为什么要有优先级:在多任务操作系统中,操作系统为了区分进程的重要程度,需要有一个衡量重要程度的指标,优先级便由此产生
一、nice值和Priority值
首先用top命令看一下当前进程的信息:
top得到:
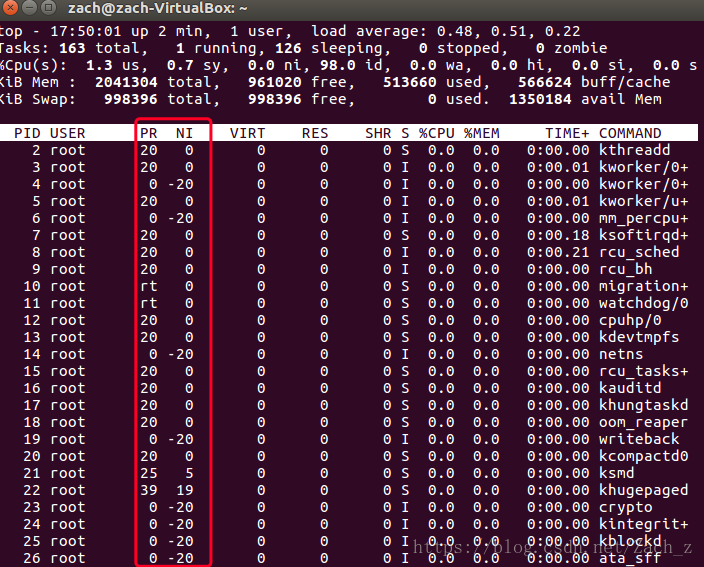
可以看到有两个属性 PR 和 NI,这两个就是Priority 和 nice值
下面来说一下这两个值什么意思
1.1 nice值
- 反应一个进程“优先级”状态的值
- 取值范围是 -20 ~ 19, 40个级别
- nice值越小,“优先级”越高
1.2 Priority值
- 优先级值
- linux上实现了140个优先级范围,取值是从0~139
- 0 ~ 99表示实时进程;100 ~ 139表示非实时进程
1.3 联系
首先,我们通过nice命令,来指定并产生一个新进程,设置命令的优先级指令如下:
nice -n [数字] [命令]使用nice打开一个nice值为10的bash:
nice -n 10 bash使用ps命令查看:
ps -l可以看到,nice值为10时,Priority的值也做了相应地改变:
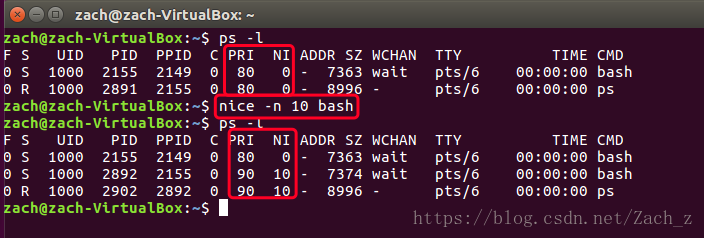
nice可以看做静态优先级,Priority可以看做动态优先级:
-20 ~ 19 的nice值可以映射为100 ~ 139的非实时进程的Priority值或者0 ~ 99实时进程的Priority值
二、实时进程和非实时进程
2.1 实时操作系统
首先了解一下实时操作系统:
- 实时操作系统(RTOS)是指当外界事件或数据产生时,能够接受并以足够快的速度予以处理,其处理的结果又能在规定的时间之内来控制生产过程或对处理系统做出快速响应,调度一切可利用的资源完成实时任务,并控制所有实时任务协调一致运行的操作系统。提供及时响应和高可靠性是其主要特点
实时操作系统又分为硬实时和软实时
- 硬实时就是必须在规定时间执行需要执行的任务
- 软实时就是稍微超过规定时间对结果影响不大
Linux严格意义上讲属于非实时操作系统,但是Priority的优先级为0 ~ 99 是对实时进程的一种描述,并且在内核设计时将实时进程单独映射了100个优先级,并且采用了更简单的调度算法来减少调度开销。
所以Linux在类型上应该可以算作软实时操作系统
所以,Linux把进程分为
- 实时进程:优先级0 ~ 99
- 非实时进程: 优先级100 ~ 139
三、调度策略
3.1 对于实时进程调度
- 谁的优先级高谁先执行
- 相同优先级则使用 SCHED_FIFO 和 SCHED_RR
- SCHED_FIFO: 先进先出方式调度,即哪个进程先执行就调度谁
- SCHED_RR: 时间片轮转方式进行调度,时间片长度为100ms
可以通过chrt命令查看、设置一个进程的实时优先级状态
3.2 对于非实时进程调度
3.2.1 O1调度
按照字面意思可以看出,O1调度算法的时间复杂度为O(1)
O1调度器根据经典的时间分配思路来设计,即将CPU的执行时间分成一段一段,优先级高的进程使用大一点的时间片,优先级低的进程使用小一点的时间片
O1调度器的处理流程:
- 进程产生(fork)的时候会给一个进程分配一个时间片长度,父子进程均分原进程时间片(防止进程通过fork方式让自己处理的任务一直有时间片); 在第一轮时间片耗尽后,系统重新分配时间片长度(防止”子孙”进程的时间片太短,造成不公平)
针对所有正在执行或在可执行队列中的进程,O1算法维护两个队列组织进程;
活动队列:存放时间片未被耗尽的进程 过期队列:存放时间片被耗尽的进程在每个系统时钟中断(Systick,1000Hz)对正在CPU上执行的进程进行检查:
1. 检查当前正在占用CPU的进程的时间片是否耗尽 2. 是否有更高优先级的进程在活动队列等待调度如果存在任意一种情况,则把当前进程的执行状态终止,放到等待队列中,换当前在等待队列找那个优先级最高的那个进程执行
CPU消耗型和IO消耗型进程
O1算法对于相同nice值的进程,再根据其占用CPU的情况将其分成两种类型:
1. CPU消耗型:总是要一直占用CPU进行运算,分给它的时间片总是会被耗尽之后,程序才可能发生调度(各种算术运算,数据处理)
2. IO消耗型:经常时间片没有耗尽就主动先释放CPU(vim,shell,跟人交互的进程)
增大IO消耗型进程的优先级
因为CPU消耗型占用CPU时间长,IO消耗型进程会很快释放CPU,如果相同nice值情况下,CPU消耗型进程会每次消耗完时间片才进行调度
所以内核会观察进程对CPU消耗状态,动态调整Priority的值,调整范围在+-5,使IO消耗型优先级增大,CPU消耗型优先级减小,避免CPU消耗型占用CPU过长所带来的卡顿感
这也是Priority被称为动态优先级的原因
3.2.2 CFS调度
由于O1,对多核,多CPU系统的支持性能不好,Linux2.6.23之后开始启用CFS作为对一般优先级(SCHED_OTHER)进程的调度方法
核心思想:n个进程,在比较小的时间内,把n个进程都执行一遍
比较小的时间 = 在R状态(执行或可执行队列中)进程被调度的最大延迟时间
进程越多,进程在周期内被执行的时间会被平分的越小
调度器对所有进程维护一个累积占用CPU时间数:vruntime
所有待执行进程都以vruntime为key放到一个由红黑树组成的队列中,每次调度执行的进程,都是红黑树最左子树上的进程(即vruntime时间最少的进程)
CFS调度器在时钟中断里进行调度检查,发生调度的时机可以总结为:
- 当前进程的状态转换时,主要是指当前进程终止退出或者进程休眠的时候
- 当前进程主动放弃CPU时
- 当前进程的vruntime时间大于每个基金成的理想占用时间时
- 当进程从中断、异常或系统调用返回时,发生调度检查
CFS优先级
- 对于CFS来说,优先级以时间消耗(vruntime增长)的快慢来决定
- 不同由下级的进程时间增长的比率是不同的,高优先级进程时间增长的慢,低优先级时间增长的块
- 比如优先级为19的进程,CPU占用1s,vruntime记录1s;但优先级为-20的进程可能占CPU 10s,vruntime才记录1s
- 每差一级CPU占用时间差为10%,计算好的结果放在数组里,用的时候直接到数组中取,减少CPU消耗时间
最小CPU占用时间
CFS设计了一个sched_min_granularity_ns参数,用来设定进程被调度执行之后的最小CPU占用时间,一个一个进程被调度执行后至少要被执行这么长时间才会发生调度切换
预期延迟时间
无论到少个进程要执行,它们都有一个预期延迟时间,即:sched_latency_ns,即每一个这个时间内执行一遍n个进程
如果进程数n很大,平均每个进程占用的CPU时间为sched_latency_ns/n很小,sched_min_granularity_ns用来限制了最小执行时间
新进程的vruntime值
CFS对每个CPU的执行队列维护一个min_vruntime值,这个值记录了CPU执行队列中vruntime的最小值
当队列中出现一个新建的进程是,它的初始化vruntime将不会设置为0,而是根据min_vruntrme的值为基础来设置
CFS对IO消耗型进程的处理
因为IO消耗型进程占CPU时间短,休眠时候进程的vruntime保持不变,休眠被唤醒后,进程的vruntime会比其他进程小很多
所以CFS对IO消耗型进程进行时间补偿:
如果进程是从sleep状态被唤醒的,而且GENTLE_FAIR_SLEEPERS属性的值为true,则vruntime被设置为 MAX(sched_latency_ns/2 , vruntime)
CFS的其他调度策略
- SCHED_BATCH: 只认为进程是CPU消耗型
- SCHED_IDLE: 调度器认为这个优先级很低,比nice值为19的优先级还低
CFS比O1的优势:
多核时,每个核都维护一个调度队列,每个CPU都对自己的队列进程调度即可
每个CPU一个队列,就可以避免对全局队列使用大内核锁,从而提高了并行效率