论文地址:SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and<0.5MB model size
1、摘要和介绍
相同精度水平的CNN网络,较少的参数的CNN架构有以下优势:
1、更高效的分布式训练;
2、将新模型导出到客户端时减少开销;
3、可行的FPGA和嵌入式部署。
SequeezeNet在与AlexNet相同的精度下,参数减少了50倍,另外配合上模型压缩技术,可以将其压缩到小于0.5MB(比AlexNet小100倍)
2、相关工作
2.1、模型压缩
首要目标是让网络有很少的模型参数并保持精度的模型。而目前有损压缩是一个很主流的方式,最早的有基于奇异值分解(SVD)的方式;权值剪枝也成为一种压缩的方式,从预训练模型开始,用零替换低于某个阈值的参数以形成稀疏矩阵,并对稀疏CNN执行迭代训练,最近其作者又提出了Deep Compression通过将网络进行剪枝、量化和基于霍夫曼编码等结合的方式,保持精度的条件下大比例的压缩网络,并进一步设计了一种称为EIE的基于FPGA的硬件加速器,直接对压缩的模型进行部署,实现了大幅度的压缩和节能。
2.2、CNN的微观结构
从最早的将CNN应用到手写数字识别,通常使用5*5的卷积核;而近年的如VGGNet等网络模型倾向使用3*3的卷积核;对于部分模型如Network-in-Network,GoogLeNet family of architectures(Inception-v2,Inception-v3,Inception-v4)在有些卷基层中使用1*1的卷积核。
对于越来越深的卷积层,人工的选择卷积核的尺寸是笨拙的。为了解决这个问题,提出了由具有特定固定组织的多个卷积层组成的各种更高级别的构建块或模块。例如,GoogLeNet论文提出了Inception模块,其包括多个不同维度的滤波器,通常包括1x1和3x3,有时5x5(Inception-v2),有时1x3和3x1(Inception-v3)。然后,许多这样的模块可能与附加的自组织层组合以形成完整的网络。我们使用术语CNN微架构来指代各个模块的特定组织和尺寸。
2.3、CNN宏结构
微结构设计单个层或者模块。我们将多个模块-端到端的CNN体系结构的体统组织称为CNN的宏结构。
研究最多的就是网络深度对网络性能的影响,12-19层的VggNet家族的提出并指出更深的网络层可以提高网络任务的精度。K. He et al提出了超过30层的卷机神经网络更大的提升卷机神经网络的精度。
跨越多个层或者模块的连接是CNN宏观结构研究的新兴领域。ResNet(残差网络)和Highway Networks分别提出了跨越多层连接的作用。例如将来自层3的激活与来自层6的激活相加连接,我们将这些连接称为旁路连接。ResNet的作者提供了一个具有和不具有旁路连接的34层CNN的A/B比较; 添加旁路连接可在ImageNet Top-5的精度上提高2个百分点。
2.4、神经网络设计空间探索
神经网络(包括深度神经网络和卷机神经网络)在微观结构、宏观结构、参数和超参数方面还有很多探索的空间。社区似乎希望获得关于这些因素对神经网络的准确性的影响(即设计空间的形状)。神经网络的设计空间探索(DSE)的许多工作集中在开发自动化方法以发现提供更高精度的神经网络架构。这些自动化DSE方法包括An optimization methodology for neural network weights and architectures(Snoek等人,2012),模拟退火(Ludermir等人,2006),随机搜索(Bergstra&Bengio,2012)和遗传算法(Stanley和Miikkulainen,2002)。每种方法提供一种一种思路来获得比baseline更高的精度,但后没有直观的给出模型设计空间形状的描述。我们避开了自动化方法,以这样一种方式重构CNN,以便我们可以进行原理性的A/B比较来研究CNN架构决策如何影响模型大小和准确性。
下面我们提出压缩和非压缩的SequeezeNet架构,然后探讨设计中微观架构和宏观结构的选择对像SqueezeNet这样的网络的影响。
3、SqueezeNet:更少的参数保持精度
主要是三部分内容:
1、整体的设计策略;
2、fire module的介绍;
3、通过fire module来构造SqueezeNet。
3.1、架构设计策略
更少的参数来保证精度无损,以下是三个最主要的策略:
1、1*1的卷积核代替3*3的卷积核,可以带来9倍的压缩;
2、减少3*3的卷积核的输入通道数;
3、将将采样放到卷积层之后以便获得更大的激活图。激活图的大小与输入图像的大小和降采样所采取的方法有关,通常在卷机或池化层中将步长(stride)设计成大于一,讲下采样设计到CNN的架构之中。早期的网络一般在网络较前的层设计的步长较大。大多数层将具有更小的激活图,如果网络中大多数层的步长为1,并且大于1步长的集中在网络的尾部,网路将会获取更大的激活图从而可以得到更高的分类精度。(He&Sun,2015)对4种不同的CNN结构应用了延迟下采样,并且在每种情况下延迟下采样导致更高的分类精度。
策略1和2是在保持准确性的同时减少CNN中的参数数量,策略3是关于在有限的参数上实现精度最大化。
3.2、The Fire Module
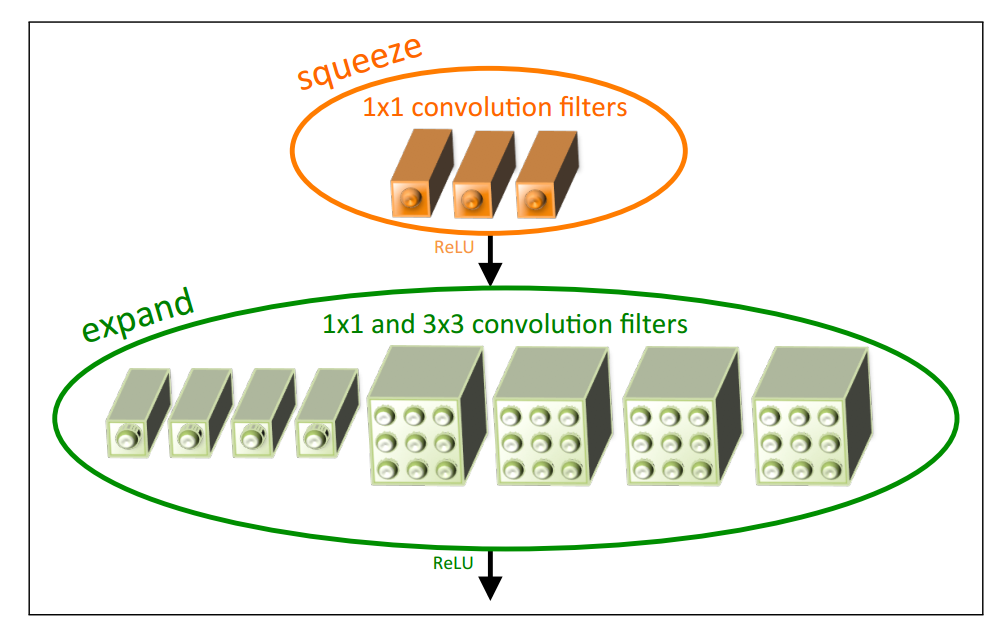
上如是fire module,fire module的定义如下:压缩的卷积层(1*1的卷积核)、传送到具有1*1和3*3卷积核的混合扩展层。Fire Module公开三个可调整的超级参数:s1*1、e1*1和e3*3。其中s1*1是squeeze层的滤波器的个数,s1*1是扩展层1*1卷积核的个数,e3*3是扩展层3*3的卷积核的个数。在使用Fire模块时,将e3*3设置为小于(e1*1+e3*3),这样可以限制输入到3*3卷积核的通道数目。
3.3、SqueezeNet的结构
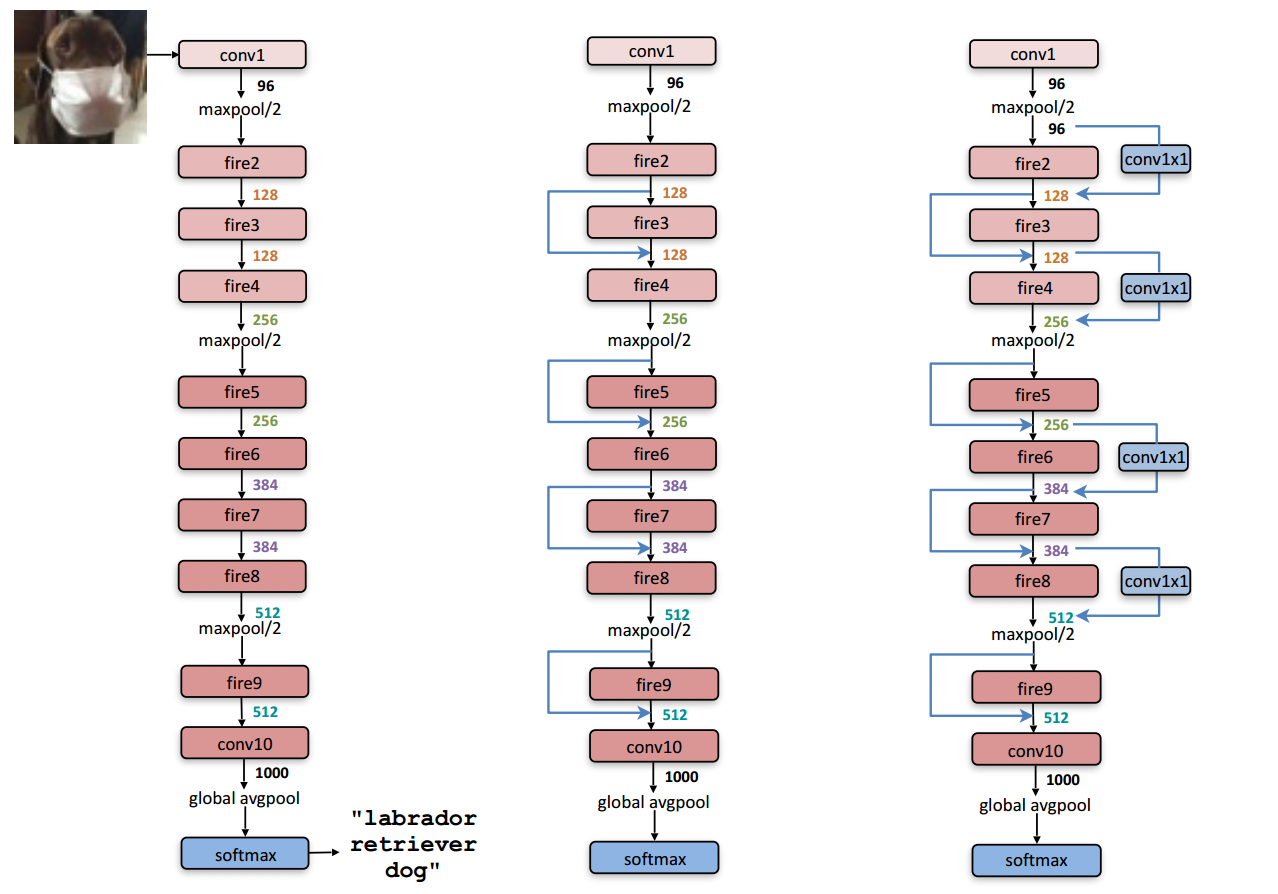
上图是整个SqueezeNet的架构,网络开始是一个的单独的卷机层(conv1),接着是8层的Fire-module(fire 2-9),然后以一个卷积层结束(conv10),网络2步长的池化操作在conv1、fire4、fire8之后。其中最左边的网络是标准的squeezeNet,中间的网络是简单旁路的squeezeNet,右边的网络是具有复杂旁路的squeezeNet,网络上有标示出每一层的卷积核的个数。
3.3.1、其他squeezeNet的细节
设计的细节以及设计直觉的来源:
1、为了使来自1x1和3x3滤波器的输出激活具有相同的高度和宽度,我们在输入数据中向扩展模块的3x3滤波器添加零填充的1像素边界;
2、ReLU(Nair&Hinton,2010)应用于挤压和膨胀层的激活。
3、在fire9模块之后应用比率为50%的dropout(Srivastava等人,2014)。
4、注意SqueezeNet中缺少全连接层; 这个设计选择是受到Network-in-Network(Lin et al,2013)架构的启发。
5、当训练SqueezeNet时,我们从0.04的学习率开始,我们线性减少整个训练的学习率,如(Mishkin et al,2016)所述。 有关训练协议(例如批量大小,学习速率,参数初始化)的详细信息,请参阅我们的Caffe兼容配置文件,位于这里:https://github.com/DeepScale/SqueezeNet。
6、Caffe框架本身不支持包含多个滤波器分辨率的卷积层(例如1x1和3x3)。为了解决这个问题,我们使用两个独立的卷积层来实现我们的扩展层:一个带1x1滤波器的层和一个带有3x3滤波器的层。然后,我们在通道维中将这些层的输出连接在一起。这在数值上等同于实现包含1x1和3x3滤波器的一个层。
4、SqueezeNet评估
baseline是2012的AlexNet-5,也就是压缩的AlexNet。

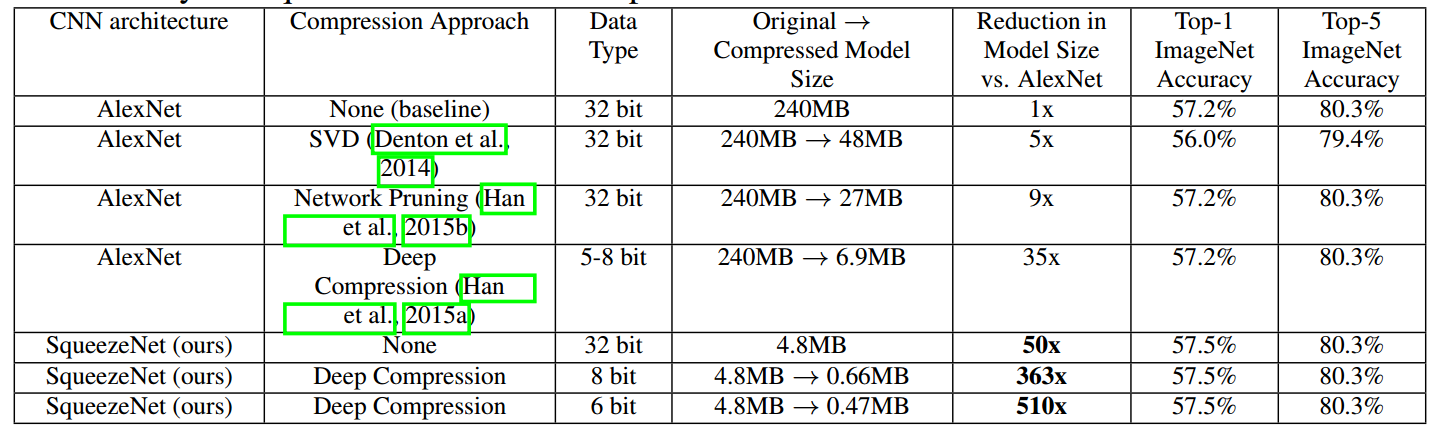
AlexNet由6000万个参数减少到120万左右,减少了将尽50倍。同时squeezeNet还可以和deep compression(上一篇博客)搭配起来,进行再一次的深度压缩,我们使用33%稀疏度和8-bits,这产生了与AlexNet相当的精度的0.66MB模型(363×小于32位AlexNet);在SqueezeNet上应用具有6-bits和33%稀疏性的深度压缩,我们产生具有等效精度的0.47MB型号(510x小于32位AlexNet)。 我们的小模型确实适合压缩。
5、CNN微观和宏观架构的空间探索
略
6、总结
1、squeezeNet在FPGA上的实现:https://github.com/Gaoshuai16/zynqnet