一.栈的基本概念
1.栈的定义
栈(Stack):是只允许在一端进行插入或删除的线性表。首先栈是一种线性表,但限定这种线性表只能在某一端进行插入和删除操作。
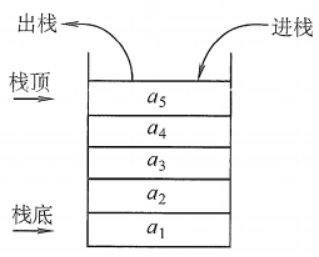
其中注意几点:
栈顶(Top):线性表允许进行插入删除的那一端。
栈底(Bottom):固定的,不允许进行插入和删除的另一端。
空栈:不含任何元素的空表。
栈又称为后进先出(Last In First Out)的线性表,简称LIFO结构

2.栈的常见基本操作
/ 支持动态增长的栈
typedef int STDataType;
typedef struct Stack
{
STDataType* _a;
int _top; // 栈顶
int _capacity; // 容量
}Stack;
// 初始化栈
void StackInit(Stack* ps);
// 入栈
void StackPush(Stack* ps, STDataType data);
// 出栈
void StackPop(Stack* ps);
// 获取栈顶元素
STDataType StackTop(Stack* ps);
// 获取栈中有效元素个数
int StackSize(Stack* ps);
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
int StackEmpty(Stack* ps);
// 销毁栈
void StackDestroy(Stack* ps); 二.栈的顺序存储结构
1.栈的顺序存储
采用顺序存储的栈称为顺序栈,它利用一组地址连续的存储单元存放自栈底到栈顶的数据元素,同时附设一个指针(top)指示当前栈顶元素的位置。
若存储栈的长度为StackSize,则栈顶位置top必须小于StackSize。当栈存在一个元素时,top等于0,因此通常把空栈的判断条件定位top等于-1。
当然我们也可以把top初始化成零,这样top指针就指向栈顶的下一个元素,只不过我们在实现的时候依然是通过指针的偏移量来对栈顶的元素来进行访问,所以两种初始化都是可以的,都是先存数据在移动指针。
2.顺序栈的基本算法
#pragma once
#include <stdbool.h>
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
typedef int STDatatype;
typedef struct Stack
{
STDatatype* a;
int capacity;
int top; // 初始为0,表示栈顶位置下一个位置下标
}ST;
void StackInit(ST* ps);
void StackDestroy(ST* ps);
void StackPush(ST* ps, STDatatype x);
void StackPop(ST* ps);
STDatatype StackTop(ST* ps);
bool StackEmpty(ST* ps);
int StackSize(ST* ps);3.顺序栈的实现
#include "Stack.h"
void StackInit(ST* ps)
{
assert(ps);
//ps->a = NULL;
//ps->top = 0;
//ps->capacity = 0;
ps->a = (STDatatype*)malloc(sizeof(STDatatype) * 4);
if (ps->a == NULL)
{
perror("malloc fail");
exit(-1);
}
ps->top = 0;
ps->capacity = 4;
}
void StackDestroy(ST* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->top = ps->capacity = 0;
}
void StackPush(ST* ps, STDatatype x)
{
assert(ps);
//
if (ps->top == ps->capacity)
{
STDatatype* tmp = (STDatatype*)realloc(ps->a, ps->capacity * 2 * sizeof(STDatatype));
if (tmp == NULL)
{
perror("realloc fail");
exit(-1);
}
ps->a = tmp;
ps->capacity *= 2;
}
ps->a[ps->top] = x;
ps->top++;
}
// 20:20
void StackPop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
ps->top--;
}
STDatatype StackTop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
return ps->a[ps->top - 1];
}
bool StackEmpty(ST* ps)
{
assert(ps);
/*if (ps->top == 0)
{
return true;
}
else
{
return false;
}*/
return ps->top == 0;
}
int StackSize(ST* ps)
{
assert(ps);
return ps->top;
}4.测试程序
#include"stack.h"
void test(void)
{
ST ST1;
StackInit(&ST1);
StackPush(&ST1, 1);
StackPush(&ST1, 2);
StackPush(&ST1, 3);
StackPush(&ST1, 4);
while (!StackEmpty(&ST1))
{
printf("%d\n", StackTop(&ST1));
StackPop(&ST1);
}
StackDestroy(&ST1);
}
int main()
{
test();
}三.栈的链式存储结构
链栈
和顺序表一样,针对顺序栈的缺点,我们可以设计出链栈,采用链式存储的栈称为链栈,链栈的优点是便于多个栈共享存储空间和提高其效率,且不存在栈满上溢的情况。通常采用单链表实现,并规定所有操作都是在单链表的表头进行的。这里规定链栈没有头节点,指针Lhead指向栈顶元素,如下图所示。

2.链栈的定义
typedef struct Stack
{
Datetype x;//数据域
ST *next // 指针域
}ST;3.性能分析
链栈的进栈push和出栈pop操作都很简单,时间复杂度均为O(1)。
对比一下顺序栈与链栈,它们在时间复杂度上是一样的,均为O(1)。对于空间性能,顺序栈需要事先确定一个固定的长度,可能会存在内存空间浪费的问题,但它的优势是存取时定位很方便,而链栈则要求每个元素都有指针域,这同时也增加了一些内存开销,但对于栈的长度无限制。所以它们的区别和线性表中讨论的一样,如果栈的使用过程中元素变化不可预料,有时很小,有时非常大,那么最好是用链栈,反之,如果它的变化在可控范围内,建议使用顺序栈会更好一些。
四.共享栈(节省空间)
1.共享栈概念
利用栈底位置相对不变的特征,可让两个顺序栈共享一个一维数组空间,将两个栈的栈底分别设置在共享空间的两端,两个栈顶向共享空间的中间延伸,如下图所示:

两个栈的栈顶指针都指向栈顶元素,top0=-1时0号栈为空,top1=MaxSize时1号栈为空;仅当两个栈顶指针相邻(top0+1=top1)时,判断为栈满。当0号栈进栈时top0先加1再赋值,1号栈进栈时top1先减一再赋值出栈时则刚好相反。
2.设计一个共享栈
/*两栈共享空间结构*/
#define MAXSIZE 50 //定义栈中元素的最大个数
typedef DataType int; //ElemType的类型根据实际情况而定,这里假定为int
/*两栈共享空间结构*/
typedef struct{
DataType a[MAXSIZE];
int top0; //栈0栈顶指针
int top1; //栈1栈顶指针
}SqDoubleStack;