☀️马上要成为打工人,这几天把前面的知识都捡了捡,发现自己对关系数据库这块的学习还有所缺失,于是本章开始学习mysql
这里写目录标题
1. 数据库系统的发展
数据库的发展主要经历了3个阶段:
1.1 人工管理阶段
1950年以前,计算机主要用于科学计算,并不擅长保存数据,而且当时计算机的硬件和软件都很落后,科学家对数据的管理基本都是通过人工管理的方式,这个阶段的数据管理特点主要有:
- 数据不保存
- 数据不共享
- 数据不具有独立性
- 使用应用程序管理数据
1.2 文件系统阶段
1960年左右,计算机的软件和硬件都有了较大的发展,有了磁盘等存储设备和专门管理数据的软件,该阶段的数据管理有以下特点:
- 数据可以长期保存
- 由文件系统管理数据
- 共享性差、数据冗余大
- 数据独立性差
1.3 数据库阶段
二十世纪60年代后,计算机逐渐应用于管理系统,而且规模越来越大,应用越来越广,数据量也急剧增长,对数据共享的要求越来越强烈,使得简单的文件系统不能满足用户的需求,于是出现了数据库系统来统一管理数据。数据库系统的出现,满足了多用户、多应用共享数据的需求,比文件系统具有明显的优点,标志着数据管理技术的飞跃。
1.4 大数据阶段
这个阶段主要是以一些分布式的数据仓库作为数据管理的工具,这里就不给与详细介绍了。
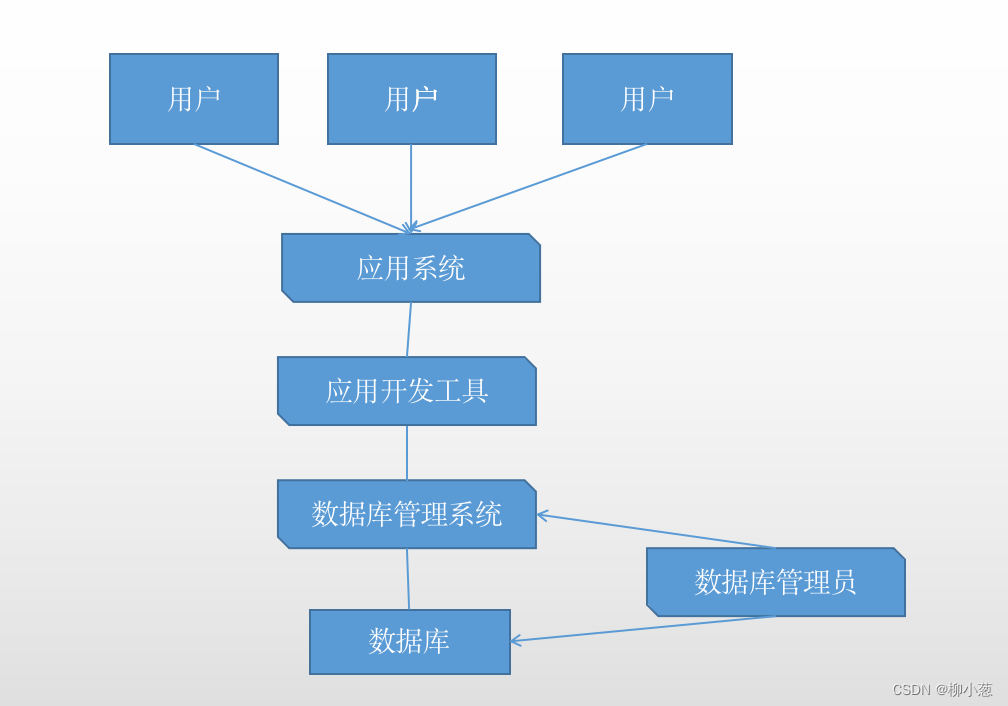
2 数据库系统的组成
数据库系统(database system,DBS) 是采用数据库技术的计算机系统,是由数据库、数据库管理系统、数据库管理员、支持数据库系统的硬件和软件组成,主要结构如下:
2.1 数据模型的概念
数据模型主要是toenail描述数据与数据之间的关系、数据的语义、数据一致性约束的概念性工具的集合,是数据库系统的核心。
数据模型主要是由数据结构、数据操作、数据完整性约束3部分构成,具体含义如下:
- 数据结构:是对系统静态特征的描述、描述对象包括数据的类型、内容、性质、和数据之间的相互关系。
- 数据操作:是对系统动态特征的描述、是对数据库各种对象实例的操作。
- 完整性约束:是完整性规则的集合,它定义了给定数据模型中数据及其联系所具有的制约和依存规则。
2.2 数据模型的种类
常见的数据模型主要有层次模型、网状模型和关系模型,具体解释如下:
-
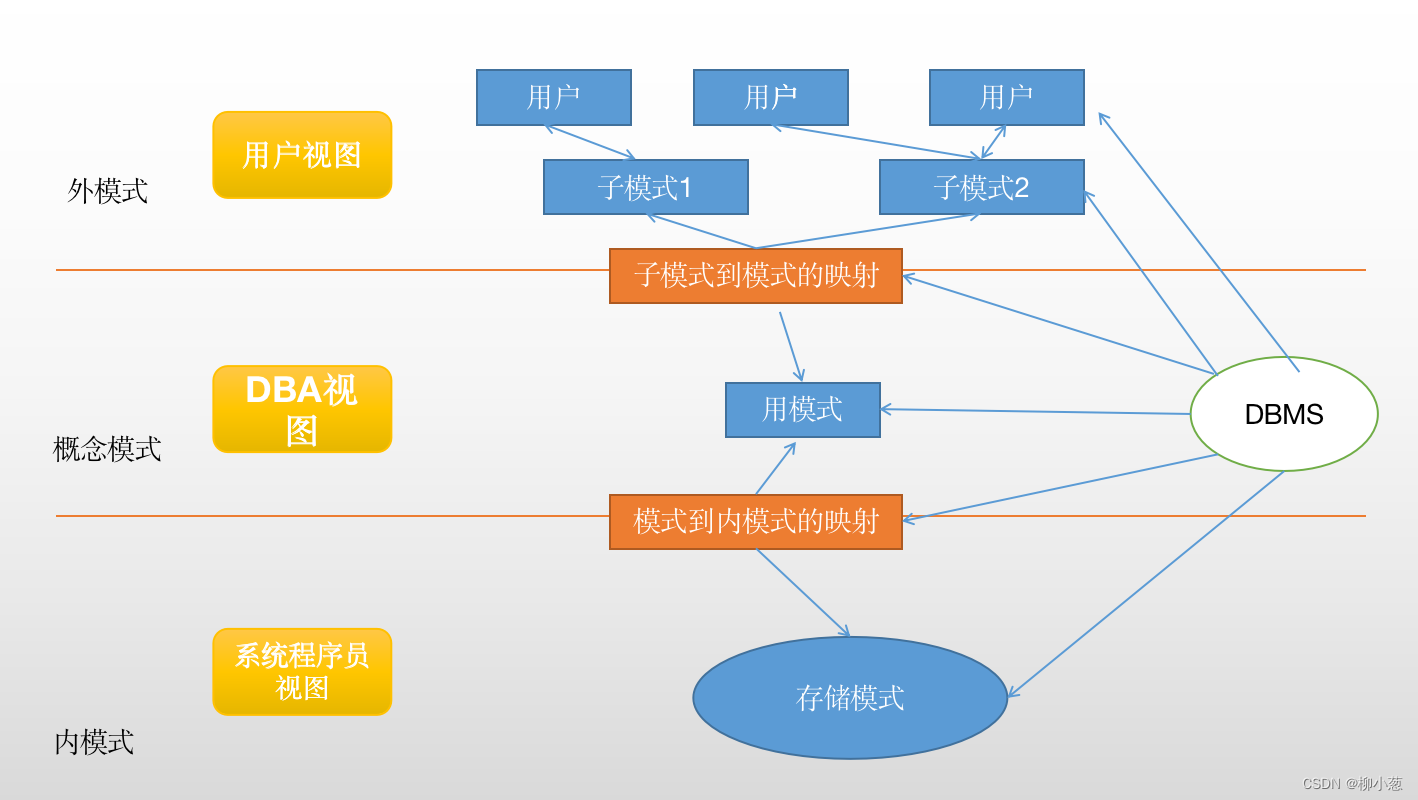
层次模型:层次模型用树状结构表示实体类型及其实体间联系的数据模型。该结构有以下特点:
(1)每棵树有且仅有一个无双亲节点,称为根。
(2)树中除根外所有节点有且仅有一个双亲。
-
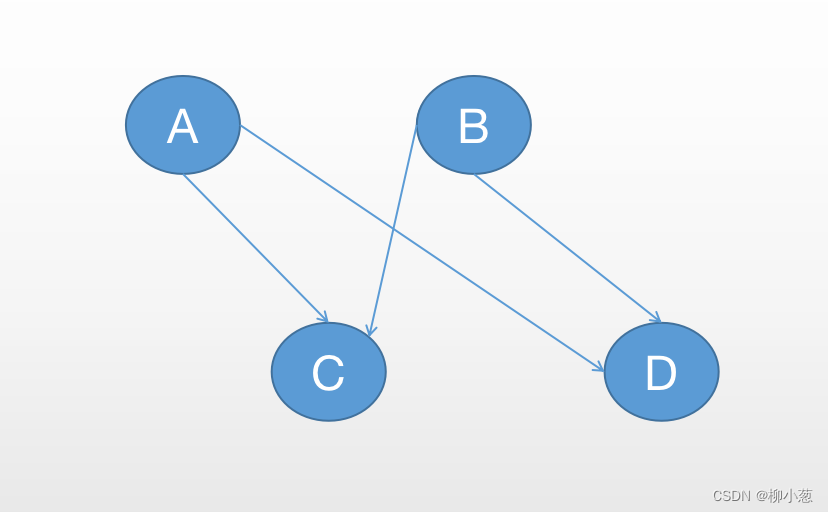
网状模型:用有向图结构表示实体类型及实体间联系的数据模型称为网状模型,用网状模型编写应用程序及其复杂,数据的独立性较差。
-
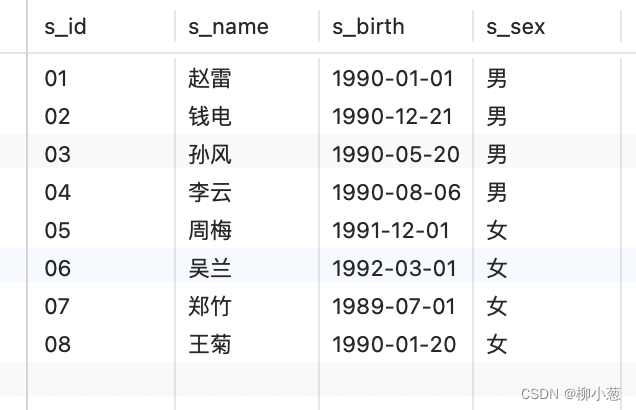
关系模型:以二维来描述。关系模型中,每个表有多个字段列和记录行,每个字段列有固定的属性(数字、字符、日期等),关系模型数据结构简单、清晰、具有很高的数据独立性,是目前主流的数据模型。
关系数据模型的基本术语如下:
(1)关系:一个二维表就是一个关系
(2)元组:二维表中的一行就是一个元组,即表中的记录
(3)属性:二维表中的一列,用类型和值表示
(4)域:每个属性取值的变化范围,如性别的域为{男,女}。
关系中的数据约束如下:
(1)实体完整性约束:约束关系的主键中属性值不能为空值
(2)参照完整性约束:关系之间的基本约束
(3)用户定义的完整性约束:反应了具体应用中数据的语义要求。
2.3 关系数据库的规范化
关系数据库的规范化理论为:关系数据库中的每一个关系都要满足一定的规范。根据满足规范的条件不同,可以分为5个等级:1NF,2NF,3NF,BCNF,4NF,5NF。一般情况下,数据库满足三范式就可以满足需求了,下面介绍一下最基础的三范式。
2.3.1 第一范式
在一个关系中,消除重复字段,且各字段都是最小的逻辑存储单位。第一范式是第二和第三范式的基础,是最基本的范式,第一范式的原则如下:
(1)数据组的每一个属性都只包含一个值
(2)关系中的每个数组必须包含相同数量的值
(3)关系中的每个数组一定不能相同
在任何一个关系数据库中,第一范式是最基本的要求,不满足第一范式的数据库就不是关系数据库。由此可见第一范式具有不可再分解的原子特性。
2.3.2 第二范式
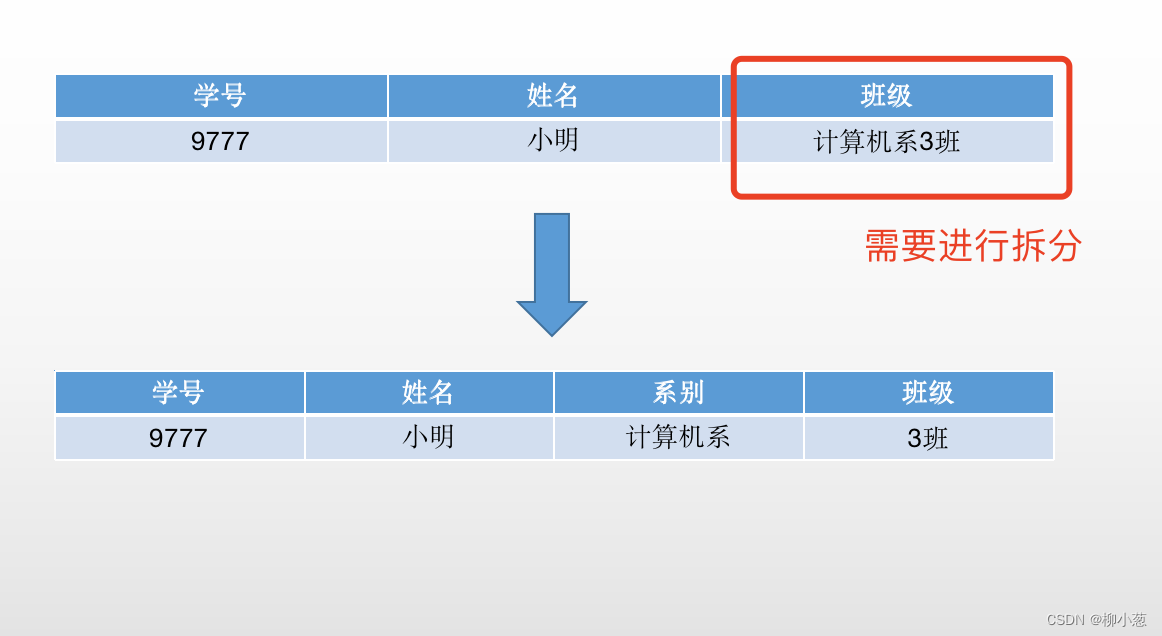
第二范式是在第一范式的基础上建立起来的,即满足第二范式必须先满足第一范式,第二范式要求数据库汇总的每一个实体(即每个记录行)必须可以被唯一地区分。或者说要求实体的属性完全依赖于主关键字,不能存在仅依赖主关键字一部分的属性,如果存在部分依赖的话,需要将这个属性与主关键字分离出来形成一个新的实体。
2.3.3 第三范式
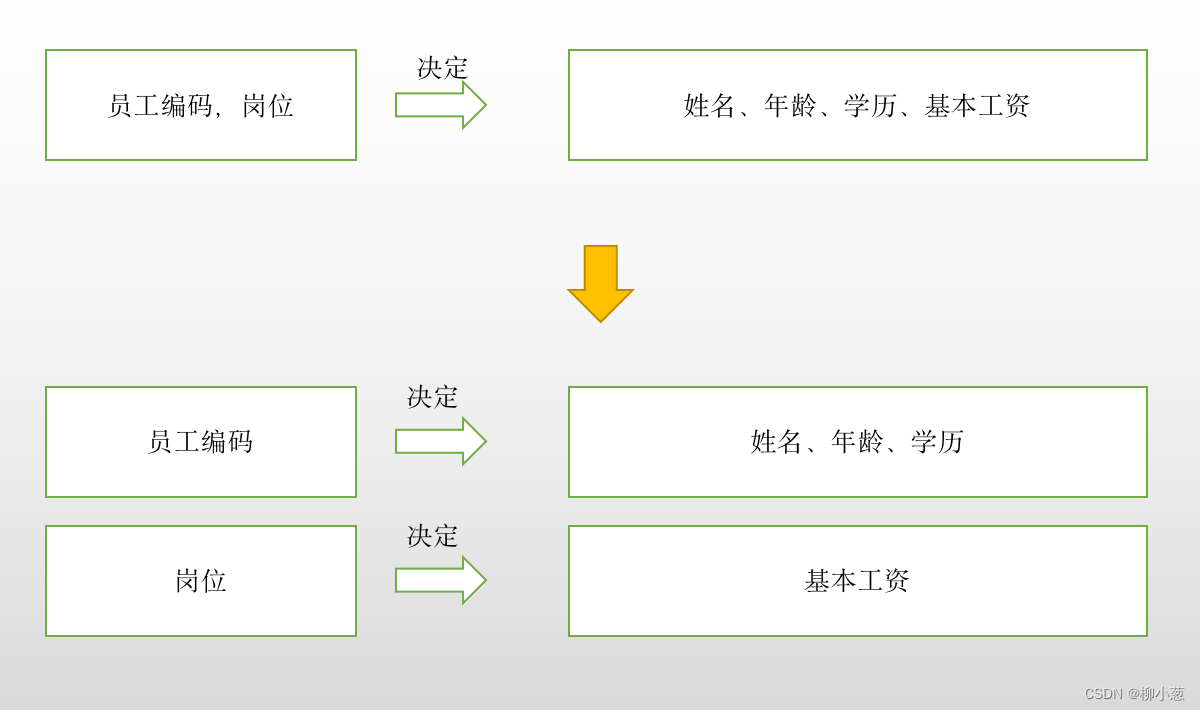
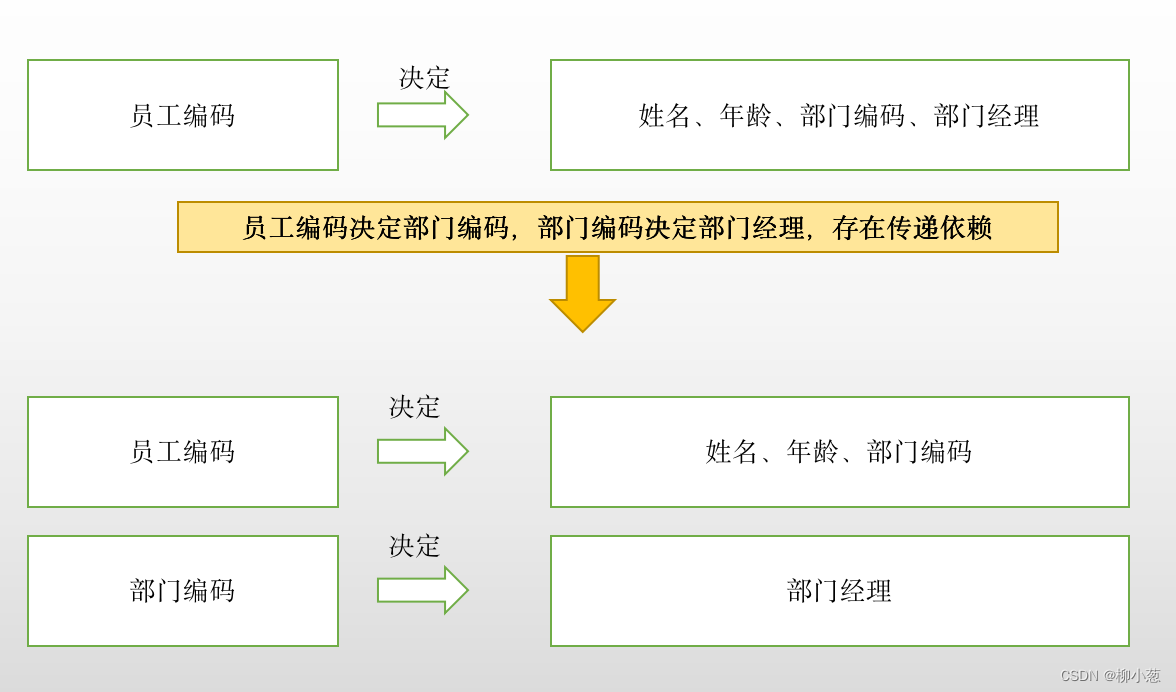
第三范式是在第二范式的基础上建立起来的,即满足第三范式必须先满足第二范式,第三范式要求关系表中不存在非关键字列中对任意候选关键字列的传递函数依赖,也就是说,第三范式要求一个关系表中不包含已在气压表中包含的非主关键字信息。
所谓传递函数依赖,就是指如果存在关键字a决定非关键字b,而非关键字段b,决定非关键字段c,则称非关键字段c传递依赖于关键字a。
2.4 关系数据库的设计原则
数据库设计是指对于一个给定的应用环境,根据用户的需求,利用数据模型和应用程序模拟现实中该应用环境的数据结构和处理活动的过程。
数据库设计原则如下:
(1)数据库内的数据文件的数据组织应该获得最大限度的共享、最小冗余、消除数据及数据依赖关系中的冗余部分,使依赖于同一个数据模型的数据达到有效的分离。
(2)保证输入输出、修改数据的一致性与正确性
(3)保证数据与使用数据的应用程序之间的高度独立性。
以上这些特点,需要涉及到数据库中一个概念:事物
事务是逻辑上的一组数据库操作,要么都执行,要么都不执行。事务在数据库中就是一个基本的工作单位,事务中包含的逻辑操作(SQL 语句),只有两种情况:成功和失败。
事物有4个特性:
- 原子性(Atomicity ):一个事务是一个不可再分割的整体,要么全部成功,要么全部失败
- 一致性(Consistency ):一个事务可以让数据从一种一致状态切换到另一种一致性状态
- 隔离性(Isolution ):一个事务不受其他事务的影响,并且多个事务彼此隔离
- 持久性(Durability ):一个事务一旦被提交,在数据库中的改变就是永久的,提交后就不能再回滚
2.5 数据库概念设计
概念设计是一个构建概念数据模型的过程,这个概念数据模型在抽象的高层建模;需要足够简单且通常是图形化的;并且能够用于与非技术用户交流数据库的需求。这里使用 ==ER 模型(实体关系模型)==来实现概念设计。
实体主要是指客观存在并且客相互区分的事物,实体既可以是实际事物,也可以是抽象的概念或者关系。实体之间一般有3种对应关系:
- 一对一:是指表a中的一条记录在表b中有且只有一条相匹配的记录。
- 一对多:表a中的行可以在表b中找到多行进行匹配,但是表b的行在表a中只有一个能匹配。
- 多对多:每个表中的行在相关表中具有多个匹配行,一般情况下,多对多的关系是通过创建第三个表实现表之间关系的连接。
3. 数据库的体系结构
3.1 数据库的三级模式
三级模式是指:模式、外模式、内模式
-
模式:迷失也称为逻辑模式或者概念模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。一个数据库只有一个模式,模式处于三级结构中间。
-
外模式:也称为用户模式,是数据库用户(包含应用程序猿和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。外模式是模式的子集,一个数据库可以有多个外模式。
-
内模式:也称为存储模式,是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。一个数据库只有一个内模式。
-
参考资料
- 《mysql从入门到精通》
- 链接: 实体关系模型
- 链接: mysql事物的四大特性
- chatgpt