Kubernetes(https://github.com/kubernetes/kubernetes)是Google公司团队于2014年基于内部集群管理系统Borg开源发起并维护的开源容器集群管理系统,它基于Go语言实现,支持如Docker等容器技术,使用它,用户可以轻松搭建和管理一个私有容器云。
技术优势:
1. 优秀的API设计,以及简洁高效的架构设计,主要组件个数很少,彼此之间通过接口调用
2. 基于微服务模式的多层资源抽象模型,兼顾灵活性与可操作性,提出的Pod模型被许多平台借鉴
3. 可扩展性好,模块化容易替换,伸缩能力极佳,1.2.0版本单集群支持1000个节点,同时运行30000个Pods
4. 自动化程度高,真正实现"所得即所需",用户通过模板声明服务后,生命周期都是自动化管理
5. 部署支持多种环境,包括虚拟机、逻辑部署,还很好地支持常见云平台,包括AWS、GCE等
6. 支持丰富的运维工具,方便用户对集群进行性能测试,问题检查和状态监控
7. 自带控制台、客户端命令等工具,允许用户通过多种方式与Kubernetes集群进行交互
Kubernetes有三大核心概念:
1.集群组件
集群由使用Kubernets组件管理的一组节点组成,这些节点提供了容器资源池供用户使用,主要由
管理组件(Master)和
工作节点(Node)组件构成。Kubernetes集群的主要任务始终围绕着应用的生命周期。通过将
不同资源进行不同层次的抽象,Kubernetes提供了灵活可靠的生命周期管理。
Master组件
提供所有与管理相关的操作,例如调度、监控、支持对资源的操作等,它会通过Node、Controller来定期检查所管理的Node资源的健康状况,完成Node的生命周期管理。在Master节点上运行着集群管理相关的一组进程kube-apiserver、kube-controller-manager、和kube-scheduler,这些进程实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控等功能。
Node节点组件
实际工作的计算实例(在1.1版本之前称为Minion),可以是虚拟机或物理机器,在创建Kubernetes集群过程中,都要预装一些必要的软件来响应Master的管理。在Node节点上,Kubernetes管理的最小运行单元是Pod,其上运行着kubelet、kube-proxy服务进程,这些服务进程负责Pod的创建、启动、监控、重启等功能。
(目前Node的配置还只能通过人工手动进行,未来可以支持通过Master来自动配置)
Node节点有如下几个重要属性:
-
地址信息
包括:
- 主机名(HostName): 节点所在系统的主机别名,
基本不会用到
- 外部地址(ExternalIP): 集群外部客户端可以通过该地址访问到的节点
- 内部地址(InternalIP): 集群内可访问的地址,外部往往无法通过该地址访问节点
-
阶段状态
包括:
- 待定(Pending):新创建节点,还未就绪状态,需要进一步的配置
- 运行中(Running): 正常运行中的节点,可被分配Pod,会定期汇报运行状态消息
- 终止(Terminated): 节点已经停止,处于不可用状态,判断条件为5分钟内未收到运行状态消息
-
资源容量
包括常见操作系统资源,如CPU、内存、最多存放的Pod个数等
-
节点信息
包括操作系统内核信息、Kubernets版本信息、Docker引擎版本信息等,会由kubelet定期汇报
2.资源抽象
每个资源都是一个REST对象,通过API进行操作,通过JSON/YAML格式的模板文件进行定义,在Kubernetes代码包的example目录下自带了很好的示例模板文件,应多参考。
主要包括:
2.1
容器组(Pod): 由位于同一节点上若干容器组成,彼此共享网络命名空间和存储卷(Volume)。Pod是Kubernetes中进行管理的最小资源单位,是最为基础的概念。跟容器类似,
Pod是短暂的,随时可变的;
2.2
服务(Service): 若干(往往是同类型的)Pod形成的对外提供某个功能的抽象,
不随Pod改变而变化,带有唯一固定的访问路径,如IP地址或者域名。
2.3
复制控制器(Replication Controller): 负责启动Pod,并维护其健康运行的状态。是用户管理Pod的句柄。
2.4
部署(Deployment): 创建Pod,并可根据参数自动创建管理Pod的复制控制器,并且支持升级。1.2.0版本引入提供比复制控制器更方便的操作。
2.5
横向Pod扩展器(Horizontal Pod Autoscaler, HPA): 类似云里面的自动扩展组,根据Pod的使用率(类似CPU)自动调整一个部署里面Pod的个数,保障服务可用性
3. 辅助概念
3.1
注解(Annotation): 键值对,可以存放大量任意数据,一般用来添加对资源对象的详细说明,可供其他工具处理
3.2
标签(Label): 键值对,可以标记到资源对象上,用来对资源进行分类和筛选
3.3
名字(Name): 用户提供给资源的别名,同类资源不能重名
3.4
命名空间(Namespace): 这里是指资源的空间,避免不同租户的资源发生命名冲突,另外可以进行资源限额
3.5
持久卷(Persistent Volume): 类似于Docker中的数据卷的概念,就是一个数据目录,Pod对其有访问权限。
3.6
秘密数据(Secret): 存放敏感数据,例如用户认证的口令
3.7
选择器(Selector): 基于标签概念的一个正则表达式,可通过标签来筛选出一组资源
3.8
Daemon集(DaemonSet): 确保节点上肯定运行某个Pod,一般用来采集日志和监控节点
3.9
任务(Job): 确保给定数目的Pod正常退出(完成了任务)
3.10
入口资源(Ingress Resource): 用来提供七层代理服务
3.11
资源限额(Resource Quotas): 用来限制某个命名空间下对资源的使用,开始逐渐提供多租户支持
3.12
安全上下文(Security Context): 应用到容器上的系统安全配置,包括uid、gid、capabilities、SELinux角色等
3.13
服务账号(Service Accounts): 操作资源的用户账号
安装使用Kubernetes
1、关闭Centos自带的防火墙服务(实际测试,可以不需要关闭firewall,建议保留运行)
systemctl disable firewalld
systemctl stop firewalld
2、安装etcd和Kubernetes
yum install -y etcd kubernetes
安装完成后需要进行如下配置:
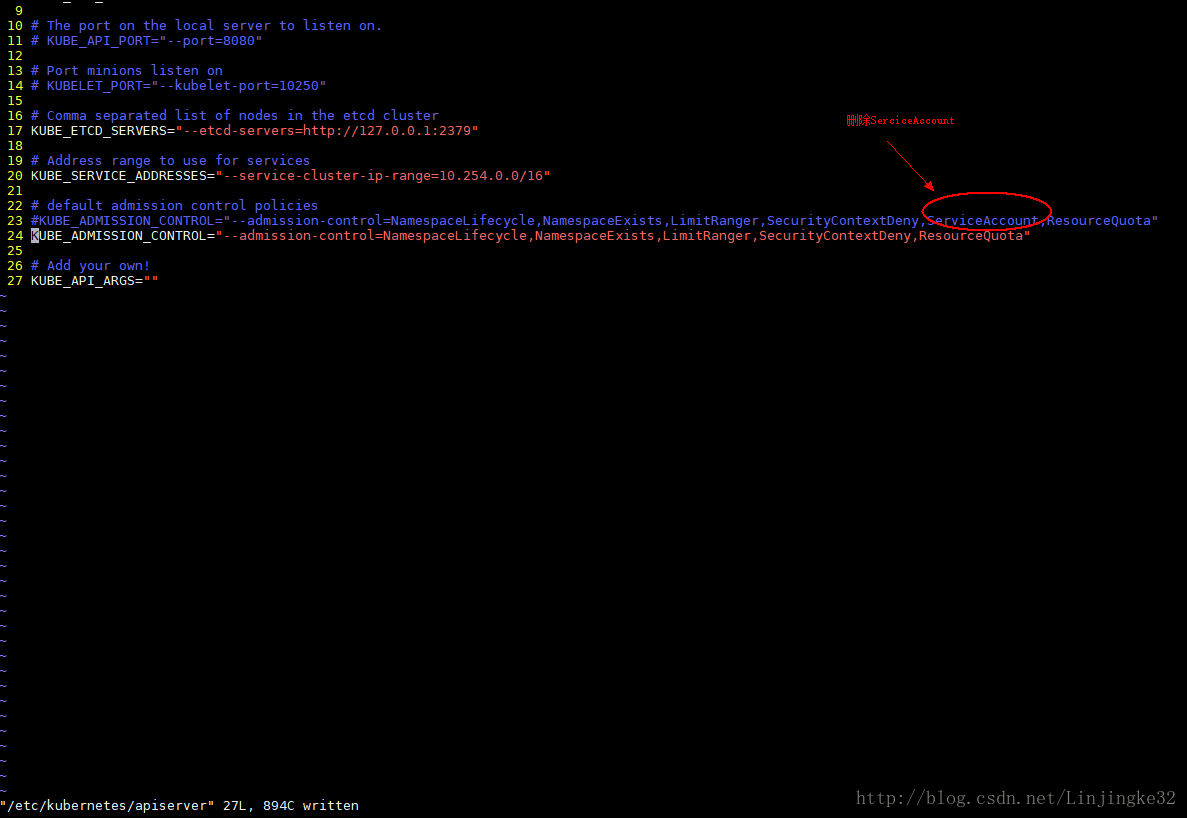
//
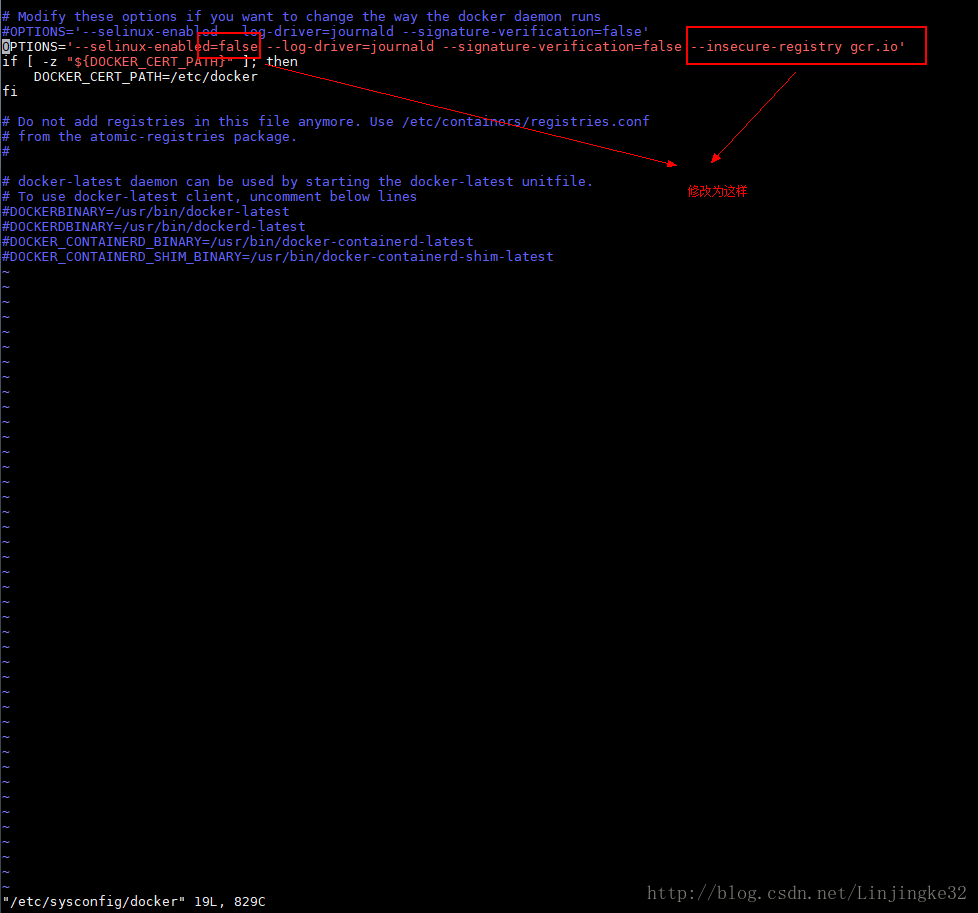
按如下顺序启动:
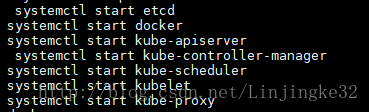
这样,就安装启动完成了一个单机版的Kubernetes集群搭建。
3、新建一个mysql的pod
准备,因为会自动下载pause容器,可能会遇到国外网络限制,无法从gcr.io拉取pause0.8.0的镜像。那么很简单,就找个可用的镜像拉取即可。
docker pull docker.io/kubernetes/pause
docker pull docker.io/kubernetes/pause

然后新建mysql-rc.yaml文件,内容如下:
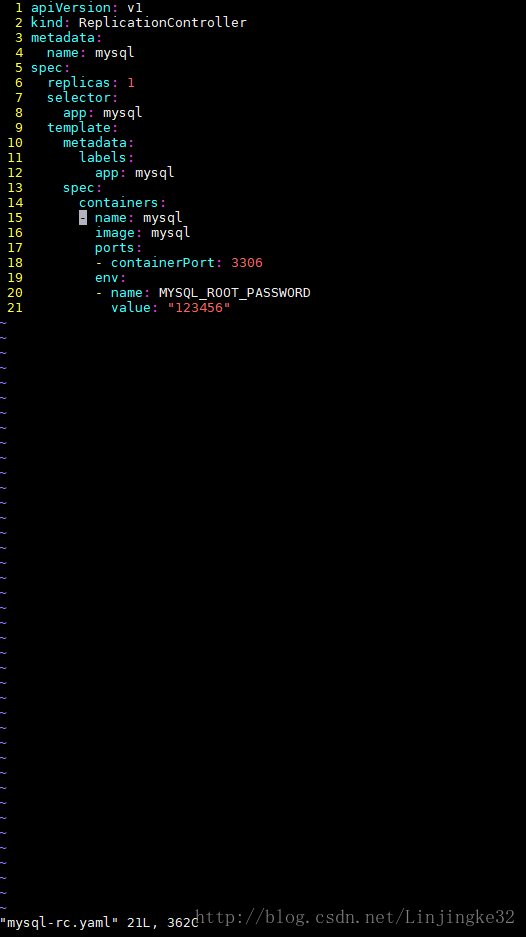
说明:
metadata:
name: mysql ---> RC的名称,全局唯一性!!
replicas: 1 ---> Pod副本的期待的数量
selector:
app: mysql ---> 符合目标的Pod拥有此标签
template: ---> 根据此模板创建Pod
metadata:
labels:
app: mysql ---> Pod副本拥有的标签,对应RC的Selector
spec:
contiainers: ---> Pod容器的定义部分
- name: mysql
从上面可以看到,在一个RC定义文件中,包含如下3个关键信息:
1. 目标Pod的定义
2. 目标Pod需要运行的副本数量(Replicas)
3. 要监控的目标Pod的标签(Label)
执行如下命令,把它发布到Kubernetes集群中,在Master节点执行命令(这里就是同一台机器):

可以查看刚刚创建的RC和pod的情况:

等了几分钟,不对路,还是状态"ContainerCreating",看看其状态:(kubectl describe pod mysql-1qkm1)
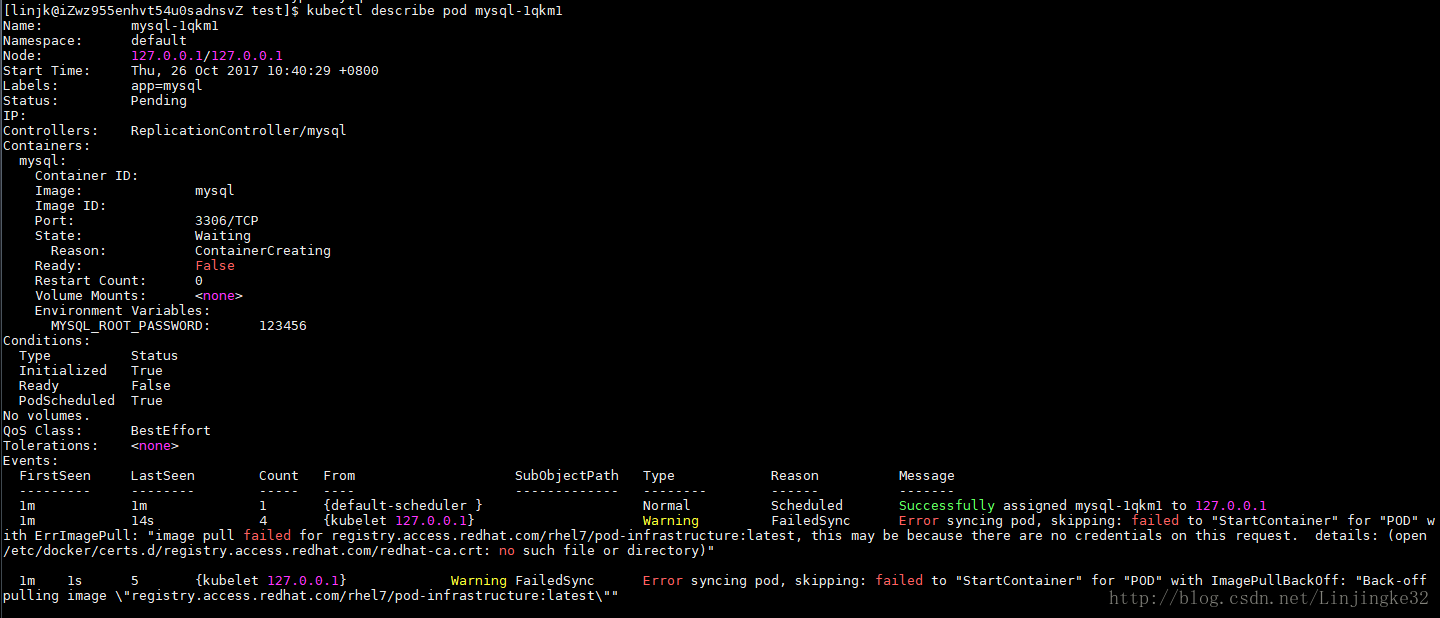
出现如上错误,安装缺少的包( sudo yum install *rhsm* ),删除Pod后( kubectl delete -f mysql-rc.yml ),再次创建,稍等片刻,成功了:
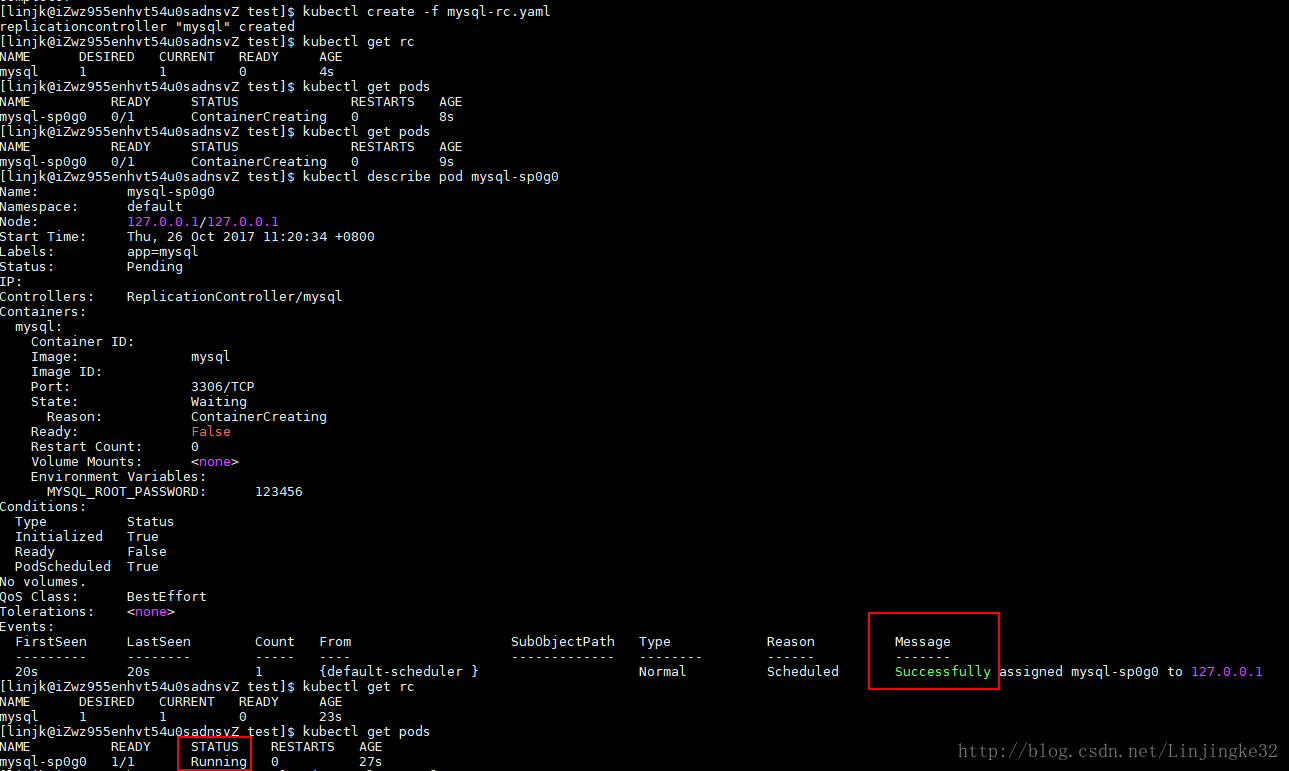
看看运行的docker容器:

可以看到,提供MySQL服务的Pod容器已经创建好在运行了,另外,还多了一个容器,这是来自谷歌的pause容器。
4、创建好POD后,接下来创建与之关联的Service----MYSQL的定义文件,名称: mysql-svc.yaml:
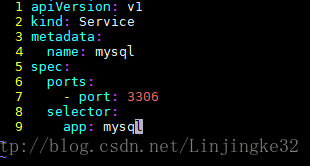
创建service:

可以发现,mysql服务被分配了一个10.254.59.106的集群IP地址,它是一个虚地址,随后,Kubernetes集群中其他新创建的Pod就可以通过Service的集群IP+端口号3306来连接访问它了。
注意:
通常情况,集群Ip(Cluster IP)是在Service创建后由Kubernetes系统自动分配的,其他Pod无法预先知道某个Service的Cluster IP地址,因此需要一个服务发现机制来找到这个服务,对这个问题,Kubernetes利用Linux的环境变量来处理,根据Service的唯一名字,容器可以从环境变量中获取到Service对应的Cluster IP地址和端口,从而进行连接访问。
5、数据容器弄好了,现在来创建应用层,这里基于tomcat容器
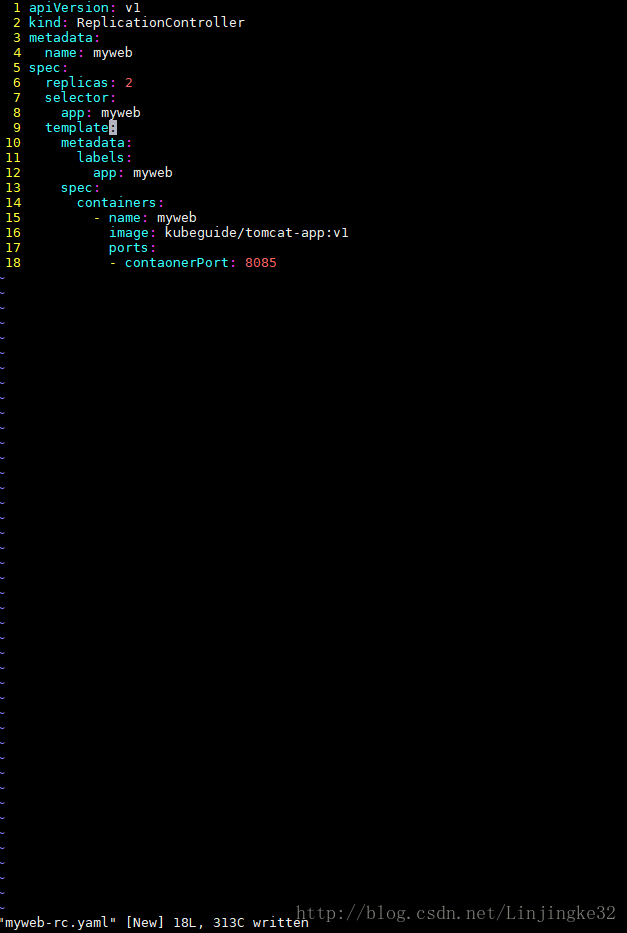
上面的配置文件这里,tomcat容器内,依赖环境变量MYSQL_SERVICE_HOST值去连接MYSQL,更安全应该是使用服务的名称"mysql",配置文件可更改如下,这里就先不更改了:
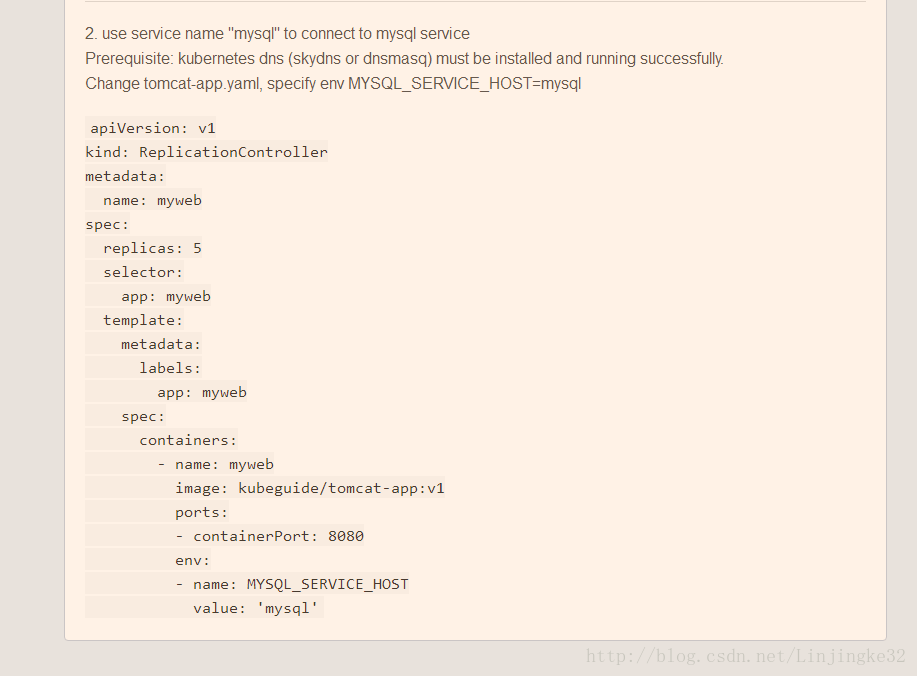
另外,这里依赖于镜像kubeguide/tomcat-app:v1,为了提高创建速度,先下载该镜像:
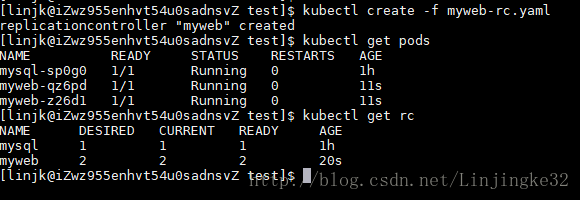
然后创建RC,因为在配置文件指定了两个副本,所以,这里有2个Pod:
接着,创建对应myweb的Service,文件为myweb-svc.yaml:
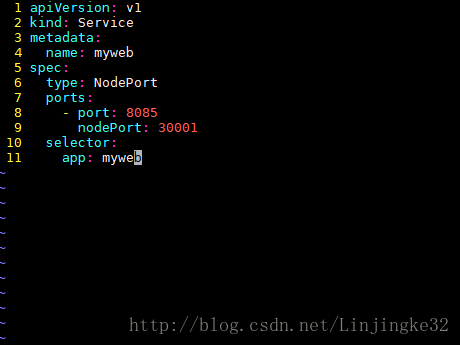
这里设置该Service开启了NodePort方式的外网访问模式,并映射宿主机的3001端口到8085端口
创建Service:
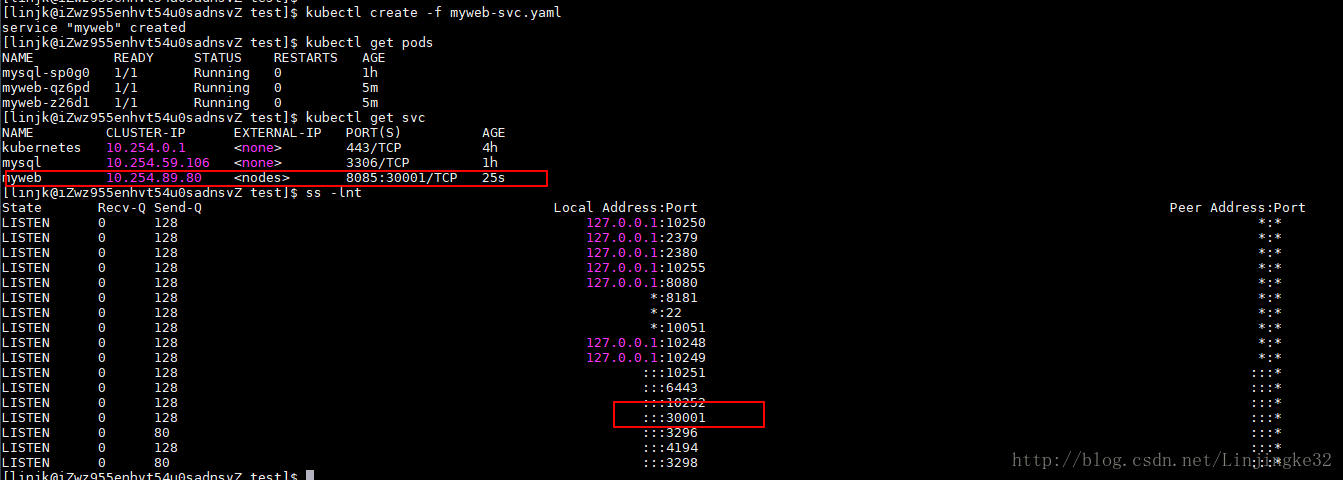
启动完成。
6、验证
测试发现,8085端口不行,因为用tomcat的默认的镜像,所以,需要修改回其默认的8080端口,修改myweb-rc.yaml和myweb-svc.yaml的8085为8080,这里就不修改截图了,删除重新创建即可:
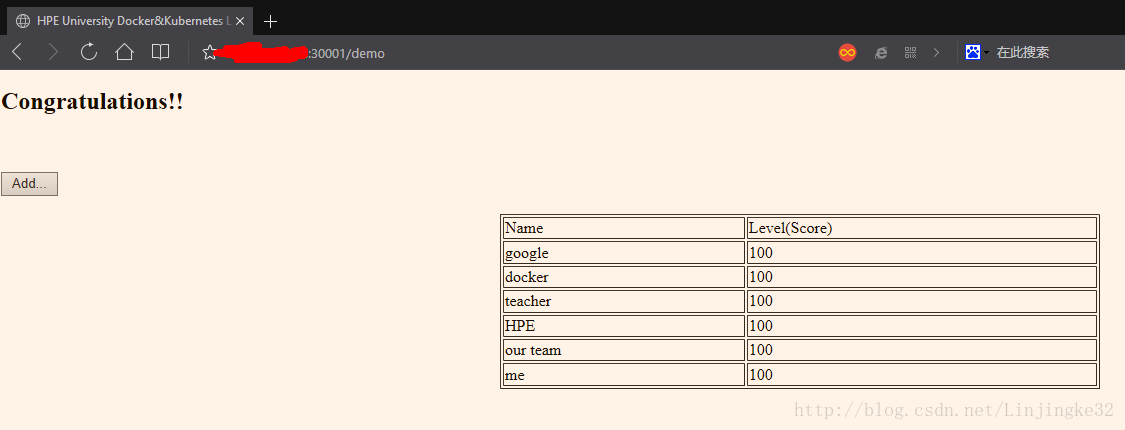
7、通过这个流程,可以发现,基于Kubernetes搭建容器集群很方便,准备好镜像,然后通过配置文件描述好其关系就行了。