SqueezeNet AlexNet-level accuracy with 50x fewer parameters and 0.5MB model size
SqueezeNet
- 是一种网络结构,准确率与AlexNet相当(ImageNet数据集上),但参数量减少50倍。
- 同时,该网络通过压缩技术可以小于0.5mb,比AlexNet小510倍
本文主要内容:
- 介绍related work
- 描述并评估SequeezeNet Architecture
- 介绍CNN结构的model size和accuracy的选择
- 探索CNN宏观结构与微观结构。(微观:模型各层的组织和维度,宏观:CNN的所有层的高层组织)
Motivation
- 更小的模型在分布式训练的时候更加高效
- 服务端与客户端之间的模型传输更加方便快捷。
- 在FPGA等嵌入式环境下部署更加可行。
Related Work
- 要想模型参数少,最首要的工作就是模型压缩:SVD、Network Pruning、DeepCompression、EIE
- CNN微观结构:5x5 filters,VGG-3x3 filters,1x1 filters。随着网络加深,手工为每个层选择filter维度变得很麻烦,出现了许多block或者modules,如GooLeNet的Inception modules等
- 宏观上研究最多的应该是网络深度的影响,当然还有一些旁路连接的设计(bypass connections)。
SueezeNet
为了保证准确率且减少参数,本文设计CNN的时候的三个策略:
- 用1x1卷积核代替3x3 filters。这样filters数目固定情况下,参数少了9倍
- 减少输入通道至3x3 filters。一个完全由3x3卷积核组成的层,参数有(输入通道数)x(filter数目)x(3x3).所以除了减少上一条说的3x3的卷积数(用1x1替代,那3x3就少了),还应该减少输入通道。本文用squeeze layers来减少输入通道。
- 在网络的后面层才Downsample,这样卷积层(前面的)具有更大的激活图(特征图)。这个策略是出于准确率考虑的,更大的激活图通常都会有更好的分类效果。
Fire Module
Fire Module是本文实现上述三个策略的CNN结构的building block(网络结构块)。
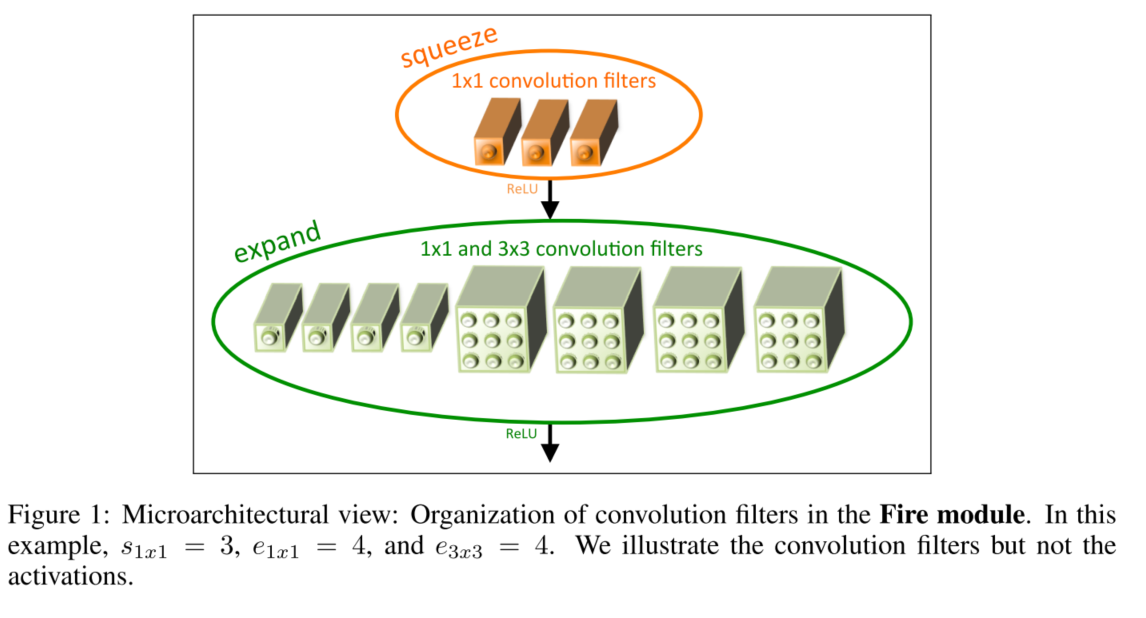
Fire Module = squeeze layer + expand layer
- squeeze layer:全部采用1x1,数目为S1x1个
- expand layer:存在e1x1个1x1的卷积核,e3x3个3x3的卷积核。
- 使用1x1的卷积核源于上述策略1,使s1x1<(e1x1 + e3x3),源于策略2,使得squeeze layer限制了3x3的filter的输入通道。
SqueezeNet Architecture
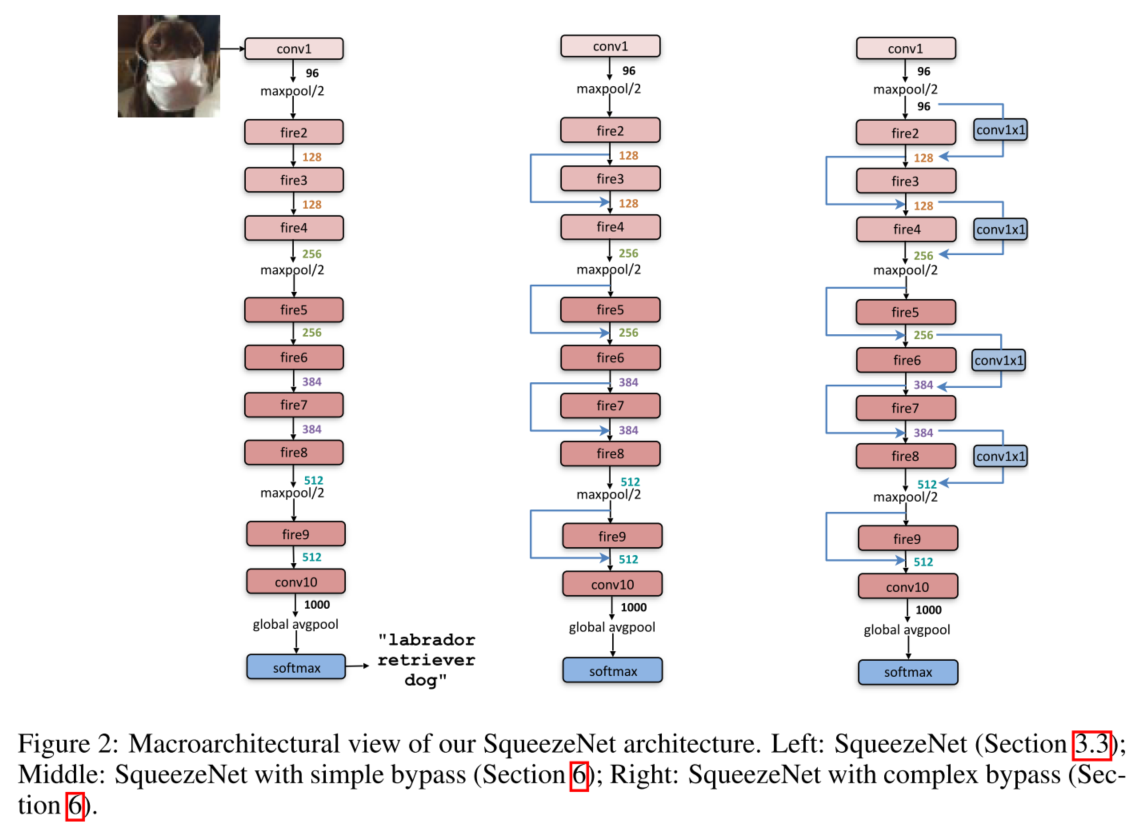
结构:input —— conv1(max-pooling,stride=2)—— fire modules(2—9,且fire4,fire8后接max-pooling)—— conv10(avg-pooling,stride=2)—— softmax
遵照策略3,pooling仅在conv1和fire4,fire8和conv10之后存在。fire module中的filter数量逐渐增加。
下图展示3中SqueezeNet结构,最左边就是上述的结构,后两种是with bypass的方案。
Other SqueezeNet Details
SqueezeNet结构设计中的其他细节和选择如下表所示
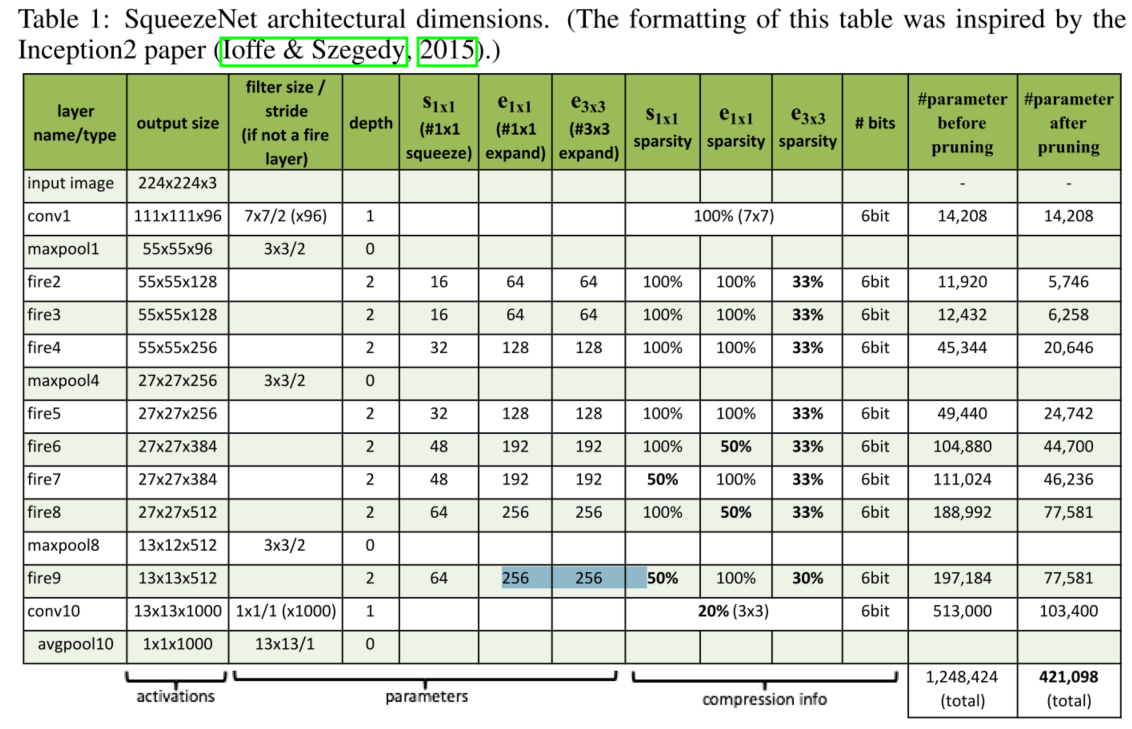
details:
- 为了让Fire Module中1x1和3x3的filter具有相同的输出维度,在3x3filter的输入数据上增加1像素的zero-padding
- ReLU在squeeze和expand layer后都执行。
- 在fire9之后采用50%Dropout
- 没有FC层
- 训练时,初始lr=0.04,之后按照论文《Systematic evaluation of cnn advances on the imagenet》描述的方案进行线性减少学习率。具体细节查看training protocol。solver.prototxt
- Caffe框架不支持包含多种卷积核的网络层,所以,本文通过两个独立的卷积层实现expand layer,之后再在channel维度上concatenate这两个卷积层的输出即可。这等同于一个层包含两种(1x1、3x3)filter
Evaluation of SqueezeNet

该部分主要评估压缩模型及其性能。本质上内容有些突兀。结论是想SqueezeNet这样的小模型依然可以被压缩。 by combining CNN architectural innovation (SqueezeNet) with state-of-the-art compression techniques (Deep Compression), we achieved a 510× reduction in model size with no decrease in accuracy compared to the baseline.
SqueezeNet + DeepCompression,得到比AlexNet小510倍同时保证准确度不变的模型!
CNN结构设计空间探索
SqueezeNet和其他的models仍然处在一个未知的CNN结构设计空间中(简单说就是没有什么具体的设计准则,已有模型仍然在摸索中)。
本文就这个问题做出探索,分为两部分
- 微观结构:关注单个神经网络层的维度和配置
- 宏观结构:端到端的组织架构
MicroArchitecture (微观)
-
Meta Parameters:结构探索时,设计了一些关于expand layer的filter数的变化的参数,1x1,3x3的filter的数量的系数,总之就是实验时的结构变量。
-
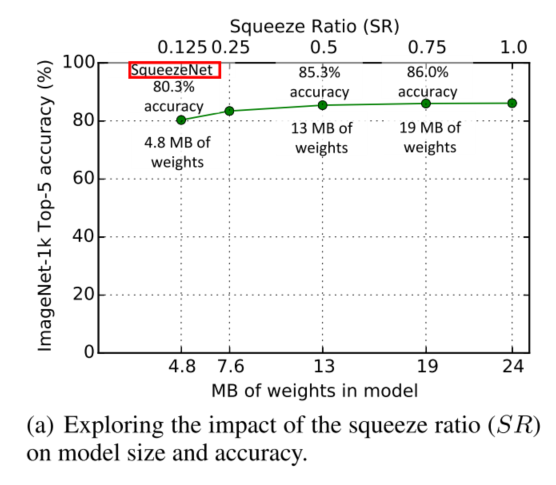
Squeeze Ratio:squeeze layer的filters数目与expand filters的数目之比。关于不同SR与准确率及模型大小的实验结果如下
-
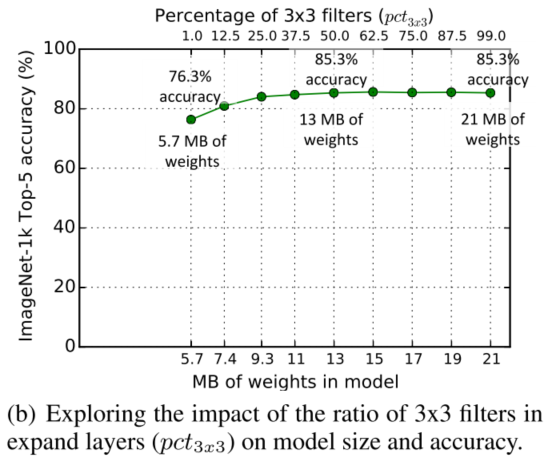
Trading Off 1x1 and 3X3 filters:之前的模型,如VGG大量使用3x3卷积核,而GoogleNet和NiN使用1x1和3X3卷积核,但没有进行分析原因。这里我们对卷积核大小对模型大小和准确率影响做了阐述。
MacroArchitecture(宏观)
宏观结构上,借鉴ResNet,我们探讨了3种结构
- SqueezeNet
- 带有简单旁路的SqueezeNet
- 带有复杂旁路的SqueezeNet
三种结构如上图2所示。

可见添加了旁路的结构准确率更高,作者认为:SqueezeNet通过Squeeze Layer减少8x的output channel(相比单纯的expand layer),大量的参数减少意味着通过SqueezeNet的信息受到限制,但是旁路的使用为信息的传递开辟了道路。