Mask RCNN 何凯明大神的经典论文之一,是一个实例分割算法,正如文中所说,Mask RCNN是一个简单、灵活、通用的框架,该框架主要作用是实例分割,目标检测,以及人的关键点检测。Mask RCNN是基于Faster RCNN的一种改进,增加一个FCN的分支。
1、Mask RCNN 网络架构
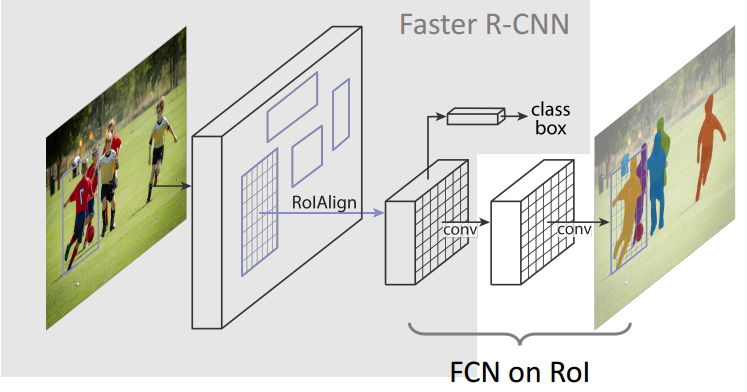
Mask RCNN就是Faster RCNN+FCN组成的,Faster RCNN完成分类和边框预测,FCN在筛选出的ROI中进行图像分割。损失函数由三部分组成:
Mask RCNN算法流程:
- 图像预处理操作,或者预处理后的图片;
- 输入到一个预训练好的神经网络中(ResNet)获得对应的feature map;
- 通过anchors对这个feature map中的每一点设定预定个的ROI,从而获得多个候选ROI;
- 将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI;
- 对这些剩下的ROI进行ROIAlign操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来);
- 对这些ROI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作)。
也就是说,Mask RCNN相对于Faster RCNN主要是两点改进,分别是FCN和ROI Align。
2、Faster RCNN网络
参考【原理篇】一文读懂Faster RCNN_Eyesleft_being的博客-CSDN博客
3、 FCN
FCN(Fully Convolutional Networks)全卷积网络是图像语义分割的一个经典网络,属于挖坑的,从此就有无穷无尽的人去填这个坑。
我们知道,CNN如AlexNet, ResNet等都是分类网络,都是给一个图像提取特征然后分类,很自然的可以想到,如果对图像的每一个像素点分类,不就可以进行图像分割了吗。实际上,FCN就是这样干的,每一个像素都分类为前景或者背景,就完成了图像分割。
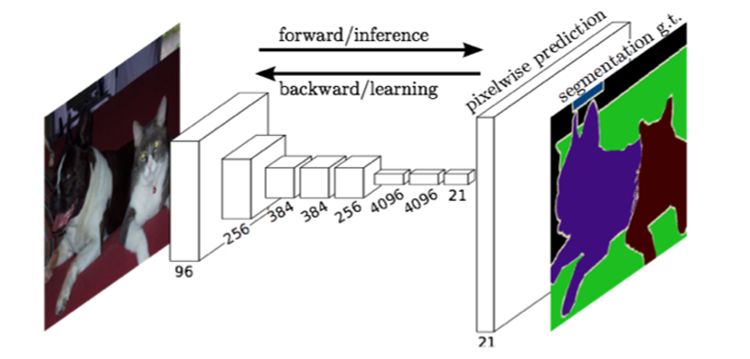
上图是FCN的整体网络架构图,从图中可以看出,所谓全卷积,就是不要全连接而已,因为网络要预测每一个像素的类别,最终的输出一定要是二维的才对,也就是heatmap图(对比CNN里的feature map)。实际上,完全可以把heatmap当作feature map来理解。
众所周知,卷积是一个下采样操作(卷积、池化)来提取抽象特征,在FCN中输入图像是H*W大小,经过一系列池化操作后最终变为H/32*W/32。
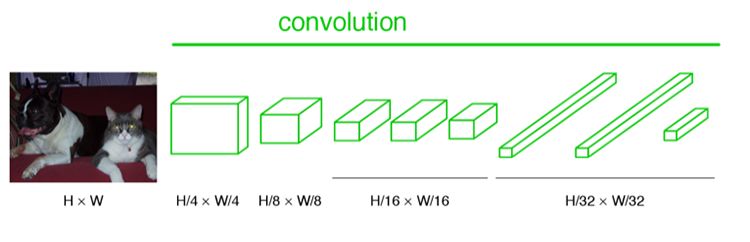
这样,同一个网络中,输入图像的尺寸就可以是任意的,最终只是缩放了多少倍而已。
现在的问题是,得到了抽象特征heatmap,比如要分类为1000类,heatmap的特征图大小就是H/32*W/32*1000。最终是要还原为H*W*1000才能预测输出的,也就是说在得到heatmap后,还需要上采样还原为H*W大小。
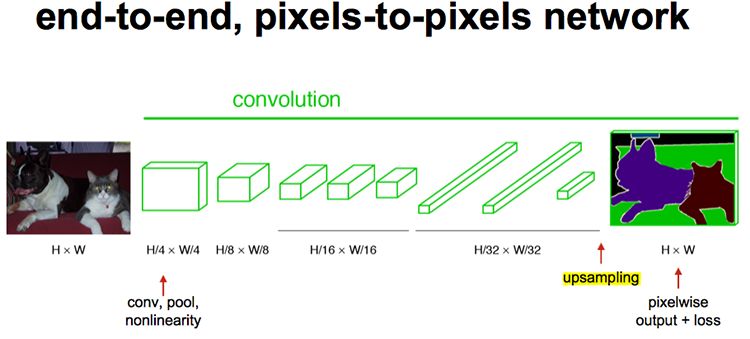
上采样
上采样就是增大图像分辨率,下采样就是缩小图像分辨率。在传统图像处理中,一般用插值算法做上采样,比如最近邻插值、双线性插值等。试想一下,如果采用插值的办法上采样,训练出的网络实际上heatmap就是概率图,每个特征点对应原图感受野的类别,然后插值算出来的概率,都是大概近似而已。这样得到的分割效果明显是不精确的。
转置卷积
可以联想到,如果能够训练参数,搞一个形式上类似反向卷积的东西,得到的网络应该就比较准确的,这个就是转置卷积。
先看看卷积操作,对于一个输入大小的图像,卷积核大小
,padding=0, stride=1,将得到
的输出,是多个像素映射为一个像素的函数,输出尺寸对应关系为:
其中,n为图像尺寸,p为padding,f为卷积核大小,s为stride
这一卷积过程可以通过变形表示为矩阵形式:
C为卷积核,x为图片。在这个例子中,输入为4*4,卷积核为3*3,输出为2*2,可以理解为x是16*1, C是4*16, 则y为4*1。那么从原理上,只要找一个尺寸16*4的矩阵,就能把4*1的向量映射为16*1,然后重新排列就行了。这是一个从少数对应多数的函数关系。
注意这里的转置只是一个形式上的转置操作,为了恢复到原始的尺寸,不是真正的求逆和转置操作。我们知道卷积其实是一种稀疏连接和参数共享,所以排列为矩阵后有很多零元素,转置也是一样,具有很多零元素,史迹上,转置卷积就是先给原图填充很多零元素,再进行正常卷积,就达到了上采样的效果。当然这里以少数到多数的映射是不能求解析解的,只能学习。
转置卷积的输出输入尺寸对应关系为:
现在再来看FCN的详细网络结构

网络过程归结如下:
- 图像H*W*3经过五层卷积提取抽象特征,五层分别下采样为1/2, 1/4, 1/8, 1/16, 1/32;
- 把全连接层变为卷积层,得到heatmap;
- 进行Transpose Convolution上采样层,这样可以上采样为2x,4x等与之前的下采样的特征进行特征融合;
- 输出最终预测结果H*W*class_num。
4、ROI Align
ROI Align是对应于ROI Pooling的优化。为了给所有的ROI获得同样尺寸的feature map,需要ROI池化,但在ROI池化中,非整数要进行量化操作(取整),这样会造成一定的误差。我们知道,feature map中的一个像素点对应于原图中较大的一块感受野,所以在feature map上的偏差,反映到原图中,将是比较大的误差,ROI Align就是用线性插值的方法代替了量化,从而解决了这个问题,提升了性能。
