本节我们的目的是,在给定正则表达式后,将其转换为非确定性有限状态自动机数据结构,后者会进一步生成一个跳转表,从而实现字符串匹配的功能。我们首先看输入,输入是一个后缀名为lex的文件,基本内容如下:
%{
FCON = 1
ICON = 2
%}
D [0-9]
%%
(e{D}+)?
%%
在编译器开发中有一系列工具链,链条中第一个叫lex, 它的作用是你可以将字符串识别对应的正则表达式输入到一个文件中,例如上面那样,然后执行lex,后者读入文件,然后输出基于C语言的代码文件,这个代码文件实际上讲正则表达式转换成了对应的可执行的C代码,我们将生成的代码编译后就可以得到可执行的,能够识别特定字符串的程序。
我们这次要实现的lex要基于python语言,首先在lex文件中分为若干部分,第一部分由%{ %}组成,它实际上是一段python代码,通常是变量定义之类,lex程序会将这部分内容直接拷贝到给定目标文件,假设我们把目标文件命名为output.py,那么语句:
FCON = 1
ICON = 2
就会直接拷贝到output.py的顶部,具体内容我们后面再详细解读。接下来的部分是宏定义,也就是%} 到 %%这部分,这里对应的语句是:
D [0-9]
这里类似于C语言的宏定义,上面字符串表明字符D表示输入是0到9这十个数字。最后一部分介于两个%%之间,这部分定义正则表达式的具体形式,对应上面内容就是:
(e{D}+)?
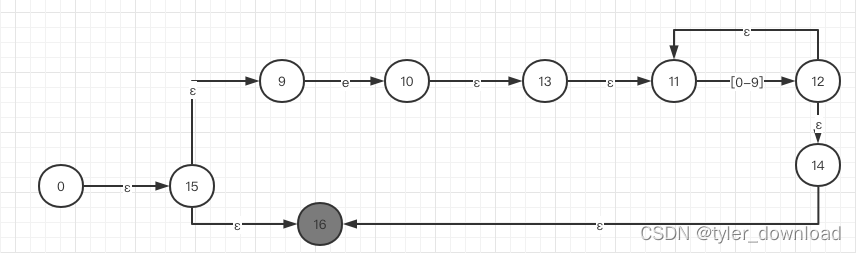
我们完成的代码将会读取这条语句,然后逐个解析其中的字符,最后构建一个类似如下的非确定性有限状态自动机:
对于这次项目完成后具体的功能演示,大家可以在B站搜索coding迪斯尼。在本节项目完成后,我们会生成特定的python代码用于实现上面给出的状态机。下面我们看看要实现代码的基本目录结构:
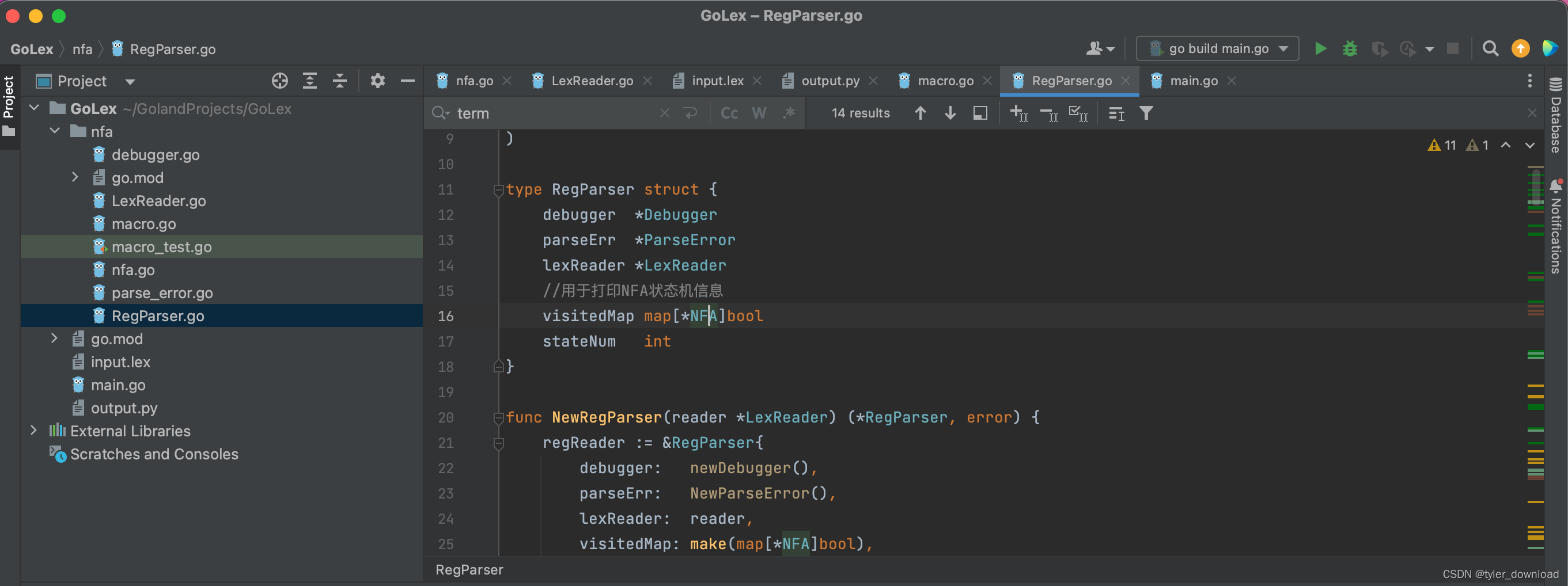
代码中最复杂的就是LexerReader.go和egParser.go,前者负责从输入文件input.lex中读取信息,当它读取到正则表达式的信息后,它需要完成两个目的,第一是将读到的字符转换为token,例如读到字符"(",它返回对应token: LEFT_PARAN,这个功能跟前面实现的词法解析一样,第二个功能是展开宏定义,在正则表达式(e{D}+)?,当它读取到{D}时,它会将其转换为宏定义对应的[0-9]进行解析。
RegParser跟前面实现的词法分析一样,用于识别token组成然后构建有限状态自动机,它同样要基于特定语法规则对正则表达式字符串进行识别,具体内容我们后面章节在详解。接下来我们看看程序的输出:
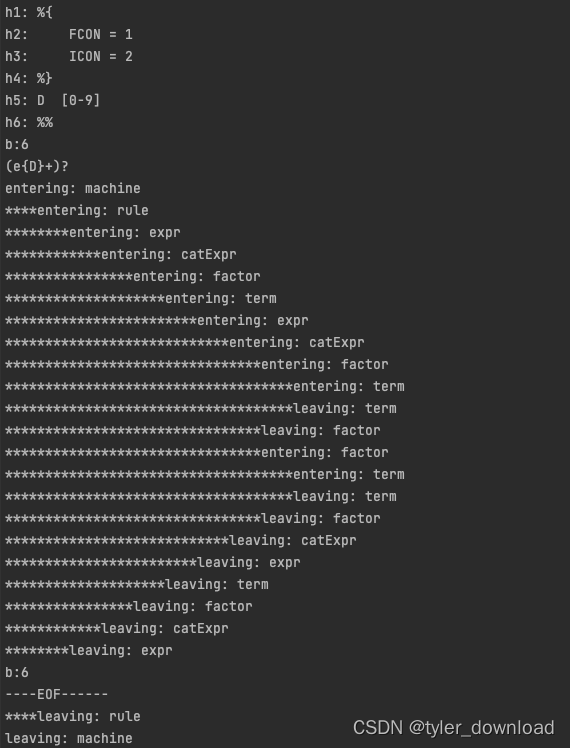
这部分是调试输出信息,从上面截图可以看到它输出了一系列函数的调用次序,上面的函数调用发生在RegParser.go里面,由于语法解析涉及到一系列递归调用,因此我们需要将其调用栈打印出来以便于分析,上面信息的输出主要由debugger.go来实现,最后输出的是NFA,也就是有限状态自动机的信息:
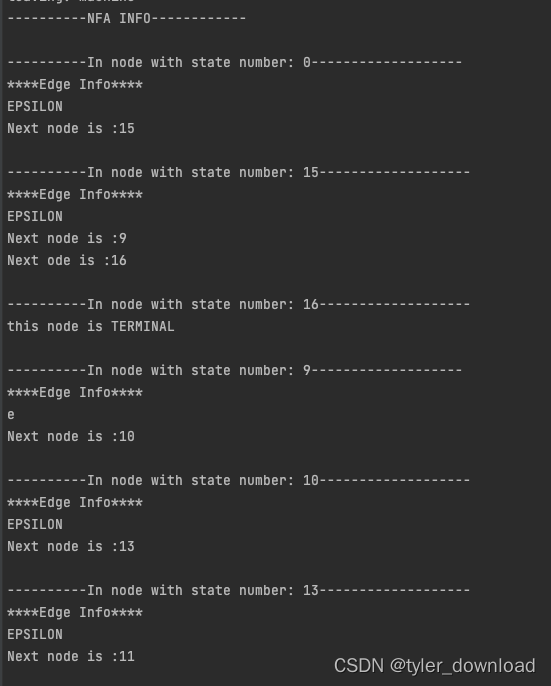
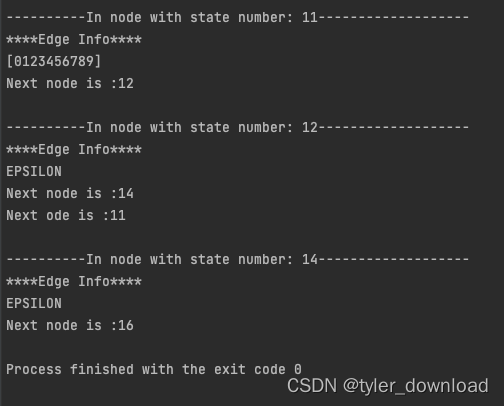
可以看到其打印的信息跟我们上面给出的状态机跳转信息一致,下一节我们将进入到代码的具体实现讲解,更多内容请在b站搜索coding迪斯尼。