Abstract
学习过的图像压缩方法显示出比经典图像压缩标准更好的率失真性能。现有的大多数学习图像压缩模型都是基于卷积神经网络的。尽管做出了巨大贡献,但基于CNN的模型的一个主要缺点是其结构不是为捕捉局部冗余而设计的,尤其是非重复纹理,这严重影响了重建质量。因此,如何充分利用全局结构和局部纹理成为基于学习的图像压缩的核心问题。受视觉转换器(ViT)和Swin Transformer最新进展的启发,我们发现将局部感知注意机制与全局相关特征学习相结合可以满足图像压缩的期望。在本文中,我们首先广泛研究了多种注意机制对局部特征学习的影响,然后介绍了一种更简单有效的基于窗口的局部注意块。建议的基于窗口的注意非常灵活,可以作为即插即用组件来增强CNN和Transformer模型。此外,我们提出了一种新的对称变压器(STF)框架,在下采样编码器和上采样解码器中使用绝对变压器块。大量的实验评估表明,该方法是有效的,优于现有的方法。
1. Introduction
图像压缩是图像处理领域的一个基础和长期的研究课题。随着视觉应用的不断增加,有损图像压缩是在有限的硬件资源中高效存储图像和视频的重要技术。经典的有损图像压缩标准包括JPEG【44】、JPEG2000【40】、BPG【8】和VVC【9】遵循类似的编码方案:变换、量化和熵编码。然而,这些图像压缩标准在很大程度上依赖于手工制定的规则,这意味着它们不是图像压缩的最终解决方案。
近年来,基于变分自动编码器(VAE)[24]的学习图像压缩在信噪比(PSNR)和多尺度结构相似性指数度量(MS-SSIM)[46]指标上取得了比传统有损图像压缩方法更好的率失真性能[41],显示出巨大的实用压缩潜力。这里,我们将简要介绍基于VAE的方法的一般管道【5】。对于编码,基于VAE的图像压缩方法使用线性和非线性参数分析变换将图像映射到潜在代码空间。量化后,熵估计模块预测延迟的分布,然后基于无损上下文的自适应二进制算术编码(CABAC)[30]或范围编码器[31]将延迟压缩到比特流中。同时,超先验[6]、自回归先验[34]和高斯混合模型(GMM)[15]允许熵估计模块更精确地预测延迟的分布,并实现更好的率失真(RD)性能。对于解码,无损CABAC或距离编码器对比特流进行解压缩,然后通过线性和非线性参数合成变换将解压缩后的延迟映射到重构图像。此外,还有一些工作[21,27,48]设计后处理网络,以提高重建质量。结合以上顺序单元,可以对这些模型进行端到端的训练。尽管已经取得了很大的进展,但上述基于CNN的模型的一个核心问题是,原始卷积层是为高层次的全局特征提取而设计的,而不是为低层次的局部细节恢复而设计的。如图1右侧所示,即使是SOTA CNN模型也仍然受到较弱的局部细节学习能力的影响,这将不可避免地限制进一步的性能改进。
受自然语言处理(NLP)中注意机制和计算机视觉任务(如图像分类和语义分割)的成功启发,许多研究人员应用非局部注意机制来指导潜在特征的自适应处理,这有助于压缩算法将更多比特分配给具有挑战性的区域(即边缘、纹理),以获得更好的RD性能。然而,这种非局部关注仍然没有改变CNN结构固有的全局感知特性。最近的研究【13,18,29,42】表明,transformer【43】可以成功地应用于视觉任务,与卷积神经网络(CNN)相比,其性能更具竞争力。那些基于注意的网络,如Vision Transformer(18)和Swin Transformer(29)利用注意机制的优势来捕获全局依赖性。然而,我们直观地发现,图像压缩中的全局语义信息不如其他计算机视觉任务中的有效。相反,空间上相邻的元素具有更强的相关性。
在以上讨论的基础上,本文从两个方面探索解决细节缺失问题,即研究局部感知注意机制和引入一种新的基于transformer的框架。首先,我们全面研究了如何将神经网络与注意机制相结合来设计局部感知有损图像压缩结构。通过一组基于全局注意机制和局部注意机制的对比实验,我们验证了上述猜测,即局部注意更适合于局部纹理重建。然后,我们提出了一个灵活的注意模块,结合神经网络来捕获空间相邻元素之间的相关性,即窗口注意。如图1所示,建议的注意力模块可以作为即插即用组件来增强CNN和Transformer模型。第二,尽管基于transformer的模型在各种计算机视觉任务中取得了巨大成功,但将transformer模型应用于图像压缩仍然存在巨大挑战,例如,没有上采样单元,固定注意力模型。为此,我们提出了一种在下采样编码器和上采样解码器中使用绝对变换块的新型对称变换器(STF)框架,这可能是设计上采样变换器的首次探索,尤其是在图像压缩任务中。大量的实验结果表明,我们的方法在本质指标上优于最先进的(SOTA)图像压缩方法。本文的主要贡献总结如下:
我们广泛研究了局部感知注意机制,发现将神经网络学习到的全局结构与注意单元挖掘出的局部纹理相结合至关重要。
我们提出了一个灵活的基于窗口的注意模块来捕获空间相邻元素之间的相关性,它可以作为一个即插即用组件来增强CNN或Transformer模型。
我们设计了一种新的对称变换器(STF)框架,在下采样编码器和上采样解码器中都有绝对变换块。
2. Related Works
学习图像压缩。最近,基于CNN的学习图像压缩模型[5,6,15–17,19,27,32,34,35]呈现出快速发展的趋势,并取得了重大突破。对于基于VAE的体系结构,[5]首先提出了一种端到端的图像压缩优化模型。[6] 在基于[5]的潜在表示中加入了一个超优先,以有效捕获空间依赖关系。受概率生成模型中自回归先验成功的启发,[34]通过添加自回归分量进一步增强了[6]中的熵模型。除此之外,[15]还通过使用剩余块和添加一个简化的注意模块,用高斯混合模型(GMM)代替常用的单一高斯模型(SGM),增强了网络架构。虽然基于GMM的熵模型在RD性能上表现更好,但在编码和解码过程中,必须为每个元素动态生成所采用的概率分布函数(PDF)和累积分布函数(CDF),从而引入大量冗余并使其耗时。相比之下,基于SGM的熵模型可以为熵编码构建固定的PDF和CDF表,计算成本更低。为了最小化自回归上下文模型中的串行处理步骤,[35]提出了一种基于信道的自回归熵模型。一些方法[2,33]使用生成性对抗网络(GAN)直接了解图像的分布并防止压缩伪影。对于基于GAN的架构,图像压缩是一项率失真感知权衡任务。
注意机制。注意机制模仿生物观察的内部过程,将更多的注意力资源投入到关键区域,以获取更多细节并抑制其他无用信息。事实证明,非局部注意机制在各种视觉任务中都是有益的。对于学习图像压缩,[28]应用非局部注意生成隐式重要性遮罩,以指导潜在特征的自适应处理,而[15]通过移除非局部块简化了注意机制。
基于Transformer的模型。受Transformer体系结构在自然语言处理方面的成功启发,有许多作品探索了Transformer在计算机视觉任务中的潜力。[18] 使用transformer架构进行图像分类。[13] 在检测中实现基于转换器的模型。[14] 提出了一种通用的图像处理任务预训练方法。[29]提出了一种用移位窗口计算的层次变换器,并在图像分类、语义分割和目标检测方面实现了SOTA性能。然而,就我们所知,还没有与转换器相关的图像压缩工作。在本文中,我们探讨了如何设计一个基于转换器的体系结构,用于学习图像压缩,以实现可比较的RD性能。
神经网络中的归一化。广义分裂归一化(GDN)[4]是学习图像压缩的一个里程碑。GDN对自然图像的局部联合统计量进行高斯化是一种高效的方法。我们已经进行了一些比较实验,用批处理规范化(22)、层规范化(3)和通道规范化(33)代替GDN。我们发现,在CNN中替换GDN将导致RD性能大幅下降。然而,我们还发现GDN在基于深度转换器的体系结构中是不稳定的。此外,GDN与变压器模块中的注意机制不兼容。
3. Method
3.1. Formulation
由于我们的方法建立在hyper-prior architecture[6,34]和channel-wise auto-regressive entropy model[35]的基础上,因此为了更好地理解,我们将简要介绍基本管道。
编码器E将给定图像x映射到潜在y。经过量化Q后,y^ 是潜在y的离散表示。然后,使用解码器D将y^ 映射回重建图像x^。主要过程如下:
y = E ( x ; ϕ ) y ˇ = Q ( y ) x ˇ = D ( y ˇ ; θ ) y = E(x;\phi) \\ \check{y} = Q(y) \\ \check{x} = D(\check{y}; \theta) y=E(x;ϕ)yˇ=Q(y)xˇ=D(yˇ;θ)
其中,ϕ 和 θ是编码器E和解码器D的可训练参数。量化Q不可避免地引入潜在的削减误差 (error = y − Q(y),导致重建图像失真。继之前的工作【35】之后,在训练阶段,我们还通过舍入和添加预测的量化误差来修改量化误差。
我们通过引入边信息zi^ ,将每个元素yi^ 建模为单个高斯分布,其标准偏差σi和均值µi。yi^ 的分布p(yi^|zi ^) 由基于SGM的熵模型建模:
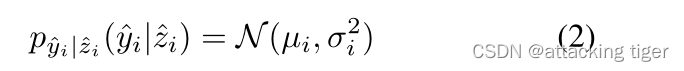
图像压缩模型的损失函数为:
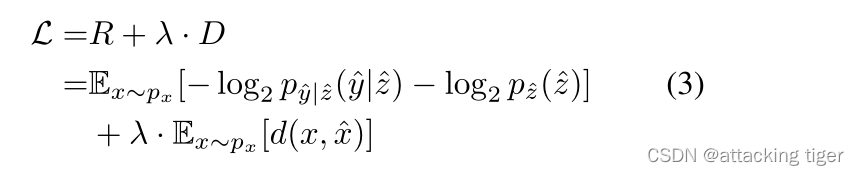
其中λ控制速率和失真之间的权衡,R是潜在表示 y ^和z ^的比特率,d(x,ˆx)是原始图像x和重建图像x ^之间的失真。

Figure 3. 最大熵信道的WAM、NLAM和W/o注意模块的可视化。它表明我们的WAM专注于高对比度区域(帆船),并在这些区域分配更多比特,而在低对比度区域(天空和云层)分配更少比特。相反,位在无注意模块和NLAM中均匀分配。
3.2. Window-based Attention
以前的大多数方法【15、28、49】都应用注意机制,基于全局感受野生成注意掩码。注意机制也被成功地应用于许多计算机视觉任务中,如图像分类、语义分割和目标检测。然而,从直觉上看,图像压缩中的全局语义信息并不像计算机视觉任务中那样实用。
Attention in Non-overlapped Windows。我们注意到,基于空间相邻元素生成注意掩码可以在计算成本较低的情况下提高RD性能。为了有效地建模和聚焦空间上相邻的元素,我们提出了基于窗口的注意力。如图2所示,以不重叠的方式将特征地图划分为M×M的窗口。我们分别计算每个窗口中的注意图,Xki和Xkj是第k个窗口中的第i个和第j个元素,如下所示:
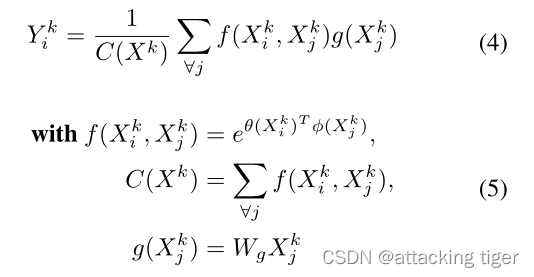
Window Attention Module。Liu等人[28]提出了非局部注意模块(NLAM),该模块由非局部块和规则卷积层级联而成。我们用窗口块代替非局部块来聚焦高对比度区域。图4(b)显示了我们的窗口注意模块(WAM)。我们将WAM、NLAM和W/o注意模块的熵最高的通道可视化,如图3所示。在第3列中,可以明显地看到,WAM可以在复杂区域(高对比度)分配更多比特,而在简单区域(低对比度)分配更少比特。此外,WAM重建图像具有更清晰的纹理细节。具有全局感受野的NLAM通常会导致比特在不同区域上的均匀分配,这与[28]中的预期不一致。
3.3. CNN-based Architecture
如图4所示,我们基于CNN的架构建立在[35]的基础上。我们通过分别插入所提出的WM来增强编码器和解码器。WMS有助于更合理地在不同区域内部分配位,而计算开销可以忽略不计。它可以显著提高研发绩效。
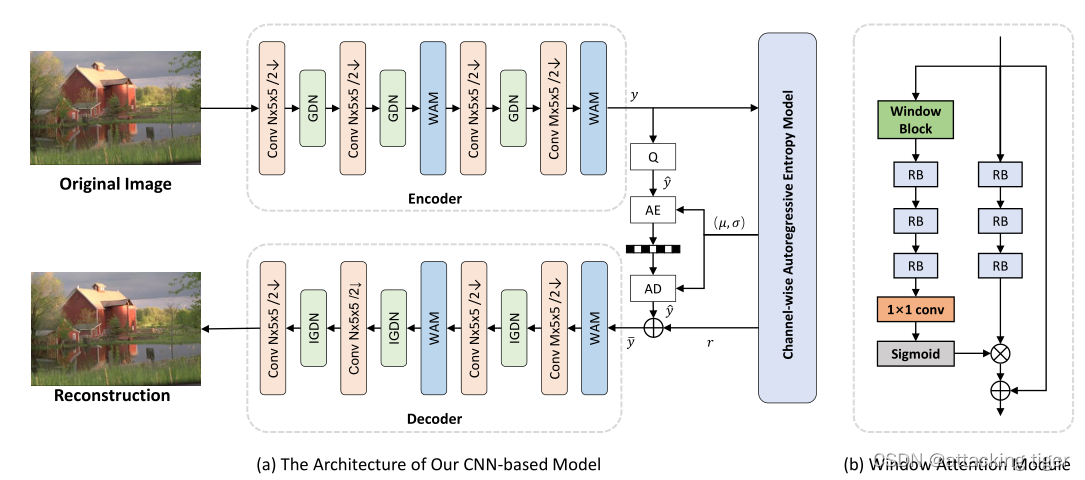
图4:(a) 我们提出的基于CNN的模型的体系结构。为了便于后续比较,我们采用了[35]中的架构。IGDN是反向GDN。(b) RB是由1×1和3×3卷积层组成的剩余块。
3.4. Transformer-based Architecture
受Transformer架构[18,29]在计算机视觉中的成功以及我们前面提到的local attention有助于合理分配位和提高RD性能的实验结果的启发,我们进一步提出了一种用于学习图像压缩的新型Transformer架构,如图5所示。
Rethinking the Transformer . 由于我们的目标是验证结合自注意力层和MLP是否可以实现与原始基于CNN的架构相当的性能,因此我们设计了一种新型的对称变换器(STF)框架,在编码器和解码器中没有卷积层。学习图像压缩设计Transformer模型的困难如下:
- 以前的工作大多基于CNN来消除空间冗余并捕获空间结构。直接将图像分割为面片可能会导致每个面片内的空间冗余。
- GDN是图像压缩中最常用的归一化和非线性激活函数。然而,GDN在深度Transformer架构中是不稳定的。此外,我们发现GDN和transformer中的注意机制是不兼容的
- 根据我们之前的分析和实验结果,在大范围内计算注意力图并不是最优的。
为了解决上述问题,我们选择了较小的patch大小,以避免每个patch内的空间冗余。我们使用LN进行归一化,这在Transformer中最常用。在我们的Transformer架构中,采用GELU作为非线性激活函数。受[29]的启发,我们在局部窗口内计算注意力图。我们的Transformer架构的优点是,它可以专注于空间相邻的面片,同时逐渐扩展感受野,具有可接受的计算复杂度。
4. Experiments
4.1. Experimental Setup
Training. 我们在CompressAI平台[7]中实现了我们提出的基于CNN的架构和基于transformer的架构。为了进行训练,我们从OpenImages数据集[26]中随机选择300k图像,并随机裁剪大小为256×256的图像。使用Adam优化器[23]对所有模型进行1.8M步的训练,批量大小为16。初始学习速率设置为1×10^(-4), 迭代120k次,下降到3×10 ^(−5)对于另一个30k迭代,1×10 ^(−5)用于最后30k次迭代。
我们的模型使用两个质量指标(MSE和MS-SSIM)作为监督进行优化。遵循[7]中的相同设置,当模型针对MSE进行优化时,λ值λ属于{0.0018、0.0035、0.0067、0.0130、0.025、0.0483}。当模型针对MS-SSIM进行优化时,lambda值λ属于{2.4、4.58、8.73、16.64、31.73、60.50}。
对于我们基于CNN的模型,潜在和超潜在的通道数分别设置为320和192。对于基于Transformer的模型,面片大小为2,窗口大小为4,通道数C为48。通常,我们的模型对于不同的λ具有相同的超参数。
Evaluation. 我们通过计算常用Kodak图像集[25]和CLIC专业验证数据集[1]上的平均RD性能(峰值信噪比和MS-SSIM)来评估基于CNN的模型和STF模型。我们将我们的方法与有影响力的学习压缩方法进行比较,包括上下文无关超先验模型(Ballé2018)[6]、自回归超先验模型(Minnen2018)[34]和具有GMM和简化注意力的自回归超先验模型(Cheng2020)[15]。RD曲线涵盖了广泛的传统压缩方法和基于人工神经网络的压缩方法,请参阅附录。
4.2. Comparison with the SOTA Methods
RD Performance. 图6显示了Kodak数据集上的比较结果。当训练均方误差并用峰值信噪比测量时,我们基于CNN的模型和STF模型的性能非常接近,可以优于其他学习的压缩方法。相反,当通过MS-SSIM进行训练和测量时,我们基于CNN的模型和STF模型只有轻微的改进。如[6]所述,MS-SSIM具有衰减高对比度区域中的误差,并提高低对比度区域中的误差的效果。但事实并非如预期的那样,它经常为低对比度区域(例如草地和头发)分配更多细节,并从高对比度区域(例如文本和显著对象)中删除细节。注意力机制更多地关注高对比度区域,并因此在其上分配更多比特。当针对MS-SSIM进行优化时,这种矛盾可能会导致我们基于注意力的模型出现不明显的改进。
如图7所示,CLIC专业验证数据集上的比较结果表明了相同的结论。它显示了我们基于CNN的模型和STF模型的鲁棒性。
Visual Quality. 图8显示了通过我们的方法和压缩标准JEPG、BPG和VVC(VTM 9.1)重建图像的示例(kodim07.png)。我们的重建图像保留了近似bpp的更多细节。当针对MS-SSIM进行优化时,我们基于CNN的模型和STF模型在视觉质量方面有了显著的改善。
4.3. Codec Efficiency Analysis
空间自回归(AR)上下文模型是有效的,后续研究经常使用它来提高RD性能。然而,AR模型按顺序编码和解码每个空间符号,这显著降低了GPU和TPU上的编解码器效率。基于GMM的内窥模型也有同样的缺陷。虽然它可以更精确地估计潜在用户的PDF和CDF,但动态生成CDF和PDF会牺牲编码效率,而基于SGM的entopy模型有固定的PDF和CDFs表。因此,我们使用信道条件(CC)模型[35]作为沿信道维度的自回归上下文模型,以实现更好的并行处理,并采用基于SGM的entopy模型以提高编码效率。
在表1中,我们在Kodak数据集上评估了我们的方法和那些耗时模型的推断延迟[15,34]
4.4. Evaluating the Effects of Window Attention
为了证明我们的结论,即专注于空间相邻元素可以实现更好的RD性能,我们通过移除WAM或使用NLAM进行了对比实验,如表2所示。图9中的消融研究表明,提出的基于窗口的注意是有效的,可以增强当前基于SOTA-CNN的模型[35]。
4.5. Discussion
More Efficient Window Attention Designing. 我们基于CNN的架构仍有改进的空间,因为基于窗口的注意力不足以捕获结构信息。此外,我们的实验结果表明GDN和注意机制是不兼容的。我们猜测GDN更像是一个非线性激活函数,而不是一个归一化块。我们的后续实验表明,直接使用卷积层生成注意力掩码也可以实现类似的RD性能。
Compatible Normalization for Transformer . 在我们基于Transformer的架构中,我们默认使用层规范化(LN)。缺点是,LN重新缩放网络中线性滤波器的响应,使其保持在合理的工作范围内,在所有空间位置具有相同的重新缩放因子,这可能会破坏元素的高斯分布。在计算注意力图时,需要LN来重新缩放响应范围。这似乎相互矛盾,但意味着基于Transformerbased的架构在学习图像压缩方面更有潜力。此外,我们期待着将变换块和卷积块结合起来,到目前为止,我们的结果表明它们是互补的。
Human Perception. 学习到的图像压缩模型直接优化PSNR或MS-SSIM等指标,并实现高RD性能。然而,一些工作[11,12,36-39]提出,峰值信噪比和MS-SSIM都与人类感知没有很好的相关性。我们发现,为MSE优化的模型会导致图像模糊,为MS-SSIM优化的模型会从具有高对比度的区域(例如,文本和显著对象)中删除细节,如图1所示。[39]提出了一种新的度量,该度量是在特定于图像压缩的感知相似性数据上学习的。受[11]中感知质量的数学定义的启发,[12]研究了率失真感知权衡。为了进行更公正的评估,感知质量度量对于实际应用至关重要(例如LPIPS[47]、FID[20]、KID[10])。
5. Conclusion
在本文中,我们广泛研究了局部感知注意力机制,发现将神经网络学习的全局结构与注意力单元挖掘的局部纹理相结合至关重要。我们提出了一种灵活的基于窗口的注意力模块,用于捕捉空间相邻元素之间的相关性,它可以作为即插即用组件来增强CNN或Transformer模型。此外,我们提出了一种新的对称变换器(STF)框架,在下采样编码器和上采样解码器中都具有绝对变换块。大量实验结果表明,所提出的方法是有效的,超过了最先进的(SOTA)RD性能。未来,我们将深入探讨影响图像压缩中局部细节重建的其他因素,如卷积核成形和归一化模式。