第一部分:深度学习
1、神经网络基础问题
(1)Backpropagation(要能推倒)
后向传播是在求解损失函数L对参数w求导时候用到的方法,目的是通过链式法则对参数进行一层一层的求导。这里重点强调:要将参数进行随机初始化而不是全部置0,否则所有隐层的数值都会与输入相关,这称为对称失效。
大致过程是:
首先前向传导计算出所有节点的激活值和输出值,
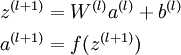
计算整体损失函数:
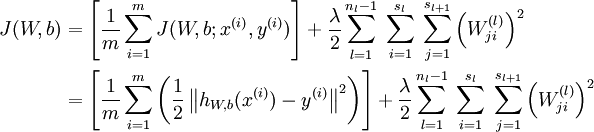
然后针对第L层的每个节点计算出残差(这里是因为UFLDL中说的是残差,本质就是整体损失函数对每一层激活值Z的导数),所以要对W求导只要再乘上激活函数对W的导数即可
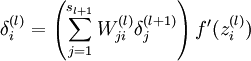

(2)梯度消失、梯度爆炸
梯度消失:这本质上是由于激活函数的选择导致的, 最简单的sigmoid函数为例,在函数的两端梯度求导结果非常小(饱和区),导致后向传播过程中由于多次用到激活函数的导数值使得整体的乘积梯度结果变得越来越小,也就出现了梯度消失的现象。
梯度爆炸:同理,出现在激活函数处在激活区,而且权重W过大的情况下。但是梯度爆炸不如梯度消失出现的机会多。
(3)常用的激活函数
(4)参数更新方法
| 方法名称 | 公式 | 算法介绍 |
|---|---|---|
| Vanilla update | 当训练数据太多时,利用整个数据集更新往往时间上不显示。batch的方法可以减少机器的压力,并且可以更快地收敛当训练集有很多冗余时(类似的样本出现多次),batch方法收敛更快。以一个极端情况为例,若训练集前一半和后一半梯度相同。那么如果前一半作为一个batch,后一半作为另一个batch,那么在一次遍历训练集时,batch的方法向最优解前进两个step,而整体的方法只前进一个step |
|
| Momentum update动量更新 | # integrate velocity # integrate position | momentum即动量,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力:  |
| Nesterov Momentum | x += v |  |
| Adagrad (自适应的方法,梯度大的方向学习率越来越小,由快到慢) |  |
|
| Adam |  |
(5)解决overfitting的方法
dropout, regularization, batch normalizatin,但是要注意dropout只在训练的时候用,让一部分神经元随机失活。
Batch normalization是为了让输出都是单位高斯激活,方法是在连接和激活函数之间加入BatchNorm层,计算每个特征的均值和方差进行规则化。
