文章目录
- 1.存储引擎产品性能对比
- 2.es安装
- 3.es核心概念
- 4.IK分词器
- 5.Rest风格说明
- 6.索引(表)基本操作
- 7.文档(数据行)基本操作
- 8.springboot集成es
-
- 1.添加pom依赖
- 2.找对应的Java对象
- 3.分析RestHighLevelClient对象的方法
- 4.es java API操作
-
- 1.创建空项目
- 2.添加springboot innilizer
- 3.添加默认Developere Tools
- 4.添加spring data es
- 5.配置javac的环境1.8,javascript环境es6
- 6.更改springboot版本
- 7.查看es依赖版本是否与es服务端7.9.3一致
- 8.自定义es依赖版本
- 9.再次查看es版本是否已经依赖成功
- 10.简单分析es客户端源码
- 11.配置RestHighLevelClient对象
- 12.java代码es创建数据
- 13.查看es是否插入成功:成功
- 14.获取索引
- 15.删除索引
- 16.创建文档
- 17.crud文档
- 18.批量操作
- 19.搜索
- 9. 实战京东搜索模拟
文章整理自:狂神说-es
1.存储引擎产品性能对比
1.Lucence
是一套信息检索工具包,jar包!不包含搜索引擎系统
包含:索引结构、读写索引的工具、排序、搜索规则等工具类
2.Lucence与ElasticSearch关系
ElasticSearch是基于Lucence做了一些封装和增加(上手简单)
3.ElasticSearch与solr的区别
性能对比:以下5图进行了对比
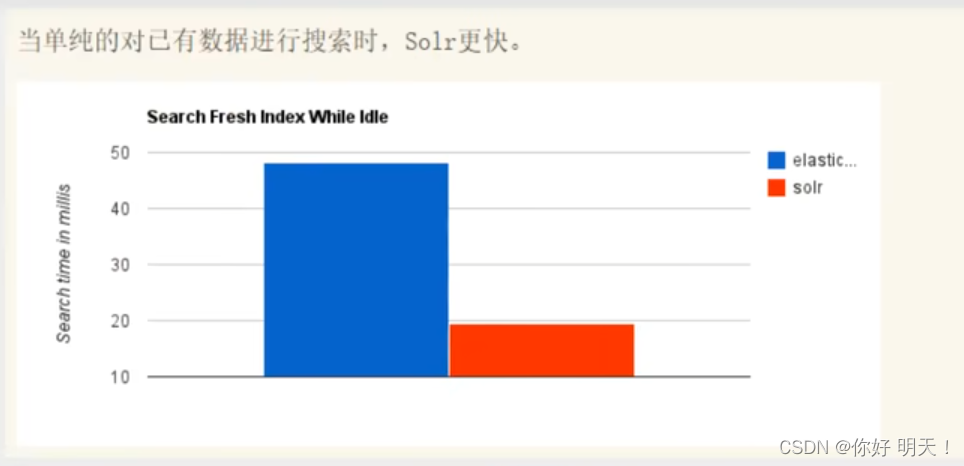
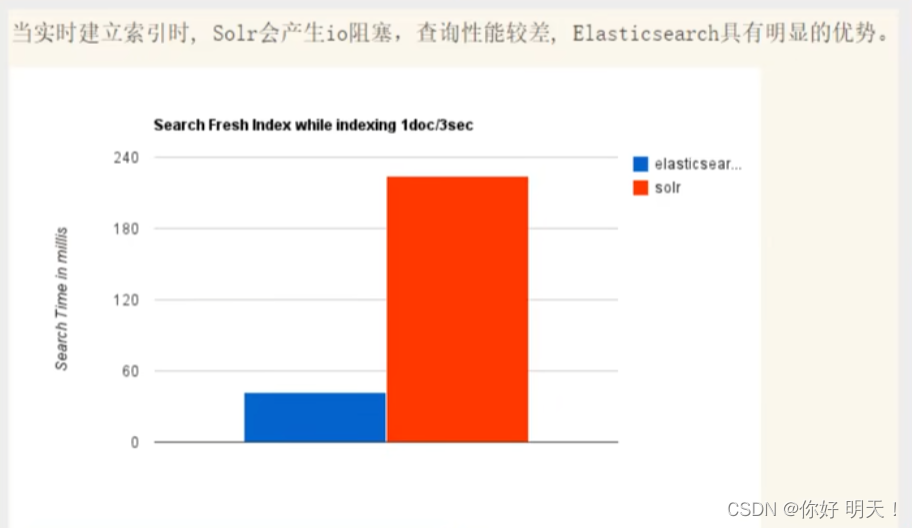

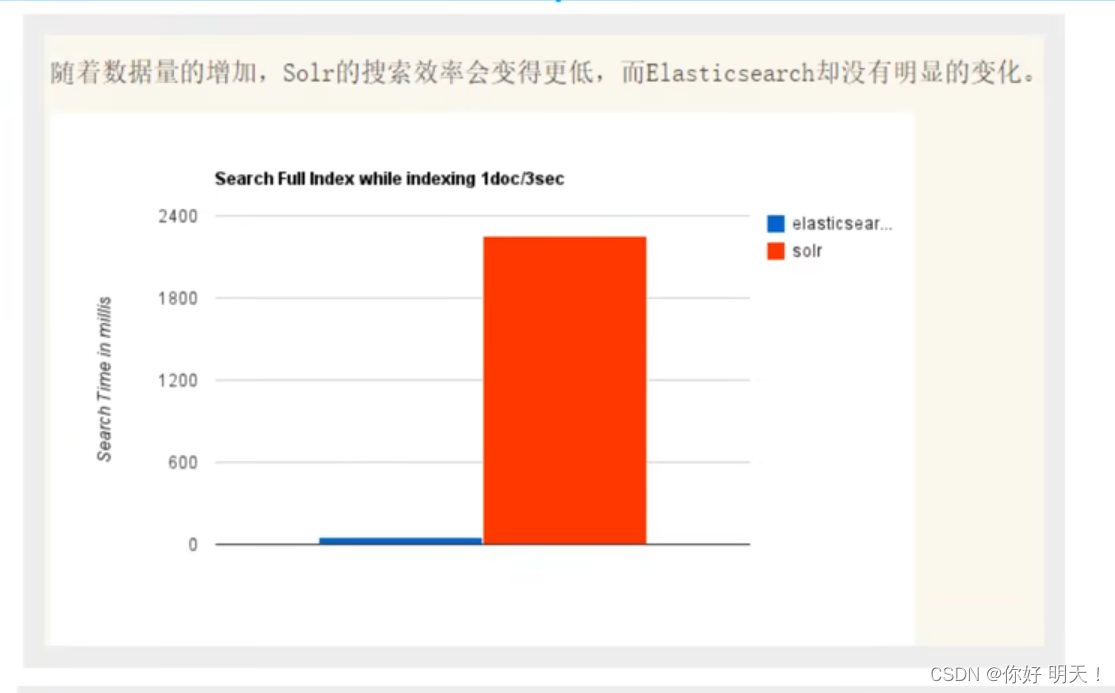
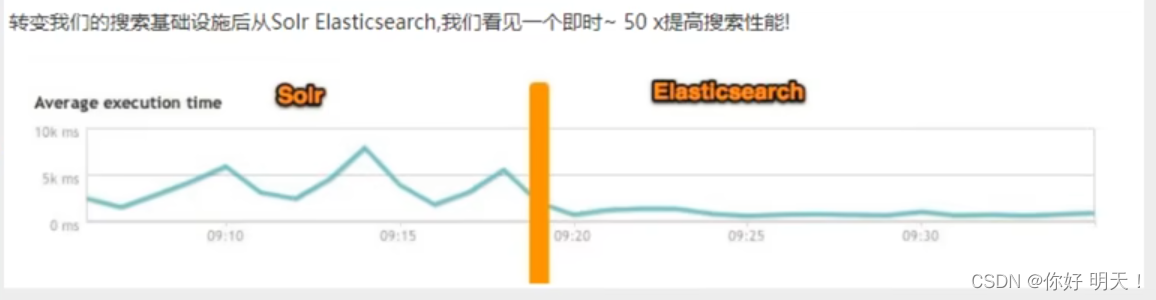
ElasticSearch VS solr 总结
1.es基本是开箱即用(解压就可以使用),非常简单。solr安装略微复杂
2.solr利用zookeeper进行分布式管理,而es自身带有分布式协调管理功能
3.solr支持更多数据格式,如JSON、XML、CSV,而es仅支持json文件格式(少而精)。
4.solr官方提供的功能更多,而es本身更注重于核心功能,高级功能多有第三方插件提供(如ik分词器,图形化界面需要kinaba支持)
5.solr查询快,但更新索引时慢(即插入/删除慢),用于电商等查询多的应用;
- es建立索引快(即查询慢),即时查询快,用于facebook、新浪等搜索
- solr是传统搜索应用的解决方案,但es更适用于新兴的实时搜索应用
6.solr比较成熟,有个更大,更成熟的用户、开发和贡献社区,而es相对开发维护者少,更新太快,学习使用成本较高
2.es安装
环境要求:jdk 1.8及以上、es客户端、界面工具
java开发,es的版本和jdk版本要对应
es与kinaba下载版本要一致
1.创建目录
# 创建目录
#es
mkdir -p /opt/apps/es/elasticsearch/{
config,data,plugins}
# kibana
mkdir -p /opt/apps/es/kibana/config
2.创建挂载的配置文件
es配置文件:
vi /opt/apps/es/elasticsearch/config/elasticsearch.yml
http.port: 9200
http.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"
kibana配置文件
vi/opt/apps/es/kibana/config/kibana.yml
server.name: kibana
# kibana的主机地址 0.0.0.0可表示监听所有IP
server.host: "0.0.0.0"
# kibana访问es的URL
elasticsearch.hosts: [ "http://localhost:9200" ]
#elasticsearch.username: 'kibana'
#elasticsearch.password: '123456'
# 显示登陆页面
#xpack.monitoring.ui.container.elasticsearch.enabled: true
# 语言
i18n.locale: "zh-CN"
3.编写docker-compose
vi /opt/apps/es/docker-compose.yml
version: '3'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.9.3
container_name: elasticsearch
environment:
- "discovery.type=single-node"
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- ./elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- ./elasticsearch/data:/usr/share/elasticsearch/data
- ./elasticsearch/plugins:/usr/share/elasticsearch/plugins
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 9200:9200
- 9300:9300
restart: always
network_mode: 'host'
kibana:
image: docker.elastic.co/kibana/kibana:7.9.3
volumes:
- ./kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml
environment:
- ELASTICSEARCH_URL=http://localhost:9200
ports:
- 5601:5601
restart: always
network_mode: 'host'
es-head:
image: tobias74/elasticsearch-head:6
container_name: es-head
restart: always
ports:
- "9100:9100"
4.添加文件夹权限
chmod -R 777 /opt/apps/es/elasticsearch/data
5.启动es与kibana
cd /opt/apps/es
docker-compose up -d
6.开放端口
firewall-cmd --add-port=9200/tcp --permanent
firewall-cmd --add-port=5601/tcp --permanent
firewall-cmd --reload
7.测试访问
es访问地址:
http://ip:9200/
http://192.168.229.132:9200/
kibana访问地址:
http://ip:5601/
http://192.168.229.132:5601/
es-head访问地址:
http://192.168.229.132:9100/
8.安装IK分词器
# 进到es plugins的目录
cd /opt/apps/es/elasticsearch/plugins/
# 创建ik 目录
mkdir ik
# 进到ik
cd /opt/apps/es/elasticsearch/plugins/ik
# 下载方式1:分词器,很慢;
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip
#下载方式2:可以windows直接下载zip包后上传到linux。
# 在谷歌浏览器输入
#https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip
# 解压分词器
unzip elasticsearch-analysis-ik-7.9.3.zip
#重启es
docker restart 容器id
3.es核心概念
集群、节点、索引、类型、文档、分片、映射是什么
es是面向文档,关系型数据库和es概念对比
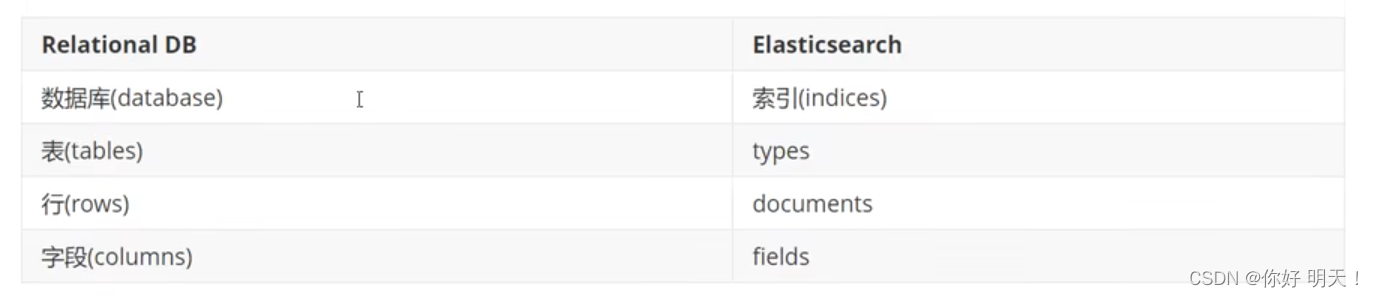
es集群中可包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)
**物理设计 **:
es在后台把每个索引划分成多个分片,每份分片可以在集群中不同的服务器进行迁移
** 逻辑设计**:
1.文档:就是一条数据
es是面向文档的,意味着索引和搜索数据的最小单位是文档,es中文档有几个重要属性
- 自我包含,一篇文档同时好汉字段和对应的值,也就是同时包含key:value
- 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的(就是json对象,通过fastjson自动转换)
- 灵活的结构,文档不依赖预先定义的模式,在关系型数据库中,要提前定义字段才能使用,在es中对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态添加一个新的字段
尽管可以随意的新增或忽略某个子弹,但是每个字段的类型非常重要,比如年龄字段类型,可以是字符或整形。
因为es会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在es中,类型有时候也称为映射类型
2.类型:表字段和类型
3.索引:就是数据库
物理设计:
一个集群至少一个节点,而一个节点就是一个es进程,默认的节点可以有多个索引,如果创建索引,索引将会由5个分片构成(主分片),每个主分片会有一个副本(复制分片)
如下创建了1个索引:P,副本R,分片结果如下:
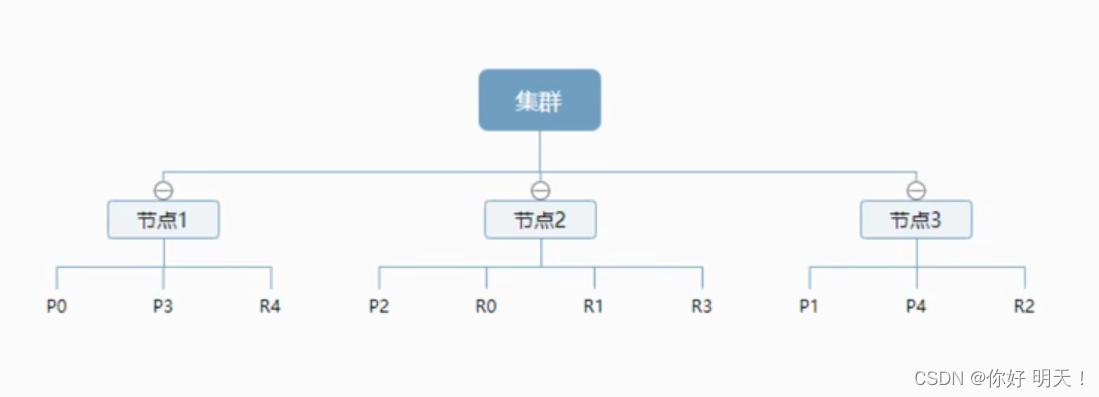
上图是一个有3个节点的es集群,可以看到主分片和对应的复制分片都不会再同一个节点内,这样就利于某个节点挂了,数据也不至于丢失。实际上,一个分片就是一个lucence索引,一个包含倒排索引的文件目录,倒排索引的结构使得es在不扫描全部文档的情况下,就能知道哪些文档包含特定的关键字。
倒排索引,优化效率
es使用的一种称为倒排索引的结构,采用lucence倒排索引作为底层。这种结构试用与快速的全文搜索,一个索引由文档中所有不重复的列构成,对于每一个词,都有一个包含他的文档列表。例如现有两个文档,内容如下
sduty every day , good good up to forever # 文档1包含的内容
To forever ,study every day ,good good up # 文档2包含的内容
为了创建倒排索引,我们首先要将每个文档拆分成独立的词语(或称为词条或tokens),然后创建一个包含所有不重复的词条的排列,单号列出每个词条再哪个文档:
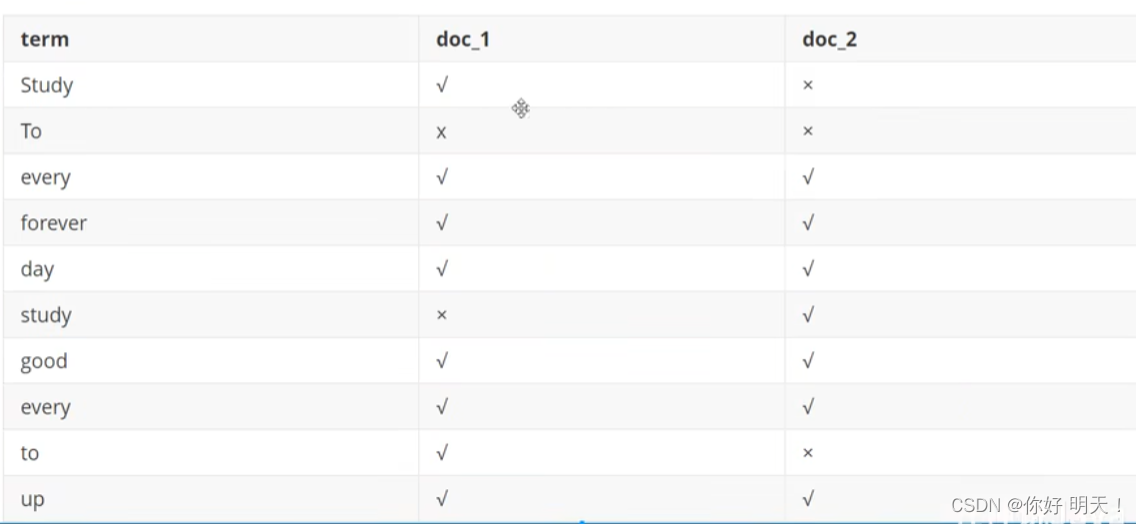
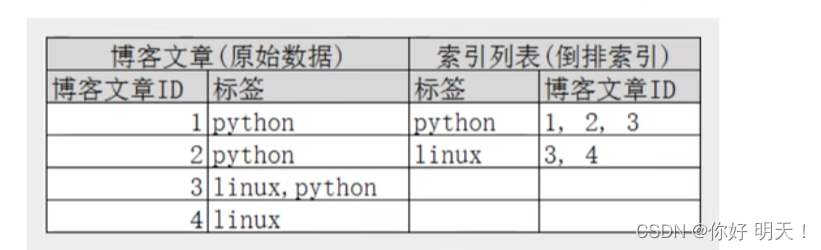
现在试图搜索to forever,需要查看包含每个词条的文档,如下:

具体例子:
如现在要搜索linux,那么就根本不会去查询id为1和2的文档,效率非常高
4.IK分词器
1.概念
分词:即把一段中文或别的划分成一个个关键字,在搜索时候会把自己的信息进行分词,会把数据库中或索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是每个字分为一个词;
比如“小鸡爱吃大米”会分成“小、鸡、爱、吃、大、米”,这显然无法达到分词要求,所以需要安装中文分词起ik分词器来解决
IK提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度切分
2.安装
1.ik分词器下载
2.下载后放到es插件包即可
3.解压就可以使用
4.重启es相关服务
3.测试
kibana上进行操作,测试ik分词器
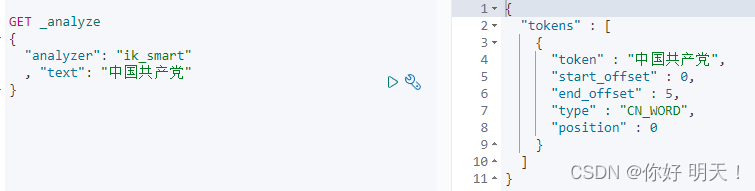
3.1 ik_smart:最少切分
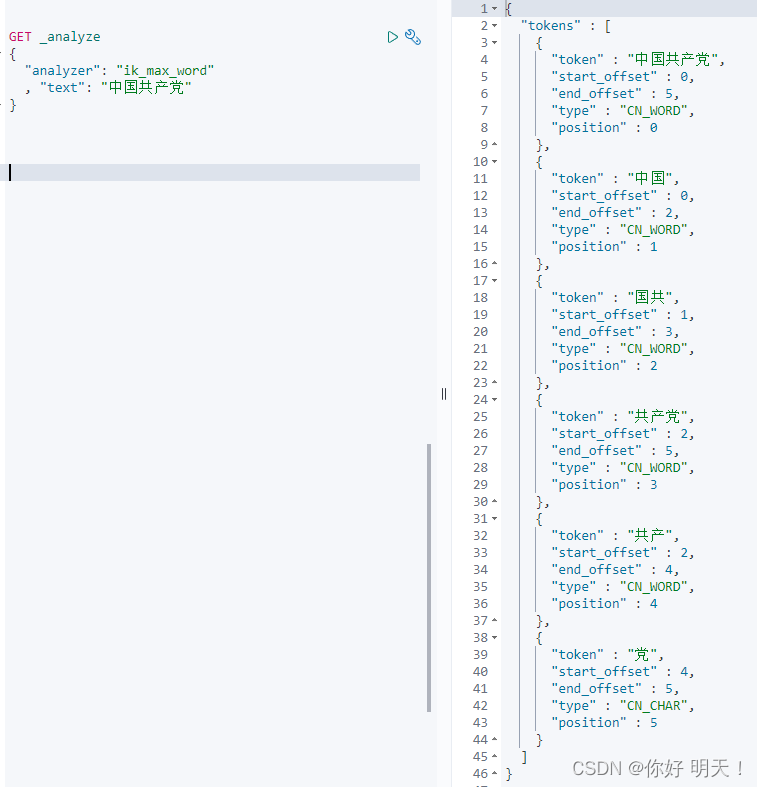
3.1 ik_max_word:最细粒度切分
3.3 ik分词器增加自定义 名词
现象:如“别搞了”,希望分词时出现“别搞了”
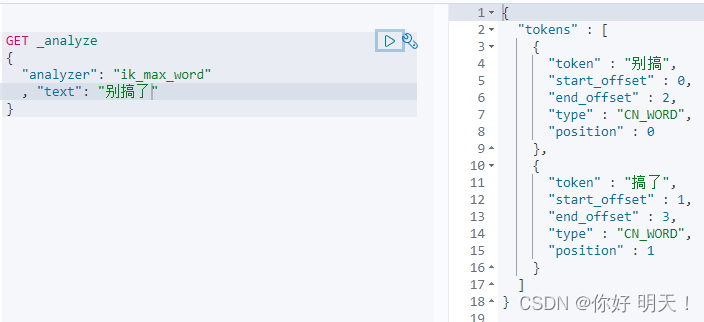
处理方式:
3.3.1 在ik目录下增加自己词典
当前目录ik分词器配置目录如下:
/opt/apps/es/elasticsearch/plugins/ik/config
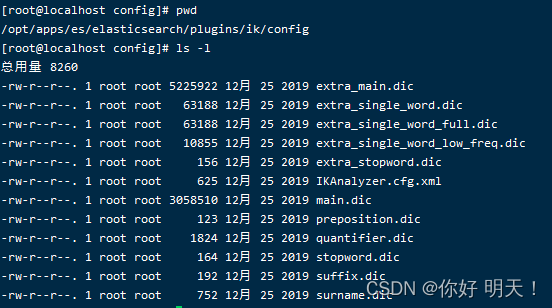
增加词典:bie.dic
3.3.1 在词典中增加 名词
vi bie.dic
别搞了
#保存
3.3.2 将词典配置到ik配置中
配置文件名:IKAnalyzer.cfg.xml

3.3.4 重启es,重新加载ik
3.3. 再次测试“别搞了”

5.Rest风格说明
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束原则。它主要用于客户端和服务器交互类的软件。基于这个风格设计软件可以更加简洁,更有层次,更易于实现缓存等机制。
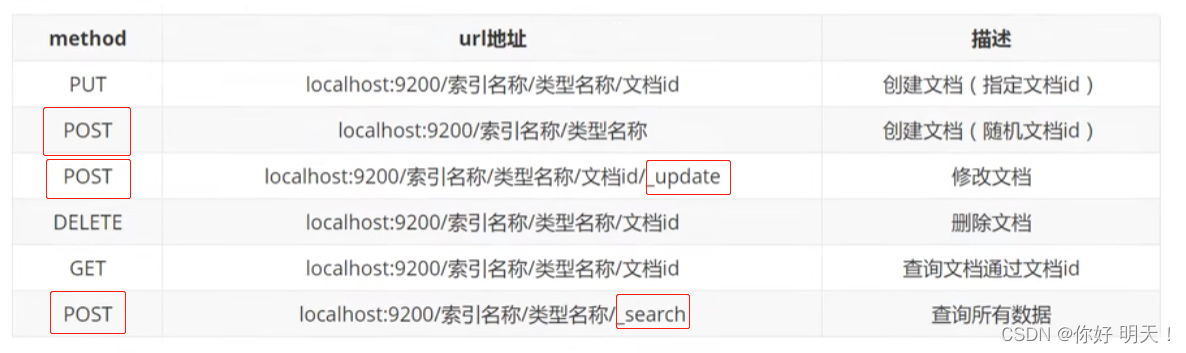
6.索引(表)基本操作
6.1 创建
put创建索引
PUT /索引名/类型名/文档id #未来类型名会被去掉
{请求提}
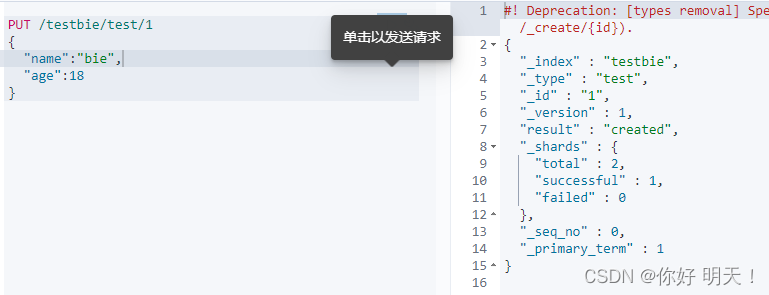
kibana索引管理:http://192.168.229.132:5601/app/management/data/index_management/indices
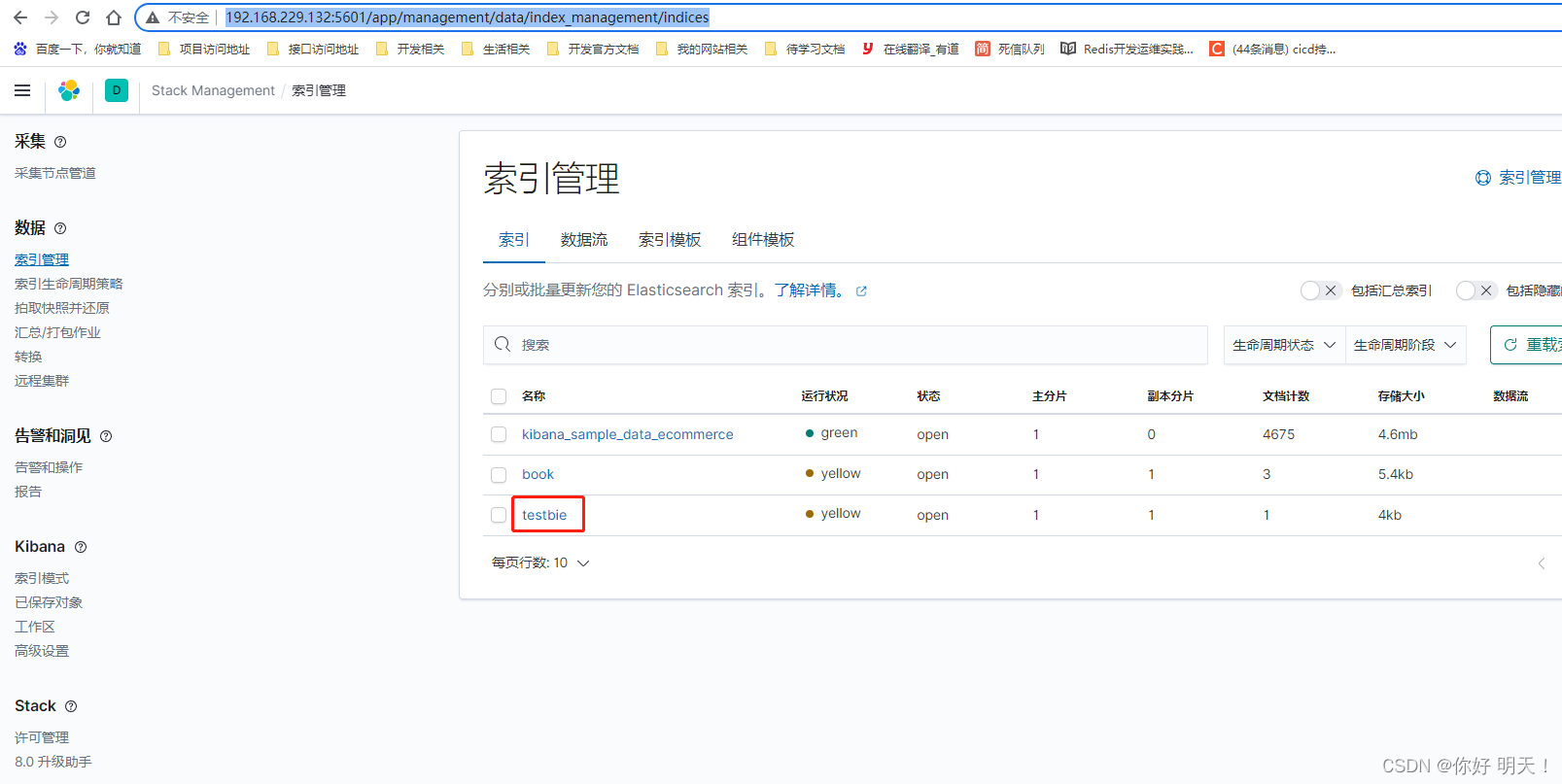
es-head查看索引
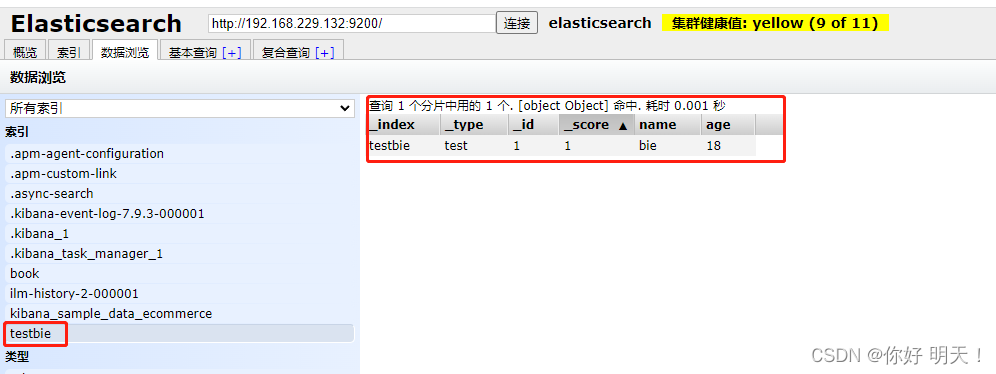
6.2 修改
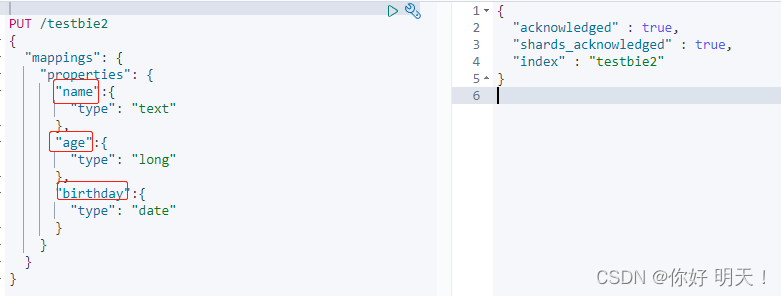
设定数据类型
为testbie2索引的字段指定数据类型
获取规则
GET testbie2
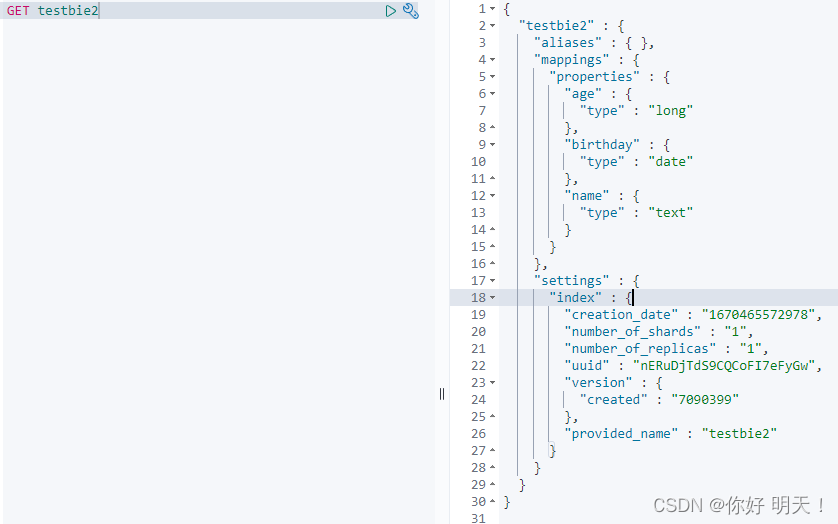
GET命令查看es索引情况

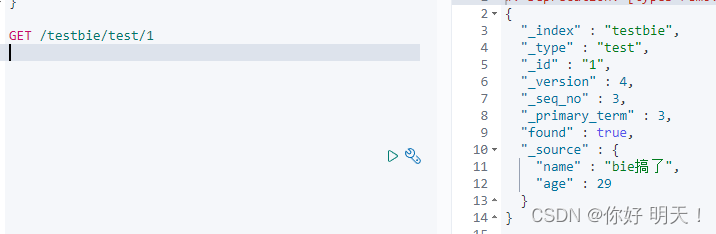
PUT修改,body里面的类容就是最终值(更新所有)
修改之前testbie/test/1的值,version代表修改版本变化次数

GET验证修改是否成功:
post更新/新增
_update后缀,只更新出现的属性
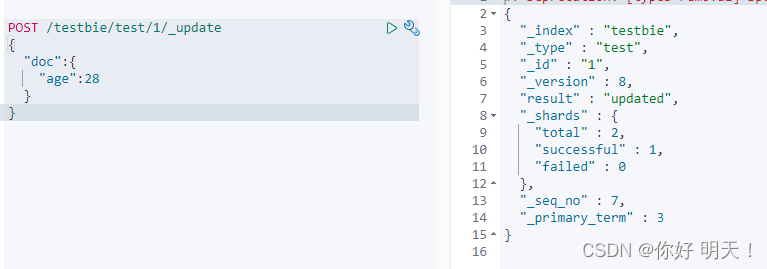
没有_update后缀,依然是更新所有的属性
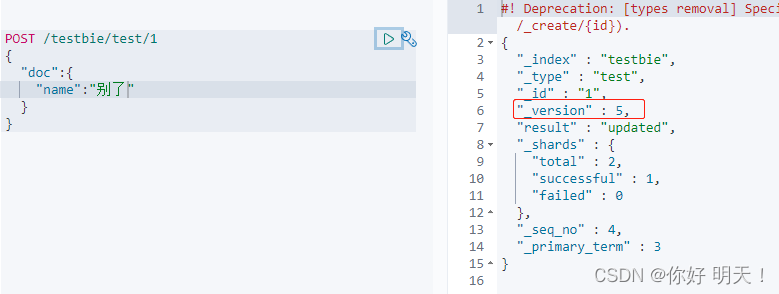
6.3 删除
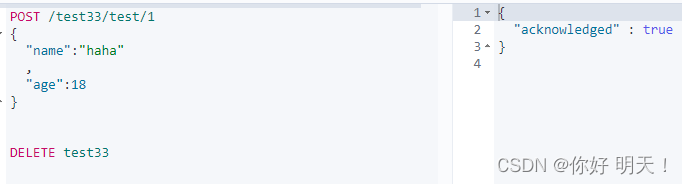
DELETE删除
删除索引,后缀精确到索引;删除文档行,后缀精确到文档行
7.文档(数据行)基本操作
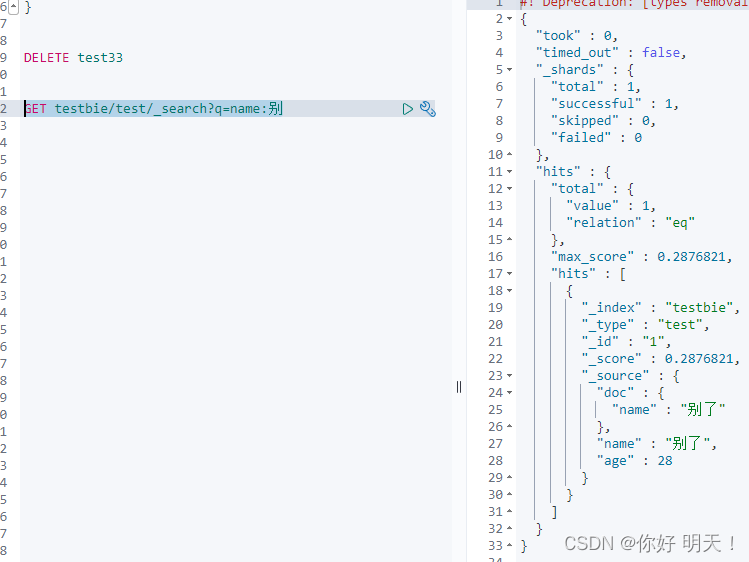
7.1 简单查询
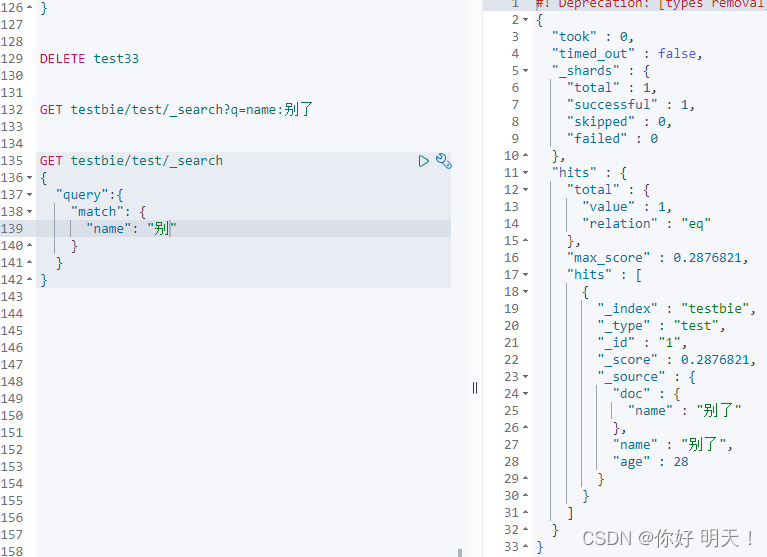
GET
GET testbie/test/_search?q=name:别
7.2 复杂查询
select (排序、分页、高亮、模糊查询、精准查询)
查询匹的配度:_score(权重)
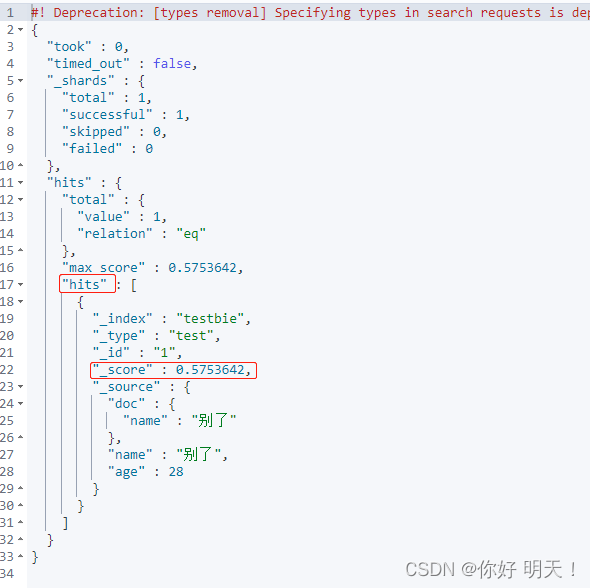
GET复杂查询语法
GET /索引/类型/_search
{
#具体查询条件
}
如下图:
其中hits对应java中的Hits对象,包含以下内容
hit:
1.索引和文档信息
2.查询的结果总数
3.查询出来的具体文档信息
4.查询的数据都可以遍历出来
5.分数越大匹配度越大
返回指定的文档属性
_source与query平级
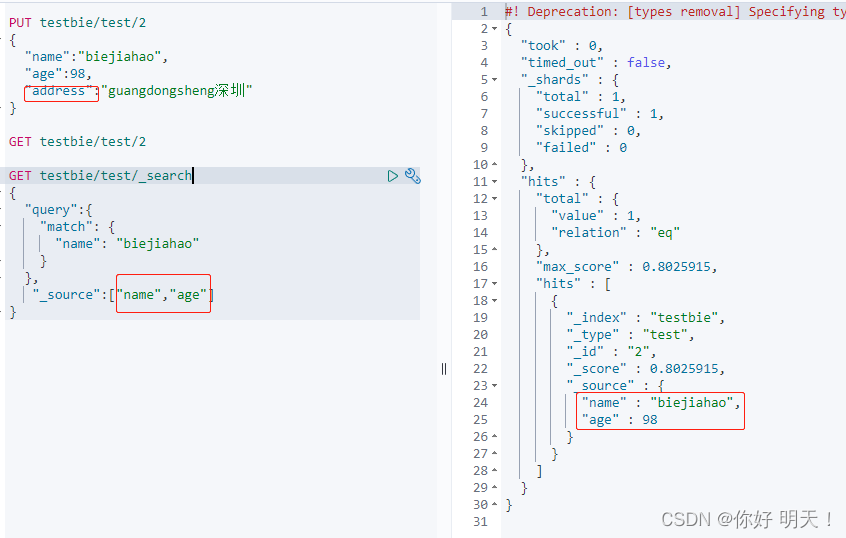
排序
sort,与query平级
sort排升序:
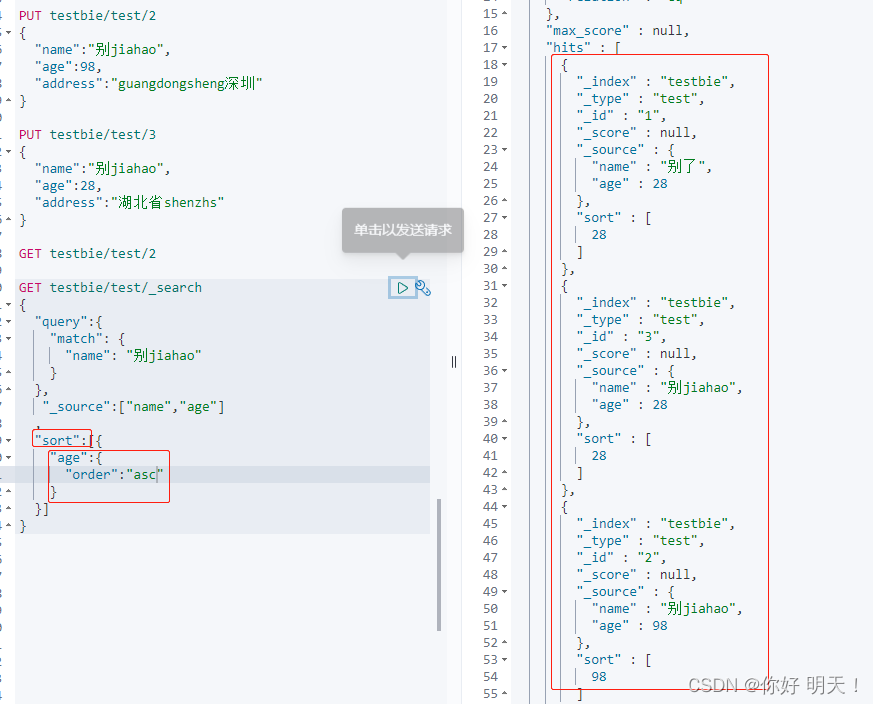
分页
一定要有这两个参数,相当于mysql的limit两个参数
from:0 #从哪里开始
sizi: 10 #取多少条值
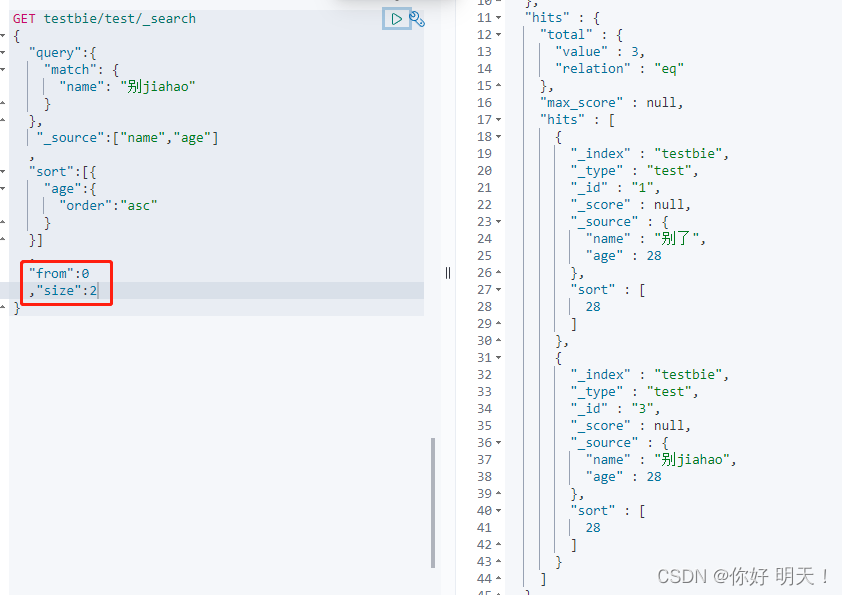
布尔值查询
多条件bool值查询,
must匹配相当于mysql的and操作,所有条件都要符合
must_not 匹配相当于mysql的 != 操作
should 匹配相当于mysql的or操作
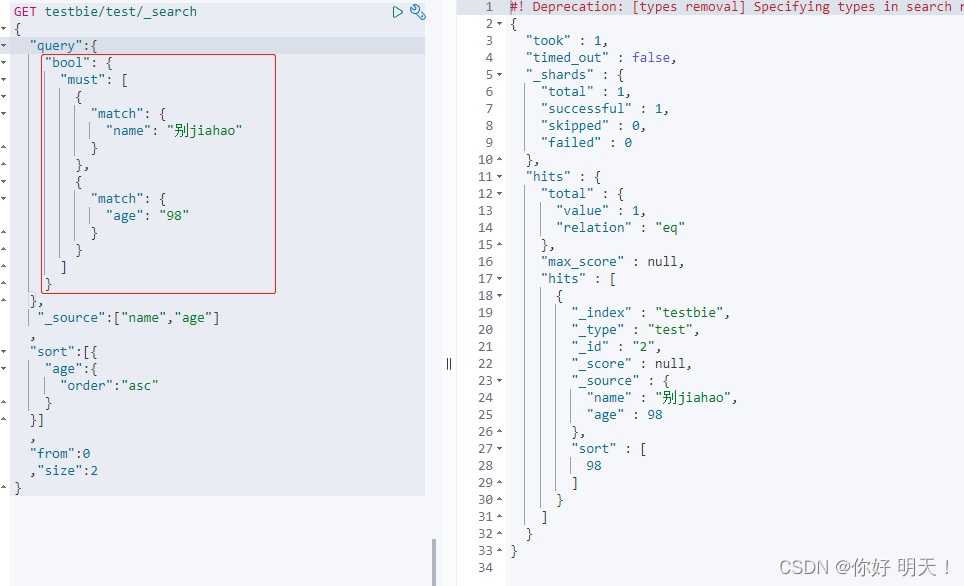
过滤
filter与must平级
gt大于,lt小于,gte大于等于,lte小于等于
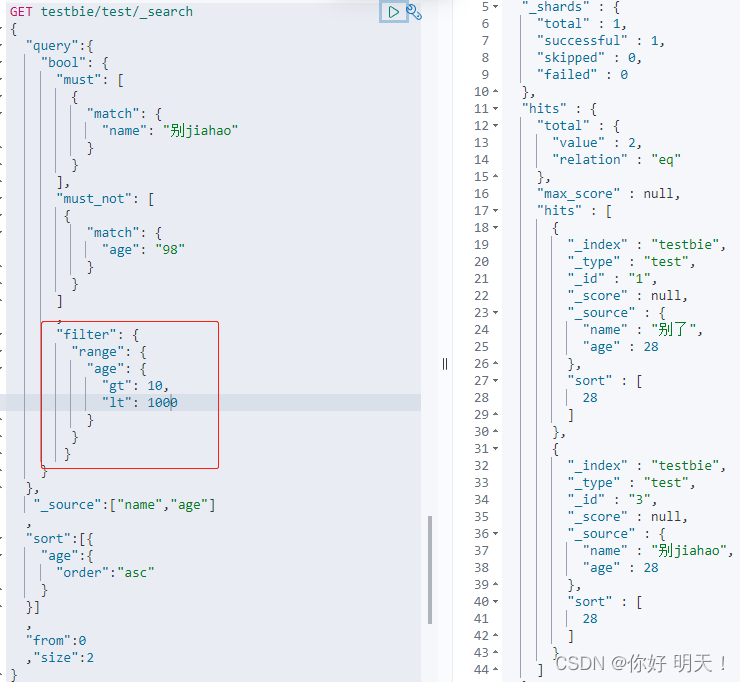
多条件查询
match自带模糊查询,多个条件用空格隔开
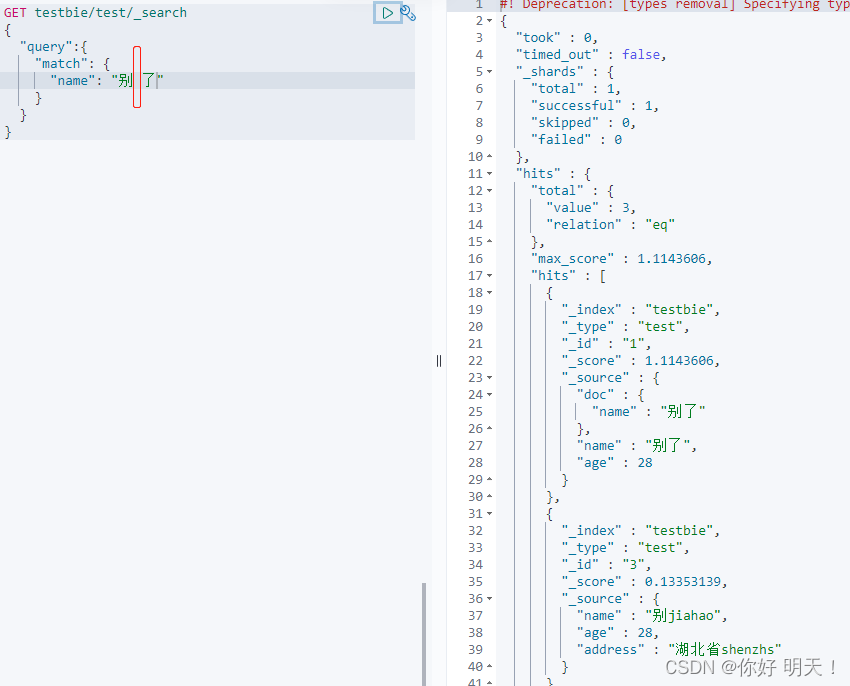
精确查询
term:精确查询
match:模糊查询
term与match平级
两个类型,在设定字段类型时要注意
text:会被分词器解析成多个词
keyworkd:不会被分词器解析
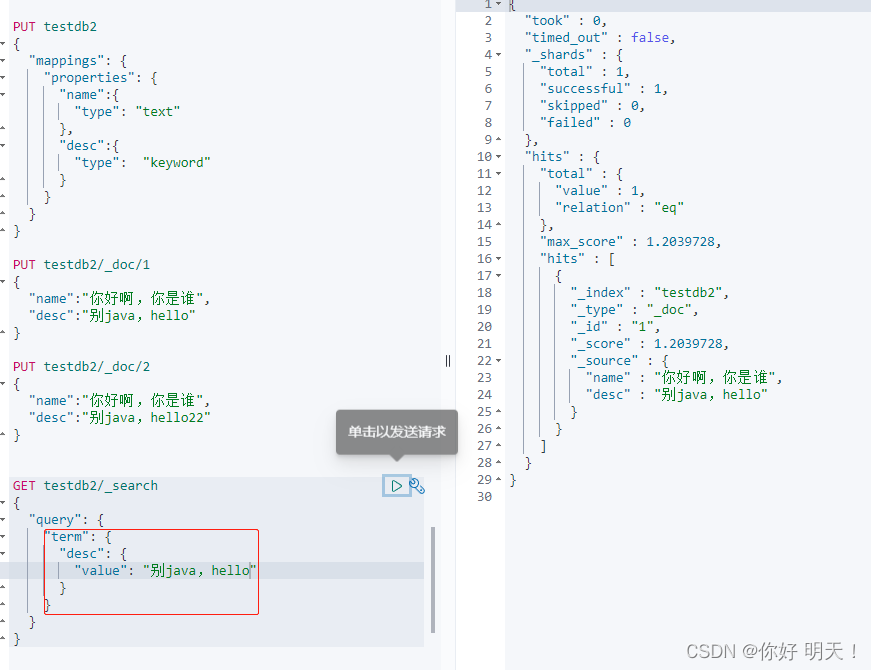
多条件精确查询
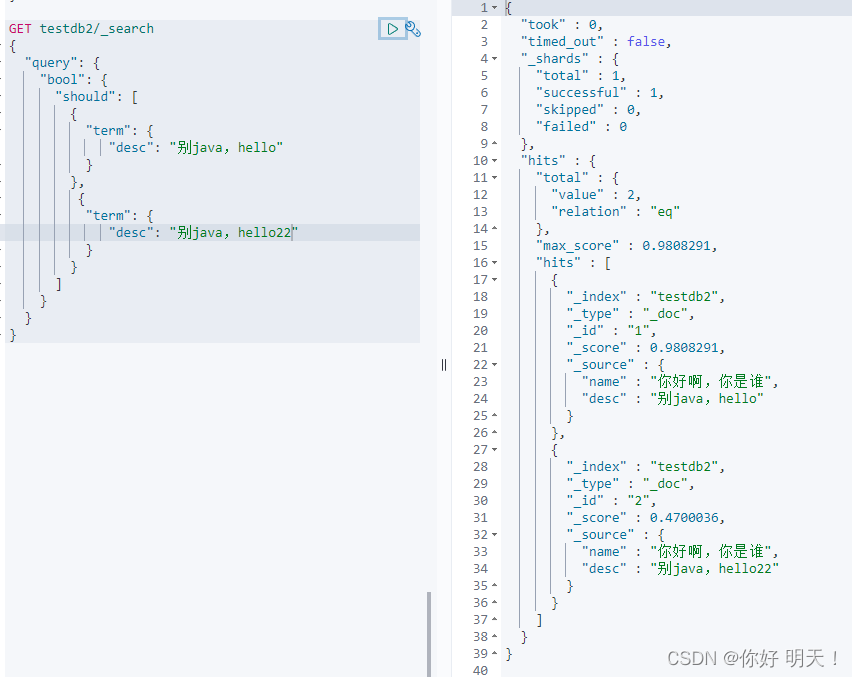
高亮查询
highlight与query平级,高亮的字段都会用"em"标签包裹返回
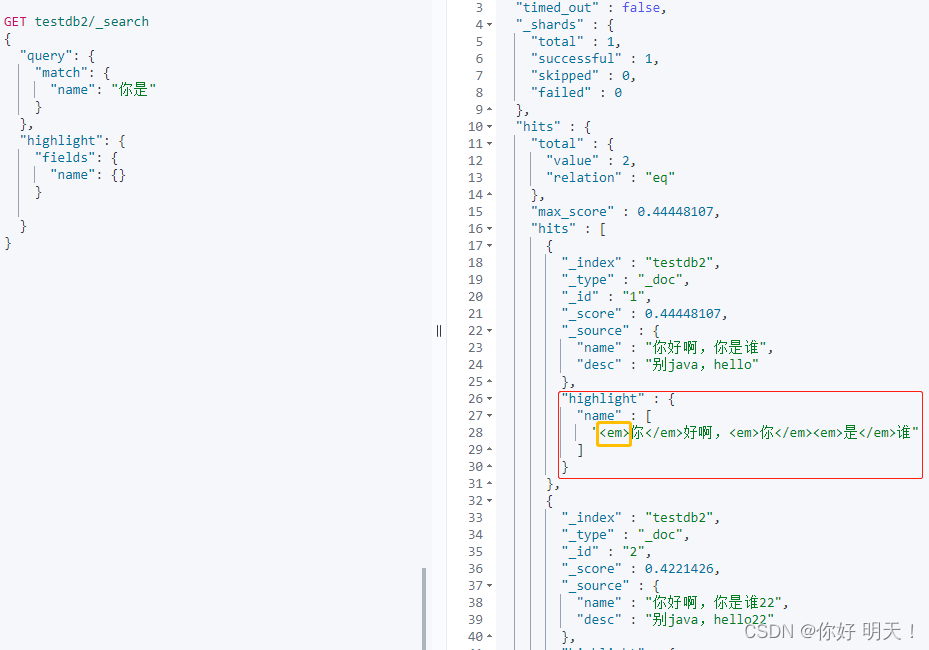
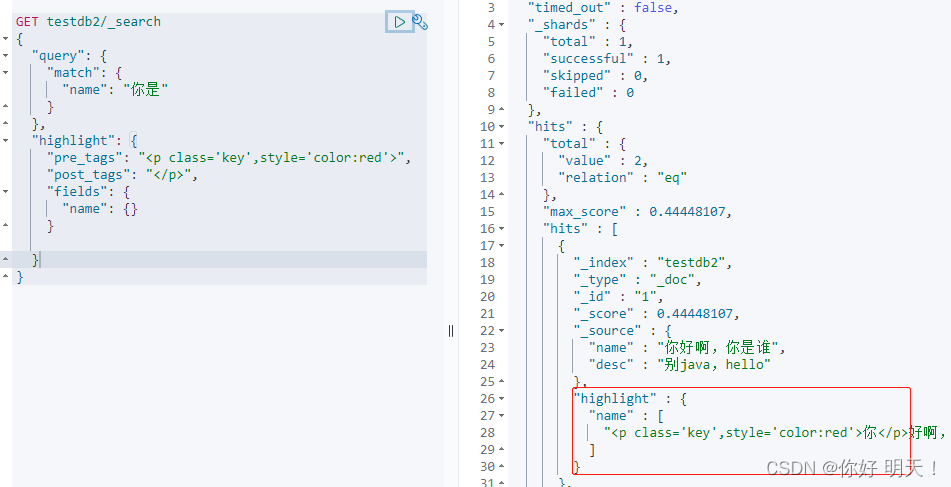
自定义高亮标签:
8.springboot集成es
es官网 https://www.elastic.co/guide/index.html#viewall
es客户端:
使用java rest客户端
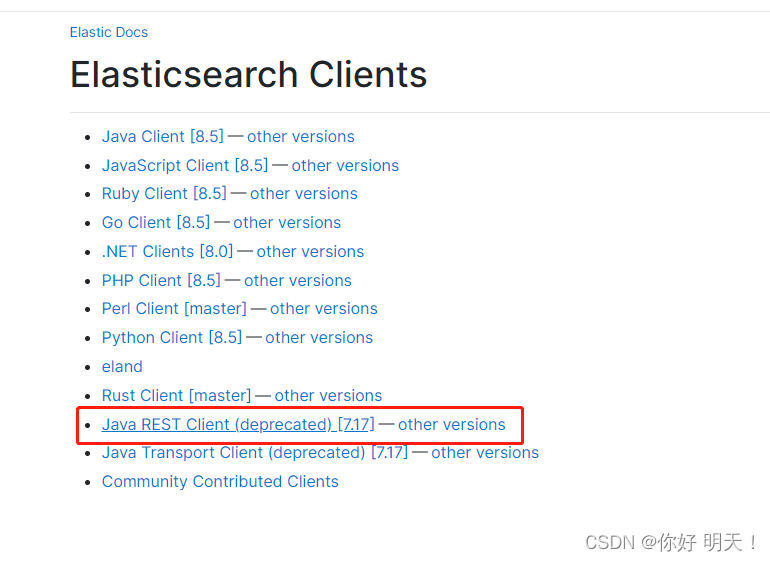
es使用java rest客户端对应官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/index.html
1.添加pom依赖
依赖版本需要和es服务端版本一致
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.9.3</version>
</dependency>
2.找对应的Java对象
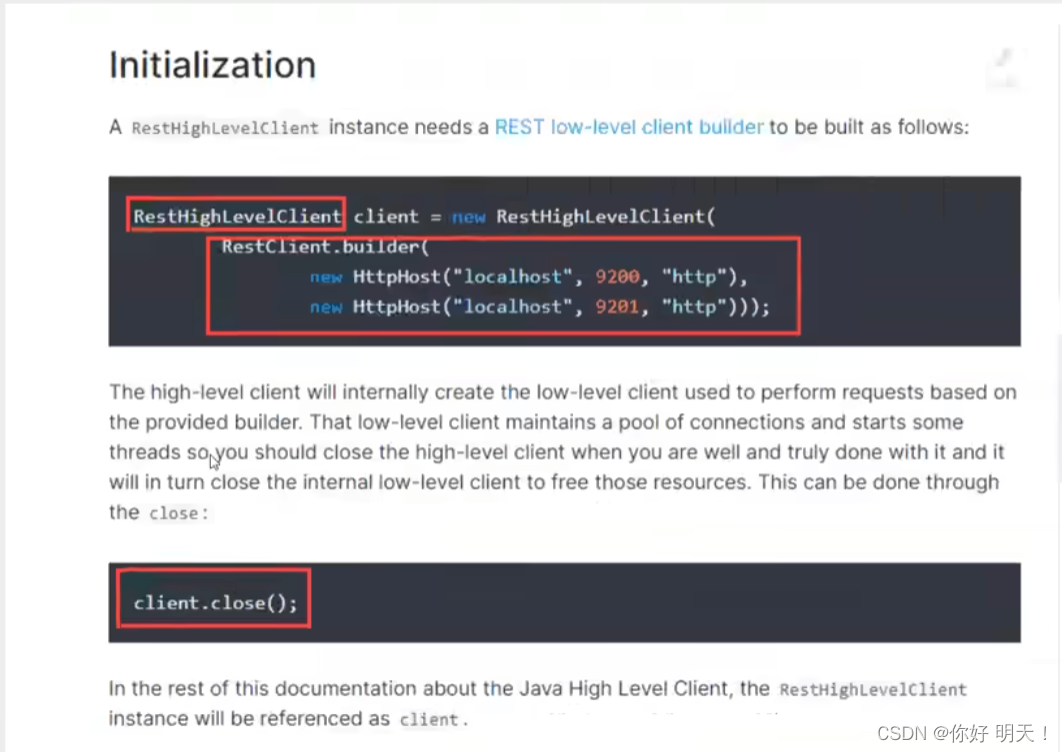
3.分析RestHighLevelClient对象的方法
略
4.es java API操作
1.创建空项目
2.添加springboot innilizer
3.添加默认Developere Tools
4.添加spring data es
5.配置javac的环境1.8,javascript环境es6
6.更改springboot版本
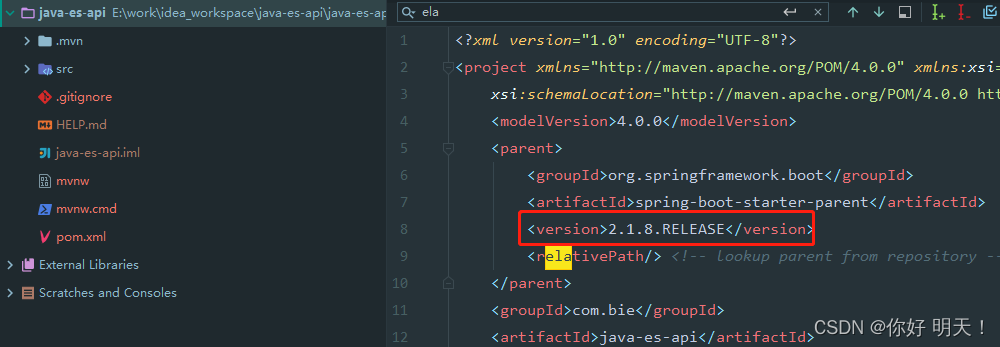
7.查看es依赖版本是否与es服务端7.9.3一致
版本不匹配
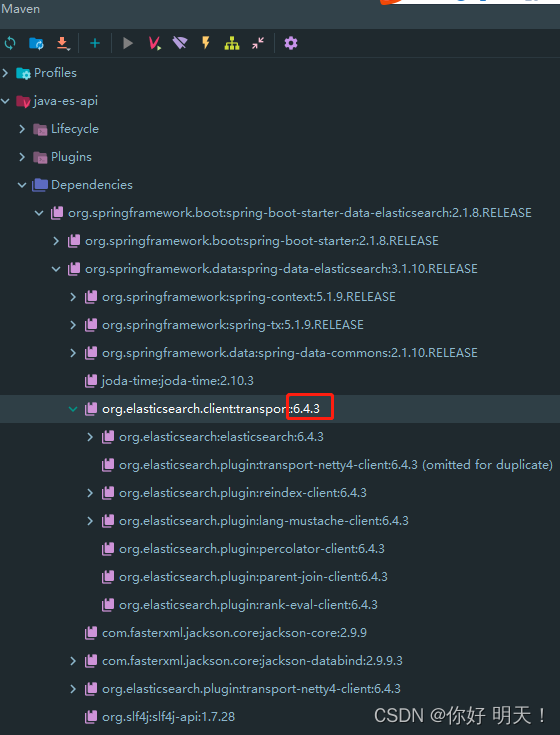
8.自定义es依赖版本
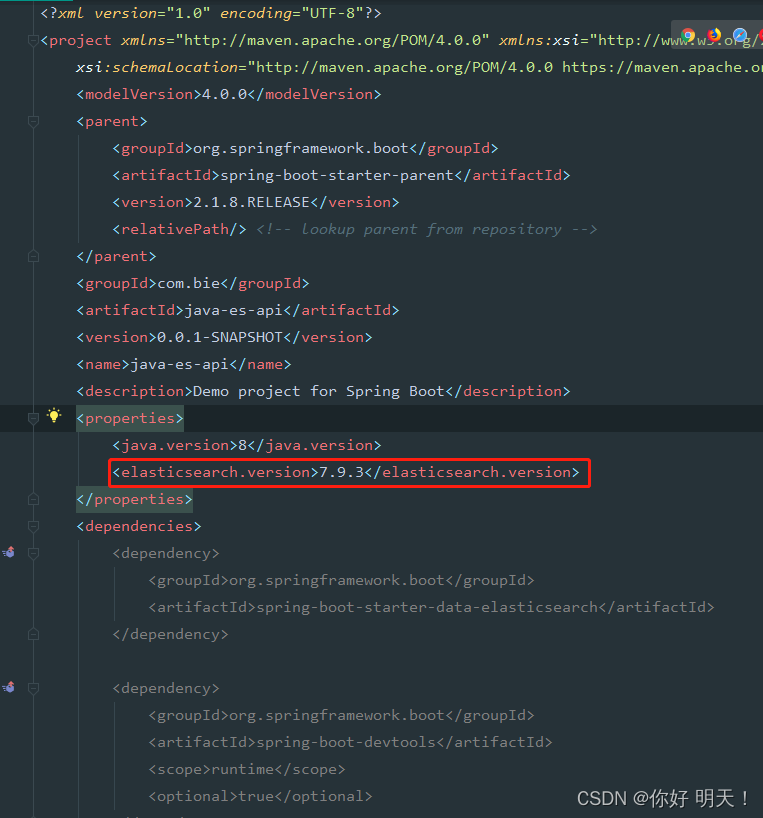
9.再次查看es版本是否已经依赖成功
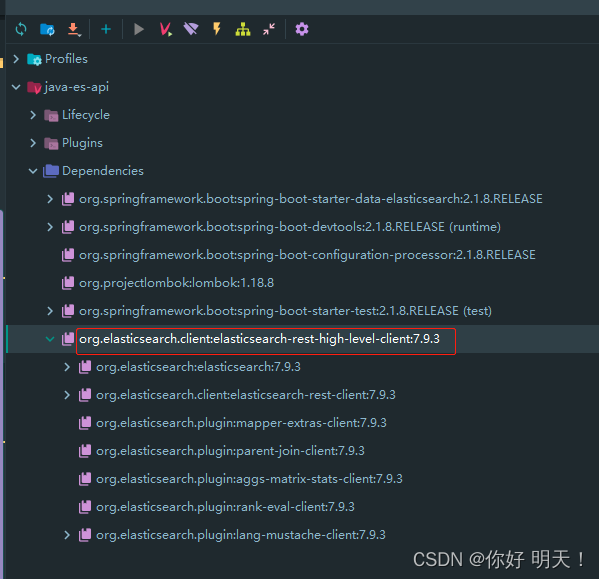
10.简单分析es客户端源码
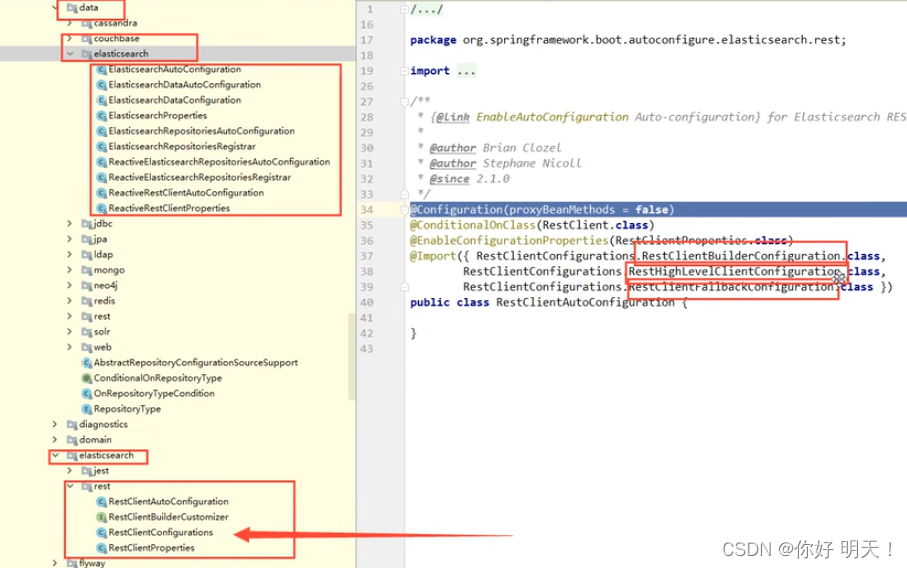
核心类:RestClietConfigartions
11.配置RestHighLevelClient对象
package com.bie.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author bjh
* @date 2022/12/9
*/
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.229.132", 9200, "http")));
return client;
}
}
12.java代码es创建数据
package com.bie;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
/**
* es 7.9.3客户端api测试
*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class JavaEsApiApplicationTests {
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
/**
* 创建索引
* Request
*/
@Test
public void createIndex() throws IOException {
// 1.创建索引请求
CreateIndexRequest bieIndex = new CreateIndexRequest("bie_index");
// 2.执行索引请求
CreateIndexResponse createIndexResponse =
this.client.indices().create(bieIndex, RequestOptions.DEFAULT);
System.out.println(createIndexResponse.toString());
}
}
13.查看es是否插入成功:成功
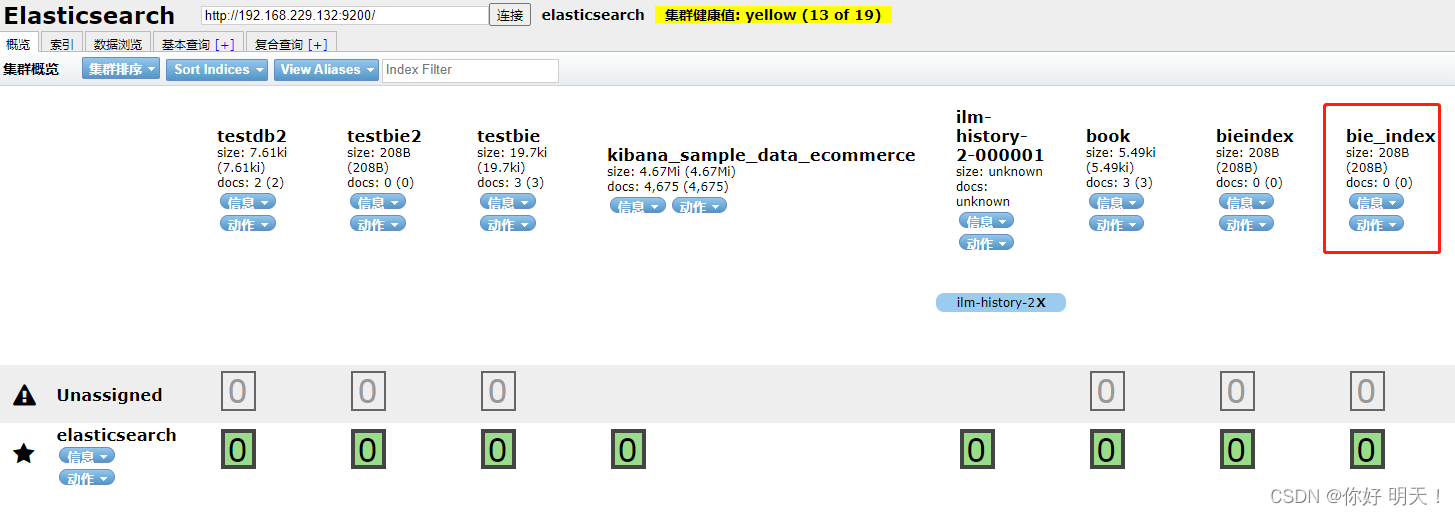
14.获取索引
/**
* 获取索引
* @throws IOException
*/
@Test
public void getIndex() throws IOException {
// 1.创建获取索引请求
GetIndexRequest bieIndex = new GetIndexRequest("bie_index");
// 2.执行索引请求
boolean exists = this.client.indices().exists(bieIndex, RequestOptions.DEFAULT);
System.out.println(exists);
}
15.删除索引
/**
* 删除索引
*
* @throws IOException
*/
@Test
public void deleteIndex() throws IOException {
// 1.创建获取索引请求
DeleteIndexRequest bieIndex = new DeleteIndexRequest("bie_index");
// 2.执行索引请求
boolean isDeleteSuccess = this.client.indices().delete(bieIndex, RequestOptions.DEFAULT).isAcknowledged();
System.out.println(isDeleteSuccess);
}
16.创建文档
/**
* 添加文档
*
* @throws IOException
*/
@Test
public void addDoc() throws IOException {
// 1.创建 索引请求对象
IndexRequest indexRequest = new IndexRequest("bie_index");
indexRequest.timeout(TimeValue.timeValueSeconds(1));
indexRequest.id("1");
// 2.创建user对象
User user = new User();
user.setAge(18);
user.setName("java从入门到入魔");
// 3.对象数据转json
indexRequest.source(JSON.toJSONString(user), XContentType.JSON);
// 4.执行请求
IndexResponse response = this.client.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(response.status()); // 返回操作的状态,初次是CREATED,后续修改返回OK
System.out.println(response.toString());
}
/**
* 获取文档,判断是否存在
*
* @throws IOException
*/
@Test
public void docExist() throws IOException {
//1.创建索引请求对象
GetRequest getRequest = new GetRequest("bie_index", "2");
//不获取返回的_source上下文,效率高
getRequest.fetchSourceContext(new FetchSourceContext(false));
//不排序
getRequest.storedFields("_none_");
// 2.执行请求
boolean exists = this.client.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
17.crud文档
/**
* 获取文档信息
*/
@Test
public void getDoc() throws IOException {
//1.创建索引请求对象
GetRequest getRequest = new GetRequest("bie_index", "1");
//2.执行请求
GetResponse response = this.client.get(getRequest, RequestOptions.DEFAULT);
//3.获取文档内容
String sourceAsString = response.getSourceAsString();
System.out.println(sourceAsString);
}
/**
* 更新文档信息
*/
@Test
public void updateDoc() throws IOException {
//1.创建 更新索引请求对象
UpdateRequest updateRequest = new UpdateRequest("bie_index", "1");
updateRequest.timeout(TimeValue.timeValueSeconds(1));
//2.封装修改数据
UpdateRequest request = updateRequest.doc(JSON.toJSONString(new User().setName("哈哈 java")), XContentType.JSON);
//3.执行请求
UpdateResponse response = this.client.update(request, RequestOptions.DEFAULT);
System.out.println(response);
}
/**
* 删除文档信息
*/
@Test
public void deleteDoc() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("bie_index", "qVMa-oQBSvq_7IxZDk-f");
deleteRequest.timeout(TimeValue.timeValueSeconds(1));
DeleteResponse response = this.client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(response.status());
}
18.批量操作
/**
* 批量 操作数据
*/
@Test
public void bulkDoc() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout(TimeValue.timeValueSeconds(10)); //数据越多,设置操作时间越大
List<User> users = Arrays.asList(new User("bie", 18), new User("bie3", 28));
for (int i = 0; i < users.size(); i++) {
bulkRequest.add(new IndexRequest("bie_index")
.id(String.valueOf(i + 1))
.source(JSON.toJSONString(users.get(i)), XContentType.JSON));
}
BulkResponse response = this.client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(response.status());
}
19.搜索
常用搜索
- 精确查询:TermQueryBuilder
- 全匹配查询:MatchAllQueryBuilder
- 分页:sourceBuilder.from();sourceBuilder.size()
- 高亮:sourceBuilder.highlighter()
/**
* 搜索
* 常用查询操作:.
* <p>
* 精确查询:TermQueryBuilder
* 全匹配查询:MatchAllQueryBuilder
* 分页:sourceBuilder.from();sourceBuilder.size()
* 高亮:sourceBuilder.highlighter()
*/
@Test
public void searchDoc() throws IOException {
SearchRequest searchRequest = new SearchRequest("bie_index");
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//QueryBuilders快速构建查询条件。
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("age", 18);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(TimeValue.timeValueSeconds(1));
searchRequest.source(sourceBuilder);
SearchResponse response = this.client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(response.getHits()));
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(JSON.toJSONString(hit.getSourceAsMap()));
}
}