
Midjourney 创作,未来AI机器人
欢迎来到人工智能应用的世界!在本文中,我们将探索使用React和强大的OpenAI平台创建图像生成器应用程序的激动人心机会。无论你是初学者还是经验丰富的开发人员,你都将学习如何利用机器学习的力量,只需几行代码即可生成令人惊叹的图像。从构建前端界面到集成OpenAI API,我们将为您逐步介绍整个过程。那么,让我们开始,发现如何使用OpenAI创建基于人工智能的React图像生成器应用程序!
项目设置
让我们通过使用Vite设置新的React应用程序来构建我们的基于人工智能的React图像生成器应用程序。确保在您的系统上安装了Node.js和Yarn,并开始执行以下命令:
$ yarn create vite接着,Vite将启动生成过程,并要求您输入一个项目名称:
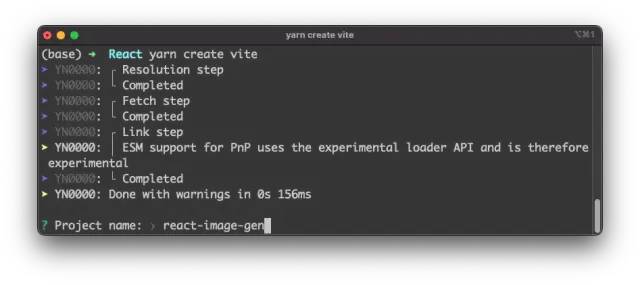
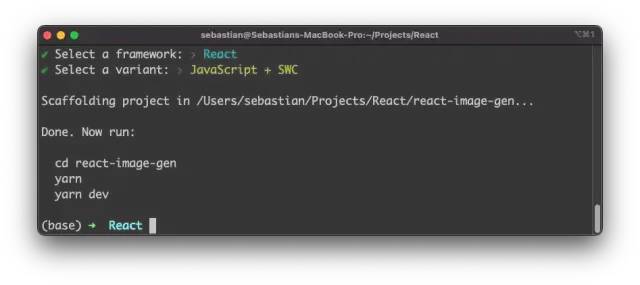
在下一步中,Vite会要求您选择一个框架。您可以使用键盘上的箭头键选择“React”选项,然后再次按回车键。最后,您需要决定使用哪个React项目。在本文的示例中,我们选择了“JavaScript + SWC”选项。
延伸阅读:什么是JavaScript + SWC?
"JavaScript + SWC" 是一个React项目的变体,其中 "SWC" 是指一个JavaScript编译器。在这个配置中,SWC编译器将用于编译JavaScript代码,以提高React应用程序的性能和执行效率。相比较于其他选项,例如 "TypeScript" 或者 "JavaScript + Babel",使用 "JavaScript + SWC" 可以获得更好的性能和更快的编译速度。
使用以下命令进入新生成的项目文件夹:
$ cd react-image-gen
在该文件夹中执行 "yarn" 命令,确保所有依赖项都被下载并安装在项目文件夹中:
$ yarn
此外,我们需要确保将 "openai" 包添加到React项目中,以便能够访问OpenAI API:
$ yarn add openai输入以下命令,可以启动开发Web服务器:
$ yarn dev
一旦服务器启动,您应该能够在浏览器中看到此默认项目:
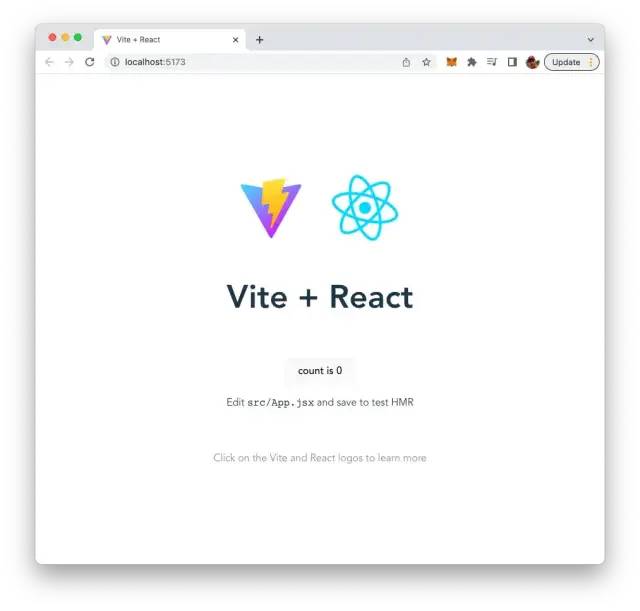
清理原有代码
让我们清理默认代码。打开 src/App.jsx 并删除除以下基本 App 组件结构以外的所有内容:
import { useState } from 'react'
import './App.css'
function App() {
return (
<div className="App">
<h1>React AI Image Generator</h1>
<div className="card"></div>
<p className="read-the-docs">
Powered by OpenAI
</p>
</div>
)
}
export default App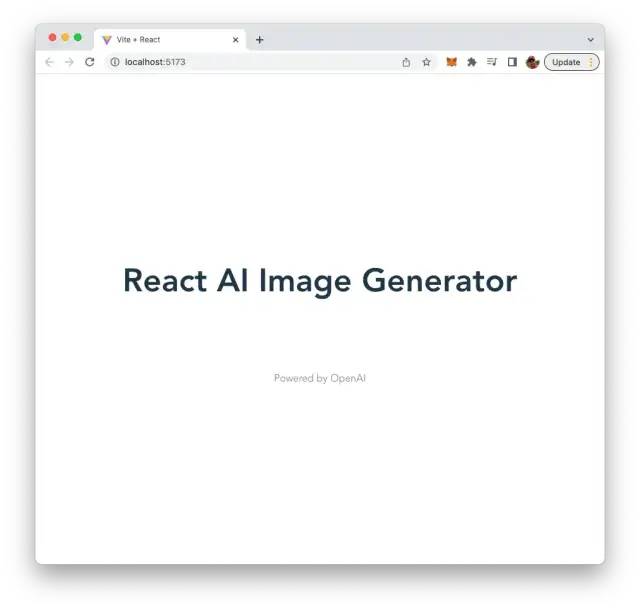
应用程序的实现
现在是时候开始实现React应用程序了。
首先,在 App.jsx 顶部插入另一个导入语句:
import { Configuration, OpenAIApi } from 'openai'该代码从 openai 包中导入了两个对象,Configuration 和 OpenAIApi。接下来,在 App 组件内部插入以下代码:
const [prompt, setPrompt] = useState('')
const [result, setResult] = useState('')
const [loading, setLoading] = useState(false)该代码使用 useState hook 在 App 组件中定义了三个状态变量。
prompt 是一个字符串状态变量,最初设置为空字符串。它用于存储将发送给 OpenAI API 以生成图像或文本的文本提示。
result 也是一个字符串状态变量,最初设置为空字符串。它用于存储发送提示后由 OpenAI API 返回的结果。
loading 是一个布尔状态变量,最初设置为 false。它用于指示当前是否正在进行与 OpenAI API 的请求。当 loading 设置为 true 时,表示请求正在进行中,而当它设置为 false 时,表示请求已完成或尚未启动。
useState hook 是一个内置的React hook,允许您向函数组件添加状态。它返回一个包含当前状态值和更新状态值的函数的数组。setPrompt、setResult 和 setLoading 函数用于更新它们各自的状态变量。
让我们继续实现,并将以下代码添加到 App 组件中:
const configuration = new Configuration({
apiKey: import.meta.env.VITE_OPENAI_API_KEY,
})
const openai = new OpenAIApi(configuration);该代码创建了两个对象,configuration 和 openai。
configuration 是从 openai 包导入的 Configuration 类的一个实例。它需要一个对象作为参数,该对象具有一个名为 apiKey 的属性。该属性的值是从
import.meta.env.VITE_OPENAI_API_KEY 变量中获取的。
VITE_OPENAI_API_KEY 包含用于访问OpenAI API的API密钥。为了使此环境变量可用,您需要在React项目的根文件夹中创建一个名为 .env 的新文件。在该文件中,您需要按以下方式设置此环境变量为您的个人OpenAI API密钥:
VITE_OPENAI_API_KEY=[INSERT YOUR OPENAI API KEY HERE]要检索您的OpenAI API密钥,您需要在 https://openai.com/ 上创建一个用户帐户,并在OpenAI仪表板中访问API密钥部分以创建一个新的API密钥。
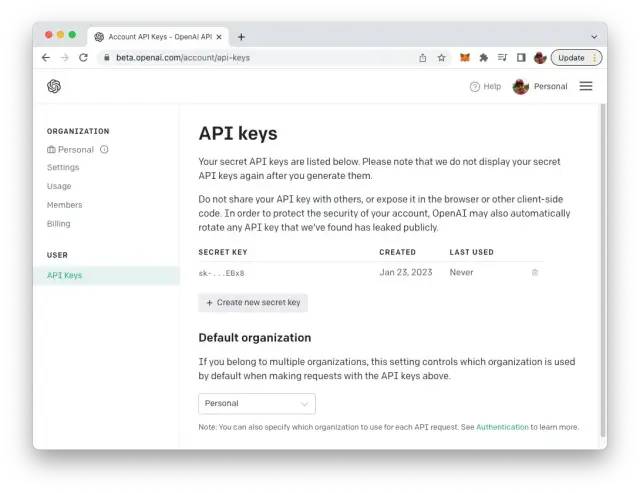
OpenAIApi 也是从 openai 包中导入的一个类。openai 是该类的一个实例,它是通过传递配置对象作为参数来创建的。
Configuration 类用于设置OpenAI API的必要配置,例如API密钥。OpenAIApi 类用于与OpenAI API交互,例如发送请求以生成图像或文本。
然后将配置对象作为参数传递给 OpenAIApi 类的构造函数,创建一个该类的实例,可用于与 OpenAI API 交互。
现在,让我们在 App 组件中创建一个用于生成图像的函数:
// 定义一个生成图像的异步函数
const generateImage = async () => {
// 开始请求,设置 loading 为 true
setLoading(true)
// 调用 OpenAI API 创建图像,使用 prompt、n 和 size 作为参数
const response = await openai.createImage({
prompt: prompt, // 文本提示
n: 1, // 生成图像的数量
size: "512x512", // 生成图像的大小
})
// 请求结束,设置 loading 为 false
setLoading(false)
// 从响应数据中获取图像的 URL,存储到 result 状态变量中
setResult(response.data.data[0].url)
}该代码定义了一个名为 generateImage 的函数,它是一个异步函数,用于向 OpenAI API 发送请求,根据用户提供的提示生成图像。
该函数首先使用 setLoading 函数将 loading 状态变量设置为 true,以指示请求正在进行中。接下来,它使用 openai.createImage 方法(OpenAIApi 类提供的方法)向 OpenAI API 发送请求。请求包含提示、n(要生成的图像数量)和图像大小。一旦收到响应,该函数使用 setLoading 函数将 loading 状态变量设置为 false,以表示请求已完成。然后,它使用 setResult 函数使用生成的图像的 URL 更新 result 状态变量。该 URL 可以用于在前端显示图像。最后,我们需要扩展从 App 组件返回的 JSX 代码,以构建用户界面:
return (
<div className="app">
<h1>React AI Image Generator</h1>
{/* 如果 loading 状态变量为 true,则显示正在生成图像的提示 */}
{loading ? (
<h2>正在生成图像,请稍候!</h2>
) : (
// 否则什么也不显示
<></>
)}
<div className="card">
{/* 输入文本框 */}
<textarea
className="text-input"
placeholder="输入提示"
onChange={(e) => setPrompt(e.target.value)}
row="5"
cols="50"
/>
{/* 生成图像按钮 */}
<button className="button" onClick={generateImage}>
生成图像
</button>
{/* 如果 result 状态变量中有图像的 URL,则显示生成的图像 */}
{result.length > 0 ? (
<img className="result-image" src={result} alt="生成的图像" />
) : (
// 否则什么也不显示
<></>
)}
</div>
<p className="footer">Powered by OpenAI</p>
</div>
)这个 JSX 代码定义了渲染 React 应用程序用户界面的组件的结构。它返回一个 class 为 "app" 的 div 元素。它包含一个带有文本 "React AI Image Generator" 的标题 h1,它是应用程序的标题。然后它有一个三元运算符,它检查 loading 状态变量的值。如果为 true,则显示一个带有文本 "正在生成图像,请稍候!" 的 h2 元素,表示正在进行图像生成请求。如果为 false,则返回空的 JSX 元素 <></>。
在 div 元素内部,它有另一个 class 为 "card" 的 div 元素。该元素包含一个 textarea 元素,它用作文本输入区域,具有占位符 "输入提示" 和一个 onChange 事件,调用 setPrompt 函数并传递文本区域的值作为参数。它还包含一个带有 class 为 "button" 的 button 元素,当单击时,它调用 generateImage 函数。
然后它有另一个三元运算符,检查 result 状态变量的长度是否大于 0。如果为 true,则显示一个 img 元素,该元素是生成的图像,其 src 属性设置为 result 状态变量,并具有 alt 属性 "生成的图像"。如果为 false,则返回一个空的 JSX 元素 <></>。
这个 JSX 代码定义了组件的 UI,使用状态变量和函数来控制应用程序的 UI 和流程。
完整源代码
以下是 React AI Image Generator 应用程序的完整源代码:
import { useState } from 'react'
import { Configuration, OpenAIApi } from 'openai'
import './App.css'
function App() {
// 定义三个 state 变量,分别表示输入框中的提示,生成的结果图片 URL 和加载状态
const [prompt, setPrompt] = useState('')
const [result, setResult] = useState('')
const [loading, setLoading] = useState(false)
// 创建 Configuration 实例,用于配置 OpenAI API 的 API Key
const configuration = new Configuration({
apiKey: import.meta.env.VITE_OPENAI_API_KEY,
})
// 创建 OpenAIApi 实例,用于和 OpenAI API 进行交互
const openai = new OpenAIApi(configuration);
// 定义生成图片的异步函数
const generateImage = async () => {
setLoading(true) // 开始请求,将加载状态设为 true
// 发送请求并等待响应结果,结果中包含了生成的图片的 URL
const response = await openai.createImage({
prompt: prompt, // 提示文本
n: 1, // 生成图片的数量
size: "512x512", // 生成图片的大小
});
setLoading(false) // 请求结束,将加载状态设为 false
setResult(response.data.data[0].url) // 将响应结果中的图片 URL 存储到 state 变量 result 中
};
// 返回应用程序的 UI
return (
<div className="app">
<h1>ReactAI 图片生成器</h1>
{loading ? ( // 如果正在加载,则显示“图片生成中...”的提示
<h2> 正在生成图像,请稍候!</h2>
) : (<></>)}
<div className="card">
<textarea
className="text-input"
placeholder="输入提示词"
onChange={(e) => setPrompt(e.target.value)} // 当文本框的值改变时,更新 state 变量 prompt
row="5"
cols="50"
/>
<button className="button" onClick={generateImage}>生成图片</button> {/* 点击按钮时,调用异步函数 generateImage */}
{result.length > 0 ? ( // 如果有生成的图片,则显示图片
<img className="result-image" src={result} alt="Generated Image" />
) : (
<></>
)}
</div>
<p className="footer">
Powered by OpenAI
</p>
</div>
)
}
export default App这段代码是应用程序的CSS样式代码,用于定义应用程序中各个元素的样式和布局。(src/App.css:)
/* 根元素的样式 */
#root {
max-width: 1280px; /* 最大宽度为 1280 像素 */
margin: 0 auto; /* 自动居中 */
padding: 2rem; /* 上下左右内边距为 2 个 rems */
text-align: center; /* 文字居中 */
}
/* 应用程序的样式 */
.app {
display: flex; /* 设置弹性盒子 */
flex-direction: column; /* 垂直排列子元素 */
align-items: center; /* 子元素水平居中 */
}
/* 输入框的样式 */
.text-input {
height: 50px; /* 高度为 50 像素 */
width: 100%; /* 宽度为父元素的宽度 */
margin-bottom: 20px; /* 下边距为 20 像素 */
border: 2px solid lightgrey; /* 边框为 2 像素的浅灰色 */
padding: 10px; /* 内边距为 10 像素 */
font-size: 14px; /* 字体大小为 14 像素 */
border-radius: 5px; /* 圆角半径为 5 像素 */
}
/* 结果图片的样式 */
.result-image {
margin-top: 20px; /* 上边距为 20 像素 */
border: 2px solid lightgray; /* 边框为 2 像素的浅灰色 */
padding: 10px; /* 内边距为 10 像素 */
width: 100%; /* 宽度为父元素的宽度 */
}
/* 卡片的样式 */
.card {
padding: 2em; /* 上下左右内边距为 2 个 em */
display: flex; /* 设置弹性盒子 */
flex-direction: column; /* 垂直排列子元素 */
}
/* 底部文字的样式 */
.footer {
color: #888; /* 文字颜色为浅灰色 */
}测试应用程序
现在是时候测试我们的应用程序了。在浏览器中访问应用程序,您现在应该能够看到以下用户界面:
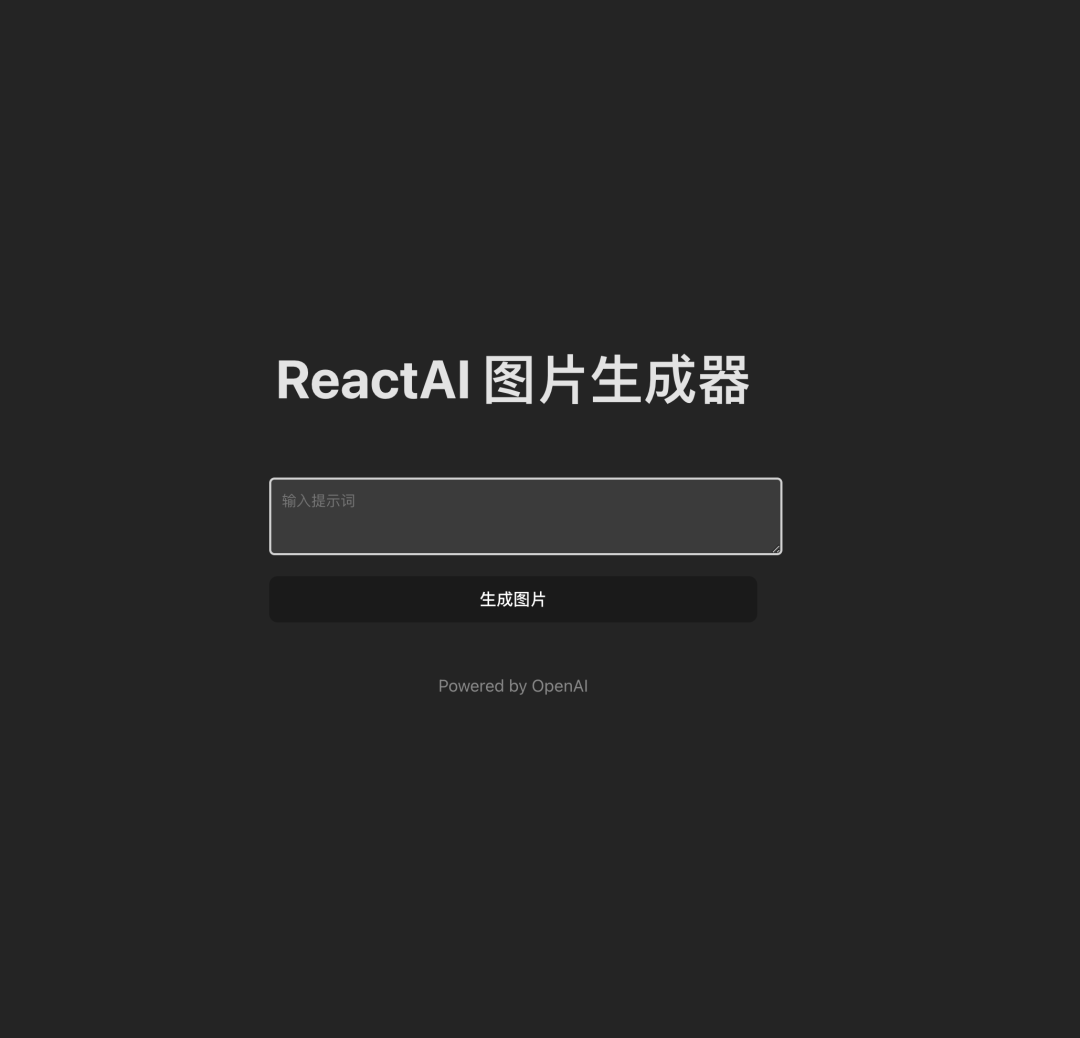
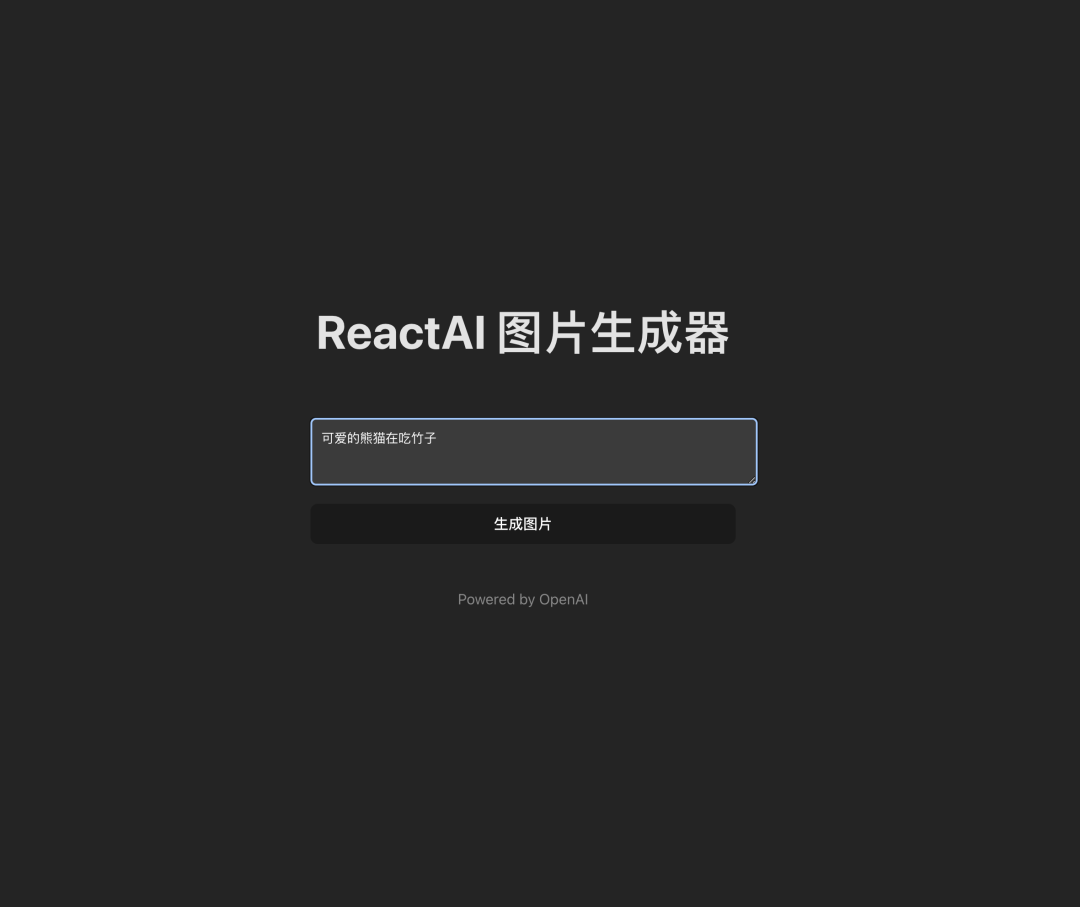
请尝试输入一个文本提示,描述您希望OpenAI生成的图片。(支持中文哦)
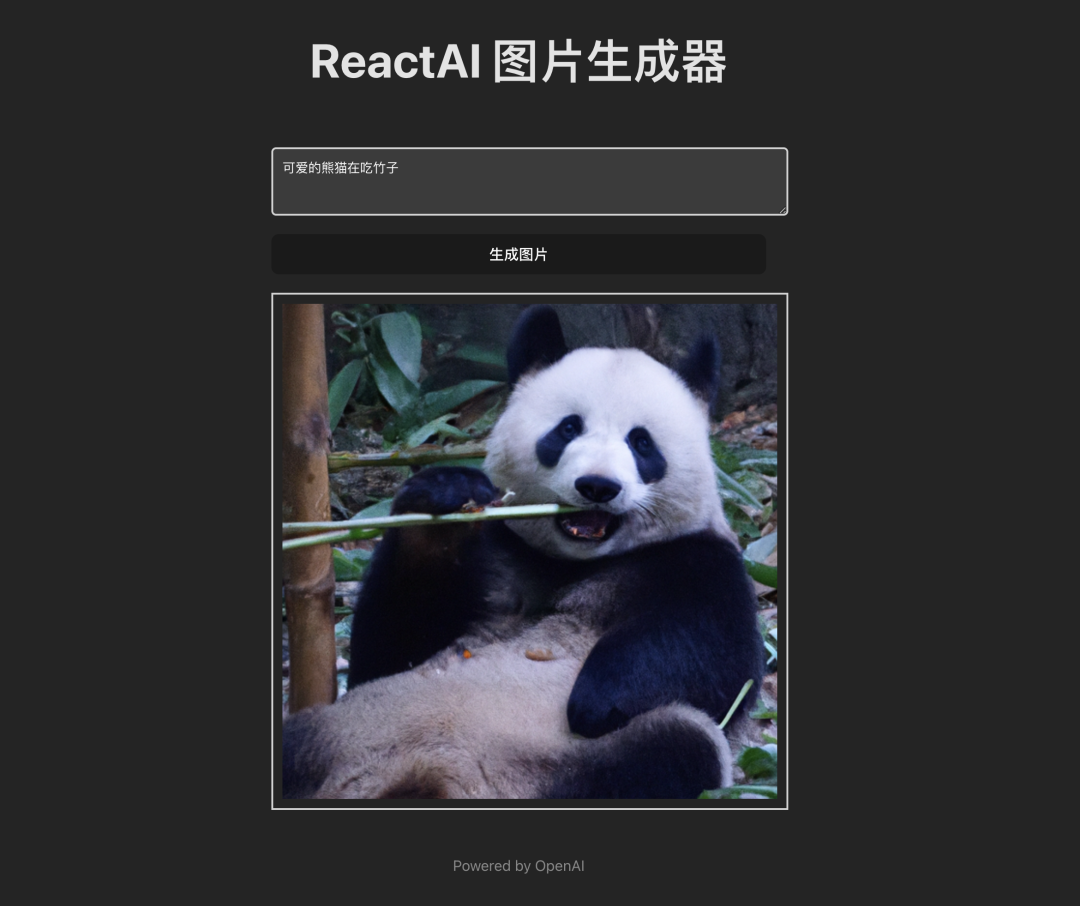
点击“生成图片”按钮,生成图片需要几秒钟时间,生成完成后您将在网页上看到生成的图片
是不是很有趣,虽然和Midjourney有差距,但不至于像百度那样,不知道付费的GPT4接口会怎么样,我使用的是免费的GPT3接口:
结束
本篇博客向你展示了如何使用OpenAI API在React中构建一个AI图像生成器应用。通过本篇博客,你学会了如何创建一个视觉上引人注目的前端界面,并使用OpenAI API生成图像。通过这个应用程序,你现在可以按需生成图像,并将它们用于各种应用程序,如社交媒体、营销活动甚至艺术项目。希望这篇教程对你有所帮助,激发了你对其他AI项目的实验兴趣。祝你编程愉快!
今天的分享就到这里,感谢你的阅读,希望能够帮助到你,文章创作不易,如果你喜欢我的分享,别忘了点赞转发,让更多有需要的人看到,最后别忘记关注「前端达人」,你的支持将是我分享最大的动力,后续我会持续输出更多内容,敬请期待。
原文:
https://medium.com/codingthesmartway-com-blog/create-an-ai-powered-react-image-generator-app-using-openai-79b575d6b808作者:Sebastian
非直接翻译,有自行改编和添加部分,翻译水平有限,难免有疏漏,欢迎指正