目录
一、CSV文件简介
CSV,全称为逗号分隔值(Comma-Separated Values),也称为字符分隔值文件,其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。通常都是纯文本文件。建议使用WORDPAD或是记事本来开启,再则先另存新档后用EXCEL开启,也是方法之一。
二、使用csv库读文件
1、两种方式
| 方式 |
含义 |
| csv.reader() |
创建一个 reader 对象,对象的内容是文件中每行信息构成的列表 |
| csv.DictReader() |
创建一个类似于reader的对象,每行内容会映射到一个字典中 |
2、csv.reader()示例
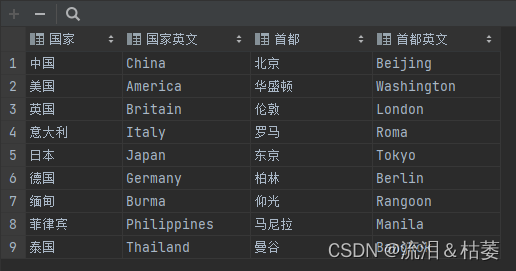
(1)、原始csv文件

(2)、代码及运行结果
import csv
file = 'csv文件.csv'
# 打开文件
with open(file, "r", encoding='utf-8') as f:
reader = csv.reader(f)
print("reader对象:\n", reader)
print("\n表头:\n", next(reader))
print("\ncsv文件内容:")
for row in reader:
print(row)运行截图:

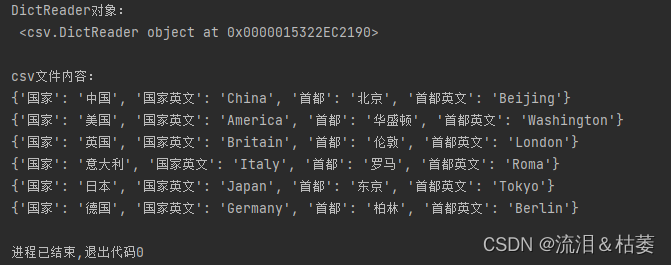
3、csv.DictReader()示例
(1)、原始csv文件

(2)、代码及运行结果
import csv
file = 'csv文件.csv'
# 打开文件
with open(file, "r", encoding='utf-8') as f:
dictReader = csv.DictReader(f)
print("DictReader对象:\n", dictReader)
print("\ncsv文件内容:")
for row in dictReader:
print(row)运行截图:
三、使用csv库写文件
1、两种方式
| 方式 |
含义 |
| csv.writer() |
创建一个 writer对象,以列表形式向文件中写入数据 |
| csv.DictWriter() |
创建一个类似于writer的对象,以字典形式向文件中写入数据 |
2、csv. writer()示例
(1)、原始csv文件
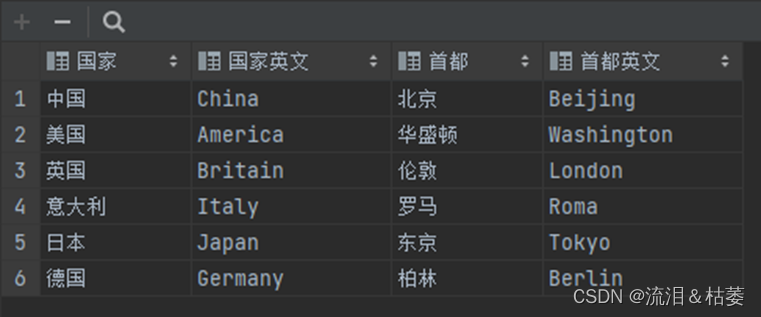
(2)、代码及运行结果
import csv
file = 'csv文件.csv'
# 打开文件
with open(file, "a", encoding='utf-8', newline='') as f:
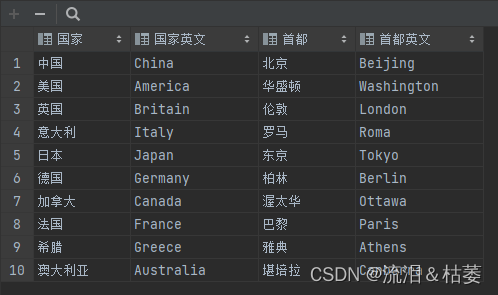
writer = csv.writer(f)
# writerow: 写入一条数据
writer.writerow(['加拿大', 'Canada', '渥太华', 'Ottawa'])
# writerow: 写入多条数据
writer.writerows([['法国', 'France', '巴黎', 'Paris'], ['希腊', 'Greece', '雅典', 'Athens'], ['澳大利亚', 'Australia', '堪培拉', 'Canberra']])运行截图:
3、csv.DictWriter()示例
(1)、代码(从头创建csv文件)
import csv
file = 'csv文件.csv'
# 打开文件
with open(file, "w", encoding='utf-8', newline='') as f:
header = ['国家', '国家英文', '首都', '首都英文']
dictWriter = csv.DictWriter(f, header)
# writeheader: 写入表头
dictWriter.writeheader()
# writerow: 写入一条数据
dictWriter.writerow({'国家': '中国', '国家英文': 'China', '首都': '北京', '首都英文': 'Beijing'})
data = [
{'国家': '秘鲁', '国家英文': 'Peru', '首都': '利马', '首都英文': 'Lima'},
{'国家': '哥伦比亚', '国家英文': 'Colombia', '首都': '波哥大', '首都英文': 'Bogota'},
{'国家': '俄罗斯', '国家英文': 'Russia', '首都': '莫斯科', '首都英文': 'Moscow'}
]
# writerows: 写入多条数据
dictWriter.writerows(data)(2)、运行截图

四、使用pandas库读文件
1、原始csv文件

2、读取全部数据
import pandas as pd
file = 'csv文件.csv'
# 打开文件
data = pd.read_csv(file, encoding='utf-8')
# 设置对齐输出
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
print(data)运行截图:

2、读取特定数据
import pandas as pd
file = 'csv文件.csv'
# 设置对齐输出
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
# nrows: 读取前nrows行 [nrows=0时即为表头]
data = pd.read_csv(file, encoding='utf-8', nrows=3)
print("只读取前三行:\n", data)
# usecols: 读取指定列
data = pd.read_csv(file, encoding='utf-8', usecols=[0, 2])
print("\n只读取第一列和第三列:\n", data)
# skiprows: 跳过指定行 [传入列表跳过指定几行或传入具体数字跳过前skiprows行]
data = pd.read_csv(file, encoding='utf-8', skiprows=range(1, 4))
print("\n跳过前三行:\n", data)运行截图:

五、使用pandas库写文件
1、将csv文件的部分内容写入新文件
(1)、原始csv文件
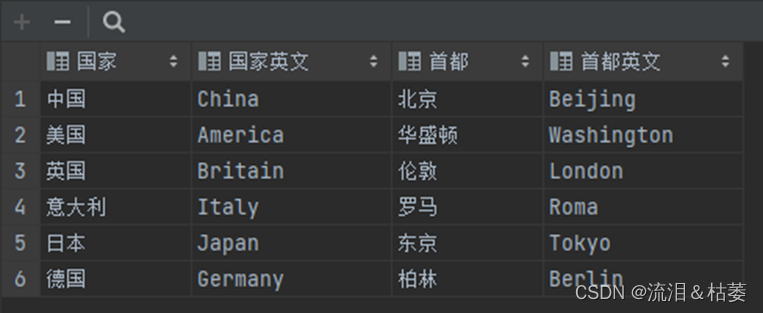 (2)、代码
(2)、代码
import pandas as pd
file = 'csv文件.csv'
# 读取旧文件【只读取部分内容】
data = pd.read_csv(file, encoding='utf-8', usecols=[0, 2], skiprows=range(1, 4))
new_file = 'csv新文件.csv'
# to_csv: 写入文件
data.to_csv(new_file, index=False)(3)、运行截图

2、将列表写入新文件
(1)、原始csv文件

(2)、代码
import pandas as pd
file = 'csv文件.csv'
data = {"国家": ["缅甸", "菲律宾", "泰国", ],
"国家英文": ["Burma", "Philippines", "Thailand"],
"首都": ["仰光", "马尼拉", "曼谷"],
"首都英文": ["Rangoon", "Manila", "Bangkok"]}
frame = pd.DataFrame(data)
# header: 是否写入表头
frame.to_csv(file, mode='a', header=False, index=False)(3)、运行截图