第二篇数据库操作
Android默认使用了SQLite数据库,在应用程序开发中,我们使用最多的无外乎增删改查。纵使操作简单,也有可能出现查找数据缓慢,插入数据耗时等情况。本篇内容将介绍一些提高的数据库性能的规范实践,帮助大家更高效地使用数据库。
2.1 避免频繁的开关DB
我们一般会在每次增删改查中开关数据库,对于可能频繁使用DB对象的情况,为了提高性能,在保证DB对象单例的情况下,可以对DB的开关进行方法封装,方法内对开关进行操作计数。
如果计数由0到1,则getXXDatabase并返回,否则返回已get的DB对象;同理,如果计数由1到0,则说明已经是申请的最后一次操作,执行close关闭。
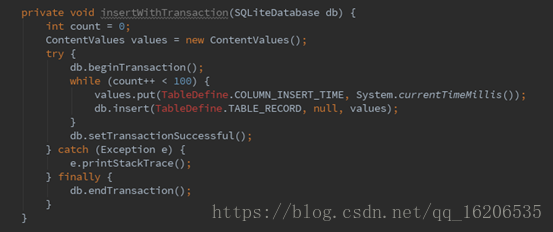
2.2 显示地使用事务
在Android中,无论是使用SQLiteDatabase的insert,delete等方法还是execSQL都开启了事务,来确保每一次操作都具有原子性,使得结果要么是操作之后的正确结果,要么是操作之前的结果。
然而事务的实现是依赖于名为rollback journal文件,借助这个临时文件来完成原子操作和回滚功能。既然属于文件,因而对于批量的修改操作会出现反复打开文件读写再关闭的操作。但通过显式使用事务,系统将在批量和多种操作过程中,控制journal文件打开关闭降低到1次,显著提高性能。
2.3 优化ColumnIndex的调用
2.3.1 按需获取数据列检索信息
通常情况下,我们处于自己省时省力的目的,对于查找使用类似这样的代码。

其中上面方法的第二个参数类型为String[],意思是返回结果参考的colum信息,传递null表明需要获取全部的column数据。良好的规范要求仅仅传递真实需要的字符串数据对象,表明需要的列信息。
2.3.2 提前获取列索引
当我们需要遍历cursor时,我们通常的做法是这样:
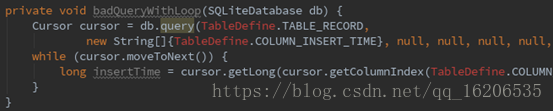
良好的规范要求,将获取ColumnIndex的操作提到循环之外,理想情况下,如果index已经固定的话,不再使用cursor去get,而是直接赋值。
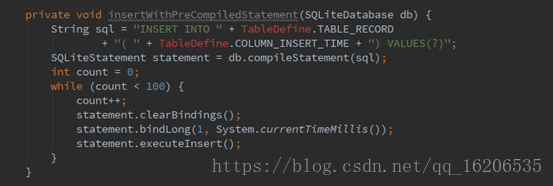
2.4 批量处理插入或者更新使用预编译
SQLite想要执行操作,需要将程序中的sql语句编译成对应的SQLiteStatement,比如select *from record这一句,被执行100次就需要编译100次。对于批量处理插入或者更新的操作,我们可以使用显式编译来做到重用SQLiteStatement。
基本步骤如下:
- 编译sql语句获得SQLiteStatement对象,参数使用?代替,比如:
SQLiteStatement statement =database.compileStatement("insert into emperors(name,dynasty,start_year)values(?,?,?)");
- 在循环中对SQLiteStatement对象进行具体数据和column的绑定,bind方法中的index从1开始。
一个批量插入示例如下:
2.5 ContentValues的容量调整
SQLiteDatabase提供了方便的ContentValues简化了我们处理列名与值的映射,ContentValues内部采用了HashMap来存储Key-Value数据,ContentValues的初始容量是8,如果当添加的数据超过8之前,则会进行双倍扩容操作。
良好的规范要求,对ContentValues填入的内容进行估量,设置合理的初始化容量,减少不必要的内部扩容操作。
2.6 SQLite语句的String拼装使用StringBuild
使用数据库的时候,经常会使用到CREATETABLE, INSERT INTO语句等,会创建大量的String对象。
规范要求,在拼装语句时,使用String.format或者StringBuilder相关接口代替,其中后者性能最优。
2.7 清晰的查询
使用明确的查询语句,避免不必要的like模糊查询;
不要用Having,其要遍历所有的记录,性能较差。
2.8 清晰的索引
对于索引字段,最好不要在字段上做计算、类型转换、函数、空值判断、字段连接操作,这些操作都会破坏 索 引原本的性能。当然,索引一般都出现在Where或是Order by字句中,所以对Where和Order by子句中的子段最好不要进行计算操作,或是加上什么NOT之类的,或是使用什么函数。
2.9 部分结果集策略
使用Limit关键字,结合order by我们可以返回符合查询需求的部分数据集,根据业务的需要,分批分页加载符合用户的需求的数据,可以加快DB查询和后续数据业务处理。
所以,如果没有特别需求,不要一次性获取所有数据集。
2.10 多表策略
数据库IO不支持读写并发,需要在java层自行维护同步锁。由于并发情况下,锁是非常非常影响性能的,再加上事务锁,以及各种写优先还是读优先机制的维护,对性能有不同的影响。
性能最高的是不要锁,所以:
尽可能分库分表,可以适当冗余数据,减少一致性事务处理,可以有效地提高性能;
同理,尽可能的减少多表查询;
2.11 简化数据封装结构
针对性的设计查询接口和返回值类型,查询返回数据简单情况下,如能使用一个map返回,就不要创建大量对象。
示例
/**
* 进行查询
* @return 查询list
*/
public synchronized ArrayList<DeviceListTable> getDeviceList()增加提供专项接口:
/**
* 进行查询
* @return 查询map
*/
public synchronized Map<String, String> getDeviceIdIconMap()2.12 耗时异步化
数据库的操作,属于本地IO,通常比较耗时,如果处理不好,很容易导致ANR。
良好的规范要求,如非可证实的简单查询,都应将DB耗时操作放入异步线程中处理,至于异步任务本身的高效实现,请参考异步任务和多线程篇。
2.13 扩展
2.13.1 读写并发
SQLiteDataBase 在API 11多了一个属性 ENABLE_WRITE_AHEAD_LOGGING。通过enableWriteAheadLogging()打开,通过disableWriteAheadLogging()关闭,默认是关闭的。这个属性关闭时,不允许读、写同时进行,通过锁来保证。
当打开时,它允许一个写线程与多个读线程同时在一个SQLiteDatabase上起作用。实现原理是写操作其实是在一个单独的文件,不是原数据库文件。所以写在执行时,不会影响读操作,读操作读的是原数据文件,是写操作开始之前的内容;在写操作执行成功后,会把修改合并会原数据库文件。此时读操作才能读到修改后的内容。但是这样也将花费更多的内存,属于通过空间换时间的策略,必要时使用。
