I. INTRODUCTION
在视觉SLAM中,动态物体会带来如下挑战:
1)如何检测图像中的动态物体,从而:
a. 防止tracking算法使用动态物体上的匹配点对
b. 防止mapping算法把移动物体加入3D地图中
2)怎么去补全3D地图中那些被移动物体挡住从而缺失了的部分。
DynaSLAM是可以用于单目,双目,RGB-D的动态SLAM系统,相当于是在ORB-SLAM2上加了一个前端的模块,上面的两个挑战,这篇论文都给出了对应的解决办法。
- 对于单目和双目:使用CNN进行像素分割,把图像中的人和车剔除,特征提取时就不会这些上面提取。
- 对于RGB-D:结合多视角几何模型和深度学习(重点!)
II. RELATED WORK
在这个部分作者还总结了一下目前动态SLAM的一些方法:
- 常规去除动态的外点:
1)RANSAC
2)robust cost function - 对于基于特征的SLAM:
1)通过把地图特征点投影到当前帧来检测场景中的变化
2)检测和追踪已知的3D动态点,比如人
3)使用深度边缘点,他有一个相关联权重可以用来表示其属于运动物体的概率 - 对于直接法SLAM,他对动态物体更加敏感:
1)通过双目相机的场景流来检测移动物体
2)使用RGB-D光流分割动态物体
3)通过计算连续帧之间投影到同一平面的深度图的差别来找到静止的部分
4)计算连续RGB图像之间intensity的差别,像素分类通过对量化的深度图进行分割而完成?
上面列出关于特征法和直接法的方案都有一些问题没能解决:
- 不能估计一些保持静止的先验动态物体,比如静止的汽车,坐着的人
- 不能检测静态物体引起的变化,比如说被人拖动的椅子,或者被人丢飞的球。
而DynaSLAM不仅可以检测出正在移动的物体,还可以检测出一些“可被移动”的物体。
III. SYSTEM DESCRIPTION 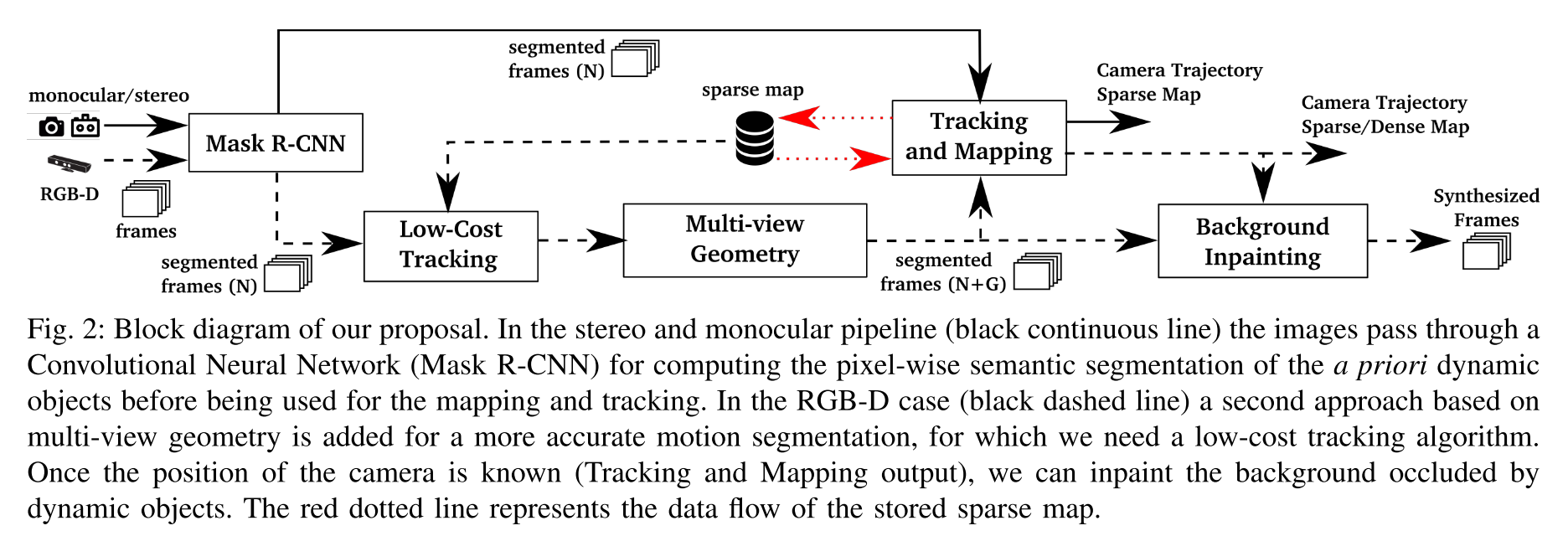
A. Segmentation of Potentially Dynamic Content using a CNN
使用MASK-RCNN进行像素级的分割,这里只用到了语义信息。
B. Low-Cost Tracking
上一步中把动态特征点去除后,用剩下的静态点线求出一个相机的位姿。由于计算特征点的时候,特征点本就喜欢落在分割轮廓这种高梯度区域(可以找图片看一下,比如,人身体分出来的分割边界,后面就是背景,有一些遮挡关系,分割边界附近会是梯度变化大的区域,特征点本身就容易落在这种地方),所以这个分割轮廓附近的点也不要,代码中用了erode处理。这一步的tracking计算比较简单,是ORB原版的简化。把地图特征点投影到图像帧,找到地图点在图像静态区域中对应的匹配点,通过最小化重投影误差来优化相机位姿。
C. Segmentation of Dynamic Content using Mask R-CNN and Multi-view Geometry
使用MASK-RCNN只能分割出先验的动态物体,但是不能找到那些“可以被移动”的物体,比如被人拿着的书,跟人一起移动的转椅等等。为了解决这种情况,就采用了下面的多视图几何的方法:
- 对于每一个输入帧,选择之前的和输入帧有最高重合度的多个关键帧(论文设置为5个),这个重合度是通过考虑新的一帧和每个关键帧之间的距离和旋转来决定的。
- 把之前关键帧中的每个关键点 x x x都投影到当前帧,得到关键点 x ′ x' x′和它们的投影深度 z p r o j z_{proj} zproj
- 对于每个关键点,它对应的3D点是 X X X。然后,计算 x x x和 x ′ x' x′反投影之间的夹角,即视差角 α \alpha α。如果角度大于30度,这个点就有可能被遮挡,之后就会被忽略。比如在TUM数据集中,如果视差角大于30度,由于视角的不同,静态点就会被视为动态。(这里用来区分遮挡情况和动态情况,相当于就是通过数据集总结出了一个视差角的上限)下面摘录一下github上的一个回答:
The angle alpha is the angle between between the rays X-KF and X-CF. That threshold on alpha should not vary much between datasets, you can leave it in 30. Since we are using depth variation to distinguish dynamic elements, we need to filter those variations that are due to normal occlusion of static elements.
Back-projection it refers to the point in the 3D from its projected view in the image and depth
How can find x’? A: we know the pose from the light tracking.
The way we do it is by putting a threshold in the parallax angle. If it is greater than 30 then occlusion may be due to static elements and not dynamic. So we cant consider them dynamic.
- 计算出关于深度的重投影误差: Δ z = z p r o j − z ′ \Delta z = z_{proj} - z' Δz=zproj−z′, z ′ z' z′是是当前帧中还有的关键点的深度(测量值)。如果 Δ z > τ z \Delta z > \tau_z Δz>τz,关键点 x ′ x' x′就会被视为动态物体。为了有一个好的精度和召回率,通过最大化 0.7 ∗ P r e s i o n + 0.3 ∗ R e c a l l 0.7*Presion + 0.3*Recall 0.7∗Presion+0.3∗Recall,将 τ z \tau_z τz定为0.4m。
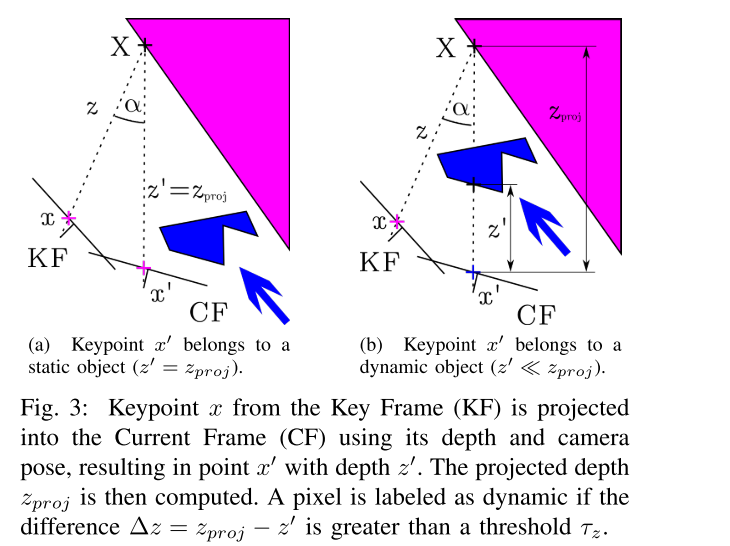
- 有一些被标记为动态的关键点位于移动物体的边界上,这可能会引起问题。为了避免这种情况,可以使用深度图像所提供的信息。如果一个关键点被设定为动态,但在深度图中它周围的区域有很大的方差,我们就把标签改为静态。
- 为了找到动态物体的所有像素点,在深度图的动态点周围进行区域增长算法。

这两种方法呈现出功能上的互补,所以最终取了两个Mask的并集,被分割的动态部分被从当前帧和地图中移除:
- 多视图几何:能识别出“可以被移动”的物体,但需要有多视图才能进行初始化。在图4a中看到,不仅检测到了图像前面的人,而且还检测到了他所拿的书和他所坐的椅子;但是远处的人并没有被检测到,原因有二:RGB-D相机在测量远处物体的深度时会有困难;其次,可靠的特征位于确定的,因此是附近的图像部分。
- 深度学习:只能识别出先验的动态物体,但是没有初始化方面的问题。可以在图4b看到,只有两个人被检测为动态物体,而且分割也不太准确;而浮动的书会被留在图像中,并错误地成为三维地图的一部分。
D. Tracking and Mapping
这一步中,系统的输入是:RGB图,深度图像,分割的Mask。
在图像中提取出的ORB特征点都被标记为静态点,如果特征点落在了分割轮廓周围(高梯度区域),就会被移除。
E. Background Inpainting
对于每一个被移除的动态物体,希望能用之前视图中的静态信息来补全丢失的背景信息(被动态物体遮挡了的部分),这样就可以合成一个没有移动物体的图像。
由于我们知道前一帧和当前帧的位置,可以将一些之前的关键帧(此处设置为前20个)的RGB和深度图投影到当前帧的动态区域:
- 有些空隙没有对应关系,被留为空白
- 有些区域不能被补全,因为其对应的场景部分到目前还没出现在关键帧中
- 如果它出现了,但没有有效的深度信息。这些空隙也不能用几何方法来重建,而需要一种更复杂的涂抹技术。
从下面的图5可以看到大部分被分割的部分已经用来自静态背景的信息进行了适当的补全。

IV. EXPERIMENTAL RESULTS
由于系统的非确定性,ORB-SLAM2在评估时将每个序列运行了5次然后比较中位数的结果;而这里因为动态物体进一步增加了不确定度,所以会把每个序列跑10次。
A. 使用TUM数据集
1. 和系统内部的比较

可以看到,在这个里面,结合了神经网络和多视图几何的方法(N+G)效果是最好的。值得关注的是DynaSLAM(G)的结果,反而误差会更高,论文中解释为:多视图几何的方法需要有运动,且他的分割结果在一段延迟之后才会变得准确,而在这个延迟中,被包含进去的动态物体就已经引入了误差。
2. 和ORB-SLAM2(RGB-D和单目)的比较
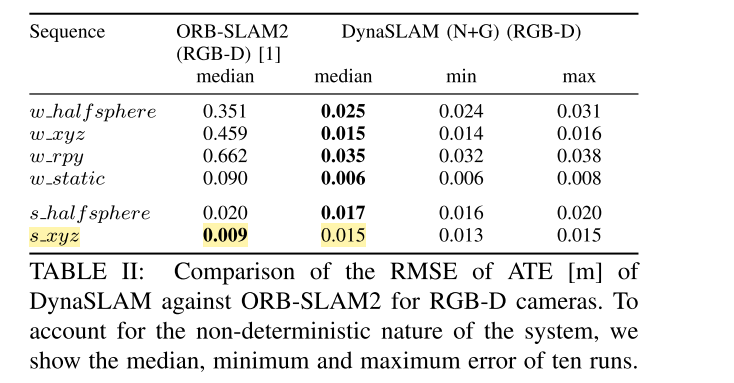
可以看到,与RGB-D模式下的ORB_SLAM2相比,DynaSLAM在高动态的场景下优势非常明显。有意思的地方是,作者提到用单目模式的ORB-SLAM2在动态环境下比RGB-D的更加准确,这里主要是因为不同的初始化方式:
- 对于RGB-D ORB-SLAM2:从非常开始的帧,系统就能进行初始化并开始追踪了,这时图像中的动态物体就会引入误差
- 对于单目的ORB-SLAM:直到有视差和使用静态假设的共识时,才会进行初始化。因此这个方法不会追踪完整的序列,有时会丢失一部分,或者甚至不进行初始化。(有点那种,打不赢的时候就溜了,只在打的赢的时候出现的感觉,不讲武德哈哈哈)
作者还对ORB-SLAM和DynaSLAM(mono)进行了比较,后者的初始化过程总是会更快。事实上,在一些高速动态的场景,ORB-SLAM只在移动物体从场景中消失后才能进行初始化。
总而言之,虽然DynaSLAM的准确度略低,但它好在用动态内容引导了系统,并产生了一个没有动态内容的地图,可重复用于长期应用。而DynaSLAM的准确度略低的原因是:估计的轨迹较长,因此会有累计误差。

B. KITTI数据集
由于KITTI数据集只能用于单目或者双目模式,所以这里的结果其实就是只使用深度学习得到Mask然后作用于ORB-SLAM的效果。
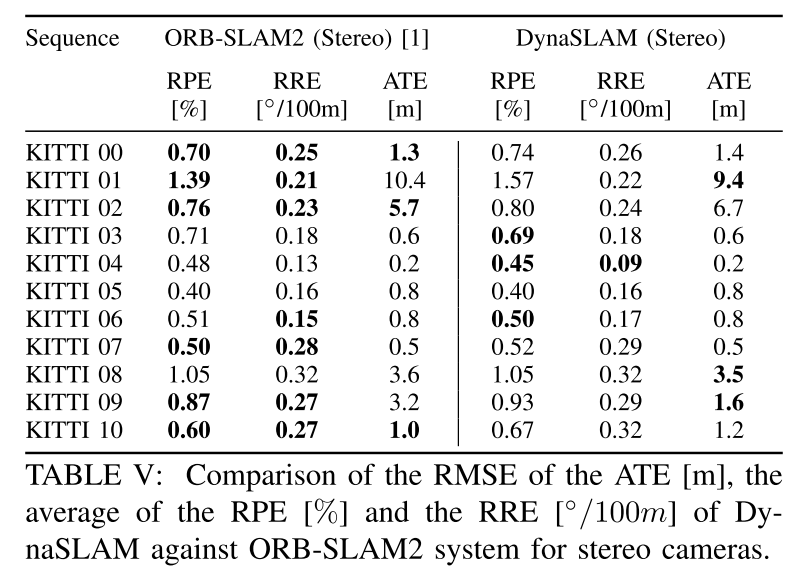
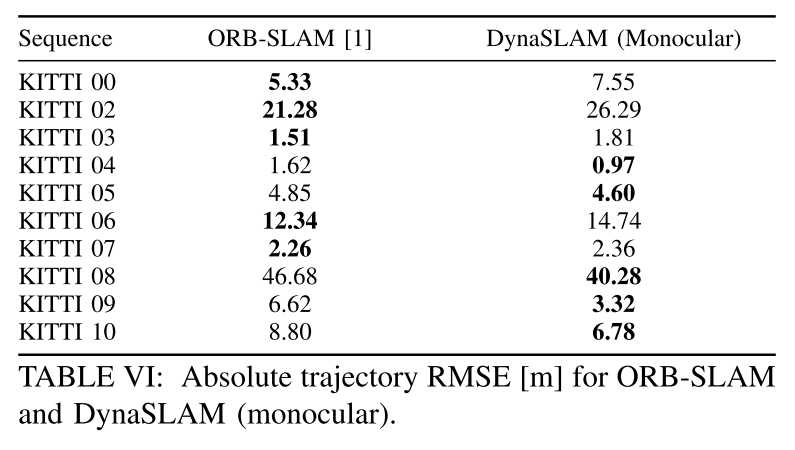 这两种情况效果其实是类似的,只是说单目对动态物体更加敏感(用了DynaSLAM提升多一点)。作者在这里举了一些具体的例子,来反映这个情况下存在的一些问题:
这两种情况效果其实是类似的,只是说单目对动态物体更加敏感(用了DynaSLAM提升多一点)。作者在这里举了一些具体的例子,来反映这个情况下存在的一些问题:
- 对01和04序列:所有的先验物体(汽车)都是在移动的,所以用Mask去除就刚刚好。
- 对于00,02,06,有一部分汽车其实是静止状态的,但Mask就一起把这些有用的信息也去掉了,这就导致使用的ORB特征点都是比较远的点,而且往往属于一些低纹理的区域,这样反而导致了更大的绝对轨迹误差的RMSE数值。但是,对于这种情况来说,回环和重定位算法的效果会更加鲁棒,因为这样建出来图只含有结构化的物体,更适合长期的应用。
C. 耗时分析
DynaSLAM还并不是一个实时的系统,下面是作者给出的计时:
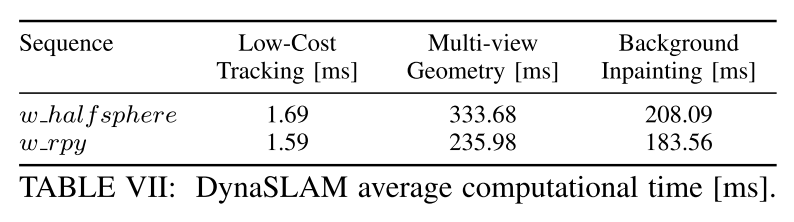 对于增加的多视图几何模块,耗时主要是因为Region Growing算法。
对于增加的多视图几何模块,耗时主要是因为Region Growing算法。