整个代码分两个阶段
第一阶段的识别是YOLOv5来实现的
第二阶段是追踪,由Deep Sort算法来实现。再次基础上进行了计数
代码地址:https://github.com/dongdv95/yolov5/tree/master/Yolov5_DeepSort_Pytorch
把代码git下来
git clone https://github.com/dongdv95/yolov5/tree/master/Yolov5_DeepSort_Pytorch2. 配置环境,把所有依赖的包安装上
作者要求python>=3.8;torch>=1.7,我的conda虚拟环境里有python=3.6和python=3.7的环境,因此需要重选装一个虚拟环境
因为重装环境需要链接conda的在外国的官方源source(https://repo.anaconda.com/pkgs/main/linux-64/;)下载python。要么你有魔法手法去连上外网,否则你直接装的话速度是非常慢的。因此你需要把国内的conda镜像添加到channel目录里面
conda默认源的网址如下
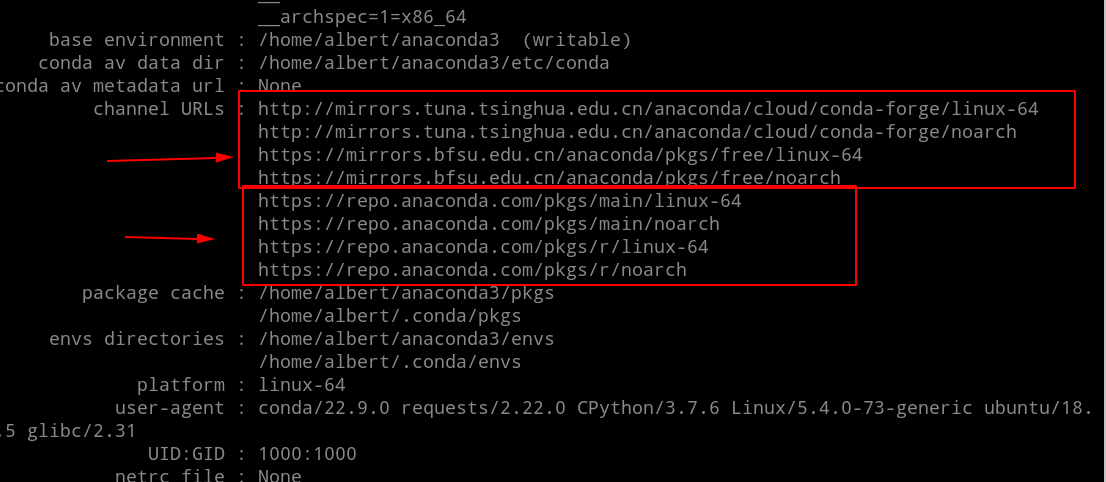
这里特别说明一下北外的那个镜像的网址可以用带s的http,但是清华那个你不要加s,否则可能清华那个没法用
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/pkgs/free/
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/free/
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
# 提供一些备选的conda代码供你挑选
# 清空所有的channel
conda config --remove-key channels
# 移除某个channel
conda config --remove channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/free
# 移除原有的环境
conda remove -n py380tc170 --all
# 更新conda
conda update --all
# 不过上面这句,如果你终端没有连接上外网,会报下面这个错
#UnavailableInvalidChannel: HTTP 404 NOT FOUND for channel anaconda/cloud/msys2/free <http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/free>注意:如果你使用的是国内的源来安装,国内这个源的python版本并不齐全。国内进行备份的时候,仅仅备份了大版本号的这些python。比如python==3.8这个大版本号,国内仅仅保存3.8这个版本下小版本好最高的那个(这里是3.8.13)。如果你指定说我就是要下载3.8.1这个小版本,那么你必须连接外网,否则这个版本是下载不下来的。因为我建议你指定版本为3.8,不要写3.8.1这种小版本号。国内的镜像会自动下载python==3.8.13
conda create -n py380tc170 python=3.8如果你执意要装小版本号的python,比如python==3.8.2,你就得连接外网。如果你用了魔法方法,浏览器已经可以连接外网了,但是你的终端terminal无法连接外网请看这篇帖子https://blog.csdn.net/Albert233333/article/details/128996907
下一步就是安装依赖,官方是提供了requirement.txt,是下面这样,但是我不建议你直接pip install 它。因为它写的是 >=,这样安装的话会安装大于这个版本号的情况下,最新的版本的package。但是作者编写这个项目的时候,往往使用的是比较老的版本的包。你用最新版本的包,就会出现各种奇怪的报错,网上还没有人解答。因此推荐你安装,满足条件的情况下,最老的版本。
# pip install -r requirements.txt
# base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
# plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# deep_sort -----------------------------------
easydict
# torchreid
Cython
h5py
six
tb-nightly
future
yacs
gdown
flake8
yapf
isort==4.3.21
imageio因此我把requirement.txt里面所有的 “>=” 换成了“==”。
matplotlib==3.2.2
numpy==1.18.5
opencv-python==4.1.2.30 # 注意这个地方官方提供的是opencv-python>=4.1.2,但是安装的时候告诉你没有这个版本要你从里面选,我选了30,后面可以运行
Pillow==7.1.2
PyYAML==5.3.1
requests==2.23.0
scipy==1.4.1
torch==1.7.0
torchvision==0.8.1
tqdm==4.41.0
# plotting ------------------------------------
pandas==1.1.4
seaborn==0.11.0
# deep_sort -----------------------------------
easydict
# torchreid
Cython
h5py
six
tb-nightly
future
yacs
gdown
flake8
yapf
isort==4.3.21
imageio你用我上面写的这个另存为一个文件“requirements_my_version.txt”,然后安装就安装成功,丝滑无报错
pip install -r requirements_my_version.txt这里注意如果你的pytorch装的不是1.7.0版本的,而是最23年2月20号新出的版本的(“1.13.1+cu117”),会报下面这个错。所以一定pytorch要装1.7.0版本的
Traceback (most recent call last):
File "track.py", line 278, in <module>
detect(opt)
File "track.py", line 108, in detect
model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.model.parameters()))) # warmup
File "/home/albert/anaconda3/envs/py380tc170/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/graduation_thesis/model_innov/Yolov5_DeepSort_Pytorch/yolov5/models/common.py", line 384, in forward
y = self.model(im) if self.jit else self.model(im, augment=augment, visualize=visualize)
File "/home/albert/anaconda3/envs/py380tc170/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/graduation_thesis/model_innov/Yolov5_DeepSort_Pytorch/./yolov5/models/yolo.py", line 126, in forward
return self._forward_once(x, profile, visualize) # single-scale inference, train
File "/media/F:/FILES_OF_ALBERT/IT_paid_class/graduation_thesis/model_innov/Yolov5_DeepSort_Pytorch/./yolov5/models/yolo.py", line 149, in _forward_once
x = m(x) # run
File "/home/albert/anaconda3/envs/py380tc170/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/home/albert/anaconda3/envs/py380tc170/lib/python3.8/site-packages/torch/nn/modules/upsampling.py", line 157, in forward
recompute_scale_factor=self.recompute_scale_factor)
File "/home/albert/anaconda3/envs/py380tc170/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1269, in __getattr__
raise AttributeError("'{}' object has no attribute '{}'".format(
AttributeError: 'Upsample' object has no attribute 'recompute_scale_factor'
3. 放置好模型文件到指定位置
目标检测使用的默认的模型文件的路径和名字是在这里设定的
track.py line261,我设定的是yolov5n.pt,就是在代码文件同目录下的名叫yolov5n.pt的文件。这个文件这个GitHub项目的作者已经放在文件里面了,所以不用你单独下载
parser.add_argument('--yolo_model', nargs='+', type=str, default='yolov5n.pt', help='model.pt path(s)')做追踪使用的 模型文件会在运行程序的时候自动保存到这个位置
/home/albert/.cache/torch/checkpoints/osnet_x0_25_imagenet.pth4. 运行代码
官方给出的指南如下
$ python track.py --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob'
https://youtu.be/Zgi9g1ksQHc' # YouTube'
rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream注意,作者的意思不是这个7个参数一起传进--source,而是说你传进去一个参数,有7种选择如上,每次用一个。有7种类型的东西都可以传进去。
本机摄像头识别
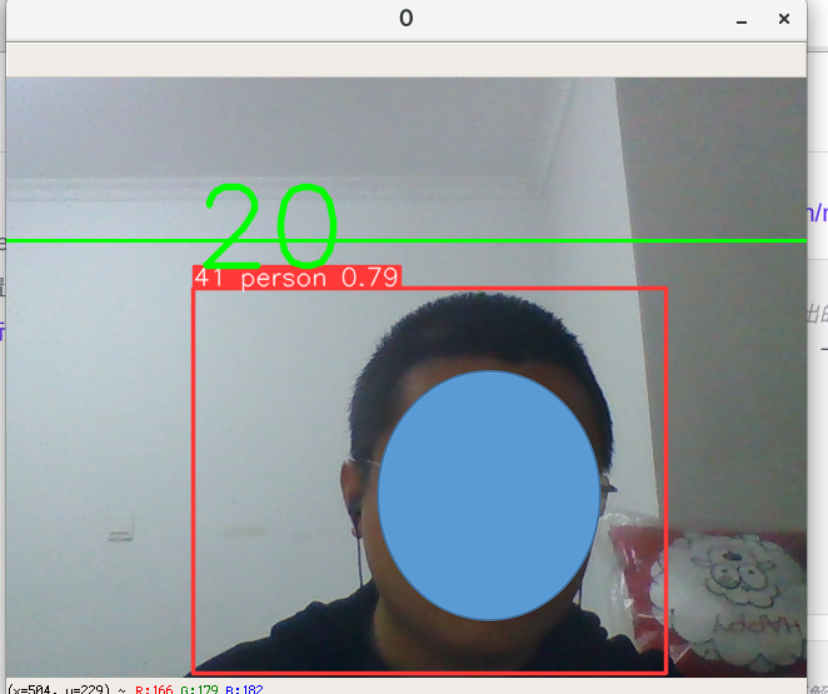
# --source后面加0
# 通过你电脑自身的摄像头拍摄你现在的情况,给你 识别、追踪。只要你头在绿线一下,是不同的人就计数。,但是,这个是模型识别的不好。同一个人分配了20个痛的id,数出来是20个人。,
python track.py --source 0识别出来就是这样
识别图片
python track.py --source ./image_data/15_persons.PNG识别的是这张图

这就是数出来的人数,不太精准。两个自行车是对的,但是人不仅仅是7个,有15个
192x480 7 persons, 2 bicycles, Done. YOLO:(0.006s), DeepSort:(0.023s)
Speed: 0.3ms pre-process, 6.2ms inference, 1.0ms NMS, 23.2ms deep sort update per image at shape (1, 3, 480, 480)对视频进行计数
# --source后面加mp4视频地址
python track.py --source ./videos/Traffic.mp4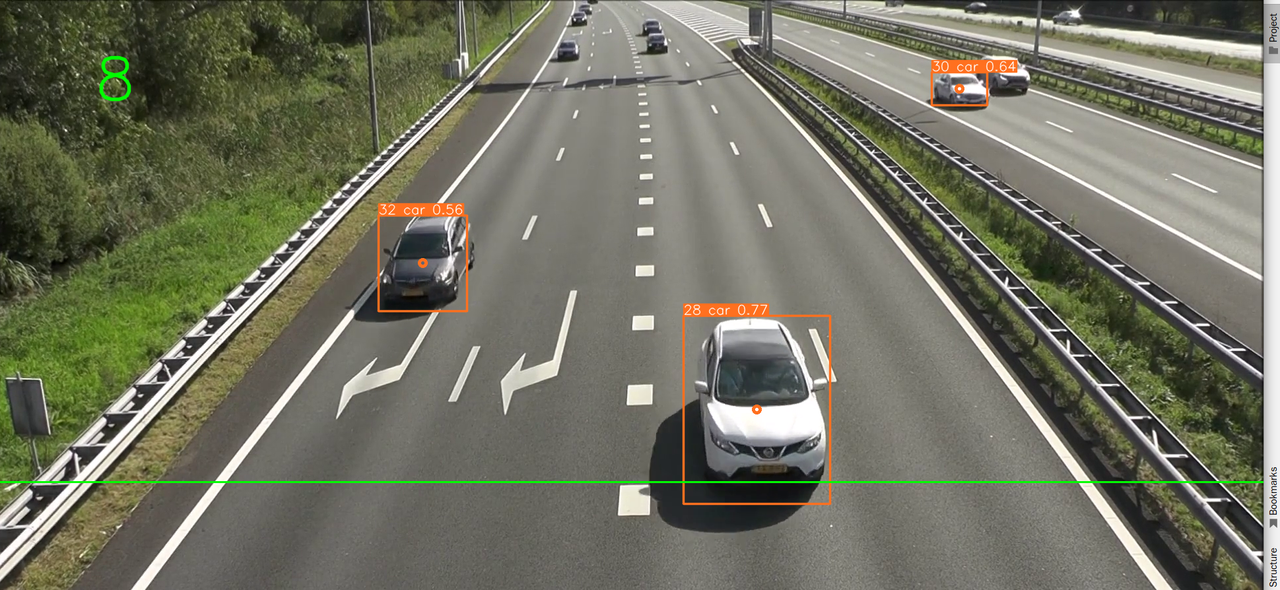
为网络视频计数的暂时不能用,运行会报错
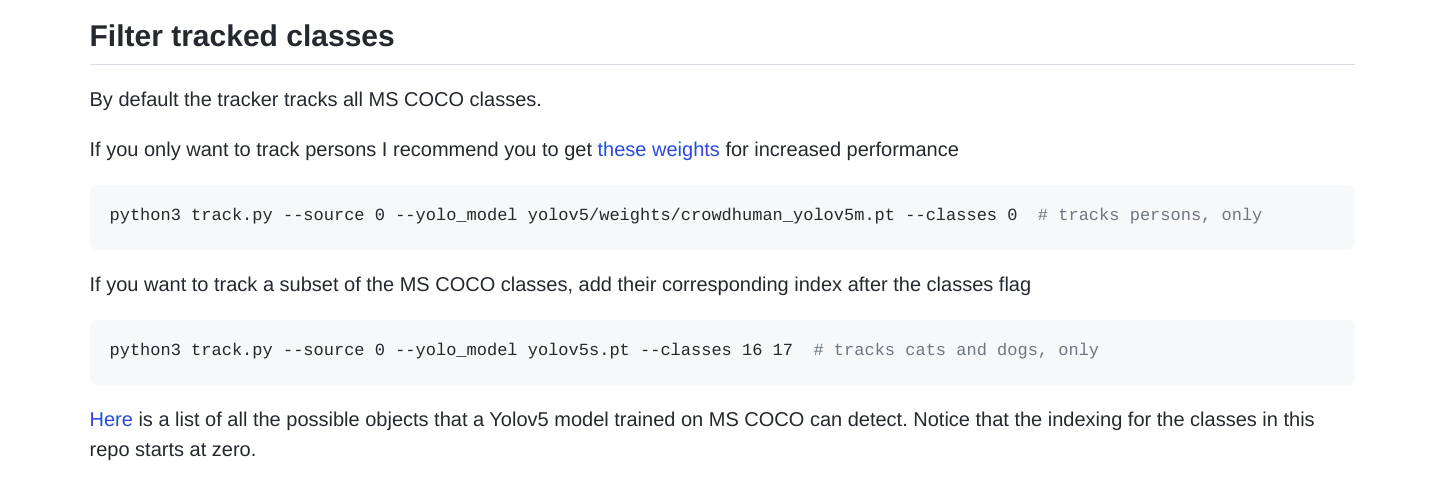
python track.py --source https://youtu.be/Zgi9g1ksQHc只识别所有类别中的某些类别Filter tracked classes
加个参数--classes即可实现序号的话参考 YOLOv5对于类别的序号,0是person,2是car
yolov5 80个类别对照表https://blog.csdn.net/ResumeProject/article/details/127601023
https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/
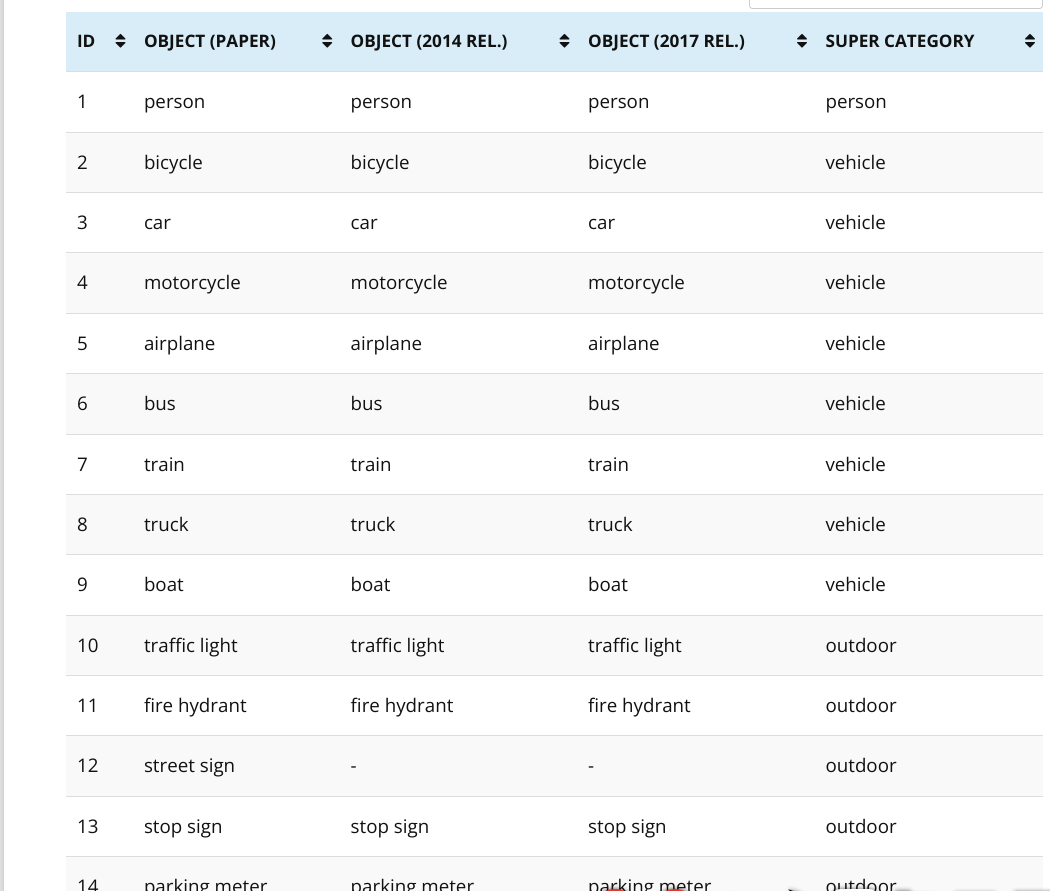
这样的话,在我们的实验场景,就可以只统计,过去的"人"的数量,小狗、小猫、自行车、电动车过去不统计
python track.py --source ./videos/Traffic.mp4 --classes 2上面这个代码是默认参数--yolo_model yolov5n.pt,也就是说上面这句等价于下面这句
python track.py --source ./videos/Traffic.mp4 --classes 2 --yolo_model yolov5n.pt上面使用的这个模型是yolov5n.pt,是基于80个类别训练的,也就是说这个模型不是专门针对人群进行识别的代码。本repo的作者推荐了一个仅仅识别人群的模型crowdhuman_yolov5m.pt,专门用来识别行人pedistrain的。
(1)调用这个模型crowdhuman_yolov5m.pt
作者的repo的这个地方提供了一个地址,你可以下载到这个模型
https://drive.google.com/file/d/1gglIwqxaH2iTvy6lZlXuAcMpd_U0GCUb/view
这个模型只能识别识别出人,如果视频中出现的都是汽车,那识别出来个数就是0了
(2)测试的数据集这个视频上面必须要有几个行人,我用的b站找的这个视频
(3)执行指令
python track.py --source ./videos/dandong.mp4 --yolo_model ./yolov5/weights/crowdhuman_yolov5m.pt --classes 0就能把视频中的人都识别出来了。并且这个模型识别行人的效果更好,你看右上 id=71的那个小人,那么小的一个人都可以识别出来。yolov5训练出来的模型是识别不出这么小的人的。足以见得专门做识别人类的crowdhuman_yolov5m模型识别的更好。

人群的视频数据集:http://visal.cs.cityu.edu.hk/downloads/
但是这个crowdhuman的模型只能识别视频,不能识别图片
python track.py --source ./image_data/bus.jpg --yolo_model yolov5/weights/crowdhuman_yolov5m.pt --classes 0 # tracks human only你用这个模型,从有人的图片里把人识别出来,识别不出来。输出保存的那个bus.jpg文件打开没有内容,是一个损坏的文件
给yolo5+deepsort人群计数增加了一个每次使用自动保存识别结果的视频文件的功能
./Yolov5_DeepSort_Pytorch/track.py的这个位置修改
# 原来的
# parser.add_argument('--save-vid', action='store_true', help='save video tracking results')
# 修改后
parser.add_argument('--save-vid', default=True,action='store_true', help='save video tracking results')5. 做自己的改造
标记的绿色的线,画的位置要距离底端30%,而不是简单固定的350px;
track.py line210
start_point = (0, int(h-0.3*h))
end_point = (w, int(h-0.3*h))
cv2.line(im0, start_point, end_point, color, thickness=1)2. 计数作为标准的那条线要是距离底端30% ,而不是简单固定的350px;
3. Object 上端和下端,任意一个纵坐标大于底端30%,就计入数字
line 268
# 只要object纵向上有一点碰到了低端的30%,就count进去
def count_obj_cross_line_any(box,w,h,id):
global count,obj_id_list
y_upper = box[1] # object的上端纵坐标
y_lower = box[3] # object的下端纵坐标
# 这个行人可以从下端进来,y_upper先大于 低端30%的纵坐标;行人也有可能从上端进来,即y_lower大于低端30%的坐标
# 两个条件满足其中之一即可,所以用or
# 行人从远处走近的可能性比从镜头后面走入然后进入画面的可能性高,所以放在or前面
if (y_lower > int(h-0.3*h)) or (y_upper > int(h-0.3*h)): # 低于70%就计数
if id not in obj_id_list:
count += 1
obj_id_list.append(id)4. 任务完成后,打印出来id列表和个数
line260加入这一句
# 将人数和id列表打印出来
# ——@@@@@ 新加的代码 @@@@@——
print("*"*50)
print("There are %s objects in total"%(count))
print("The id list : %s"%(obj_id_list))
print("*" * 50)
# ——@@@@@ 新加的代码@@@@@——