1.ground truth分配中存在的一些问题
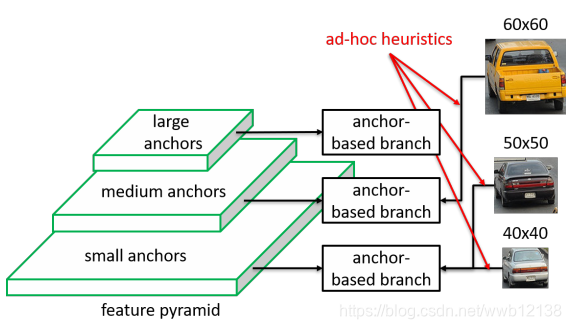
在介绍FSAF前先说一下在带有FPN的检测器中是如何分配ground truth的,如下图Fig1所示,一个大小为50×50像素的汽车实例可能和小的anchor有好的重合所以将其分配给了small anchors这层,同理这个40×40像素的汽车也分配到了这层,但是,另一个60×60像素的汽车与其他两个有着相似的特征但是却分配到了medium anchors层。这就说明anchor匹配机制其本质上就是一种人为的启发式特征选择。这导致一个主要缺陷,即用于训练每个实例的所选特征层可能不是最佳的。
2.FSAF模块
2.1 相关工作
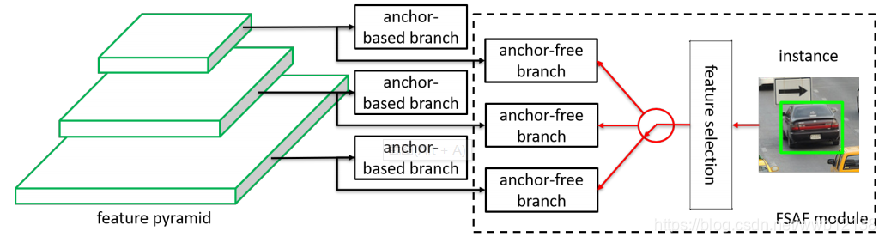
为了解决上述问题,作者提出了一种简单有效的FSAF模块,如下图Fig2所示,这样做的目的就是让每个实例可以自己去选择最好的特征层来优化网络,采用这样的方法就不再需要anchor来进行约束,而是采用anchor free的方式来对实例进行编码。每个层的特征金字塔都构建一个anchor free的分支,其独立于anchor based的分支。
2.2 网络结构
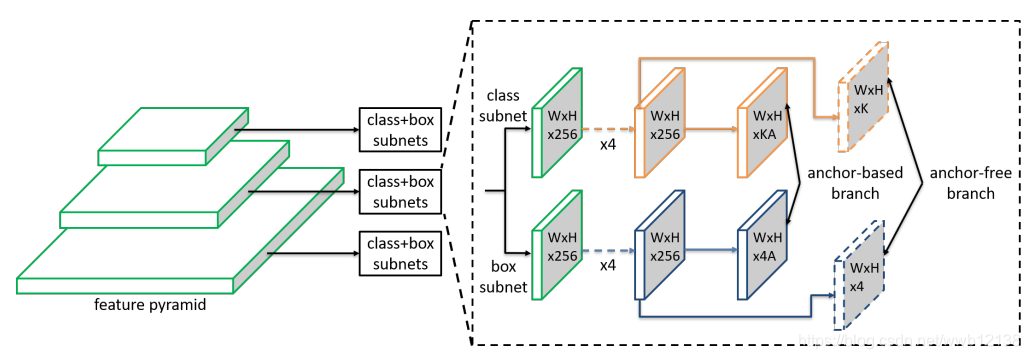
下图Fig3中虚线部分为FSAF模块,其中每一个特征层,都会被用来检测不同尺度的物体,每个特征层都包含两个并行的子网络。其中W×H×K(K为分类数)的特征图用来进行分类(这里使用的是signoid函数),W×H×4的特征图用来进行回归(这里使用relu函数)。
2.3 具体细节
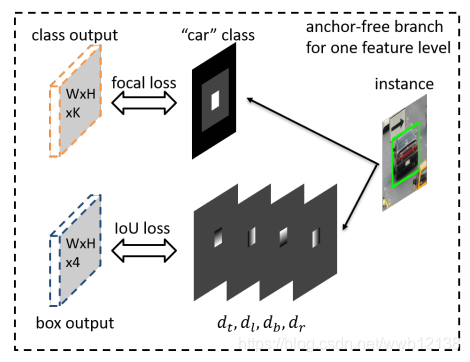
下图Fig4为FSAF模块中的classification和regression两个分支,对于一个实例其bounding box为b=[x, y, w, h],将其映射到特征层上的坐标为
,文中定义了一个有效区域
=
文中设置
=0.2,和忽略区域
=
,文中设置
=0.5。
=
,
=
,
=
,
=
,
=
,
=
,
=
,
=
。图中的白色区域为有效区域在训练中为正例区域内会填充1,灰色区域为忽略区域在训练中不参与梯度回传,黑色区域为负例在训练中区域内会填充0。文中选用focal_loss作为分类分支的损失函数。对于回归分支,回归输出的是与类别无关的4个偏移量映射。对于有效区域中的任一像素点(x,y),生成一个四维向量,分别代表到有效区域上,左,下,右,边的距离。该分支采用IOULoss。
2.4 特征层的选择
FSAF模块的设计就是为了达到自动选择最佳Feature ap的目的,最佳Feature是由各个feature level共同决定。如下图Fig5所示,哪一个 anchor-free branch 输出的 loss 最小,就把 ground-truth 分配去哪一个层。

其中分类损失于回归损失如下面的公式1所示(损失函数是在有效区域计算的):

2.5 联合训练
文中还提出了一种联合训练的方式,将anchor based分支与anchor free分支进行一个加权训练。如下面的公式2所示:
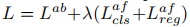
3实验
1)根据下图Fig6可以看出有两种选择特征层的方法,一个是本文提出的Online feature selection,一种是Heuristic feature selection:=
+
,发现在使用anchor based分支与Online feature selection效果达到最好。

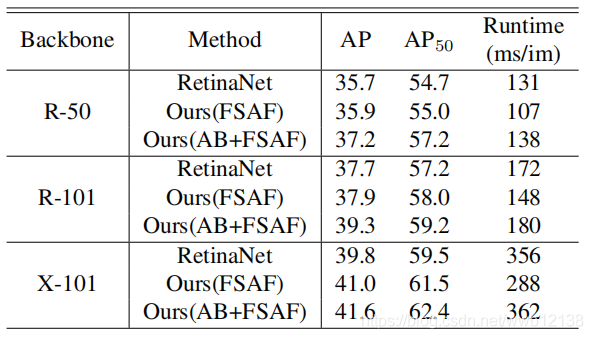
2)根据下图Fig7发现在不同的backbone中单独使用FSAF模块虽然在AP上提升很小但是却在速度上有很大的提升。
3)下图Fig8为FSAF在coco数据集上与其他模型的对比。
