深度学习面试问题汇总(二)
文章目录
Batch Normalization、Layer Normalization、Instance Normalization、Group Normalization
1BN
- BN即Batch Normalization,可以缓解internal covariate shift问题,加速神经网络的训练,保证网络的稳定性。
- BN有正则化作用,可以无需额外使用dropout来避免过拟合,从而提高泛化能力。
- BN对不同的初始化机制和学习率更鲁棒,即降低了对初始化的要求。
1.1什么是internal covariate shift问题?具体表现是什么呢?

1.2BN的具体实现及细节问题

为什么需要最后一步线性变换呢?
因为之前几步得到均值为0方差为1的输入在经过sigmoid激活函数或者tanh激活函数时,容易陷入线性区域,从而失去非线性的特征表达能力。最后的线性变换是将标椎正态分布进行缩放和平移,从而让输入能更多落在非线性区域,从而获得非线性的表达能力。
缺点:
- BN特别依赖Batch Size,小Batch下效果不好
- BN对处理序列化数据的网络不太适用,如RNN,LSTM等,尤其当序列样本的长度不同时
- BN只在训练的时候用,BN处理训练集的时候,采用的均值和方差是整个训练集的计算出来的均值和方差。测试和训练的数据分布如果存在差异,那么就会导致训练和测试之间存在不一致现象
2LN
在计算均值和协方差时,通过统计每层中所有神经元的数据来计算,不受mini-batch大小的约束,适合RNN结构的网络。
在LN中,所有神经元的μ和σ都是一样的,不受到批次的约束。并且训练和测试的处理方式是一样的,不用记住训练时的统计量,节省存储空间。
3GN
GN优化了BN在比较小的mini-batch情况下表现不太好的劣势。其是首先将 Channels 划分为多个 groups,再计算每个 group 内的均值和方法,以进行归一化。对于GN,它的一个像素集为一个样本的一部分连续特征图的像素点集合。GB的计算与Batch Size无关,因此对于高精度图片小BatchSize的情况也是非常稳定的。
4 BN、LN、IN、GN的区别

假如现在图像先进行了卷积运算得到如上图所示的激活状态(N,C,H,W),其中N是样本数,C为通道数即特征图数。
- BN:取不同样本的同一个通道的特征做归一化,逐特征维度归一化。这个就是对batch维度进行计算。所以假设5个100通道的特征图的话,就会计算出100个均值方差。5个batch中每一个通道就会计算出来一个均值方差。
- LN:取的是同一个样本的不同通道做归一化,逐个样本归一化。5个10通道的特征图,LN会给出5个均值方差。
- IN:仅仅对每一个图片的每一个通道最归一化。也就是说,对【H,W】维度做归一化。假设一个特征图有10个通道,那么就会得到10个均值和10个方差;要是一个batch有5个样本,每个样本有10个通道,那么IN总共会计算出50个均值方差。
- GN:这个是介于LN和IN之间的一种方法。假设Group分成2个,那么10个通道就会被分成5和5两组。然后5个10通道特征图会计算出10个均值方差。
优化器
1. Batch gradient descent(BGD)
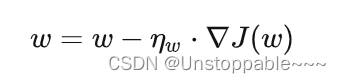
-
基本思想:使用整个数据集来计算梯度
-
优点:
-
- 梯度计算准确;
- 下降过程稳定;
- 对凸损失函数能保证收敛到全局最小值,非凸损失函数能保证收敛到局部最小值。
-
缺点:
-
- 如果数据集含有许多相似或者重复样本,则梯度计算冗余
- 计算耗时;
- 收敛慢;
- 如果整个数据集较大放不进内存则无法计算梯度;
- 不可用于在线学习算法。
2.Stochastic gradient descent(SGD)
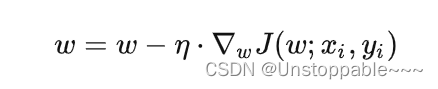
-
基本思想:随机选择一个样本计算负梯度,沿着负梯度方向更新参数,步长随着迭代次数慢慢变小。
-
优点
-
- 避免了BGD梯度计算的冗余问题
- 梯度计算更快
- 可用于在线学习算法,来了新样本就可以计算梯度更新模型
- 随机性可以帮助跳出局部最小值,使用模拟退火方法在迭代过程中不断减小步长可以慢慢逼近最小值
-
缺点
-
- 梯度方差大,容易上下震荡,到达最值点的路径比较曲折
3. Mini-batch gradient descent(MBGD)
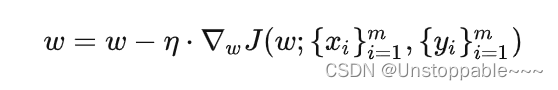
-
基本思想:每次更新参数时,使用小批次的数据来计算梯度。
-
优点
-
- 减少梯度的方差,收敛过程比SGD更稳定
- 梯度计算比BGD效率更高
-
缺点
-
- 不能保证好的收敛性
- 选择合适的学习率困难,太大收敛过程容易震荡,或者收敛不到最小值,太小收敛慢
- 收敛过程中学习率的变化需要事前确定并适应于收敛过程
- 所有的参数使用一样的学习率,不同特征的量纲不同,对结果的影响也不同,所有参数都使用一样的学习率进行相同幅度的更新容易导致陷入局部最优。
- 后三个关于学习率的缺点BGD\SGD也有
4.Adam
Momentum+RMSProp
-
优点
-
- 自适应调整学习率
- 在实践中表现良好,并优于其他自适应学习方法算法。