第二章 预备知识
本章主要介绍编写 myos 所需的基础知识。包括 8086 虚拟机的基本组成,以及8086 汇编语言程序设计的相关知识。你如果已经掌握了这些内容,可以越过本文。
2.1 8086 虚拟机
什么是 8086 虚拟机?前面已经讲了,编写操作系统需要一台目标机来调试与运行,目标机当然既可以是一台实际的计算机,也可以是虚拟机,为了简单与方便起见,myos 选择虚拟机作为目标机。正如第一章介绍的那样,VMware Player 虚拟的是 x86 系列机,由于 myos只考虑 8086,因此我们把 CPU 是 x86 的虚拟机简称为 8086 虚拟机。
8086 CPU 是 Intel 公司于 1978 年设计开发的 16 位微处理器芯片。8086 向前兼容最早的 8 位机 8080,向后是 x86 架构的鼻祖。选择 8086 虚拟机作为编写 myos 的目标机,一方面是因为 8086 相对简单,便于掌握,另一方面了解 8086 也是学习 x86 系列 CPU 的基础。从编写操作系统的角度来看,关于 8086 虚拟机,我们需要掌握 8086 的各种寄存器功能、8086 汇编编程、8086 访存机制以及 8086 中断机制等基本知识。这一节主要介绍 8086寄存器的功能以及 8086 访存机制,下一节介绍 8086 汇编编程,第七章介绍 8086 中断机制。
2.1.1 8086 寄存器功能
为什么要了解寄存器?因为操作系统直接运行在硬件之上,因此编写操作系统离不开汇编语言,而用汇编语言编程则必须掌握 CPU 相关寄存器的功能与用法。什么是寄存器?寄存器就是存储单元,并且是在控制器里面的存储单元。注意这里说的是控制器,不是 CPU,CPU 是控制器的一种。在控制器里面,寄存器的数量从几十个到几百个不等,控制器越复杂,寄存器的数量越多。有些寄存器里面保存的数只是普通的数,有些寄存器里面保存的数则具有特殊含义或功能。8086 共有 14 个 16 位的寄存器,包括 4 个通用寄存器,4 个段寄存器,5 个指针寄存器和 1 个标志寄存器。如图 2-1 所示。
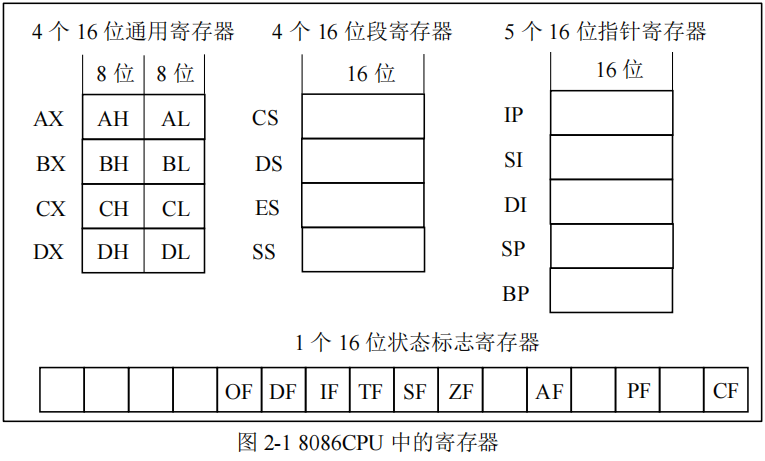
1、通用寄存器
8086 有 4 个 16 位的通用寄存器,分别是 AX(Accumulate register)、BX(Based register)、CX(Count register)和 DX(Data register)。通用寄存器的意思是里面保存的数是普通的数,在程序中给这 4 个寄存器任意赋值,其结果不会对系统运行造成很大影响。但是这些通用寄存器还是有一些约定俗成的用法,其中 AX 用做累加器,保存一些运算结果;BX 保存一个基地址;CX 主要用作计数器,通常保存循环变量;而 DX 则除了用作普通数据寄存器之外,还常用于保存端口地址,以便访问外部设备。可以用各种寻址方式给通用寄存器赋值,比如:
MOV AX,100 ;立即数寻址,把 100 赋值给 AX 寄存器。
MOV BX,AX ;寄存器寻址,把 AX 中的数赋值给 BX。
MOV CX,[0x2000] ;直接寻址,把内存 0x2000 单元中的数赋值给 CX。
MOV DX,[CX] ;寄存器间接寻址,把 CX 中的数所指内存单元中的数赋值给 DX。为了与之前的 8 位机 8080 兼容,每个 16 位的通用寄存器还可以当作两个 8 位通用寄存器来用,比如 AX 寄存器当作 8 位寄存器来用时,分别用 AH(高 8 位)和 AL(低 8 位)来表示,如图 2-1 所示。编程时既可以直接给一个 16 位的寄存器赋值,也可以单独给一个8 位的寄存器赋值,比如:
MOV BX,100 ;此时 BH=0,BL=0x64。
MOV CH,300 ;不能这样做,因为 CH 放不下 300 这个数。
MOV AL,23 ;只能保证 AL=23,AH 中还是原来的数。2、段寄存器
8086 有 4 个 16 位的段寄存器,分别是代码段寄存器 CS(Code Segment);数据段寄存器 DS(Data Segment);堆栈段寄存器 SS(Stack Segment)和扩展段寄存器 ES(Extra Segment)。段寄存器主要用于保存内存的段地址,与下面介绍的指针寄存器配合生成最终的内存单元地址。
段寄存器只能通过寄存器寻址方式来赋值,也就是说只能把通用寄存器中的值赋值给段寄存器,而不能把一个数直接赋值给段寄存器,一般都用 AX 寄存器来给段寄存器赋值。因为段寄存器中的值是内存单元的段地址,因此不能随意给段寄存器赋值,尤其是代码段寄存器 CS,只能通过转移指令来隐含赋值,而不能在程序中显式赋值。
3、指针寄存器
8086 有 5 个 16 位的指针寄存器,分别是源地址索引寄存器 SI(Source Index)、目标地址索引寄存器 DI(Destination Index)、基地址指针寄存器 BP(Base Pointer)、指令指针寄存器 IP(Instruction Pointer)和堆栈指针寄存器 SP(Stack Pointer)。这些寄存器主要用于和各段寄存器配合生成内存单元的地址。
SI 寄存器和 DI 寄存器既可以与 DS 段寄存器配对,也可以与 ES 段寄存器配对,一般用于对内存中数据块的访问,其中 SI 用于指出源地址,DI 用于指出目标地址。BP 寄存器顾名思义用于存放间接寻址时的基地址,当它作为间接寻址时,默认的段寄存器是 SS。IP寄存器只能和 CS 段寄存器配对,用于指出 CPU 即将要执行的下一条指令的地址,因此在程序中不能给 IP 赋值,以免使程序失去控制。SP 寄存器只能和 SS 段寄存器配对,用于指出堆栈的地址。注意观察图 2-1 中各段寄存器与各指针寄存器的对应关系。

除 IP 寄存器外,可以用立即数寻址方式或寄存器寻址方式给其余4个指针寄存器赋值。
4、状态标志寄存器
8086 有 1 个 16 位的标志寄存器。该寄存器虽然有 16 位,但只有其中的 9 位有意义,这 9 位包括 6 位状态位和 3 位控制位。6 位状态位分别为辅助进位标志(AF)、进位标志(CF)、溢出标志(OF)、奇偶标志(PF)、符号标志(SF)和零标志(ZF),状态位主要由运算器的运算结果来影响;3 位控制位分别为方向标志(DF)、中断允许标志(IF)和跟踪标志(TF)。无论状态位还是控制位,都需要通过具体的指令来访问,编程人员无需知道具体每一位的位置。
上面简单介绍了 8086 CPU 中的各寄存器,你将在后面的汇编编程中具体看到各寄存器的详细用法。
2.1.2 8086 访存机制
首先,内存由很多的存储单元组成,每个存储单元能保存一个字节的二进制数。其次,每个存储单元都有一个唯一的地址,地址也是一个二进制数,通过地址来区别不同的存储单元。第三,CPU 每次把地址送到地址线上,选中某个存储单元,然后才能读写这个存储单元中的数。如图 2-2 所示。图中数据线上的标记表示当选通 0x1234 内存单元后,CPU 可以读取该内存单元的值 0x55,也可以把 CPU 内的值 0xAA 写入该单元。注意地址线与数据线的箭头标记。

第四,一个 CPU 能读写多少个存储单元,换句话说,CPU 能访问的内存空间有多大,取决于这个 CPU 的地址线条数。如果某 CPU 只有 2 条地址线,则通过这 2 条地址线只能送出 4 个二进制数地址:00、01、10 和 11,能区分 4 个存储单元,也就是该 CPU 的访存空间是 4B;如果某 CPU 有 8 条地址线,则通过这 8 条地址线可以送出 256 个二进制数地址:00000000、00000001、……、11111110 和 11111111,能区分 256 个存储单元,也就是该 CPU的访存空间是 256B。依次类推,8086 CPU 有 20 条地址线,通过这 20 条地址线可以送出 2^20个二进制数地址,其地址范围为 0x00000—0xFFFFF,能区分 220=1M 个存储单元,也就是8086 的访存空间为 1MB。如图 2-3 所示。

那么 16 位的 8086 CPU 又如何给出 20 位的内存地址呢?8086CPU 为了能访问 1MB 的内存空间,在如何访问内存的机制上引入了“段”的概念。段就是内存空间的一块区域,引入段的概念后,内存中每个存储单元一维的线性地址就可以用“段地址:段内偏移”这样一个二维地址来描述,段地址是某段在内存中第一个存储单元的地址,段内偏移是段内某个存储单元在该段内的相对位置。
如果某段在内存中从内存地址 0x12342 开始,则一维线性地址 0x1234E 对应的二维地址就是 0x12342:0x0C,即此时段地址是 0x12342,段内偏移是 0x0C;如果某段在内存中从内存地址 0x12348 开始,则一维线性地址 0x1234E 对应的二维地址就是 0x12348:0x6,即此时段地址是 0x12348,段内偏移是 0x6,如图 2-4 所示。显然二维地址中段地址加上段内偏移就是一维的线性地址,而相同的一维地址可以用不同的二维地址表示。

如前所述,8086CPU 设计了 4 个 16 位段寄存器和 5 个 16 位指针(即偏移量)寄存器,这些寄存器就是用来保存 8086CPU 访问内存中某段时的段地址及段内偏移地址。由于段寄存器是 16 位而段地址是 20 位,因此规定每个段的 20 位段地址中最低 4 位必须为 0,因此在 8086 中前述的 0x12342 和 0x12348 就都不能作为段地址,下一个合理的段地址只能是0x12350,如图 2-5 所示。这样在段寄存器中只需保存 20 位段地址的高 16 位(0x1235)就可以了,低 4 位的 0 不用保存,但在生成一维的 20 位地址时需要在段地址的低位添加上这4 个 0。另外由于指针寄存器也都是 16 位,即段内偏移地址最多也只能是 16 位二进制数,因此每个段的最大段长为 64K。

8086 把在内存中存放程序的段叫做代码段,代码段中每个存储单元的二维地址由段寄存器 CS 与指令指针 IP 配对指出。例如 8086CPU 在上电瞬间,通过硬件逻辑电路使CS=0xFFFF,IP=0x0000,因此 CPU 执行的第一条指令的地址为 CS:IP=0xFFFF:0x0000,对应的一维线性地址是 0xFFFF*0x10+0x0000=0xFFFF0。如第一章所述,这个地址也就是 BIOS的入口地址,可以猜测,BIOS 的第一条指令是跳转指令(想想为什么)。以后每条指令的地址要么由指令指针寄存器 IP 自动加数生成(顺序执行),要么通过跳转指令来设置(分支执行)。在程序中不能显式给 CS 和 IP 寄存器赋值。8086 把在内存中存放数据的段叫做数据段,数据段中每个存储单元的二维地址由段寄存器 DS 与 SI 或 DI 配对指出,对应的一维线性地址是 DS*0x10+SI(或 DI),DS*0x10 表示 DS 中的 16 位段地址低位补 4 个 0。
8086 把在内存中用于堆栈的段叫做堆栈段,堆栈段中每个存储单元的二维地址由段寄存器 SS 与堆栈指针 SP 配对指出,对应的一维线性地址是 SS*0x10+SP。
8086 在内存中还预备了一个段叫做扩展段,扩展段中每个存储单元的二维地址由段寄存器 ES 与基址指针 BP 配对指出,对应的一维线性地址是 ES*0x10+BP。
综上所述,8086CPU 访问内存单元的地址由各段寄存器和各指针寄存器中的值生成,在汇编语言程序中按规则使用各段寄存器和指针寄存器,就能读写 1MB 内存空间的任意一个存储单元。这里需要强调一点,每个内存单元的 20 位地址都是通过段地址和偏移量计算而来,但一般在汇编程序中有时候只会给出偏移地址,所以一定要搞清楚这个偏移地址对应的是哪一个段寄存器,这个段寄存器中的值是否合适。
当程序比较小时,可以把代码段、数据段和堆栈段都放在一个段中,此时只需要让 CS、DS 和 SS 都指向这个段即可。
这里还需要澄清两个概念,这些概念在有关 8086 的资料中容易引起混淆。
一个是最小模式和最大模式。8086 可以工作在最小模式或最大模式。最小模式是指系统中只有 8086 处理器;最大模式是指系统中除主处理器 8086 以外,还有协处理器 8087 或8089。最小模式和最大模式与 8086 的访存没有关系。
另一个是实模式与保护模式。实模式就是 8086 的访存模式,20 位地址所映射的 1MB内存空间可以任意访问,在程序中给出的任何一个内存地址都是实实在在的物理地址,对应的是实实在在的物理内存单元,没有硬件级别的内存保护机制和多任务的工作模式。保护模式是 80286 及以上处理器的访存模式,在保护模式下,访存空间为 16MB(24 条地址线)或4GB(32 条地址线),系统配置了内存管理单元(MMU,Memory Manage Unit),为实现虚拟存储器和支持多任务提供了内存共享及保护的硬件支持,在程序中给出的任何一个内存地址都是虚拟地址,普通用户见不到真实的物理地址。在保护模式下编写操作系统,需要了解更多的复杂硬件机制,编程更加复杂且不易掌控。
本教材只考虑 8086 的实模式,在此模式下实现一个基本的操作系统框架。
2.1.3 BIOS 之后的内存映像
如前所述,8086CPU 的内存地址空间是 0x00000—0xFFFFF,那么这 1MB 的内存空间,myos 应该怎么用呢?如果电源打开,CPU 执行的第一条指令就是 myos,那么这偌大的内存空间就完全由 myos 来管理,你想怎么用就怎么用。不幸的是电源打开的瞬间,CPU 首先执行的不是 myos,而是 BIOS。因此,等到 myos 接管系统后,1MB 的内存空间就不是全部供myos 支配,而是有些被 BIOS 自己占用,有些被 BIOS 分配给其他部件,myos 只能使用 1MB内存空间的一部分。因此,所谓 BIOS 之后的内存映像,就是当 myos 接管系统后整个内存空间的使用分布情况。
首先,BIOS 需要把中断向量表复制到内存地址的最低端,中断向量表共占用 1KB 内存空间,地址范围为 0x00000-0x003FF。关于中断向量表,第七章再详细介绍。
其次,BIOS 还要把自检时产生的一些系统参数复制到内存地址的低端,以便 myos 接管后参考使用,这些参数区称为 BDA(BIOS Data Area),共 256 字节,地址范围为 0x00400-0x004FF。
第三,BIOS 会把 MBR 加载到内存地址的低端,如前所述,MBR 占用 512 字节,其地址范围为 0x07C00-0x07DFF。
第四,BIOS 会把 EBDA 复制到内存地址的高端,EBDA(Extended BIOS Data Area)占用 1KB,其地址范围为 0x9FC00-0x9FFFF。
第五,0xA0000-0xBFFFF 为系统设定的显存区域,大小为 128KB。关于显存,第五章会详细介绍。
第六,0xC0000-0xC7FFF 为显卡 BIOS,ROM 区域,大小为 32KB。
第七,0xC8000-0xEFFFF 映射为其他硬件,ROM 区域,大小为 160KB。
第八,BIOS 自己驻留在内存地址的最高端,ROM 区域,大小 64KB,地址范围为 0xF0000-0xFFFFF。
除了上述区域,其他地址空间可供 myos 自由使用,如图 2-6 所示。
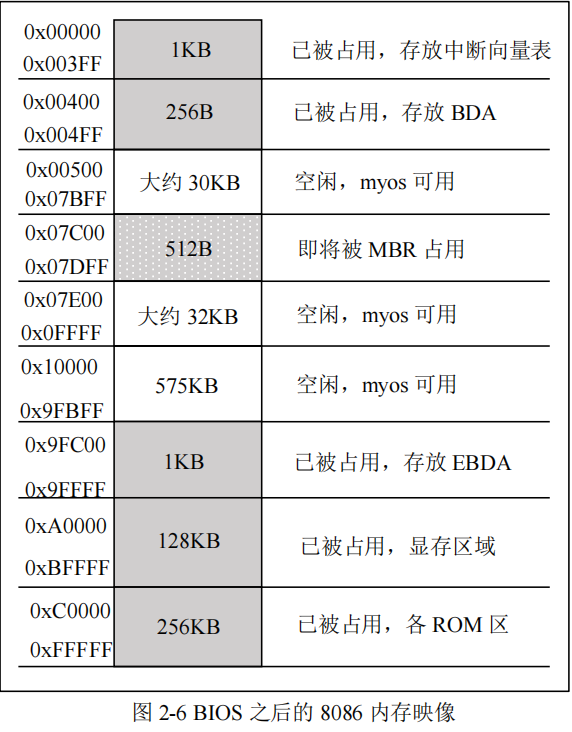
图中白色部分可被 myos 任意使用,灰色部分虽然已被 BIOS 占用,但除了 ROM 区域外,其他部分仍可以被 myos 访问,只是访问时一定要搞清楚各区域中数据的含义,否则可能会导致系统不可知。myos 初步设定从 0x10000 开始加载。
2.2 8086 汇编语言编程
汇编语言编程就是用汇编指令编写程序,汇编指令就是机器指令的汇编形式,即用助记符来表示机器指令,比如在 8086 中“把寄存器 AX 中的值压入堆栈”这条机器指令的机器码是一个字节 0x50,对应的汇编指令是“PUSH AX”;再比如“给寄存器 AH 赋值 0”这条机器指令的机器码是两个字节 0xB4、0x00,对应的汇编指令是“MOV AH,00”。直接用机器码编写程序,非常困难;用汇编指令编写的程序要用汇编器 NASM 汇编成机器码,才能让 CPU 执行,因此汇编指令用什么格式怎么写,就必须遵循 NASM 的规定。
目前主要有两种格式的 x86 汇编语言,一种是 Intel 格式,一种是 AT&T 格式。最主要的区别是 Intel 格式把目标操作数放在前而源操作数放在后,AT&T 格式则刚好相反;另一个区别是两种格式对寄存器名和操作数的书写格式不同,比如 Intel 格式的汇编指令“MOV AH,00”用 AT&T 格式书写就是“movb $0,%ah”。NASM 遵循 Intel 格式。
本节主要介绍在编写 myos 时常用的 8086 汇编指令、NASM 语法以及基本的 BIOS 调用。
2.2.1 8086 汇编指令
一个 CPU 能执行的所有指令称为这个 CPU 的指令系统。8086 的指令系统共有 117 条指令,这些指令从功能上主要分为三大类,分别是传送类指令、运算类指令和控制类指令。本教材不打算介绍 8086 的每条指令,也不单独介绍 8086 的全部寻址方式,只是详述在编写myos 时这三种类型指令中主要用到的一些基本指令的功能、格式和用法。
1、传送类指令
传送类指令主要用于实现数据之间的传送。
1、MOV 指令
MOV 指令主要用于在两个寄存器或寄存器与内存单元之间传送数据,也可以传送立即数到寄存器或内存单元中。
MOV 指令的格式如下所示:
MOV destination,source其中 destination 表示目标操作数,source 表示源操作数,中间用逗号隔开。该指令表示把source 所描述的源操作数传送到 destination 所描述的目标存储单元中,操作数既可以是 8 位二进制数,也可以是 16 位二进制数。根据操作数的不同类型,大概有如下 5 种情况:
(1)MOV 寄存器,立即数:把立即数传送到寄存器中。这里寄存器可以是 8 位寄存器 AH、AL、BH、BL、CH、CL、DH、DL,或者 16 位寄存器 AX、BX、CX、DX、SI、DI、SP、BP,但不能是 CS、DS、ES、SS 和 IP。如果是 8 位寄存器,立即数必须要小于 2^8,如果是 16 位寄存器,立即数必须要小于2^16。比如:
MOV AL,200 ;把立即数 200 传送到 8 位寄存器 AL 中。
MOV AX,400 ;把立即数 200 传送到 16 位寄存器 AX 中。
;上面合法,而下面就不合法。
MOV AH,300 ;300在 8 位寄存器 AH 中放不下。(2)MOV 内存单元,立即数:把立即数传送到内存单元中。这里内存单元的地址既可以采用直接寻址,又可以采用寄存器间接寻址,无论采用哪种寻址方式,都需要把内存单元的地址用方括号括住,同时还要用关键字“byte”或“word”指定传送的位数。比如:
MOV byte[label],200 ;把 200 传送到由标号 label 定位的内存单元中。
MOV word[1000],200 ;把 200 传送到地址为 1000 和 1001 的两个内存单元中。
MOV byte[SI],200 ;把 200 传送到寄存器 SI 中的值所指的内存单元中。注意这里 label 是一个标号,代表一个内存单元的地址,它可以是任意合法的字符串。
(3)MOV 寄存器,寄存器:在寄存器之间传送数据。这里寄存器可以是除 IP 寄存器之外的任何寄存器,另外源、目寄存器之间的位数要匹配。比如:
MOV DS,BX ;把 BX 中的 16 位二进制数传送到 DS 中,BX 仍保留原来的数。
MOV AH,DL ;把 DL 中的 8 位二进制数传送到 AH 中,DL 仍保留原来的数。
;上面合法,而下面就不合法。
MOV SI;DL ;或者
MOV AH;BX(4)MOV 内存单元,寄存器:把寄存器中的数传送到内存单元中。这里寄存器可以是除 IP 寄存器之外的任何一个寄存器,由于寄存器本身已经确定了要传送数的位数,因此内存单元的地址不需要“byte”和“word”关键字指定。比如:
MOV [DI],AX ;把 AX 中的数传送到由 DI 中的值指定的连续两个内存单元中。
MOV [2000],BL ;把 BL 中的数传送到地址为 2000 的内存单元中。(5)MOV 寄存器,内存单元:把内存单元中的数传送到寄存器中。这里寄存器可以是除 IP 寄存器之外的任何一个寄存器,由于寄存器本身已经确定了要传送数的位数,因此内存单元的地址不需要“byte”和“word”关键字指定。比如:
MOV AX,[SI] ;把 SI 中的值指定的连续两个内存单元中的值传送到 AX 寄存器中。
MOV BL,[label] ;把 label 标号所指的内存单元中的数传送到 BL 寄存器中。MOV 指令是汇编程序中使用最多的一条指令,同时也是比较灵活的一条指令,除了上述基本情况外,在使用中还需要注意以下几点:
(1)立即数不能作为目标操作数;
(2)立即数不能传送给段寄存器;
(3)段寄存器之间不能传送数据;
(4)内存单元之间不能传送数据;
(5)不能用 MOV 指令给代码段寄存器 CS 传送数据。用 MOV 指令给 CS 传送数据虽然汇编能通过,但运行时程序肯定会崩溃。CS 的值只能与 IP 一起由专门的指令来修改。
2、PUSH 指令和 POP 指令
PUSH 和 POP 指令用于堆栈操作,可以把寄存器中的数或内存单元的数压入到堆栈(PUSH),或从堆栈弹出一个数到寄存器或内存单元中(POP)。如前所述,堆栈就是一块内存空间,由堆栈段寄存器 SS 和堆栈指针 SP 指向该空间的操作位置,每当执行 PUSH 指令时,首先 SP-2→SP,然后把要压栈的数保存在 SS 和 SP 指向的内存单元(压入栈顶);每当执行 POP 指令时,先把 SS 和 SP 指向的内存单元的值弹出,然后 SP+2→SP(从栈顶弹出)。
PUSH ;指令的格式如下所示:
PUSH source
POP ;指令的格式如下所示:
POP source
;其中 source 表示源操作数,可以是寄存器或内存单元。比如:
PUSH AX
POP word[2000]前一条指令把 AX 中的数压入堆栈,后一条指令把堆栈中的数弹出到内存单元中,这相当于把寄存器 AX 中的数保存到内存单元 2000 和 2001 中。对堆栈操作的基本场景是:调用子程序时,CALL 指令把要传递的参数和返回地址压入堆栈,在子程序中,首先用 PUSH 指令把在子程序中要用到的寄存器的值压入堆栈保存起来,然后在子程序结束时用 POP 指令弹出这些寄存器的值,最后 RET 指令从堆栈中弹出返
回地址。对堆栈的灵活使用可以编写出高质量的程序。使用 PUSH 和 POP 指令时需要注意以下两点:
(1)PUSH 和 POP 指令只能操作 16 位二进制数,所以 source 只能是 16 位寄存器;
(2)PUSH 和 POP 指令必须配套使用,否则程序容易崩溃。
3、LODSB 指令和 LODSW 指令
LODSB 和 LODSW 指令用于通过简化方法把内存单元的数传送到寄存器中。这两条指令没有操作数,其格式如下所示:
LODSB
LODSW其中 LODSB 把 DS:SI 所指的内存单元中的数传送到 AL 寄存器中,然后把 SI 加 1 或减 1。LODSW 把 DS:SI 所指的连续两个内存单元中的数传送到 AX 寄存器中,然后把 SI 加 2 或减 2,这里的加减取决于状态标志寄存器中的方向位。比如,若方向标志位为 0,则 LODSB相当于以下两条指令:
MOV AL,[DS:SI]
INC SI:SI+1→SI
;而 LODSW 相当于以下两条指令:
MOV AX,[DS:SI]
ADD SI,2:SI+2→SI注意这里内存单元的地址默认由 DS 和 SI 指出,因此在使用 LODSB 或 LODSW 指令时一定要清楚此时 DS 和 SI 的值。一般都是先给 DS 和 SI 赋值,然后再使用这两条指令。
4、LEA 指令
LEA 指令用于把一个内存地址的偏移量传送给一个寄存器。LEA 指令的格式如下所示:
LEA destination,source其中 source 一般是一个内存单元的标号地址,destination 是一个 16 位的寄存器,一般是 SI或 DI。比如:
LEA SI,label ;把 label 标号的偏移地址传送给 SI 寄存器。如前所述,label 代表一个内存单元的地址,因此它既可以是一条指令的地址,也可以是一块数据的地址。用在 LEA 指令中,显然表示的是一块数据的首地址,这条指令的目的就是让 SI 寄存器指向这块数据。注意对比如下几条指令的功能:
MOV AX,[label] ;把 label 标号所指的内存单元中的数传送给 AX 寄存器。
MOV AX,label ;把 label 标号本身代表的地址传送给 AX 寄存器。
LEA AX,label ;把 label 标号本身代表的地址传送给 AX 寄存器。
LEA AX,[label] ;把 label 标号所指的内存单元的地址传送给 AX 寄存器。
MOV AL,[label] ;这样可以,传送一个字节。
MOV AL,label ;这样不可以,因为地址是 16 位。以上第 2、3、4 条指令的结果是一样的,最合理的用法是第 3 条指令。如果与 C 语言中的指针对比,[label]就是*p,而 label 就是 p。
5、IN 指令和 OUT 指令
IN 指令和 OUT 指令用于读写端口地址。
什么是端口地址?在计算机系统的硬件中,所有外部设备都要通过一个逻辑部件才能和系统相连,这个逻辑部件叫做接口,比如网卡、声卡、显卡等都是接口。从编程的角度看,每个接口里面都有数量不等的若干寄存器,CPU 通过访问这些寄存器来实现对外部设备的控制与操作。这些寄存器的地址就叫做端口地址(注意区分 TCP/IP 协议中的端口地址)。在 8086 中,内存地址和端口地址分开来单独编址,内存地址范围 0x00000-0xFFFFF,用 MOV指令访问,端口地址范围 0x0000-0xFFFF,用 IN 和 OUT 指令访问。
由于操作系统直接运行在硬件之上,因此编写操作系统肯定要涉及到外部设备的接口,因此掌握 IN 和 OUT 指令的使用方法是必须的。但是只掌握 IN 和 OUT 指令的使用方法还远远不够,因为还有各种各样操作各异、功能繁杂的接口里面的寄存器。好在 myos 运行在BIOS 之上,所有基本外设(键盘、显示器、中断控制器、定时器)的初始化都由 BIOS 完成,BIOS 还提供了访问这些外设的子程序。因此这里不再详述各接口中寄存器的具体操作,而只介绍 IN 和 OUT 指令的具体用法。
IN 和 OUT ;指令的格式如下所示:
IN AL/AX,端口地址/DX
OUT 端口地址/DX,AL/AX注意,当端口地址小于 256 时,在指令中可以直接写端口地址,当端口地址大于 256 时,要把端口地址放在 DX 中,然后在指令中使用 DX 来指出端口地址。这里寄存器只能是 AL或 AX,可以传送 8 位或 16 位二进制数。比如:
IN AL,0x64 ;把端口 0x64 中的值传送到 AL 寄存器。
OUT 0x60,AL ;把 AL 寄存器中的 8 位二进制数传送到 0x60 端口。
IN AL,DX ;把 DX 所指端口中的 8 位二进制数传送到 AL 寄存器。
OUT DX,AX ;把 AX 中的 16 位二进制数传送到 DX 所指的端口中。2、运算类指令
运算类指令包括算术运算指令和逻辑运算指令。运算类指令中段寄存器不能作为操作数参加运算,所有的运算类指令都会影响状态标志寄存器。
1、ADD 指令
ADD 指令完成两个数的加法运算。其格式如下:
ADD destination,source其中 destination 表示目标操作数,source 表示源操作数,中间用逗号隔开。该指令把 source所描述的源操作数与 destination 所描述的目标操作数相加,结果保存在 destination 中。这里source 可以是立即数、内存单元或寄存器,destination 可以是寄存器或内存单元。ADD 指令既可以完成 8 位二进制数的加法运算,又可以完成 16 位二进制数的加法运算,这取决于destination 指出的操作数位数。比如:
ADD AL,20 ;20 与 AL 寄存器中的值相加,结果保存在 AL 寄存器中,这是一个 8位二进制数的加法运算。这里的 20 显然不能大于 255。
ADD BX,[20] ;BX 中的数与地址为 20 和 21 两个内存单元中的数相加,结果保存在BX 寄存器中,这是一个 16 位二进制数的加法运算。
ADD SP,BP ;SP 与 BP 寄存器中的数相加,结果保存在 SP 寄存器中,这是一个 16位二进制数的加法运算。
ADD byte[100],100;100 与地址为 100 的内存单元中的数相加,结果保存在地址为100 的内存单元中,这是一个 8 位二进制数的加法运算。尽管 ADD 指令格式中 destination 可以是各个寄存器或内存单元,但用 AX 作为destination 的运算速度会更快。
2、SUB 指令
SUB 指令完成两个数的减法运算,与 ADD 指令的用法基本相同,这里不再赘述。
3、MUL 指令
MUL 指令完成两个无符号数的乘法操作。其格式如下:
MUL sourceMUL 指令的被乘数隐含在 AL 或 AX 寄存器中,这里的 source 表示乘数,可以是寄存器或内存单元。如果 source 表示 8 位乘数,则 source 与 AL 相乘,16 位乘积保存在 AX 寄存器中,如果 source 表示 16 位乘数,则 source 与 AX 相乘,32 位乘积保存在 DX 和 AX 寄存器中。比如:
MUL BL;AL*BL→AX。
MUL CX;AX*CX→DX:AX。
MUL byte[label];label 所指内存单元中的数与 AL 相乘,乘积保存在 AX 寄存器中。4、DIV 指令
DIV 指令完成两个无符号数的除法操作。其格式如下:
DIV sourceDIV 指令的被除数隐含在 AX 或 DX:AX 寄存器中,这里的 source 表示除数,可以是寄存器或内存单元。如果 source 表示 8 位除数,则 AX 除以 source,8 位商保存在 AL 寄存器中,8 位余数保存在 AH 寄存器中。如果 source 表示 16 位除数,则 DX:AX 除以 source,16 位商保存在 AX 寄存器中,16 位余数保存在 DX 寄存器中。比如:
DIV DL;AX 除以 DL,商保存在 AL 中,余数保存在 AH 中。
DIV CX;DX:AX 除以 CX,商保存在 AX 中,余数保存在 DX 中。
DIV byte[label];AX 除以 label 所指内存单元中的数,商保存在 AL 中,余数保存在AH 中。5、INC 指令和 DEC 指令
INC 指令实现对操作数的自增 1 操作,类似于 C 语言的 i++。其格式如下:
INC source这里 source 可以是寄存器或内存单元。比如:
INC CL;CL+1→CL
INC SI;SI+1→SI虽然指令本身允许对内存单元的值做自增 1 操作,但在实际应用中很少用到,这里也就不举例了。
DEC 指令实现对操作数的自减 1 操作,其用法与 INC 相同,这里不再赘述。
6、AND 指令
AND 指令是一条逻辑运算指令,它完成两个操作数的按位逻辑与运算。其格式如下:
AND destination,source其中 destination 表示目标操作数,source 表示源操作数,中间用逗号隔开。该指令把 source所描述的源操作数与 destination 所描述的目标操作数按位进行逻辑与运算,并把结果保存在destination 中。这里 source 可以是立即数、内存单元或寄存器,destination 可以是寄存器或内存单元。AND 指令既可以完成 8 位二进制数的逻辑与运算,又可以完成 16 位二进制数的逻辑与运算,这取决于 destination 指出的操作数位数。比如:
AND AL,0x80;AL 寄存器中的值与 0x80 进行与运算,结果保存在 AL 寄存器中。该指令一般用于测试 AL 寄存器的最高位,若最高位为 1,则与运算结果不为 0,否则为 0。
8086 提供的逻辑运算指令还有逻辑或运算指令 OR、逻辑非运算指令 NOT 和逻辑异或运算指令 XOR。这些指令的用法与 AND 类似,这里不再赘述。
7、SHL 指令
SHL 指令完成对操作数的逻辑左移操作。移位指令可以实现对操作数的按位处理。8086 提供了 8 条移位指令,分别是:逻辑左移指令(SHL)、逻辑右移指令(SHR)、算术左移指令(
SAL)、算术右移指令(SAR)、循环左移指令(ROL)、循环右移指令(ROR)、带进位循环左移指令(RCL)和带进位循环右移指令(RCR)。这里只介绍SHL 指令的用法,告诉大家 8086 还提供了这种类型的指令,在实际编程中如果需要用到各种移位指令,参阅相关资料即可。
SHL 指令的格式如下所示:
SHL source,count其中 source 表示被移位的操作数,可以是寄存器或内存单元。count 表示移位的次数,可以是立即数,也可以是 CL 寄存器中的值。比如:
SHL AL,1;AL 寄存器中最左边的 1 位被移入状态标志寄存器中的进位位,其余各位依次左移,最右边的位补 0。
MOV CL,4
SHL BX,CL;BX 寄存器中最左边的 4 位被移出,最后 1 位移入状态标志寄存器中的进位位,其余各位依次左移,最右边的 4 位补 0。3、控制类指令
控制类指令用于实现对程序执行顺序的控制。
1、JMP 指令
JMP 指令用于实现在程序中的无条件转移。无条件是指不考虑任何条件,总是转移。转移是指 CPU 不再顺序执行当前指令的下一条指令,而是跳转到其它地方的一条目标指令处继续执行。
如前所述,CPU要执行的程序都在内存中,CPU要执行的下一条指令的内存地址由CS:IP 寄存器指出,因此 JMP 指令的本质就是修改 CS:IP 寄存器的值。JMP 指令的格式如下所示:
JMP label这里 label 就是目标指令在内存中的地址。那么如何根据 label 修改 CS:IP 呢?根据label 的不同寻址方式,共有 7 种情况,前 4 种情况称为段内跳转,只修改 IP,后 3 种情况称为段间跳转,既要修改 IP,还要修改 CS。
(1)JMP short label;含义是下一条指令从 label 处开始执行。具体操作是 label 表示的内存地址减去当前 JMP 指令所在的内存地址,得到一个相对的偏移量,然后把这个偏移量再加到 IP 中,从而实现跳转。由于是 short 关键字,偏移量被规定为一个字节大小,其范围为-128~+127,也就是此时的 JMP 指令只能从当前位置向前或向后跳转 127 字节的距离,称为短跳转。
(2)JMP near label;含义同(1),但由于是 near 关键字,所以偏移量是两个字节大小,其范围为-32768~+32767,也就是此时的 JMP 指令可以从当前位置向前或向后跳转32767 字节的距离,称为近跳转。
(3)JMP BX;含义是下一条指令从 BX 中的值所指的内存单元处开始执行。具体操作是把 BX 寄存器中的值直接送到 IP 寄存器中,也即目标指令的地址间接通过 BX 传送给IP。这里 BX 还可以是 AX、CX、DX、SI、DI、BP 和 SP 寄存器。
(4)JMP word label;含义是从 label 所指的内存单元中的值所指的内存单元处开始执行,有点拗口?也就是说目标指令的地址存放在 label 所指的连续两个内存单元中。具体操作是[label] →IP,注意不是 label →IP。
(5)JMP dword label;含义同(4),区别是目标指令的地址存放在 label 所指的连续四个内存单元中。具体操作是[label] →IP,[label+2] →CS。
(6)JMP 0x1234:0x5678;含义是下一条指令从 0x1234:0x5678 处开始执行。具体操作是 0x1234 →CS,0x5678 →IP。当然冒号左右可以是任意 16 位二进制数。
(7)JMP far label;含义是下一条指令从 label 处开始执行。具体操作是 label→IP,label 标号所在的段地址→CS。
这里还想再啰嗦一句。(1)和(2)是编程中最常用的形式,通常在 JMP 指令中可以不写 short 和 near 关键字,而由汇编器决定采用何种跳转,但你应该理解当初设计人员的良苦用心(一如 IEEE754 的 1.M)。它们的区别就是(1)汇编后的机器码是 2 个字节而(2)是 3 个字节,但(2)可以跳转得更远一些。和 MOV 指令一样,繁乱复杂的背后其实是灵活高效!懂得了选择,你就比别人更进了一步。
2、CMP 指令
CMP 指令用于比较两个操作数的大小。其指令格式如下所示:
CMP source1,source2CMP 指令本质上就是做了一次减法运算,因此操作数的格式同前述运算类指令一样,这里不再赘述。CMP 指令与 SUB 指令相同的是都影响了状态标志寄存器中的标志位,不同的是 CMP 指令不保存结果而 SUB 指令要保存结果,这也是格式中写成 source1 和source2 的缘故。CMP 指令的目的就是为下面介绍的条件转移指令创造条件。
3、Jcondition 指令
Jcondition 指令是一类条件转移指令,用于实现在程序中的条件转移。condition 位置是各种条件的英文首字母,若条件满足,则跳转到目标指令处执行,若条件不满足,则不转移,继续顺序执行下一条指令。指令格式如下所示。
Jcondition label这里的 label 是目标指令的地址标号,规定为 1 个字节的偏移量,相当于 short label,也就是说Jcondition 指令只能向前或向后跳转 127 字节。Jcondition 指令共有 30 条,使用时要与运算类指令或 CMP 指令配合。比如:
SUB AX,BX
JZ label;结果为 0(相等)则跳转到 label 处执行,否则继续顺序执行。
AND AL,0x80
JNZ label;结果不为 0(AL 最高位为 1)则跳转到 label 处执行,否则继续顺序执行。
CMP CX,100
JE label;相等,则跳转到 label 处执行,否则继续顺序执行。
CMP SI,DI
JNE label;不相等,则跳转到 label 处执行,否则继续顺序执行。以上举例的指令是最常用的相等与不相等条件,前两条与运算类指令配合,后两条与CMP 指令配合。但实际上它们判断的都是状态标志寄存器中的 ZF 标志,所以可以混用,只是逻辑上这样写更好一些。需要提醒一点的是,在 CMP 与 Jcondition 指令之间增加其他指令可能会导致程序的不确定性,因为这个其他指令可能会影响标志位而 Jcondition 指令只判断标志位。其他条件转移指令的使用方法与这 4 条指令完全相同,这里不再赘述。
4、LOOP 指令
LOOP 指令也是一条条件转移指令。该指令隐含了一个操作数 CX,其指令格式如下:
LOOP label指令执行时,首先 CX-1→CX,若 CX 非 0,则跳转到 label 标号处执行指令,否则顺序执行下一条指令。
5、CALL 指令
CALL 指令用于实现子程序的调用。其指令格式如下所示:
CALL labelCALL 指令本质上也是一条跳转指令,label 用于指出目标指令的地址,相当于是子程序的第一条指令地址。这里 label 的寻址方式与 JMP 指令相似,也包括段内调用和段间调用,只是 CALL 指令没有 short 寻址方式。比如:
CALL near label;下一条指令跳转到 label 处执行,偏移量范围为-32768~+32767,段内调用。
CALL BX;下一条指令从 BX 中的值所指的内存单元处开始执行,段内调用。
CALL word label;下一条指令从 label 所指的内存单元中的值所指的内存单元处开始执行,段内调用。
CALL dword label;下一条指令从 label 所指的连续 4 个内存单元中的值所指的内存单元处开始执行,段间调用。
CALL 0x1234:0x5678;下一条指令从 0x1234:0x5678 处开始执行,段间调用。
CALL far label;下一条指令从 label 处开始执行。但是 CALL 指令毕竟不是 JMP 指令。JMP 指令只是直接跳转指令,一去不复还,所以JMP 指令执行时的具体动作只是跳转,即把目标指令的地址传送到 IP 或 CS:IP 即可。而CALL 是子程序调用指令,因此 CALL 指令执行时的具体动作除了跳转,还要保存返回地址,这样返回指令才能正确返回。CALL 指令的跳转动作与 JMP 指令一样,保存返回地址的动作是把紧挨着 CALL 指令的下一条指令的地址保存在堆栈中,如果是段内跳转,只把段内地址压入堆栈,如果是段间跳转,则先压段地址,再压段内地址。
6、RET 指令
RET 指令实现从子程序返回的功能。很显然,既然 CALL 执行时已经把返回地址压入堆栈了,那么 RET 指令执行时只要把返回地址从堆栈弹出到 IP 或 CS:IP 就行了,因此RET 指令没有操作数。RET 指令的格式如下所示:
RET
RETF
IRET其中 RET 指令是段内返回指令。当 CALL 指令是段内调用时,在子程序的最后用RET 指令返回,其具体动作是把返回地址从堆栈弹出到 IP。RETF 指令是段间返回指令。当 CALL 指令是段间调用时,在子程序的最后用 RETF指令返回,其具体动作是把返回地址从堆栈弹出到 CS:IP,注意出栈顺序是先出偏移量,再出段地址。IRET 指令中断返回指令。在中断处理程序的最后用 IRET 指令返回。IRET 指令是段间返回指令,其具体动作是把返回地址从堆栈弹出到 CS:IP,再从堆栈弹出状态标志寄存器的值。
喋喋不休地解释这么多,主要还是想让你理解指令执行的本质,只有从本质上(指令执行的具体动作)掌握了指令的执行过程,才能在编程中游刃有余,自由选择,也才能编写出高质量的程序。比如以下程序段:
MOV AX,0x1234
PUSH AX
XOR AX,AX
PUSH AX
RETF本质上相当于 JMP 0x1234:0x0000,你能看出来吗?
7、INT 指令
INT 指令是中断指令。其指令格式如下所示:
INT number这里 number 称为中断类型码,是一个 0 到 255 之间的数字。可以把 INT 指令先简单的理解为调用子程序,number 就是子程序号,也就是通过 INT 指令可以调用 256 个子程序,但是是以中断机制来调用的。有关中断机制的内容第七章详述。
以上就是在编写 myos 过程中用到的基本 8086 指令的简介,具体的使用可以在以后的编程中慢慢学习。也许在编程过程中还会用到其他指令,具体遇到时再解释。
2.2.2 NASM 语法
NASM 规定一段 8086 汇编语言程序由多条语句组成。每条语句由如下 4 个部分的全部或某几个部分组成:
label: instruction operands ;comment其中 label 是标号,用于指出该条语句的地址,在语句中不是必需的;instruction 是该条语句的具体指令,这些指令可以是 8086 汇编指令或 NASM 定义的伪指令、关键字等,每条语句都必须有operands 指出指令操作的对象,根据 instruction 的含义在语句中可有可无;comment 是以分号标注的注释部分,根据需要在语句中添加。这 4 部分之间用空格隔开,空格个数没有严格的限制。
同样需要说明一下,这里总结的并不是 NASM 全部的详细语法,只是介绍为编写myos 所需的基本内容。
1、标号
标号就是一个字符串,用于表示所在行的地址。强调一下,一个标号既有偏移地址,也有段地址。标号中的有效字符是字母、数字、下划线‘_’、‘$’、‘#’、‘@’、‘~’、‘.’和‘?’,但只有字母、‘.’、‘_’和‘?’可以作为标号的开头。以字母开头的标号是普通标号;以‘.’开头的标号表示该标号是一个本地标号;以‘_’开头的标号表示该标号是一个外部标号;以‘$’开头的标号表示该标号是一个标号而不是一个关键字,比如$MOV 是标号而不是 MOV 指令。
标号后面的冒号是可选的,也就是说在行首定义标号时,后面的冒号可写可不写。冒号‘:’也不是标号的一部分,也就是说在行首定义时可以在标号后面加冒号,但在其他地方引用标号时不能有冒号。
在 NASM 中,标号是唯一大小写敏感的标识符,比如 Foo、foo、FOO 是三个不同的标号,而 Mov、mov、MOV 则指同一条指令。
2、伪指令
伪指令(Pseudo Instruction)是用于对汇编过程进行控制的指令。伪指令只在汇编过程中起作用,它为汇编器提供一些辅助的程序表达,以实现机器指令所不能表达的内容,伪指令本身并不生成可执行的机器码。
①、ORG 伪指令
ORG 伪指令指定下一条语句的汇编地址,其格式如下所示:
ORG 数值这里数值的范围是 0x0000—0xFFFF。
汇编程序在将汇编语言源程序汇编成可执行代码时,首先分配一个初置为 0 的汇编地址计数器,然后在汇编过程中,以汇编地址计数器的值作为每条语句的地址,并按照每条语句实际需要的字节数来改变汇编地址计数器的值。因此,汇编过程中所有标号和变量的偏移地址就是当前汇编地址计数器的值。而 ORG 伪指令的作用就是修改汇编地址计数器的值。
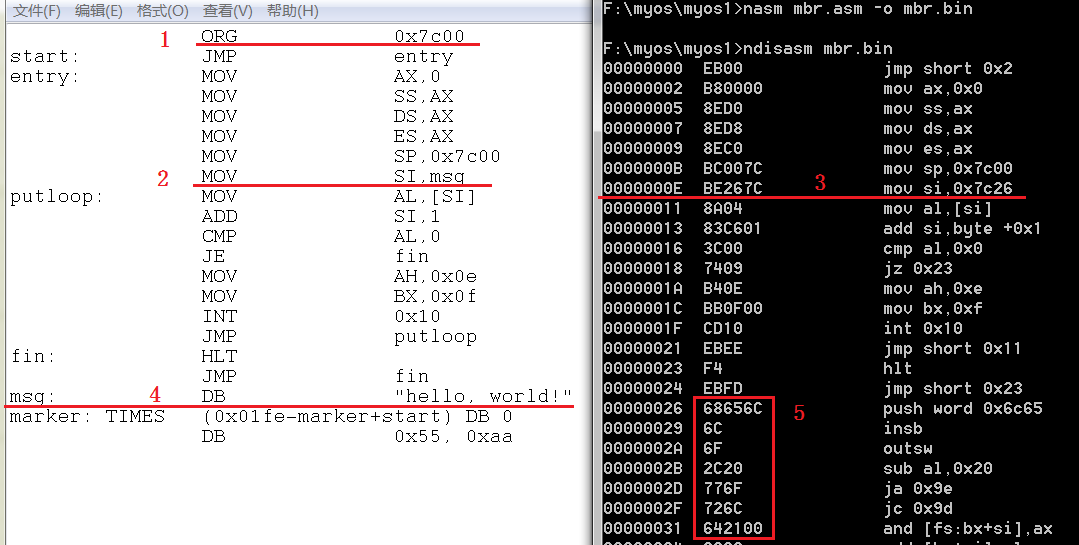
图 2-7 伪指令的含义
图中左边是第一章的 mbr.asm 汇编程序,右边是该程序反汇编的结果。从图中可以看出:
左边 1 标注的 ORG 伪指令在右边的反汇编结果中没有出现,表明它只在汇编时起作用,并不真实产生代码。它的作用就是把汇编地址计数器的值由默认的 0 修改成了0x7c00。
左边 2 标注的语句中标号 msg 在右边的 3 标注的反汇编语句中,地址是 0x7c26,如果没有 ORG 语句,该地址就应该是 0x0026。
左边 4 标注的语句定义了字符串,右边 5 标注的框中就是这些字符串的 ASCII 码,只不过反汇编器把它当做指令反汇编,就出现了在左边原本没有的一些指令。
一般程序将来在内存中运行时的地址在汇编时是不知道的,因此 ORG 伪指令用的比较少。但对一些特殊的代码段,比如我们第一章的 MBR,其将来就必须运行在内存的0x0:0x7c00 处,因此 ORG 伪指令又显得非常重要。强调一下,ORG 伪指令只能修改段内偏移地址。
②、DB 和 DW 伪指令
DB 和 DW 伪指令用于定义初始化的字节或字。其格式如下所示:
label1:DB 数值
label2:DW 数值虽然标号是可选的,但由于定义的数值要被引用,因此语句前面加上标号是必要的。数值可以是各种格式,之间用逗号隔开,比如:
char: DB 0x55 ;只定义一个字节,其值为 0x55。
DB 56,57,58 ;连续定义 3 个字节,其值为 56、57 和 58。
string: DW ‘abc’ ;定义了 2 个字,其值为 0x41、0x42、0x43、0x00。③、RESB 和 RESW 伪指令
RESB 和 RESW 伪指令用于定义未初始化的字节或字。其格式如下所示:
label1:RESB ;数值
label2:RESW ;数值
;这里的数值表示定义的字节或字的个数,比如:
buffer:RESB 64 ;定义连续的 64 个字节,这 64 个字节的值未知。
wordvar:RESW 1 ; 定义 1 个字,该字的值也未知。④、EQU 伪指令
EQU 伪指令定义一个标号,该标号代表一个常数。其格式如下所示:
label:EQU 常数值
;注意,使用 EQU 伪指令时,前面必须有标号。比如:
length: EQU 100 ;以后在程序中,length 就是 100。该语句等价于 C 语言中的“#define length 100”。
⑤、TIMES
TIMES 伪指令用于重复定义指令或数据。其格式如下所示:
label:TIMES; ;数值 指令或数据
;这里的数值表示重复定义的次数,指令或数据是被重复定义的实体。比如:
zerobuf:TIMES 100 DB 0 ;连续定义初值为 0 的 100 个字节。
TIMES 10 MOVSB ;连续定义 10 条 MOVSB 指令。注意在“TIMES 100 RESB 1”与“RESB 100”之间并没有结果上的区别,只是后者在汇编时会快上 100 倍。
⑥、EXTERN 和 GLOBAL 伪指令
EXTERN 伪指令用于引入一个外部标号,它与 C 语言的关键字 extern 作用相同。如果在本模块中需要引用一个定义在其他模块的标号,在本模块中要用 EXTERN 伪指令申明。其格式如下所示:
EXTERN labelGLOBAL 伪指令用于输出一个本地标号。如果在别的模块中需要引用一个定义在本模块中的标号,在本模块中要用 GLOBAL 伪指令申明。其格式如下所示:
GLOBAL _label显然 EXTERN 与 GLOBAL 要配套使用。只有在一个模块中定义了一个外部标号(最前面加下划线)并用 GLOBAL 伪指令输出,才能在另一个模块中用 EXTERN 伪指令输入(不写下划线)。
编写 myos 时需要汇编与 C 语言混合编程,因此这两个伪指令十分重要。具体例子在后面的编程中会有很多。
⑦、BITS 伪指令
BITS 伪指令用于指定目标处理器模式,即指定 NASM 汇编的可执行代码是在 16 位处理器上还是在 32 位处理器上运行。其格式如下所示:
BITS 16 ;或 32对于纯二进制可执行文件(.bin),NASM 默认汇编为 16 位代码,因此第一章的mbr.asm 中不需要有 BITS 伪指令;对于其他格式的可执行文件,NASM 默认汇编为 32 位代码,由于 myos 要运行在 16 位的 8086 上,因此在汇编语言程序中需要用“BITS 16”伪指令指定目标处理器模式为 16 位。
3、常数
NASM 能理解 4 种类型的常数:数值常数、字符常数、字符串常数和浮点常数,由于8086 没有浮点指令,因此这里只介绍前 3 种。
①、数值常数
NASM 规定可以用二进制、八进制、十进制和十六进制表示一个常数。以下通过实例来说明各进制数的书写格式:
MOV AX,100b ;二进制数,数字只能是 0、1。
MOV AX,777q ;八进制数,数字不能超过 7。
MOV AX,123 ;十进制数
MOV AX,0a2h ;十六进制数,第一位必须是 0~9 的数字。
MOV AX,0xa2 ;十六进制数。
MOV AX,$0a2 ;十六进制数,$后第一位必须是 0~9 的数字。用于表示进制的‘b’、‘q’、‘h’、‘x’以及十六进制数的‘abcdef’既可以大写也可以小写。
②、字符常数和字符串常数。
字符常数或字符串常数都要用单引号或双引号标识。字符串常数一般只用于 DB 或DW 伪指令。单引号中允许有双引号出现。比如:
DB 'a'
DB '"hello"'
MOV AL,'A'
MOV AH,"H"4、表达式
NASM 中的表达式语法与 C 语言非常相似,这里不再赘述。前面介绍伪指令时,各伪指令格式中的数值都可以用表达式表示,需要注意的是要考虑表达式计算结果的范围不能超过 16 位二进制数。表达式中除了常用的‘+’、‘-’、‘*’、‘/’(加减乘除)运算符外,还有‘<<’(左移)和‘>>’(右移)两个位移运算符。比如‘5<<3’相当于把 5 乘上 8,‘16>>2’相当于 16 除以 4。
NASM 在表达式中还支持两个特殊的符号。一个是‘$’,表示$本身所在源代码行开始处的地址,因此可以简单地写这样的代码:
JMP $来表示无限循环,$实际上就是前面提到的汇编地址计数器。另一个是‘$$’,表示$$所在段开始处的地址,因此可以通过:
$ - $$来计算该表达式在当前段内的偏移。
5、有效地址
8086CPU 支持 8 位和 16 位二进制数的操作。所谓的操作,本质上就两个动作:传送和计算。不管是传送还是计算,涉及的操作数不是在寄存器中,就是在内存单元中。这里所说的有效地址就是指在指令中描述的内存单元的地址。NASM 提供了简单有效的内存单元地址的语法表示,那就是把一个可计算的表达式放在方括号内表示内存单元的地址,换句话说,任何一个内存单元的地址,都必须在一个方括号内。比如:
MOV AX,[200]
MOV AX,[SI]
MOV AX,[ES:SI]
MOV AX,[label]
MOV AX,[DS:label]
MOV AX,[label+2]
MOV AX,[label+BX]NASM 还允许使用关键字‘BYTE’、‘WORD’、‘SHORT’、‘NEAR’和‘FAR’强制产生特定形式的有效地址,这些关键字的用法,前面都已举例,这里就不再赘述。
作业:
如何用 CALL 指令实现 JMP 指令的功能?
参照第一章的操作方法,修改 mbr.asm,实现以下功能:完成 2 个 100 以内的正整数乘积,并把乘积结果显示在屏幕上。
答:第二题为http://t.csdn.cn/hY20e