写在最前面
这次实习有个项目要用遗传算法,老师先发我了一个代码链接提前学习一下,于是整理了这份笔记。
最后跑通并初步理解了,直接调用python包装的库真香(✪ω✪),不过也有可能是这次没有尝试多条件约束。
之前用matlab一直没跑通多条件约束的遗传算法(ಥ_ಥ) ,编码解码变异的代码又长又难理解,改参可能是因为我没理解,所以完全没办法定制。感觉代码一直有在进步,之后有时间再试试matlab吧。
最近刚杨康,忙着打游戏hhh;再加上之前挤压了很多任务,赶着写代码还有论文。
跑了几个项目,有的结果还可以,有的直接跑废了,但数据敏感不能直接写笔记,等之后有空了看怎么处理一下吧。
参考
最先老师发我的是这个链接,前面的遗传算法介绍写的通俗易懂,但代码错位+缺失、没跑通
https://mp.weixin.qq.com/s/lQipLASGLIXYk-Yj-cOSPA
后面参考这个链接补全了代码
https://support.i-search.com.cn/article/1566570455826

matlab的遗传算法
https://blog.csdn.net/viafcccy/article/details/94429036
这个是pip设置清华源
https://blog.csdn.net/lemon4869/article/details/106683885
原理
遗传算法
(目前最喜欢这一版的,表达准确精炼)
遗传算法(Genetic Algorithm, GA)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解(所找到的解是全局最优解)的方法。
参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定 五个要素组成了遗传算法的核心内容。
1)种群初始化。我们需要首先通过随机生成的方式来创造一个种群,一般该种群的数量为100~500,这里我们采用二进制将一个染色体(解)编码为基因型。随后用进制转化,将二进制的基因型转化成十进制的表现型。
2)适应度计算(种群评估)。这里我们直接将目标函数值作为个体的适应度。
3)选择(复制)操作。根据种群中个体的适应度大小,通过轮盘赌等方式将适应度高的个体从当前种群中选择出来。其中轮盘赌即是与适应度成正比的概率来确定各个个体遗传到下一代群体中的数量。
具体步骤如下:
(1)首先计算出所有个体的适应度总和Σfi。
(2)其次计算出每个个体的相对适应度大小fi/Σfi,类似于softmax。
(3)再产生一个0到1之间的随机数,依据随机数出现在上述哪个概率区域内来确定各个个体被选中的次数。
4)交叉(交配)运算。该步骤是遗传算法中产生新的个体的主要操作过程,它用一定的交配概率阈值(pc,一般是0.4到0.99)来控制是否采取单点交叉,多点交叉等方式生成新的交叉个体。
具体步骤如下:
(1)先对群体随机配对。
(2)再随机设定交叉点的位置。
(3)再互换配对染色体间的部分基因。
5)变异运算。该步骤是产生新的个体的另一种操作。一般先随机产生变异点,再根据变异概率阈值(pm,一般是0.0001到0.1)将变异点的原有基因取反。
6)终止判断。如果满足条件(迭代次数,一般是200~500)则终止算法,否则返回step2。
TPOT库
TPOT 库(Tree-based Pipeline Optimisation Technique,树形传递优化技术),该库基于 scikit-learn 库建立。
TPOT 是一个 Python 编写的软件包,利用遗传算法行特征选择和算法模型选择,仅需几行代码,就能生成完整的机器学习代码。
自动化机器学习(AML)是一种流水线(也称管线),它能够让你自动执行机器学习(ML)问题中的重复步骤,从而节省时间,让你专注于使你的专业知识发挥更高价值。 最重要的是,它不仅是一些模糊的想法,而且还有一些基于标准 python ML 包建立的应用包,如 scikit-learn。
在这种情况下,任何熟悉机器学习的人都可能会回想起网格搜索(grid search)这个概念。 他们这样想是完全正确的。 实际上,AML 是在 scikit-learn 中应用的网格搜索的扩展,而不是迭代这些值预先定义的集合和其组合,它通过搜索方法,特征,变换和参数值来获得最佳解决方案。 因此,AML“网格搜索”不需要在可能的配置空间上进行详尽的搜索 - AML 有一个很赞的应用叫做 TPOT 包,其提供了像遗传算法这样的应用,可用来在某个配置中混合各个参数并达到最佳设置。
下图为一个基本的传递结构。
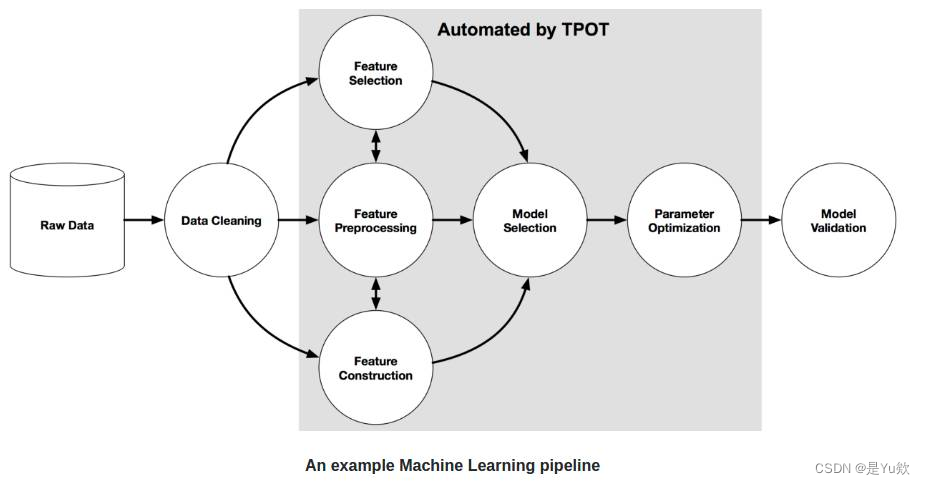
图中的灰色区域用 TPOT 库实现了自动处理。实现该部分的自动处理需要用到遗传算法。
TPOT 库有一个简单的规则:如果不运行 TPOT 太久,那么它就不会为你的问题找出最可能传递方式。
所以,得增加进化的代数,拿杯咖啡出去走一遭,其它的交给 TPOT 就行。此外,你也可以用这个库来处理分类问题。进一步内容可以参考这个文档:http://rhiever.github.io/tpot/
代码部分
问题描述
The data scientists at BigMart have collected 2013 sales data for 1559
products across 10 stores in different cities. Also, certain
attributes of each product and store have been defined. The aim is to
build a predictive model and find out the sales of each product at a
particular store.Using this model, BigMart will try to understand the properties of
products and stores which play a key role in increasing sales.Please note that the data may have missing values as some stores might
not report all the data due to technical glitches. Hence, it will be
required to treat them accordingly.
译文:
来自BigMart的数据科学家已经收集了不同城市10家商店的1559种产品在2013年的销售数据。此外,还定义了每个产品和商店的某些属性。这个比赛的目的是构建一个 预测 模型来找出 每个产品在特定商店的销售情况 。
有了这个模型,BigMart将尝试了解在增加销售方面起 关键作用 的产品和商店的属性。
请注意,由于技术问题,某些商店可能无法报告所有数据,因此数据可能包含缺失值。所以,需要进行数据预处理。
Big Mart Sales数据集
下载
下载地址1(可以用邮箱注册kaggle账号下载):https://www.kaggle.com/datasets/brijbhushannanda1979/bigmart-sales-data?resource=download
下载地址2(已失效):
https://datahack.analyticsvidhya.com/contest/practice-problem-big-mart-sales-iii/
或者评论区留言邮箱,我看到了就发过去
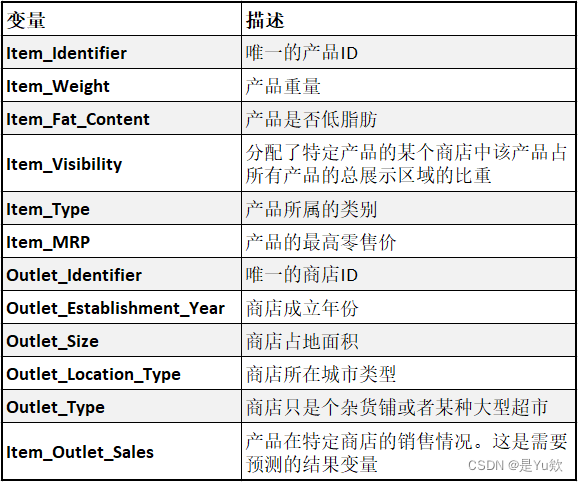
描述
8523 个训练集和 5681 个测试集,训练集同时包含输入变量和输出变量。需要根据训练集来预测测试集的销售额。
安装库
设置清华镜像源
方法1:设为默认镜像源(推荐)
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
然后就可以愉快地使用了。
方法2:临时使用
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 你的包名

安装库
为了能够使用 TPOT 库,你需要先安装一些 TPOT 建立于其上的 python 库。下面我们快速安装它们:
# installing DEAP, update_checker and tqdm
pip install deap update_checker tqdm
# installling TPOT
pip install tpot
全部代码
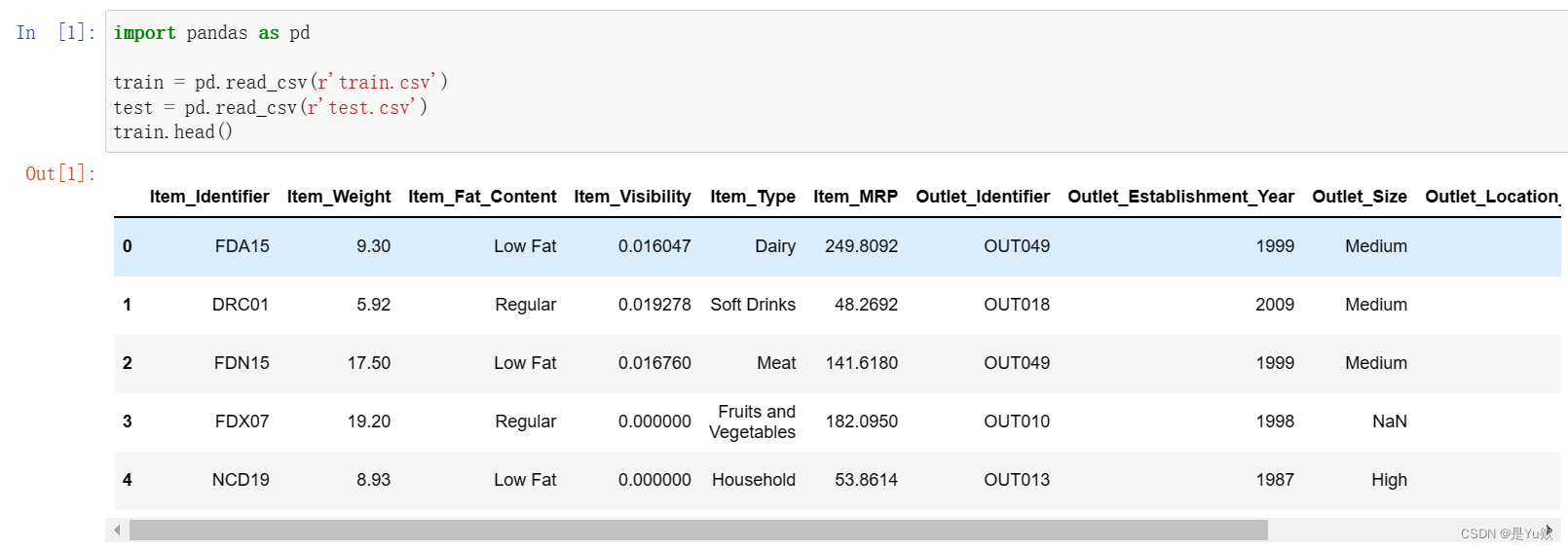
import pandas as pd
train = pd.read_csv(r'train.csv')
test = pd.read_csv(r'test.csv')
train.head()
# import basic libraries
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn import preprocessing
from sklearn.metrics import mean_squared_error
### mean imputations
# 产品重量为空的单元格用这列的平均值填充
train['Item_Weight'].fillna((train['Item_Weight'].mean()), inplace=True)
test['Item_Weight'].fillna((test['Item_Weight'].mean()), inplace=True)
### reducing fat content to only two categories
# 产品脂肪含量为low fat和LF的一律改为Low Fat,为reg的一律改为Regular
train['Item_Fat_Content'] = train['Item_Fat_Content'].replace(['low fat','LF'], ['Low Fat','Low Fat'])
train['Item_Fat_Content'] = train['Item_Fat_Content'].replace(['reg'], ['Regular'])
test['Item_Fat_Content'] = test['Item_Fat_Content'].replace(['low fat','LF'], ['Low Fat','Low Fat'])
test['Item_Fat_Content'] = test['Item_Fat_Content'].replace(['reg'], ['Regular'])
# 产品脂肪含量为low fat和LF的一律改为Low Fat,为reg的一律改为Regular
train['Outlet_Establishment_Year'] = 2013 - train['Outlet_Establishment_Year']
test['Outlet_Establishment_Year'] = 2013 - test['Outlet_Establishment_Year']
# 商店占地面积为空的单元格都用Small填充
train['Outlet_Size'].fillna('Small',inplace=True)
test['Outlet_Size'].fillna('Small',inplace=True)
# 商店占地面积为空的单元格都用Small填充
train['Item_Visibility'] = np.sqrt(train['Item_Visibility'])
test['Item_Visibility'] = np.sqrt(test['Item_Visibility'])
col = ['Outlet_Size','Outlet_Location_Type','Outlet_Type','Item_Fat_Content']
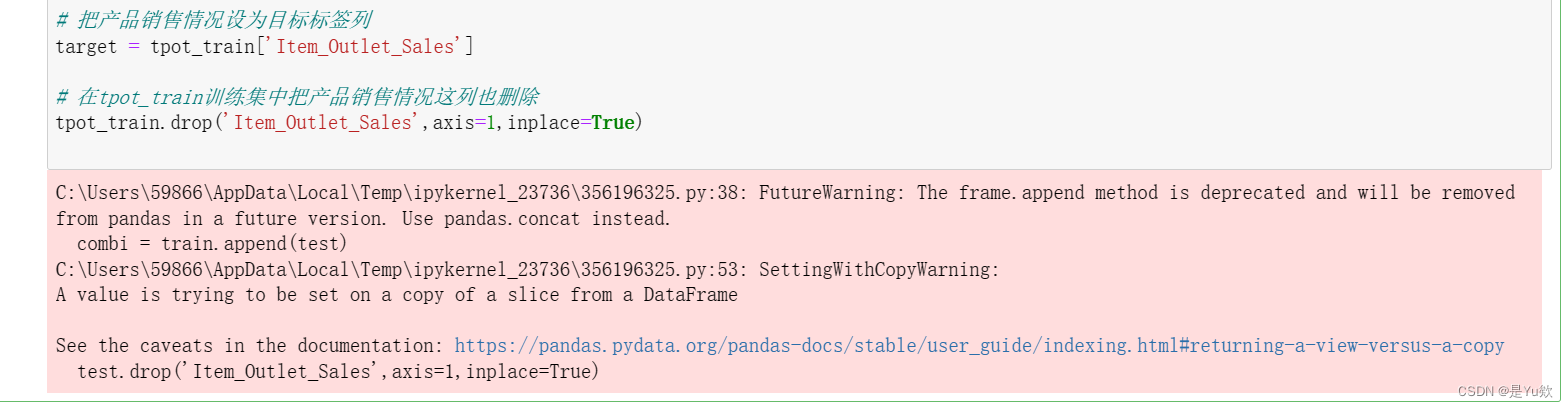
# 测试集添加一列产品销售情况,数据都用0填充,方便将训练集和测试集拼接起来
test['Item_Outlet_Sales'] = 0
# 拼接后的新DataFrame
combi = train.append(test)
# 名义变量转化为离散变量:商店占地面积、商店所在城市类型、商店类型和产品脂肪含量这四列
# 都调用scikit-learn库中的降维方法,会把各种类型都转为0、1、2这样的简单结构
number = preprocessing.LabelEncoder()
for i in col:
# fit_transform就是将序列重新排列后再进行标准化
# 参考:https://blog.csdn.net/weixin_47125742/article/details/115449648
combi[i] = number.fit_transform(combi[i].astype('str'))
combi[i] = combi[i].astype('object')
# 将拼接后的DataFrame根据原来大小重新拆分成训练集和测试集
train = combi[:train.shape[0]]
test = combi[train.shape[0]:]
# 刚才为了方便拼接,给测试集添加了一列虚假的产品销售情况,现在将这列删除
test.drop('Item_Outlet_Sales',axis=1,inplace=True)
## removing id variables
# 删除产品ID、产品类型和商店ID后的结果赋值给tpot_train训练集和tpot_test测试集
tpot_train = train.drop(['Outlet_Identifier','Item_Type','Item_Identifier'],axis=1)
tpot_test = test.drop(['Outlet_Identifier','Item_Type','Item_Identifier'],axis=1)
# 把产品销售情况设为目标标签列
target = tpot_train['Item_Outlet_Sales']
# 在tpot_train训练集中把产品销售情况这列也删除
tpot_train.drop('Item_Outlet_Sales',axis=1,inplace=True)
跑的时间有点久,可以打局英雄杀再来看看
# 接下来开始训练模型
# finally building model using tpot library
from tpot import TPOTRegressor
from sklearn.model_selection import train_test_split
# 将tpot_train训练集和目标标签列随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签
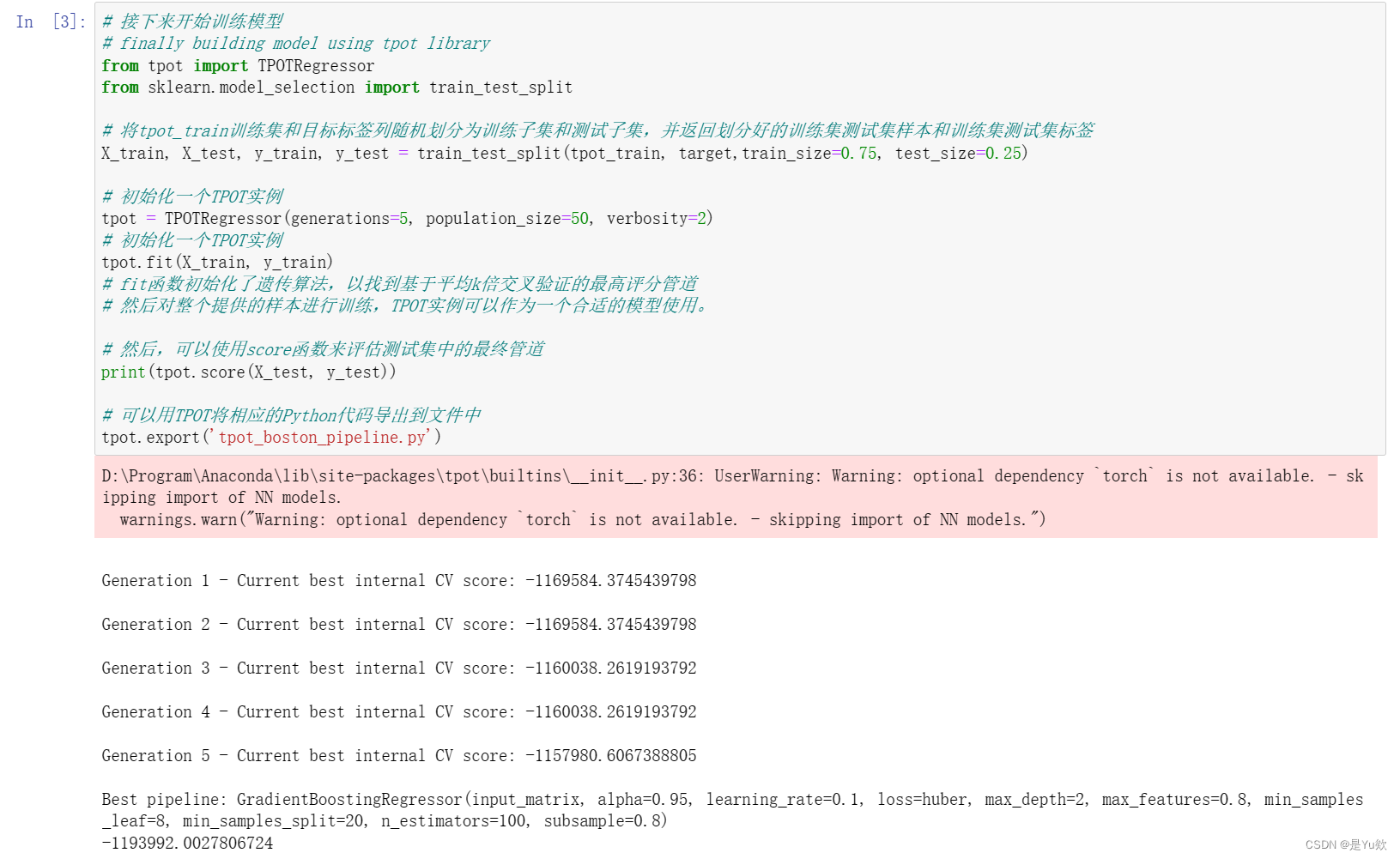
X_train, X_test, y_train, y_test = train_test_split(tpot_train, target,train_size=0.75, test_size=0.25)
# 初始化一个TPOT实例
tpot = TPOTRegressor(generations=5, population_size=50, verbosity=2)
# 利用fit函数来寻找最优的管道,fit函数初始化了遗传算法,以找到基于平均k倍交叉验证的最高评分管道
# 然后对整个提供的样本进行训练,TPOT实例可以作为一个合适的模型使用。
tpot.fit(X_train, y_train)
# 然后,可以使用score函数来评估测试集中的最终管道
print(tpot.score(X_test, y_test))
# 可以用TPOT将相应的Python代码导出到文件中
tpot.export('tpot_boston_pipeline.py')
## predicting using tpot optimised pipeline
# 使用TPOT优化后的代码对测试集进行预测
tpot_pred = tpot.predict(tpot_test)
sub1 = pd.DataFrame(data=tpot_pred)
#sub1.index = np.arange(0, len(test)+1)
# 预测结果列重命名为Item_Outlet_Sales
sub1 = sub1.rename(columns = {
'0':'Item_Outlet_Sales'})
# 新增Item_Identifier列
sub1['Item_Identifier'] = test['Item_Identifier']
# 新增Item_Identifier列
sub1['Outlet_Identifier'] = test['Outlet_Identifier']
# 对三个列重命名
sub1.columns = ['Item_Outlet_Sales','Item_Identifier','Outlet_Identifier']
# DataFrame列重新排序
sub1 = sub1[['Item_Identifier','Outlet_Identifier','Item_Outlet_Sales']]
# 输出符合比赛要求提交格式的csv文件
sub1.to_csv('tpot.csv',index=False)
据说效果没有那么好,没找到提交csv的地方,没法调参验证什么的。