1. CPU 字长决定了可寻址的内存空间大小,32位CPU 最大寻址空间是2^32 = 4GiB
64位CPU 最大可寻址空间是2^64,由于在当前这个空间过于庞大,所以64位CPU只会用到地址空间一部分,具体根据系统和平台有所差异
2. 最大地址空间跟系统拥有的可用物理内存大小无关,所以叫做虚拟内存
3. 虚拟内存被划分为内核空间和用户空间,32位系统普遍采用低地址段为用户空间(user space), 高地址段为内核空间(Kernel Space)

图1 64位系统类似方法使用地址空间的某一段来当做内核空间,取另外一段为用户空间
4. Linux 权限级别
Linux 为了保护进程执行空间,将虚拟内存划分为内核区和用户区两部分,用户进程不允许访问内核区。用户进程如果想使用内核空间必须采用系统调用方法来实现,内核代替用户进程进行一些操作后再将结果返回给用户进程。
内核除了代替用户进程执行系统调用动作,还要响应底层硬件产生的异步中断,由于异步中断产生和当前的用户进程有时没任何关系,所以中断处理必须非常小心,比如中断上下文一定不能进入休眠;除了系统调用和异步中断处理,内核还有一种类似用户进程的处理方式叫内核线程,内核线程不像异步中断处理过程,它可以进入休眠。
5. 虚拟地址空间
有时进程拥有的虚拟地址空间比设备拥有的实际RAM还要大,当有多个进程采用虚拟地址空间后,系统必须考虑如何将物理可用的内存空间映射到虚拟地址空间,通常都采用页表的方式将物理内存映射到虚拟内存空间,虚拟内存被kernel 划分为相同size的页,物理内存也被分为同size的页帧。
多个进程的不同虚拟地址可以指向同一个物理页帧,内核负责将虚拟地址映射成物理地址,并决定哪些物理区域可以进程间共享,哪些区域不能。
一个页虚拟地址不是总有对应的物理页帧,这有可能由于此页对应的数据暂时不用就没有load 进memory,也有可能之前swap out 到disk /nand flash 中去了,需要重新swap back 到memory。
32 位架构系统上如果每个虚拟页都要在页表中有对应的项,那们我们kernel 需要维护上百万条的页表项,如果在64架构上那么这个问题将会急剧恶化,导致最终整个RAM 都不够存放页表。 为了解决这个问题,现在都采用分级页表的方法,只为需要用到区域做映射,不用到的区域可以被忽略。
6. 32 Linux采用三级映射:PGD-->PMD-->PTE

图2 32 位Linux 虚拟地址采用的三级映射
7. 但是在ARM32 Linux 默认采用两级映射,省略了PMD映射,只有打开了内核宏CONFIG_ARM_LPAE才会使用3级映射

图3 ARM32 虚拟地址采用两级映射
8. ARM64 Linux 采用四级映射:PGD-->PUD-->PMD-->PTE

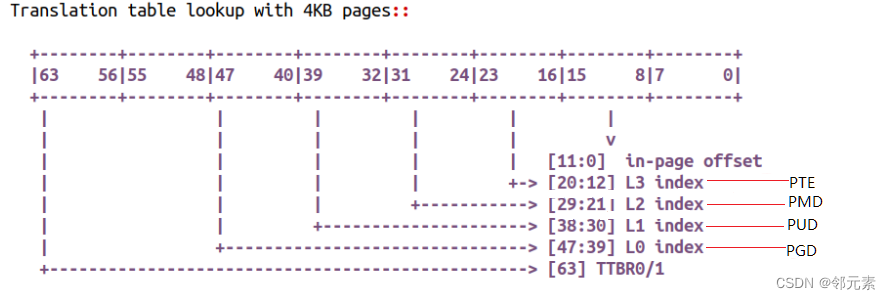
9. 多级页表可以很好的解决虚拟地址到物理地址的映射表过大问题,但由于每次对虚拟内存的访问都要经过整个转换链,导致性能开销,CPU 采用两种方式较快虚拟地址到物理地址的转化
1. CPU 专门包含一个叫做内存管理单元(MMU)的模块用于相关优化这一处理过程
2. 将高频转换的虚拟地址的数据保存到CPU 的TLB缓存中,这样下次访问这个虚拟地址的数据就不用在做地址转换或者访问RAM了,但这必须保证对应的RAM 数据被改变后,TLB对应的缓存项同步失效。
10. 物理内存分配
当分配RAM 空间时,内核需要追踪哪些页已经被分配,哪些没被分配,Linux 内核只能按页帧分配,页帧内更具体的分配交给上层lib去实现。
10.1 Linux 伙伴系统(Buddy System)
大量的内核空间指派请求需要连续的物理帧页,内核采用一种叫做 Buddy System 策略,将大小(2^n)相同的连续物理页帧放入同一个链表

系统长时间运行会导致物理内存频繁的分配和回收,导致没有大的连续页帧块,可用页帧分散在整个物理内存空间,这就叫内存碎片化,内存碎片化的减少优化手段有很多,但都不能完全消除内存碎片化,其中一种办法是在其他大的连续页帧块中间保留一些不分配页帧可以有效缓解内存碎片化。
11 内核的专属内存分配器---Slab cache
由于内核buddy system 只能按整个页帧为单位分配物理内存,User Space 可以调用标准库将将页分配为更小的单元,内核不能调用标准库,只能建立它自己的一套内存管理机制,这个机制就是Slab alloctor,它同时为内核定制一套缓存机制叫slab cache,可以根据各模块需求不同,一次申请一个大的cache,然后自己负责其指派和回收,当指派完了再由slab alloctor 再去向buddy system 申请。
11. 1 内核对于频繁使用的对象,它会定义自有的某一类型cache,当请求这一类型的对象时,就直接从cache 获得对于大小,Slab Cache自动照看buddy system,在对应类型cache 满的时候会主动去申请新的cache 空间
11.2 内核会提供各种不同大小的slab caches,内核可以直接用 kmalloc kfree进行访问。

12. 页交换和页回收
页交换--内核会将不平凡使用的页帧从RAM交换出到硬盘或者flash 中去,在需要的时候再将其加载进RAM 中,这样可以实现延展虚拟内存的目的。
页回收-- 当映射的数据发生改变后,内核需要将其数据回同步回写,这样才能保证swap out的数据再swap 进来是有效的最新数据。
13. 时针
Jiffies 时间
jiffes 时间按照100Hz 或1000Hz 的频率增加,为了节能往往还会采用动态Jiffies