pytorch求导机制
1、backward
创建两个矩阵
x:2×3
a:3×2
requires_grad:表示该矩阵可进行求导,相当于一个变量了,默认为false
x = torch.tensor([[1.0, 2.0, 3.], [2., 3., 4.]], requires_grad=True)
a = torch.tensor([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]])
- torck.mul(x,y):
x 点乘 y
x和y形状要相同 - torch.mm(x,y):
x 叉乘 y
x的列和y的行要一致
y = torch.mm(x, a)

表示矩阵y对其中的可求导参数(这里是x)进行求导
y.backward():传入的参数 应为 于y相同维度的张量
y.backward(torch.ones_like(y))
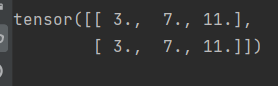
x.grad即表示 y 对 x 求导后 的结果
x.grad
将梯度清零,否则梯度会累加
x.grad.data.zero_()
2、torch.autograd.grad
torch.autograd.grad(outputs, inputs, grad_outputs=None, retain_graph=None, create_graph=False)
功能:求取梯度
outputs:用于求导的张量,如 loss
inputs:需要梯度的张量
create_graph:创建导数计算图,用于高阶求导
retain_graph:保存计算图
grad_outputs:多梯度权重
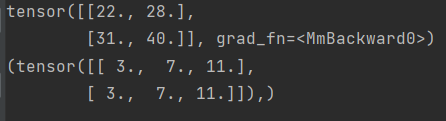
x_grad = torch.autograd.grad(outputs=y, inputs=x, grad_outputs=torch.ones_like(y))
3、区别
- torch.autograd.grad(): 第一个参数 目标函数 第二个参数 待求解的自变量参数,返回值为 求导结果的tensor
- backward():不需要传入参数,只需要直接调用他 由目标函数tensor调用,无返回值,求导结果在 待求解自变量的grad属性中。
4、连续求导
例如:求 y=x ^ 2 对 x 的一阶偏导和二阶偏导。
import torch
x = torch.tensor([6.], requires_grad=True)
y = x ** 2
grad_1 = torch.autograd.grad(y, x, create_graph=True) # grad_1 = dy/dx = 2x = 2 * 6 = 12
grad_2 = torch.autograd.grad(grad_1[0], x) # grad_2 = d(dy/dx)/dx = d(2x)/dx = 2
print(grad_1)
print(grad_2)
