组给定的图像中提取文本并检测各种符号。
在这个任务中我们需要解决:
用于训练和推理的 torch (SSD MobileNet) 模型。
用于可视化的 cv2 和 matplotlib。
用于数据处理和存储的 NumPy 和 pandas。
NVIDIA Tesla T4 或 NVIDIA Tesla P100 GPU 配置。
使用 SSD MobileNet 进行符号检测
数据
数据非常少,我们总共有 7 个图像和 9 个符号(类),即我们的任务是在符号检测的基础上进行多分类。这将是一项具有挑战性的任务,因为与处理大数据集不同,我们正在用更少的数据解决问题,其中很少有如下:
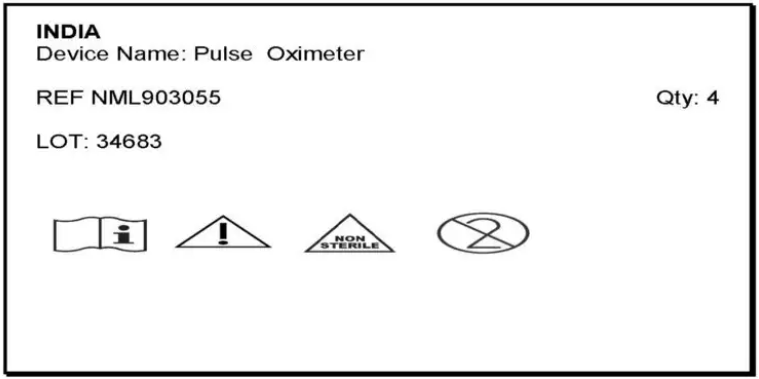
我们从中提取文本和所有符号的示例图像

示例符号
首先为我们的项目制定一个计划:
由于我们的数据较少,我们将使用一些图像增强技术并尝试生成数据。
我们将使用 SSD MobileNet 模型来训练我们的数据集。
我们将在训练中使用所有这些合成数据,并将使用其余六张原始图像作为验证集进行验证。
在我们的最后一步中,我们将使用 Paddle-OCR 从图像中提取文本。
文本详细信息包括设备名称、参考号、批号、数量等,这些详细信息将通过 excel 文件生成。
什么是 SSD MobileNet
在深入研究 SSD MobileNet 之前,让我们先了解什么是 SSD。
SSD 全称 Single Shot Detection,用于实时检测物体。
SSD 的两个主要组件是 Backbone model 和 SSD Head。
其中 Backbone model 通常是一个预训练的图像分类网络,充当整个模型的特征提取器。
SSD Head 只是添加到该 Backbone 的一个或多个卷积层,它将通过边界框坐标为我们提供所需对象的位置和类别。
对于我们的模型,我们将使用 MobileNet 作为我们的特征提取器。这就是它被称为 SSD MobileNet 模型的原因。
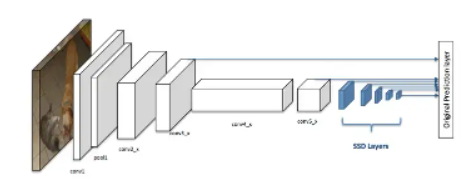
这张图有两部分,第一部分是白色方框,代表Mobile Net架构的网络,第二部分是蓝色方框,代表SSD head
生成合成数据:
我们将使用简单的数学方法进行数据合成。
首先,我们将从七张原始图像中获取一张图像,然后仅在这幅选定的图像上尝试我们的增强。
然后,我们将通过为特定符号位置提供随机符号来创建 7k 合成图像,从而使模型能够学习如何识别比正常情况更小的物体。
下面的代码将帮助我们生成 7k 图像并将它们保存在数据框中,其中包含符号详细信息(类别编号)及其相应的边界框。
import pandas as pd
import random
columns = ["filename","xmin","ymin","xmax","ymax","class"]
df = pd.DataFrame(columns=['filename', 'xmin', 'ymin', 'xmax', 'ymax', 'class'])
symbol_height = 70
symbol_width = 160
for count in range(7000):
synth_img = cv2.imread('/content/result_Page_7.jpg')
top, left = 435 , random.randint(-17,-15)+150
bottom , right = top + 70 , left +160
synth_img[(425):600, 100:750] = (255,255,255)
for i in range(5):
image = random.choice(glob('/content/symbols/*'))
img = cv2.imread(image)
img = cv2.cvtColor(img,cv2.COLOR_RGBA2BGR).astype(np.float32)
img = cv2.resize(img,(symbol_width,symbol_height))
synth_img[int(top):int(bottom), int(left):int(right)] = img
classes = (image.split(".")[-2].split('/')[-1])
row = ['augmented_98/'+ str(count)+'.jpg', left,top,right,bottom,classes]
df.loc[len(df.index)] = row
row = ['augmented_98/'+ str(count)+'.jpg', 1049,126,1244,227,4]
df.loc[len(df.index)] = row
left = right + random.randint(30,40)
right = left + symbol_width
if i == 3 :
top, left = 435 + 72 , symbol_width-10
bottom , right = top + symbol_height , (2*symbol_width)-10
cv2.imwrite('augmented_98/'+ str(count) +'.jpg',synth_img)具有六列的数据框,其中 xmin、ymin、xmax 和 ymax 是边界框坐标,而类(0 到 9)表示符号的编号。
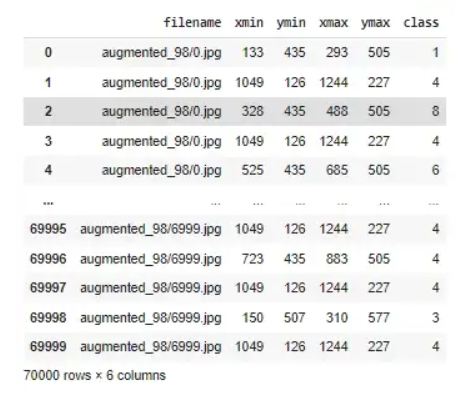
我们可以通过使用 matplotlib 库可视化图像来验证我们的数据,以在以下代码片段的帮助下检查我们的合成数据边界框是否正确。
def show_output_with_bbox(filename, bboxes, labels, transform):
image = cv2.imread(filename) # cv2.IMREAD_COLOR
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB).astype(np.float32)
image = image/255.0
aug_pipeline = get_aug_pipeline()
transformed = aug_pipeline(image=image, bboxes=bboxes, labels=labels)
img = transformed['image']
bboxes = torch.as_tensor(transformed['bboxes'])
bboxes = bboxes.detach().numpy()
labels = transformed['labels']
img_height = img.shape[1]
img_width = img.shape[2]
fig, ax = plt.subplots(figsize=(5,5))
ax.imshow(img.permute(1,2,0).numpy())
for bbox, class_name in zip(bboxes, labels):
xmin = bbox[0]
ymin = bbox [1]
width = bbox[2] - xmin
height = bbox[3] - ymin
rect = patches.Rectangle((xmin, ymin), width, height, linewidth=2, edgecolor='r', facecolor='none')
ax.add_patch(rect)
ax.text(xmin, ymin, class_name, color='w')
plt.show()
################################################################################
trainFiles = df['filename'].unique().tolist()
for filename in trainFiles[:3]:
records = df[df['filename']==filename]
bboxes = records[['xmin', 'ymin', 'xmax', 'ymax']].values
labels = records[['class']].values
labels = [x[0] for x in labels]
area = (bboxes[:,2]-bboxes[:,0]) * (bboxes[:,3]-bboxes[:,1])
show_output_with_bbox(filename, bboxes, labels, get_aug_pipeline())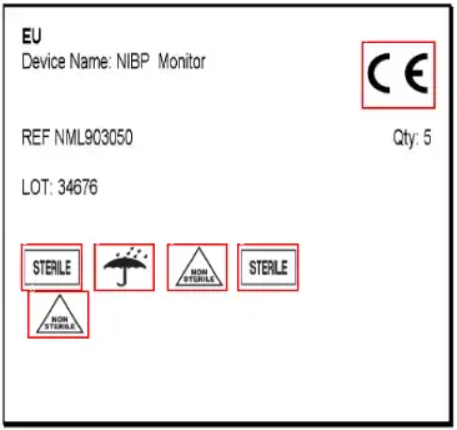
验证边界框是否正确
训练模型:
使用下面的代码片段,我们将能够从 torchvision 下载 ssdlite320_mobilenet_v3_large 模型,我们可以自定义模型以根据我们的要求进行分类,即总共 10 个类,包括一个背景类。
正如我们之前计划的那样,我们不会在训练时进行验证,我们将利用训练本身的所有数据。我们将 7k 图像设置 batch size 为 5 进行 25 个 epoch 的训练。
我们将学习率设置为 0.01,momentum 和 weight decay 分别设置为 0.9 和 0.0005。
SSD_MODEL = torchvision.models.detection.ssdlite320_mobilenet_v3_large(pretrained=False, num_classes=10)
torch.cuda.empty_cache()
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
if torch.cuda.is_available():
SSD_MODEL.cuda()
params = [p for p in SSD_MODEL.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.01, momentum=0.9, weight_decay=0.0005)
EPOCHS = 25
loss_stats = {
'train': [],
"val": []
}
# TRAINING
print("Begin training.")
for e in tqdm(range(EPOCHS)):
epoch_loss = []
SSD_MODEL.train()
for i, data in enumerate(train_data_loader):
images, targets = data
optimizer.zero_grad()
inputs = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
# pass input to model
loss_dict_train = SSD_MODEL(inputs, targets)
# loss
losses_train = sum(loss for loss in loss_dict_train.values())
epoch_loss.append(losses_train.item())
# backprop
losses_train.backward()
# update weights
optimizer.step()
#------====------#
# Epoch end - Training loss
train_loss_epoch = np.mean(epoch_loss)
loss_stats['train'].append(train_loss_epoch)
print(f'Epoch {e+0:03}: | Train Loss: {train_loss_epoch :.5f}')
torch.save({
'epoch': e,
'model_state_dict': SSD_MODEL.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}, f"/content/drive/MyDrive/Glove_6B/augmented_98.pth")
最后五个 epoch 的训练损失
让我们验证模型输出:
下面对原始图像的预测显示,模型在 20 个 epoch 后表现良好。
边界框与类名是准确的。
已捕获置信度得分(每个符号在 0 到 1 的范围内)。
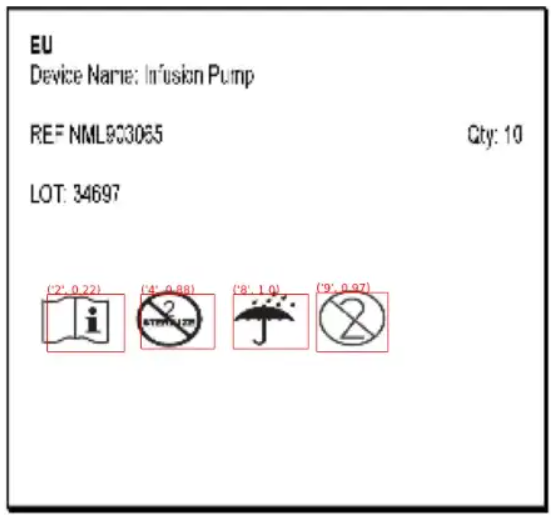
元组的第一个元素是类别编号,第二个元素是置信度得分
使用 Paddle -OCR 进行文本提取:
什么是 Paddle-OCR:
在深入了解 Paddle-OCR 之前,让我们先了解什么是 OCR。
OCR(光学字符识别)用于将基于文本的文档检测为数字文档。它主要分为通用 OCR 和特定领域 OCR。
Paddle -OCR 是一款开源的通用 OCR 工具,使用“Paddle”算法(水平识别)检测文本,占用内存极少,支持多语言。
该模型可以识别静态和移动图片中的文本,而不管它们的方向和语言如何。识别的响应时间要少得多(ms)。
paddle -OCR 的用例:
在金融业务中,可以用于支票簿、发票、个人报表、收据等业务单据的信息提取。
工厂自动化用于冲压和读取带有序列号的雕刻零件,以避免生产线出错。
在政府业务中,在机场,它用于护照识别和信息提取。它也可以用于交通标志识别。
让我们进行编程并提取一些细节:
Python 通过在一行代码中实现模型使我们的生活变得轻松。下面的代码片段展示了我们如何从 Paddle -OCR 模型创建一个对象并提取所需的信息,然后我们可以将其保存为我们想要的格式。
# READING TEXT FROM IMAGES USING PADDLE-OCR
result = ocr.ocr(image, cls=True)
for i in (result[0]):
if i[1][0].startswith("Device Name:"):
before_keyword1, keyword1, Device_name = i[1][0].partition('Device Name:')
device_Name_list.append(Device_name)
elif i[1][0].startswith("REF"):
before_keyword2, keyword2, REF = i[1][0].partition('REF')
REF_list.append(REF)
elif i[1][0].startswith("LOT:"):
before_keyword3, keyword3, LOT = i[1][0].partition('LOT:')
LOT_list.append(LOT)
elif i[1][0].startswith("Qty:"):
before_keyword4, keyword4, Qty = i[1][0].partition('Qty:')
Qty_list.append(Qty)
#CREATING DATAFRAME TO SAVE IN EXCEL FILE
data = pd.DataFrame(columns = ['Device Name','REF','LOT','Qty','Symbols'])
data['Device Name'] = device_Name_list
data['REF'] = REF_list
data['LOT'] = LOT_list
data['Qty'] = Qty_list
data['Symbols'] = symbol_list
data.to_excel("output.xlsx",index=False)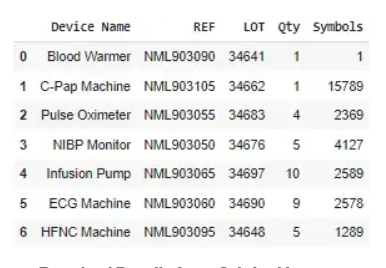
原始图像所需的详细信息
结论
在这个数字信息时代,如果需要,我们可以尝试使用人工智能解决每一个业务问题。
即使可用数据较少,我们也可以使用深度学习/机器学习技术来解决我们的问题。
· END ·
HAPPY LIFE
