任务需求是爬取微博的内容和评论。一开始我是准备直接用正常的爬虫来做,但是发现微博上的内容几乎都是动态加载生成的。所以了解了一下就学习使用·selenium自动化测试工具来爬取相关数据。
首先是不登录微博,发现只能查看最多二十条数据,这自然限制太大所以还是需要实现登录后再爬取。
1.登录微博
由于微博现在的登录不能只输入账号密码,所以通过查找了一些方法后选用了注入cookie来实现自动登录。而想要注入的cookie需要自己先登录获得。这里直接使用了各位大佬给出的方法。实现扫码登录后获取cookie。
from selenium import webdriver
from time import sleep
import json
from selenium.webdriver.common.by import By
if __name__ == '__main__':
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://weibo.com/login.php')
sleep(6)
a = driver.find_element(By.XPATH, '//*[@id="pl_login_form"]/div/div[1]/div/a[2]')
a.click()
sleep(10)
dictCookies = driver.get_cookies() # 获取list的cookies
jsonCookies = json.dumps(dictCookies) # 转换成字符串保存
with open('微博_cookies.txt', 'w') as f:
f.write(jsonCookies)
print('cookies保存成功!')2.通过获取到的cookie实现自动登录然后爬取用户微博内容和评论
2.1打开浏览器,进入到登录页面。这里我最大化窗口了。
# 打开浏览器,进入到微博登录页面
def browser_initial():
browser = webdriver.Chrome()
browser.maximize_window()
browser.get('https://weibo.com/login.php')
return browser2.2实现自动化登录
# 将已经登录获得的cookie写入,实现自动登录
def log_csdn(browser):
with open('微博_cookies.txt', 'r', encoding='utf8') as f:
listCookies = json.loads(f.read())
# 往browser里添加cookies
for cookie in listCookies:
cookie_dict = {
'domain': '.weibo.com',
'name': cookie.get('name'),
'value': cookie.get('value'),
"expires": '',
'path': '/',
'httpOnly': False,
'HostOnly': False,
'Secure': False
}
#print(cookie_dict)
browser.add_cookie(cookie_dict)
sleep(1)
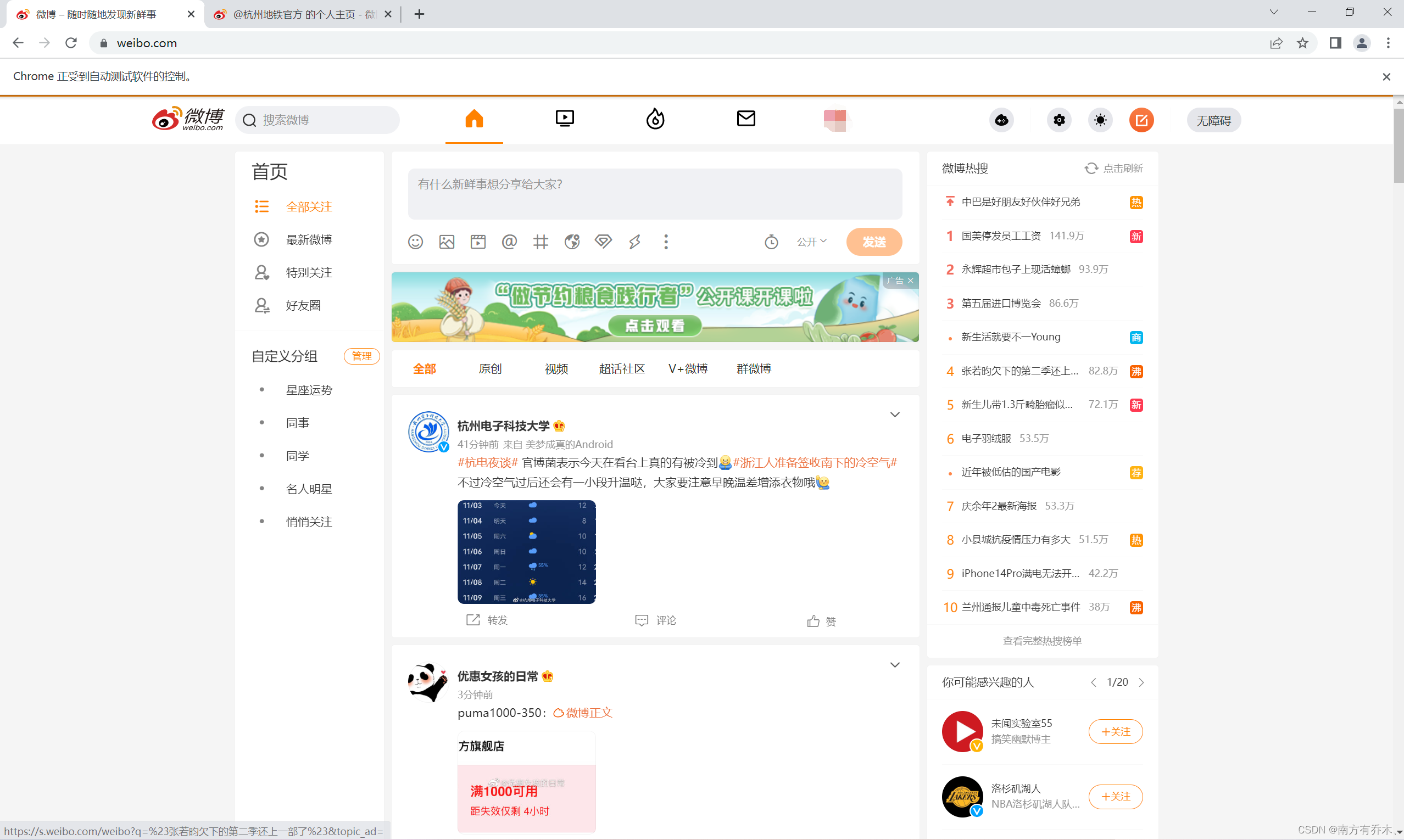
browser.get('https://weibo.com/login.php')登录后的页面如下图
2.3搜索内容并且爬取
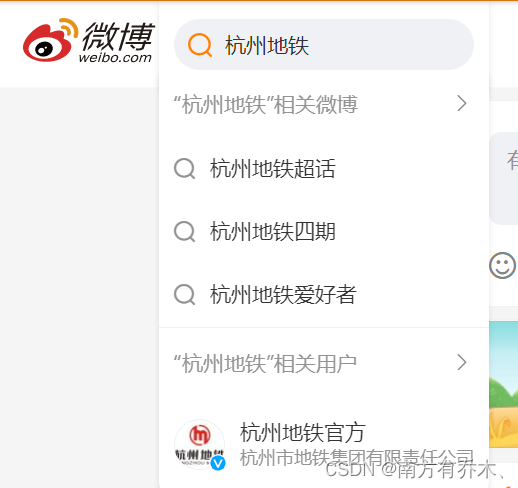
这时候需要在左上角的搜索框输入自己需要搜索的用户,然后通过按回车来实现搜索
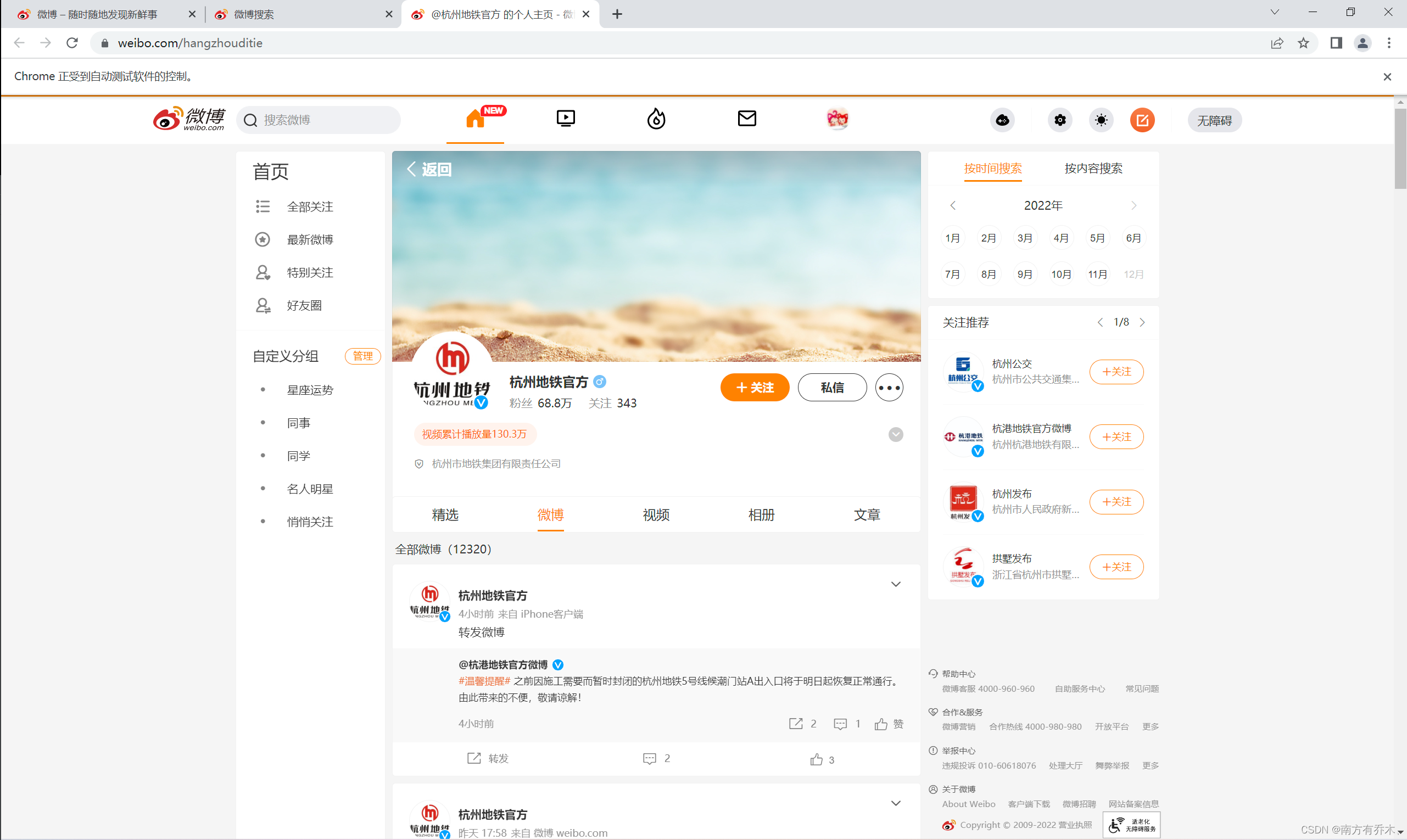
得到新的页面里可以看到最上方会显示相关的账户,找到相关元素并点击即可

最后进入到用户的完整页面
这时侯就可以开始爬取用户的微博信息和评论了。由于微博的内容是动态加载的,通过F12可以看到一开始是仅展示六条内容的元素
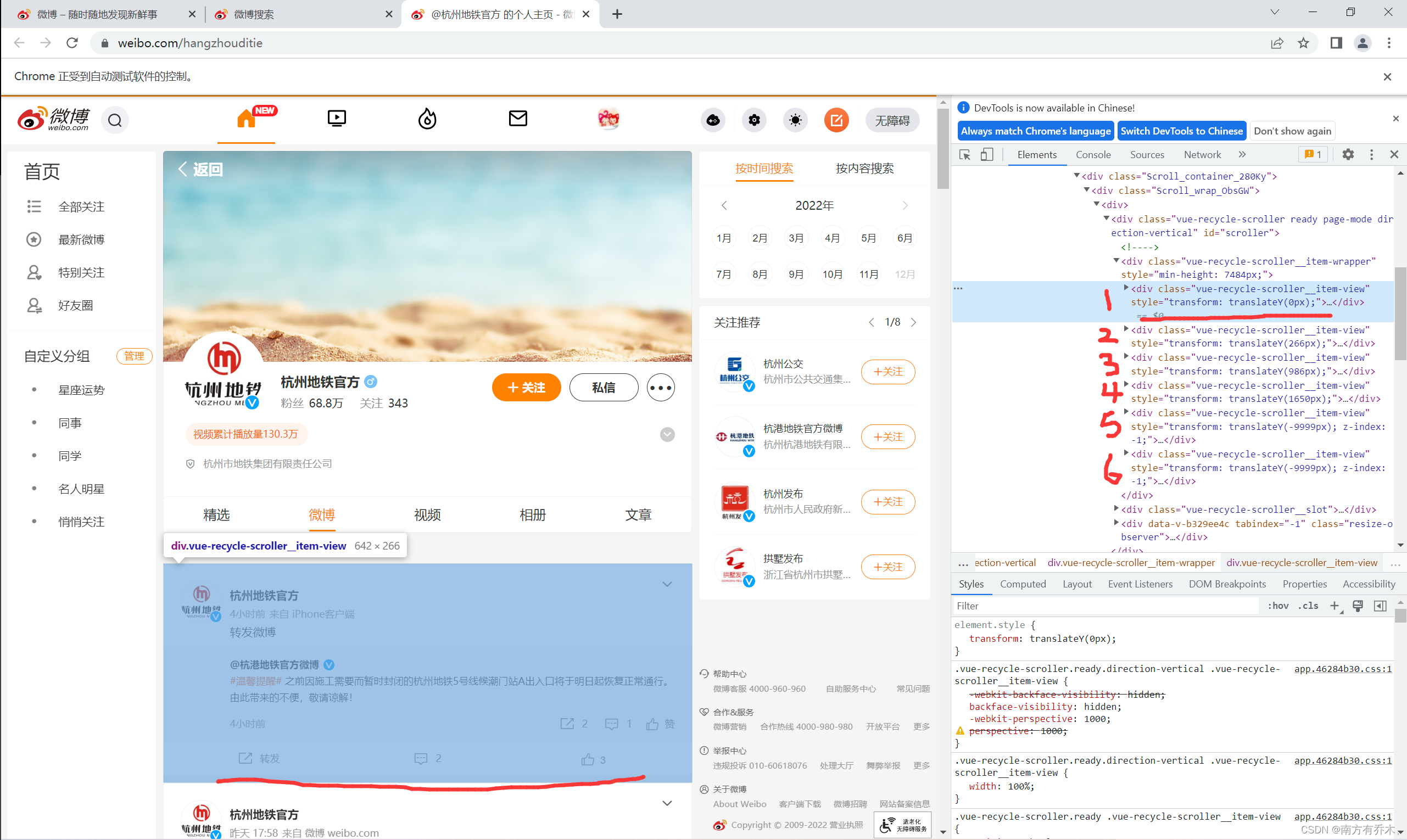
通过滑动,元素会逐渐增加,但是上限是12个,并且后面会出现元素顺序和微博内容顺序不符的情况。如果单单爬取微博的内容,不爬评论那还好,只需要定位到每一个元素块,获取其内部的text文本然后处理一下就可以获得自己想要的信息。但是由于还要爬取相应的评论内容,并且评论还要和微博内容相对应,所以不能直接进行爬取。
这里我选择微博内容里的时间元素里的href
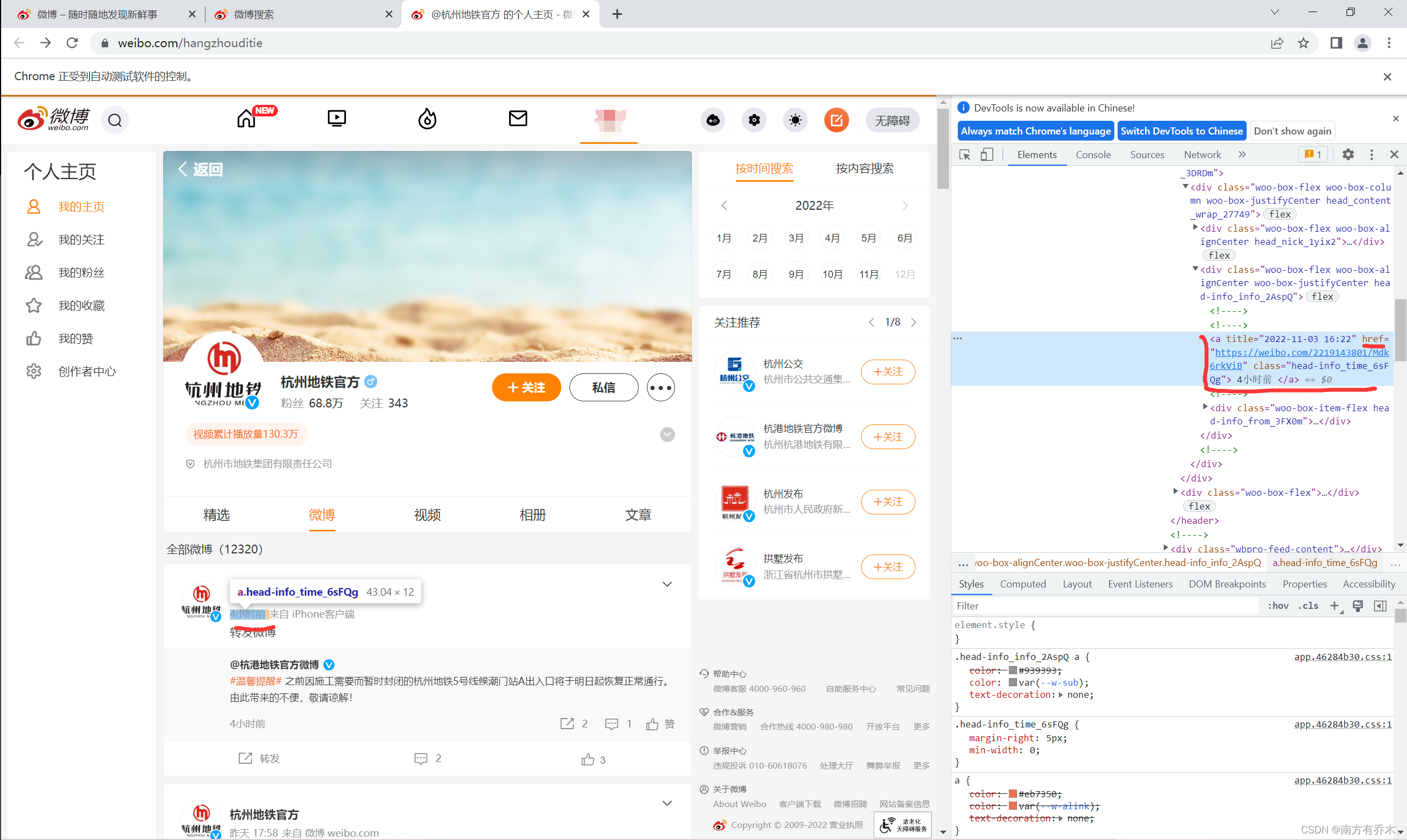
通过点击这个a标签,可以跳转到该条微博的详情页面
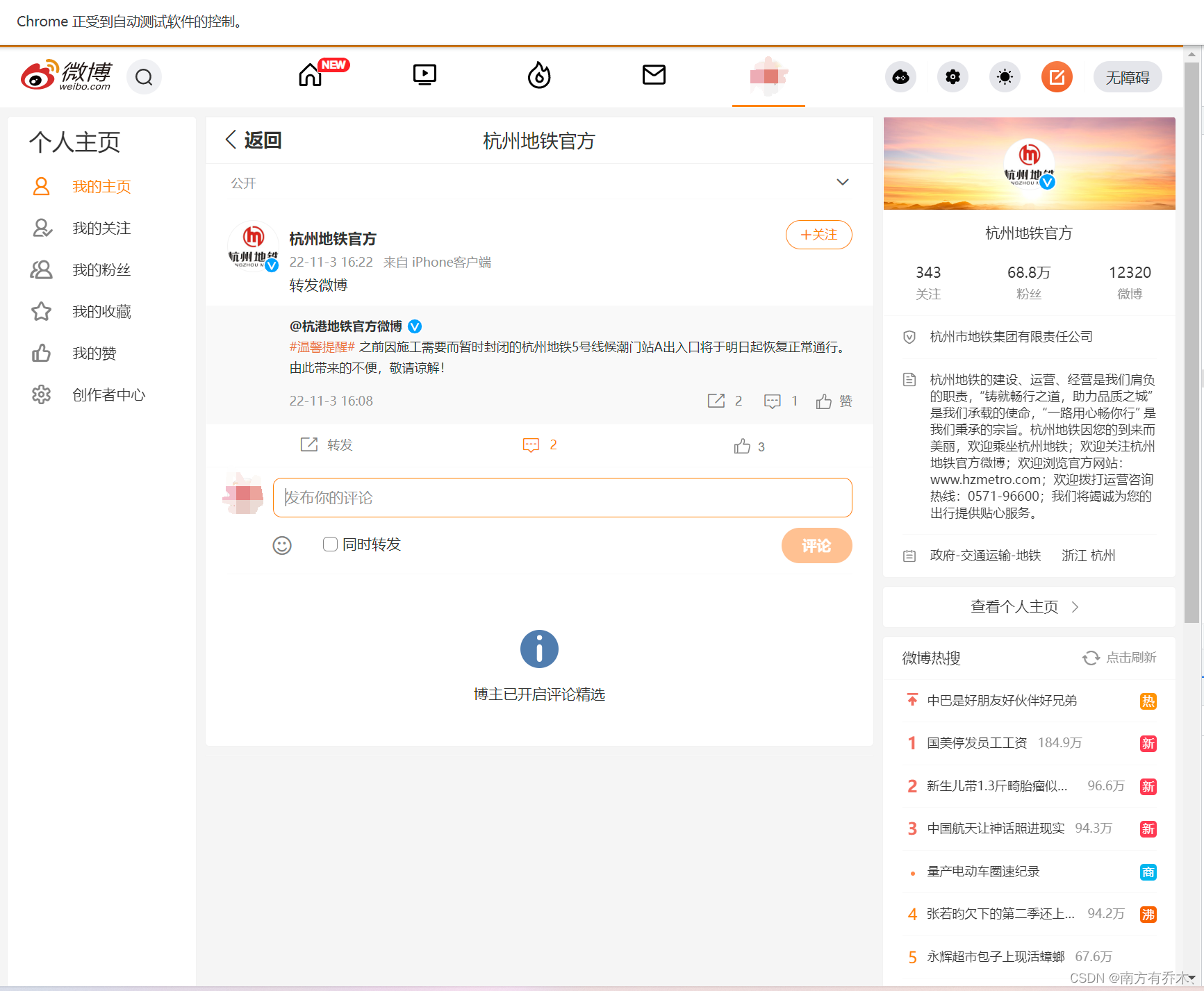
这时候就可以分块爬起微博的内容以及转发数、评论数、点赞数和评论的内容了。要注意的是这里的转发数评论数这些可能存在多个,比如此图里是转发他人微博,他人微博里也有转发数这些。还有就是评论的内容有可能是开启精选后的,和普通的评论内容要做判断。 爬取完微博内容和评论后点击上方的返回按钮,回到之前的页面。
hrefs = []
# 搜索内容
def search(username):
# 等待元素出现再进行下一步
WebDriverWait(browser, 15).until(EC.presence_of_element_located((By.CLASS_NAME, "woo-pop-ctrl")))
# 获取搜索框元素
searchinput = browser.find_element(By.CLASS_NAME, 'woo-input-main')
# 将要搜索的内容写入搜索框
searchinput.send_keys(username)
# 等待0.5秒后按回车
sleep(0.2)
searchinput.send_keys(Keys.ENTER)
# 转移句柄到新的页面
new_window = browser.window_handles[-1]
# 关闭原来的页面
browser.close()
# 窗口转移到新的页面
browser.switch_to.window(new_window)
# 等待
WebDriverWait(browser, 15).until(EC.presence_of_element_located((By.CLASS_NAME, "card-wrap")))
# 定位用户微博头像并点击
weibo = browser.find_element(By.XPATH, '//div[@class="card card-user-b s-brt1 card-user-b-padding"]/div/a')
weibo.click()
new_window = browser.window_handles[-1]
browser.switch_to.window(new_window)
WebDriverWait(browser, 15).until(EC.presence_of_element_located((By.CLASS_NAME, "vue-recycle-scroller__item-view")))
# 微博一次最多给12条内容的元素,并且给出的元素不保证顺序。
# 所以第一次进入页面的时候获取所有的内容元素,a标签里的href唯一,所以将其提取出来
for t in range(3):
a = browser.find_elements(By.XPATH, '//div[@class="woo-box-item-flex head_main_3DRDm"]/div/div[2]/a')
# 在获取到的列表里进行筛选,已经爬取过的微博就跳过
for i in range(len(a)):
if a[i].get_attribute("href") in hrefs:
print("已经搜索过")
continue
else:
print("还没搜索过")
# 每次都向下滑动400像素,大致符合一条微博的高度
changepage(400)
# sleep(0.5)
newpage = a[i].get_attribute("href")
# 打印href
print(newpage)
hrefs.append(newpage)
# print(comments)
# 打印已经搜索的微博内容数
print(len(hrefs))
# 使用js脚本来点击元素,否则可能出现元素不在网页上,无法交互的报错
# a[i].click()
browser.execute_script("arguments[0].click();", a[i])
# 不要直接用href去请求,否则点击返回的时候会直接回到微博首页面
# browser.get(newpage)
sleep(0.5)
# 爬取具体内容页面的内容和评论
findall()
sleep(0.2)
# 找到返回按钮并点击
WebDriverWait(browser, 15).until(EC.presence_of_element_located((By.XPATH,
'//div[@class="woo-box-flex woo-box-alignCenter Bar_left_2J3kl Bar_hand_2VAG1"]/i')))
back = browser.find_element(By.XPATH,
'//div[@class="woo-box-flex woo-box-alignCenter Bar_left_2J3kl Bar_hand_2VAG1"]/i')
back.click()text = []
# 将页面向下滑动px像素
def changepage(px):
browser.execute_script("window.scrollBy(0, {})".format(px))
# 爬取微博的内容和评论
def findall():
# 等待页面元素加载
WebDriverWait(browser, 15).until(EC.presence_of_element_located((By.CLASS_NAME, "Feed_body_3R0rO")))
body = browser.find_element(By.CLASS_NAME, 'Feed_body_3R0rO')
# 通过换行来划分内容
bodytext = body.text.split("\n")
print(bodytext)
# 找到转发评论点赞的元素,但是如果有微博内容为转发他人的微博,则存在两个footer元素,
# 所以寻找多个,然后取最后那一个
footer = browser.find_elements(By.TAG_NAME, 'footer')
footertext = footer[-1].text.split("\n")
print(footertext[1])
WebDriverWait(browser, 15).until(EC.presence_of_element_located((By.CLASS_NAME, "Detail_box_3Jeom")))
try:
prompt = browser.find_element(By.CLASS_NAME, "RepostCommentList_tip_2O5W-")
print(prompt.text)
t = False
except:
t = True
print(t)
while t:
try:
browser.find_element(By.XPATH, '//div[@class="Bottom_text_1kFLe"]')
t = False
except:
t = True
WebDriverWait(browser, 15).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="vue-recycle-scroller__item-wrapper"]')))
pagecomment = browser.find_elements(By.XPATH, '//div[@class="vue-recycle-scroller__item-view"]')
for i in pagecomment:
comment = i.text.split("\n")
if comment in text:
continue
else:
print(comment)
text.append(comment)
sleep(0.1)
changepage(600)最后爬取内容和评论的总的代码如下:
from selenium import webdriver
from time import sleep
import json
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
text = []
hrefs = []
# 打开浏览器,进入到微博登录页面
def browser_initial():
browser = webdriver.Chrome()
browser.maximize_window()
browser.get('https://weibo.com/login.php')
return browser
# 将已经登录获得的cookie写入,实现自动登录
def log_csdn(browser):
with open('微博_cookies.txt', 'r', encoding='utf8') as f:
listCookies = json.loads(f.read())
# 往browser里添加cookies
for cookie in listCookies:
cookie_dict = {
'domain': '.weibo.com',
'name': cookie.get('name'),
'value': cookie.get('value'),
"expires": '',
'path': '/',
'httpOnly': False,
'HostOnly': False,
'Secure': False
}
#print(cookie_dict)
browser.add_cookie(cookie_dict)
sleep(1)
browser.get('https://weibo.com/login.php')
#print(browser.get_cookies())
#browser.refresh() # 刷新网页,cookies才成功
# 搜索内容
def search(username):
# 等待元素出现再进行下一步
WebDriverWait(browser, 15).until(EC.presence_of_element_located((By.CLASS_NAME, "woo-pop-ctrl")))
# 获取搜索框元素
searchinput = browser.find_element(By.CLASS_NAME, 'woo-input-main')
# 将要搜索的内容写入搜索框
searchinput.send_keys(username)
# 等待0.5秒后按回车
sleep(0.2)
searchinput.send_keys(Keys.ENTER)
# 转移句柄到新的页面
new_window = browser.window_handles[-1]
# 关闭原来的页面
browser.close()
# 窗口转移到新的页面
browser.switch_to.window(new_window)
# 等待
WebDriverWait(browser, 15).until(EC.presence_of_element_located((By.CLASS_NAME, "card-wrap")))
# 定位用户微博头像并点击
weibo = browser.find_element(By.XPATH, '//div[@class="card card-user-b s-brt1 card-user-b-padding"]/div/a')
weibo.click()
new_window = browser.window_handles[-1]
browser.switch_to.window(new_window)
WebDriverWait(browser, 15).until(EC.presence_of_element_located((By.CLASS_NAME, "vue-recycle-scroller__item-view")))
# 微博一次最多给12条内容的元素,并且给出的元素不保证顺序。
# 所以第一次进入页面的时候获取所有的内容元素,a标签里的href唯一,所以将其提取出来
for t in range(3):
a = browser.find_elements(By.XPATH, '//div[@class="woo-box-item-flex head_main_3DRDm"]/div/div[2]/a')
# 在获取到的列表里进行筛选,已经爬取过的微博就跳过
for i in range(len(a)):
if a[i].get_attribute("href") in hrefs:
print("已经搜索过")
continue
else:
print("还没搜索过")
# 每次都向下滑动400像素,大致符合一条微博的高度
changepage(400)
# sleep(0.5)
newpage = a[i].get_attribute("href")
# 打印href
print(newpage)
hrefs.append(newpage)
# print(comments)
# 打印已经搜索的微博内容数
print(len(hrefs))
# 使用js脚本来点击元素,否则可能出现元素不在网页上,无法交互的报错
# a[i].click()
browser.execute_script("arguments[0].click();", a[i])
# 不要直接用href去请求,否则点击返回的时候会直接回到微博首页面
# browser.get(newpage)
sleep(0.5)
# 爬取具体内容页面的内容和评论
findall()
sleep(0.2)
# 找到返回按钮并点击
WebDriverWait(browser, 15).until(EC.presence_of_element_located((By.XPATH,
'//div[@class="woo-box-flex woo-box-alignCenter Bar_left_2J3kl Bar_hand_2VAG1"]/i')))
back = browser.find_element(By.XPATH,
'//div[@class="woo-box-flex woo-box-alignCenter Bar_left_2J3kl Bar_hand_2VAG1"]/i')
back.click()
# 将页面向下滑动px像素
def changepage(px):
browser.execute_script("window.scrollBy(0, {})".format(px))
# 爬取微博的内容和评论
def findall():
# 等待页面元素加载
WebDriverWait(browser, 15).until(EC.presence_of_element_located((By.CLASS_NAME, "Feed_body_3R0rO")))
body = browser.find_element(By.CLASS_NAME, 'Feed_body_3R0rO')
# 通过换行来划分内容
bodytext = body.text.split("\n")
print(bodytext)
# 找到转发评论点赞的元素,但是如果有微博内容为转发他人的微博,则存在两个footer元素,
# 所以寻找多个,然后取最后那一个
footer = browser.find_elements(By.TAG_NAME, 'footer')
footertext = footer[-1].text.split("\n")
print(footertext[1])
WebDriverWait(browser, 15).until(EC.presence_of_element_located((By.CLASS_NAME, "Detail_box_3Jeom")))
try:
prompt = browser.find_element(By.CLASS_NAME, "RepostCommentList_tip_2O5W-")
print(prompt.text)
t = False
except:
t = True
print(t)
while t:
try:
browser.find_element(By.XPATH, '//div[@class="Bottom_text_1kFLe"]')
t = False
except:
t = True
WebDriverWait(browser, 15).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="vue-recycle-scroller__item-wrapper"]')))
pagecomment = browser.find_elements(By.XPATH, '//div[@class="vue-recycle-scroller__item-view"]')
for i in pagecomment:
comment = i.text.split("\n")
if comment in text:
continue
else:
print(comment)
text.append(comment)
sleep(0.1)
changepage(600)
if __name__ == "__main__":
# 打开浏览器进入微博登录页面
browser = browser_initial()
# 使用cookie登录微博
log_csdn(browser)
# 爬取相关用户的评论
search("杭州地铁")里面的数据处理还没做,大家可以自己打印出来后根据自己的需要进行处理。