部署方式变迁
在服务部署上主要经历了三个历程:
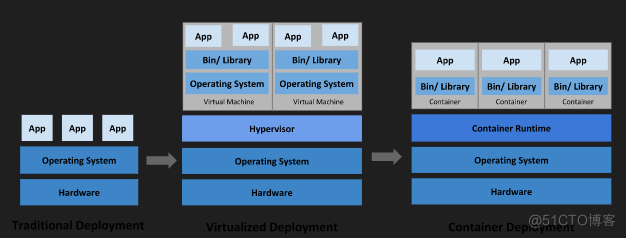
传统部署:互联网早期,会将服务直接部署到物理机上
优点:简单,不需要其他技术的参与
缺点:不能灵活定义资源使用边界,很难合理分配计算机资源,服务之间会容易产生影响
虚拟化部署:可以在一台物理机上运行多个虚拟机
优点:
作为解决方案,引入了虚拟化
虚拟化技术允许你在单个物理服务器的 CPU 上运行多个虚拟机(VM)
虚拟化允许应用程序在 VM 之间隔离,并提供一定程度的安全
一个应用程序的信息 不能被另一应用程序随意访问。
虚拟化技术能够更好地利用物理服务器上的资源
因为可轻松地添加或更新应用程序 ,所以可以实现更好的可伸缩性,降低硬件成本等等。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
缺点:
虚拟层冗余导致的资源浪费与性能下降
容器化部署:与虚拟化相似,但共享操作系统
优点:
容器类似于 VM,但可以在应用程序之间共享操作系统(OS)。
容器被认为是轻量级的。
容器与 VM 类似,具有自己的文件系统、CPU、内存、进程空间等。
由于它们与基础架构分离,因此可以跨云和 OS 发行版本进行移植。
缺点:
自动收缩扩展
无法大批量控制
容器相关
容器优势:
- 敏捷性:敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 及时性:持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性),支持可靠且频繁的 容器镜像构建和部署。
- 解耦性:关注开发与运维的分离:在构建/发布时创建应用程序容器镜像,而不是在部署时。 从而将应用程序与基础架构分离。
- 可观测性:可观察性不仅可以显示操作系统级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
- 跨平台:跨开发、测试和生产的环境一致性:在便携式计算机上与在云中相同地运行。
- 可移植:跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
- 简易性:以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
- 大分布式:松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
- 隔离性:资源隔离:可预测的应用程序性能。
- 高效性:资源利用:高效率和高密度
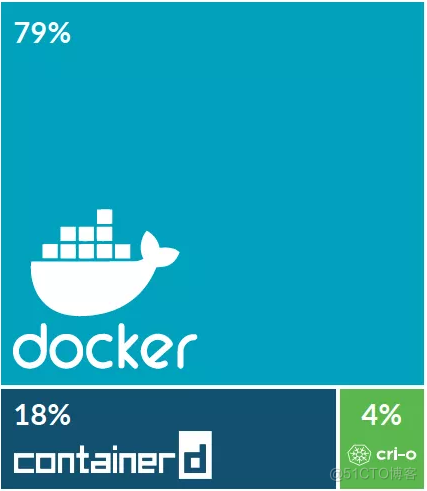
市场份额
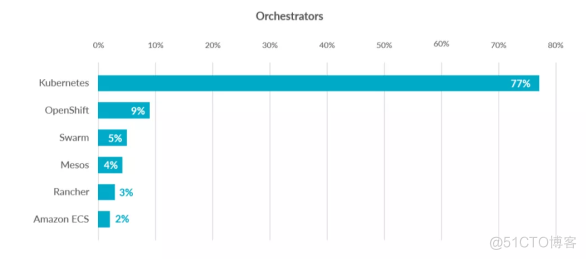
服务编排
K8S 简介
Kubernetes 是一个全新的基于容器技术的分布式架构方案,是谷歌严格保守十几年的 borg 系统的一个开源版本,于 2014 年 9 月发布第一个版本,2015 年 7 月发布第一个正式版本
kubemnetes的本质是一组服务器集群,它开源在集群的每个节点上运行特定的程序,来对节点中的容器进行管理,它的目的就是实现资源管理的自动化
K8S 特点
- 自愈: 一旦某个容器坏掉,能够迅速启动一个新的容器,保证业务的高可用.
- 弹性伸缩: 可以根据业务的压力,自动对集群中正在运行的容器数量进行调整,当应用压力大时会自动将容器运行的数量调大,当压力降低后,会将扩展的容器删除
- 服务发现: 可以通过服务发现找到依赖的服务
- 负载均衡: 当一个应用启动了多个容器,能够自动实现负载均衡
- 版本回退: 当新发布的程序版本有问题时,可以立即回退到上一个版本
- 故障切换: 当一个节点挂掉后,上面运行的所有容器会被自动迁移至正常的节点
- 存储编排: 可以根据容器自身的需求自动创建存储卷
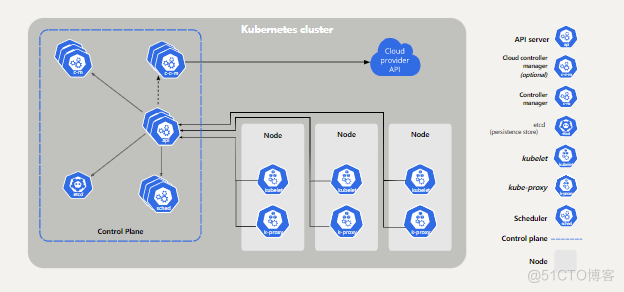
K8S 各节点组件
kubernetes 集群主要由控制节点 (master) 和工作节点(node组成),每个节点上都会安装不同的组件
Master: 集群的控制平面,负责集群的决策 (管理者)
- APIServer: 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制。
- Scheduler:负责集群资源调度,按照预定的调度策略将pod调度到相应的node节点上,一个k8s集群有很多个node节点,master就是通过scheduler进行一系列算法,最终觉决定要在哪个node节点上创建pod。
- Controler-Manager: 负责维护集群的状态,比如程序部署、故障迁移、自动扩展、滚动更新,当一个node节点挂掉后,容器的迁移都是由Control了Manager来操作的。
- Etcd: 负责存储集群中各种资源对象的信息,集群中有多少少个node、多少个master、哪个容器运行在哪个node节点等待各种集群信息都是存储在Etcd中
Node: 集群的数据平面,负责为容器提供运行环境 (工作者)
- Kubelet: 负责维护容器的生命周期,调用docker来创建、更新、删除容器
- KubeProxy: 负责提供集群内部的服务发现和负载均衡,容器运行后肯定是要对外提供访问了,KubeProxy 就是将容器对外暴露,让外界能够访问到
- Runtime:负责节点上容器的各种操作
kubernetes集群架构图
集群原理:
kubernetes 部署集群后,master 和node都会将自身的信息存储到 etcd 数据库运维要创建一个nginx容器,创建请求首先被发送到 master 节点的 apiserver 组件,apiserver 组件会调用 schedule 组来决定在哪个 node 节点上运行该容器,此时,scheduler组件会读取etcd中各个节点的信息,然后根据一定的算法最终决定在哪个node节点运行容器,并告知 apiserver,apiserver 调用 controller-manager 组件去调度对应的node节点进行部署容器,node 节点上的 kubelet 组件收到部署容器的指令后,会调用docker,最后由docker来启动容器,当容器启动后,会调用 kube-proxy 将容器里面的 nginx 暴露给外界,当用户访问时,也是通过 kube-proxy 进行访问