在编译原理中,语法解析可能是最抽象和难以理解的部分,初学者很容易在这里卡壳。学习抽象知识的最好方法就是在初期先看大量具体实例,获得足够深厚的感性认识后,我们再对感性认知进行推理和抽象从而获得更高级的理性认知,这在哲学上称为经验主义。在学校学习知识最大的问题在于一开始就给初学者灌输抽象概念,这是一种违背人认知规律的方式,因此很容易让学生坠入云里雾里的迷糊状态,最终感觉问题太“难”从而放弃对它的学习。
我作为过来人直到在编译原理中语法解析部分的抽象性。如果你直接去读相关教程中例如大学课本或龙书中对语法解析的描述,你大概率会被其“秒杀”,因为他们描述的东西太抽象太不知所云了,因此根据我过来经验,在语法解析部分,我们最好通过具体的实例来理解。
这次我们做一个计算器,用户输入一系列算术表达式,表达式间使用分号隔开,然后我们的程序给出每个表达式的计算结果,例如输入如下:
1+2;
3+4*5;
(1+2)*(5-3)/2;
程序读入上面内容后输出如下结果:
3;
23;
3;
要完成既定功能,首要任务就是读入表达式后我们需要识别表达式想要执行的操作。前面我们在词法解析中看到,字符串在读入后词法解析会给每个字符串分配一个标签,于是表达式转变成了标签的排列,语法解析的任务就是判断标签排列是否符合规定,然后根据标签排列的情况执行特定动作。
对于表达式 1+2,经过词法解析后它变成 NUM PLUS NUM,现在问题在于这个标签序列是否合理呢,要解决这个问题我们就需要判断其是否符合算术表达式的语法。因此我们需要先设定表达式语法。语法的设定可以根据自顶向下和自底向上两种方式,我们先看第一种。自顶向下是指,我们先用一个抽象的概念描述一个整体,然后将这个概念分解成次一级的抽象概念的组合,然后次一级抽象概念继续向下分解,通过不断的分解,概念变得越来越具体,直到最后概念不再具有抽象性,它变成了具体的对象。
基于以上原则,我们首先用一个概念 stmt 来描述一系列算术表达式的集合。显然 stmt 可以分解成一个或多个用分号隔开的算术表达式 expr,于是 stmt 分解如下:
stmt -> expr SEMI | expr SEMI stmt
我们注意到右边 expr 是比 stmt 次一级的抽象概念,同时在右边还有一个具体对象那就是 SEMI 也就是分号的标签,同时右边还包括了 stmt 自己,有就是说一个抽象概念有可能分解成一个次一级抽象概念和自身的组合,这是语法解析的一个特点。
我们注意到 stmt 可以分解成 expr SEMI, 于是 stmt 本身也就能分解成多个 expr SEMI 的组合,只要我们把右边 expr SEMI stmt 中的 stmt 持续分解成 expr SEMI stmt 即可。例如我们要解析三个算术表达式:
1+2; 3+4; 5+6;
显然上面字符串的组合规律满足 stmt -> expr SEMI stmt, 于是第一个 expr SEMI 对应 1+2;,然后在将右边的 stmt 分解成 expr SEMI,于是有 stmt-> expr SEMI expr SEMI stmt,这样我们就对应了 1+2; 3+4; 最后我们将右边的 stmt 用 stmt->expr SEMI 分解,于是就有 stmt -> expr SEMI expr SEMI expr SEMI,由此三个表达式就能对应到语法规则 stmt-> expr SEMI | expr SEMI stmt
下面我们需要解析 expr 这个概念。我们可以感觉到expr 可以通过运算符+, -, * , / 分成作用两部分,这两部分都可以是 expr,于是 expr 可以解析成:
expr -> expr PLUS expr | expr MINUS expr | expr MUL expr | expr DIV expr | LEFT_PARA expr RIGHT_PARA,
但是上面的分解就会陷入死循环,因为 expr 只能分解成自身的组合,这是一种循环定义。因此在右边分解时,必须有一个不同与左边的概念,显然单独一个数字也能对应到算术表达式,因此我们还有 expr -> NUM,注意 NUM 已经是一个不能继续分解的符号,于是 expr 的分解规则为:
expr -> expr PLUS expr | expr MINUS expr | expr MUL expr | expr DIV expr | LEFT_PARA expr RIGHT_PARA
expr -> NUM
但上面的语法存在一个问题叫歧义性,也就是对同一个算术表达式1+2*3,上面语法能给出两种解析方式,第一种是先运用 expr -> expr PLUS expr,这样它能解析掉 1+2,然后再运用 expr -> expr MUL expr, 于是所得结果相当与(1+2)*3,如果我们用树形结构来表达我们的解析过程,那就是:
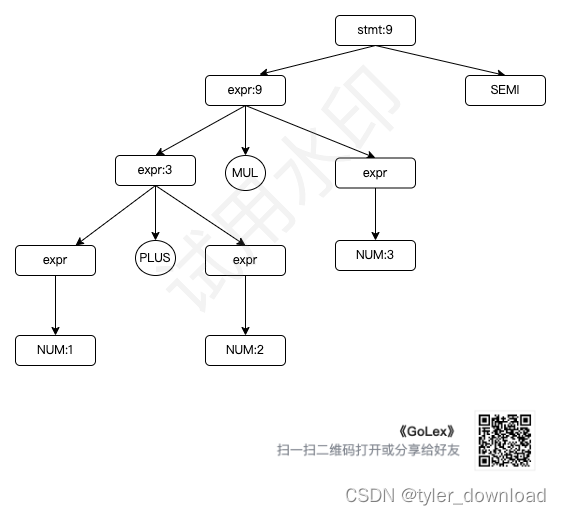
第二种是先运用 expr -> expr MUL expr, 这样就能先对应 2 * 3,然后再运用 expr -> expr PLUS expr, 于是就对应 1 + (2 * 3),这种解析方式对应的树形结构为:
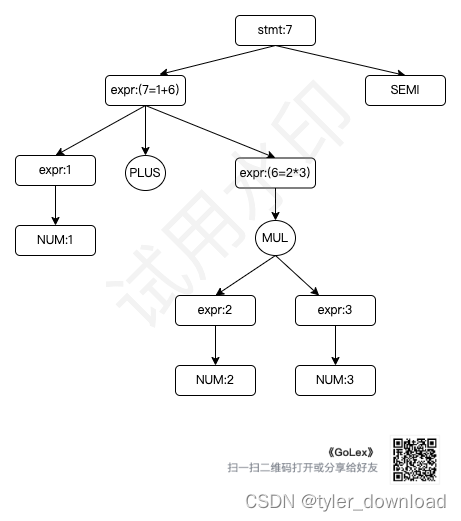
上面的树形结构也叫语法解析树,可以看到如果某个操作越早被执行,那么它对应的节点就会越接近树的底部,对于第一颗树加法先于乘法被执行,因此加法对应节点就低于乘法节点,同理在第二个解析树中,由于乘法先于加法被执行,因此它对应的节点就低于加号节点。
语法的歧义性主要是因为解析式的右边出现了至少两个以上相同的非终结符。例如 expr -> expr PLUS expr,右边就出现了两次非终结符 expr,因此我们需要改掉这个特点。修改方法是使用一个次一级的符号来替换掉右边的一个 expr,例如:
expr -> expr PLUS term
expr -> expr MINUS term
expr -> expr MUL term
expr -> expr DIV term
expr -> LEFT_PARA expr RIGHT
expr -> term
term -> NUM
于是表达式 1 + 2 * 3 就只会有 1 中解析方式,首先我们只能用 expr -> expr MUL term 来对应,于是右边 expr 就对应1+2, 于是右边 expr 再使用 expr -> expr PLUS term 来对应,因此语法解析树就是:
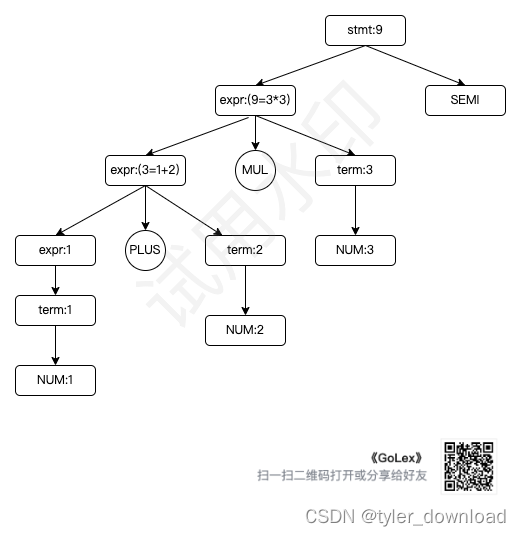
上面语法虽然解决了歧义性,但是又产生两个问题,第一个是它无法解析 1+(2*3)这样的表达式,处理起来也简单,只要去掉 expr -> LEFT_PARA expr RIGHT_PARA,然后增加 term->LEFT_PARA expr RIGHT_PARA 即可。
第二个问题是,语法没有处理运算符的优先级,在计算中乘法和除法优先于加法和减法,但在我们前面语法中是哪个运算符更加靠近左边,它的优先级就会更高。处理这个问题的方法是再加一个抽象符号factor,然后把乘法和除法往下挪动,于是语法变成:
expr -> expr PLUS term
expr -> expr MINUS term
expr -> term
term -> term MUL factor
term -> term DIV factor
term -> factor
factor -> NUM
factor -> LEFT_PARA expr RIGHT
于是根据上面语法,表达式 1 + 2 * 3 对应的解析树就是:
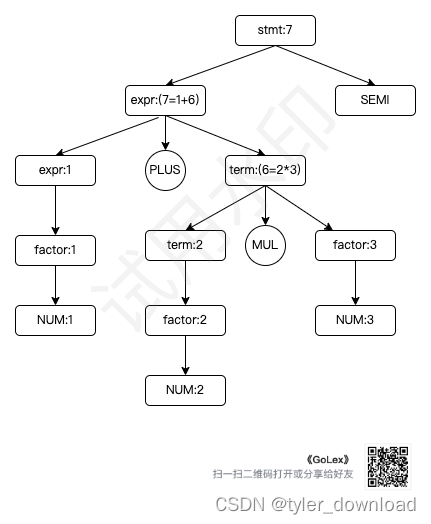
通过上面语法的修改后可以看到,在一个算术表达式中,乘法和除法优先于加法和减法,不管乘法除法操作符位于表达式哪个位置,同时括号的优先级最高,因为括号对应的表达式在所有表达式的位置最低,所以设计语法时,你要想对应操作的优先级越高,那么把出现该操作符对应的表达式方得就要越低。
在上面解析中需要注意的是,我们会根据算术表达式中的符号来确定语法表达式,如果算术表达式中包含+,-两个符号,那么我们可以用 expr->expr + term 或者 expr -> expr - term 来推导。我们把+或-前面部分再递归的使用 expr 对应表达式来推导,后面部分使用 term 来推导。问题是如果算术表达式中包含多个+或者-的时候,我们依靠哪个+或者-来将表达式分割成两部分呢。例如 1 + 2 - 3 * 4,我们是将1 分配给 expr,然后将2-3*4分配给 term,还是将 1+2-3 分配给 expr,3*4 分配给term 呢,答案是后者,因为2-3*4 分配给 term 时,它无法解析,因为 term 右边的分解中不包含+或-符号,所以推导的原则就是从左到右扫码算术表达式,找到最后一个+或者-号,再将其分成两部分,同理在进入 term 的推导时也是如此,从左到右扫描表达式,找到最后一个*或者/号时再将表达式分割成两部分。
另外在推导时我们看到无论是 expr 还是 term,它右边解析时都不包含左括号和右括号,所以 (1+2)这样的表达式我们应该怎么推导呢,由于 expr 不包含括号,因此它在从左向右扫码表达式时,我们不处理位于括号中的标签,同理在推导 term 时,由于它右边包含的表达式也不包含括号,因此它也需要忽略所有括号里面的标签。所以我们在推导 (1+2)时,首先使用 expr 表达式,我们发现它不满足 expr->expr + term, expr -> expr - term, 因此我们使用 expr -> term。然后在已经 term 推导时,发现(1+2)不满足 term->term * factor, term -> term / factor,于是推导进入 term->factor,由于 factor 右边支持括号,因此推导进入 factor -> ( expr ),这里我们去掉左右括号后,剩下的部分也就是 1+2就能放入到 expr 进行解析。
下面我们使用代码实现上面的语法解析流程。前面我们做 dragon_compiler 的时候体验过语法解析,我们本节在当时完成的 lexer 基础上去实现我们现在的算术表达式语法解析。拿来当时的 dragon compiler 代码,去掉里面的 parser 部分,增加 expression_parser 文件夹,cd 到expression-parer 目录下,使用 go mod init expression_parser做初始化,然后添加一个名为 expression_parser.go 的文件,其内容如下:
package expression_parser
import (
"fmt"
"io"
"lexer"
"math"
"strconv"
)
type Symbol struct {
token lexer.Token
value int
}
type ExpressionParser struct {
parserLexer lexer.Lexer
//用于存储一个算术表达式的所有标签
symbols []Symbol
}
func NewExpressionParser(parserLexer lexer.Lexer) *ExpressionParser {
return &ExpressionParser{
parserLexer: parserLexer,
symbols: make([]Symbol, 0),
}
}
func (e *ExpressionParser) makeSymbol(token lexer.Token) {
val, err := strconv.Atoi(e.parserLexer.Lexeme)
if err != nil {
val = math.MaxInt
}
symbol := Symbol{
token: token,
value: val,
}
e.symbols = append(e.symbols, symbol)
}
func (e *ExpressionParser) getExprTokens() error {
sawSemi := false
for true {
//读取算术表达式对应的标签,结束标志是遇到分号 s
token, err := e.parserLexer.Scan()
if err != nil && token.Tag != lexer.EOF {
errStr := fmt.Sprintf("error: %v\n", err)
panic(errStr)
}
if err == io.EOF {
return err
}
e.makeSymbol(token)
if token.Tag == lexer.SEMI {
sawSemi = true
break
}
}
if sawSemi != true {
//算术表达式没有 1️⃣ 分号结尾
errStr := fmt.Sprintf("err: expression missing semi")
panic(errStr)
}
return nil
}
func (e *ExpressionParser) Parse() {
//第一个表达式左边是 stmt 所以从调用函数 stmt 开始
e.stmt()
}
func (e *ExpressionParser) ioEnd() bool {
e.symbols = make([]Symbol, 0)
token, err := e.parserLexer.Scan()
if err != nil && err != io.EOF {
strErr := fmt.Sprintf("err: %v\n", err)
panic(strErr)
}
if err == io.EOF {
return true
}
e.makeSymbol(token)
return false
}
func (e *ExpressionParser) stmt() {
//stmt -> expr SEMI | expr SEMI stmt
e.getExprTokens()
val := e.expr(e.symbols[:len(e.symbols)-1])
if e.symbols[len(e.symbols)-1].token.Tag != lexer.SEMI {
panic("parsing error, expression not end with semi")
}
fmt.Printf("%d;", val)
if e.ioEnd() {
//所有标签读取完毕,这里采用 stmt -> expr SEMI
return
}
//这里采用 stmt -> expr SEMI stmt
e.stmt()
}
func (e *ExpressionParser) expr(symbols []Symbol) int {
if len(symbols) == 0 || symbols == nil {
panic("error token begin for expr parsing")
}
/*
读取 PLUS 或 MINUS 标签,读取到,那么标签前面部分继续用 expr 分析
后面部分用 term 分析
*/
sawOperator := false
operatorPos := 0
inPara := false
for i := 0; i < len(symbols); i++ {
/*
在将 expr 通过+,-分割成两部分时,如果遇到左括号,那么在括号内部的
+,-不作为分割的依据
*/
if symbols[i].token.Tag == lexer.LEFT_BRACKET {
inPara = true
}
if symbols[i].token.Tag == lexer.RIGHT_BRACKET {
if !inPara {
panic("expr parsing err, missing left ")
}
inPara = false
}
if inPara {
continue
}
if symbols[i].token.Tag == lexer.PLUS || symbols[i].token.Tag == lexer.MINUS {
//必须找到表达式中最后一个加号或减号
sawOperator = true
operatorPos = i
}
}
if sawOperator {
//expr -> expr PLUS term | expr MINUS term
left := e.expr(symbols[0:operatorPos])
right := e.term(symbols[operatorPos+1:])
res := 0
if symbols[operatorPos].token.Tag == lexer.PLUS {
res = left + right
} else {
res = left - right
}
return res
} else {
//expr -> term
return e.term(symbols)
}
panic("expr parsing error: should not go here")
}
func (e *ExpressionParser) term(symbols []Symbol) int {
if len(symbols) == 0 || symbols == nil {
panic("error token begin for term parsing")
}
/*
遍历标签,如果找到 MUL 或者 DIV,那么使用
term -> term MUL factor | term DIV factor
如果找不到使用
term -> factor
*/
sawOperator := false
operatorPos := 0
inPara := false
for i := 0; i < len(symbols); i++ {
/*
在将 expr 通过+,-分割成两部分时,如果遇到左括号,那么在括号内部的
+,-不作为分割的依据
*/
if symbols[i].token.Tag == lexer.LEFT_BRACKET {
inPara = true
}
if symbols[i].token.Tag == lexer.RIGHT_BRACKET {
if !inPara {
panic("expr parsing err, missing left ")
}
inPara = false
}
if inPara {
continue
}
if symbols[i].token.Tag == lexer.MUL || symbols[i].token.Tag == lexer.DIV {
//必须是表达式中最后一个乘号或除号
sawOperator = true
operatorPos = i
}
}
if sawOperator {
//term -> term MUL factor | term DIV factor
left := e.term(symbols[0:operatorPos])
right := e.factor(symbols[operatorPos+1:])
if symbols[operatorPos].token.Tag == lexer.MUL {
return left * right
} else {
return left / right
}
} else {
return e.factor(symbols)
}
panic("term parsing err, should not go here")
}
func (e *ExpressionParser) factor(symbols []Symbol) int {
if len(symbols) == 0 || symbols == nil {
panic("error token begin for factor parsing")
}
sawLeftPara := false
if symbols[0].token.Tag == lexer.LEFT_BRACKET {
sawLeftPara = true
symbols = symbols[1:]
}
sawRightPara := false
if symbols[len(symbols)-1].token.Tag == lexer.RIGHT_BRACKET {
sawRightPara = true
symbols = symbols[:len(symbols)-1]
}
if sawLeftPara && !sawRightPara {
panic("parsing factor err: missing right para")
}
if !sawLeftPara && sawRightPara {
panic("parsing factor err: missing left para")
}
if sawLeftPara && sawRightPara {
return e.expr(symbols)
}
//factor -> NUM
if len(symbols) == 0 || len(symbols) > 1 {
panic("factor->num but we have zero or more than 1 tokens")
}
if symbols[0].value == math.MaxInt {
panic("parsing factor->num error: not a number")
}
return symbols[0].value
}
上面代码需要做几方面的说明,第一是stmt 函数启动语法解析流程,它调用getExprTokens函数一次性读入一个算术表达式的所有标签,算术表达式的结尾用分号结束,因此它一直读取到遇到分号对应的 token 为止,然后它创建 Symbol 对象,改对象包含两个字段,分别是当前字符串对应的标签,如果它对应数字,那么 value 字段对应该字符串转换为数字后的数值。
根据表达式 stmt-> expr SEMI | expr SEMI stmt,函数 stmt 调用 expr 进行下一步解析。这里需要注意的有两点,第一是 expr 推导中没有括号,所以它在遍历表达式的标签时,一旦进入了括号,它就必须忽略括号内所有标签。第二点需要注意的是,根据 expr->expr PLUS term | expr MINUS term,我们需要找到标签 PLUS或者 MINUS,将标签分成两部分,前半部分继续交给 expr 解析,后半部分交给 term 解析,问题在于我们必须找到最后一个 PLUS 或者 MINUS,因为 term 解析式不能包含加号或减号,例如 1+2-34,如果我们在第一个加号处将其分解成两部分:1 和 2-34,后者传入 term 时解析就会出错,因此我们需要找到最后一个减号才能分割,也就是需要将其分解成1+2和 3*4才行,这也是 expr 进去后第一个 for 循环的工作。
如果传给 expr 的标签中找不到加号或者减号,那么他会调用 term 对传入的符号进行解析。term 的实现跟 expr 一样,首先它不支持括号,因此一旦进入到括号后,它需要忽略所有在括号内的标签。同理由于其表达式为 term->term MUL factor| term DIV factor| factor,因此它需要找到乘号和除号来将表达式分成两部分,跟 expr 一样,他必须找最后一个乘号或除号才能将标签分解成两部分,将前部分继续调用 term 分析,后部分交给 factor。
根据 factor->LEFT_PARA expr RIGHT PARA | NUM,factor 被调用时首先判断起始标签是不是左括号,如果是那么需要判断最后标签是不是有右括号,如果不是那么意味着括号缺失,如果有,那么将括号内部的所有标签交给 expr 进行解析,要是没有括号标签,那么它只能将当前标签进行数字解析,因此它需要判断当前标签只有一个,并且能解析成数字。
完成上面代码后,在 main.go 中添加代码如下:
package main
import (
"expression_parser"
"fmt"
"lexer"
)
func main() {
source := "1+(2*3)-4;(1+2)*(6/2);1+2*3-4/2;"
my_lexer := lexer.NewLexer(source)
parser := expression_parser.NewExpressionParser(my_lexer)
parser.Parse()
fmt.Println("\nparsing end here")
}
上面代码运行后所得结果如下:
my@MACdeAir dragon-compiler % go run main.go
3;9;5;
parsing end here
根据输出结果可以确认我们的代码实现是正确的。根据前面我们实现的 dragon-compiler,大家可以知道我们当前语法存在一些问题,首先就是左递归,那时我们说过左递归的语法难以用代码实现,这导致我们必须一次性读完一个算术表达式的所有标签后才能解析。第二是语法清晰度不够,这导致我们在 expr 和 term 中必须要找到最后一个加号减号或者乘号除号才能将标签分解成两部分进行解析,后续我们会给出这些问题的处理方法。
本节代码下载路径为:
https://github.com/wycl16514/compiler-implementation-of-expression-parser.git
更详细的调试演示请在 b 站搜索:coding 迪斯尼。