1.3 初步检索
1.3.1、_cat
GET /_cat/nodes:查看所有节点
GET /_cat/health:查看 es 健康状况
GET /_cat/master:查看主节点
GET /_cat/incices:查看所有索引 show data
1.3.2 索引一个文档(保存)
保存一个数据,保存在哪个索引的哪个类型下,指定用哪个唯一标识
PUT customer/external/1; 在 customer 索引下的 external 类型下保存 1号数据为,id不能省略,必传,存在则更新,不存在则插入

_代表的是元数据信息,_shards:里面包含的是集群的信息
POST customer/external/1; 在 customer 索引下的 external 类型下保存 1号数据为,id带不带都可以,带上id作用和put请求是一样的,不带id,系统会自动生成一个唯一id,每次都是新插入数据。
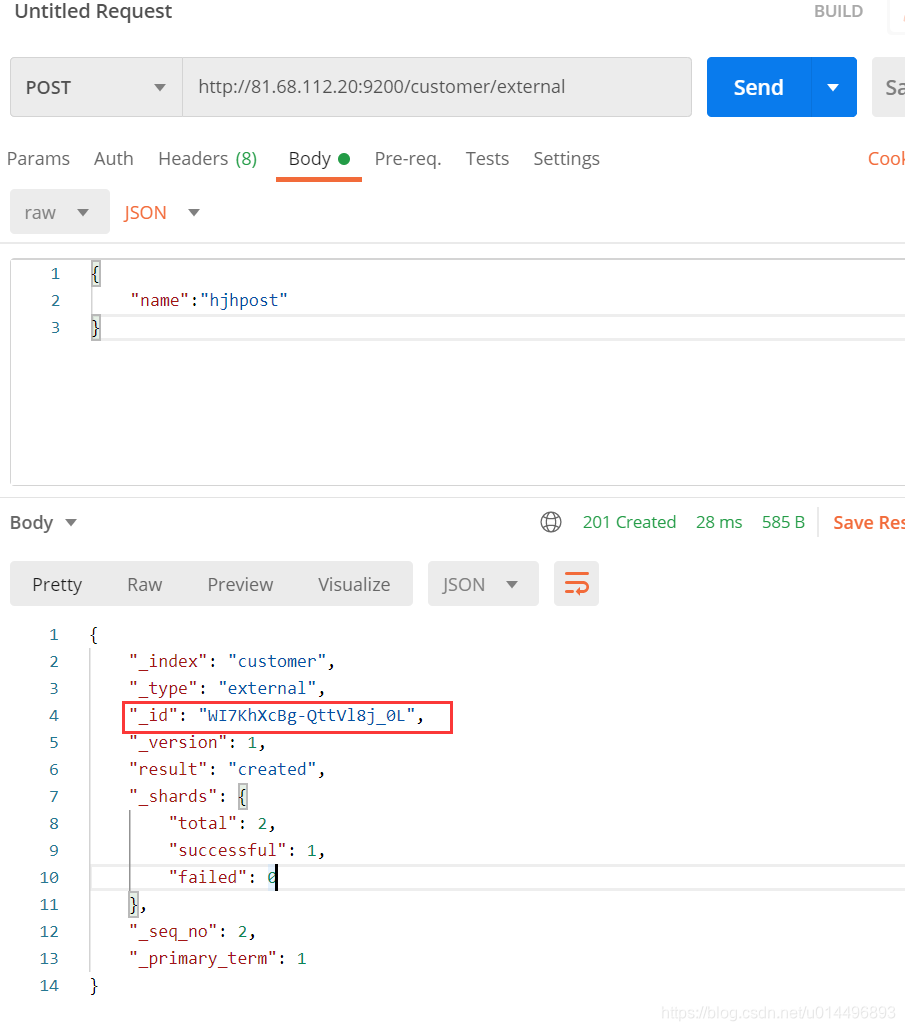
1.3.3、查询文档
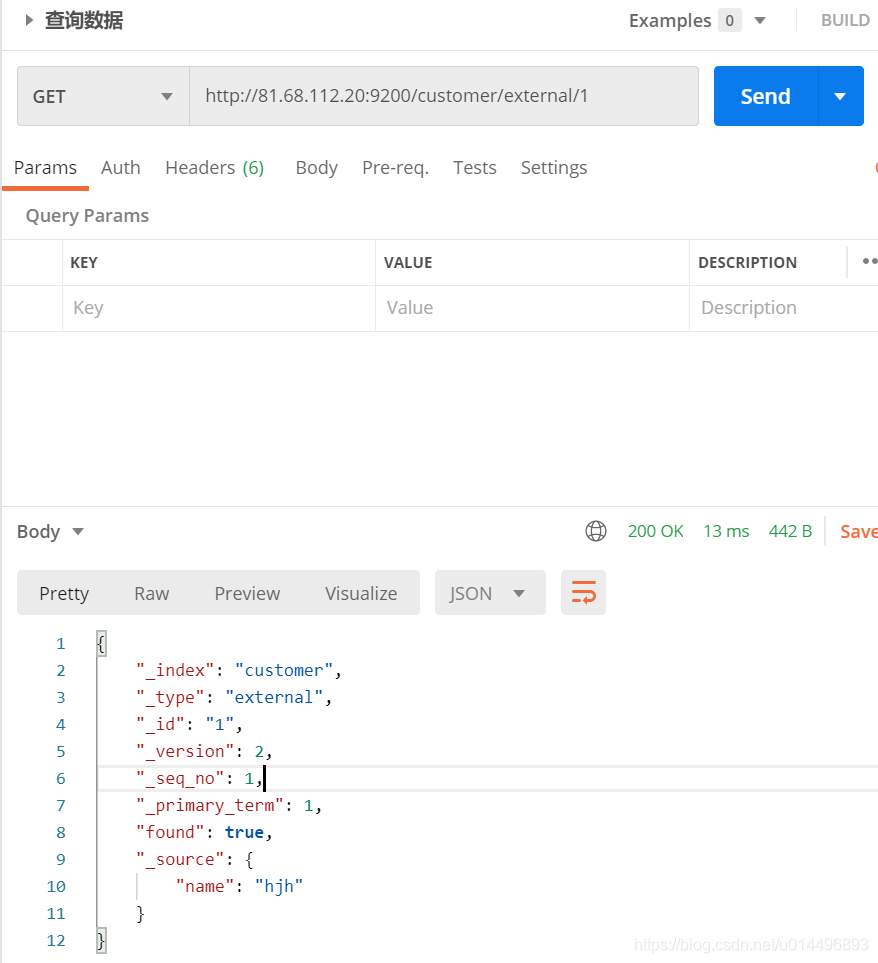
GET custome/external/1
结果:
{
"_index": "customer", // 在那个索引
"_type": "external", // 在那个类型
"_id": "1", // 记录id
"_version": 1, 。// 版本号
"_seq_no": 0, // 并发控制字段,每次更新就会+1,用来做乐观锁
"_primary_term": 1, //同上,主分片重新分配,如重启,就会变化
"found": true,
"_source": {
"name": "John Doe" // 真正的内容
}
}
乐观锁的实现:
更新携带:?if_seq_no=1&if_primary_term=1可以实现乐观锁,每次更新了_seq_no都会加1
http://81.68.112.20:9200/customer/external/1?if_seq_no=1&if_primary_term=1
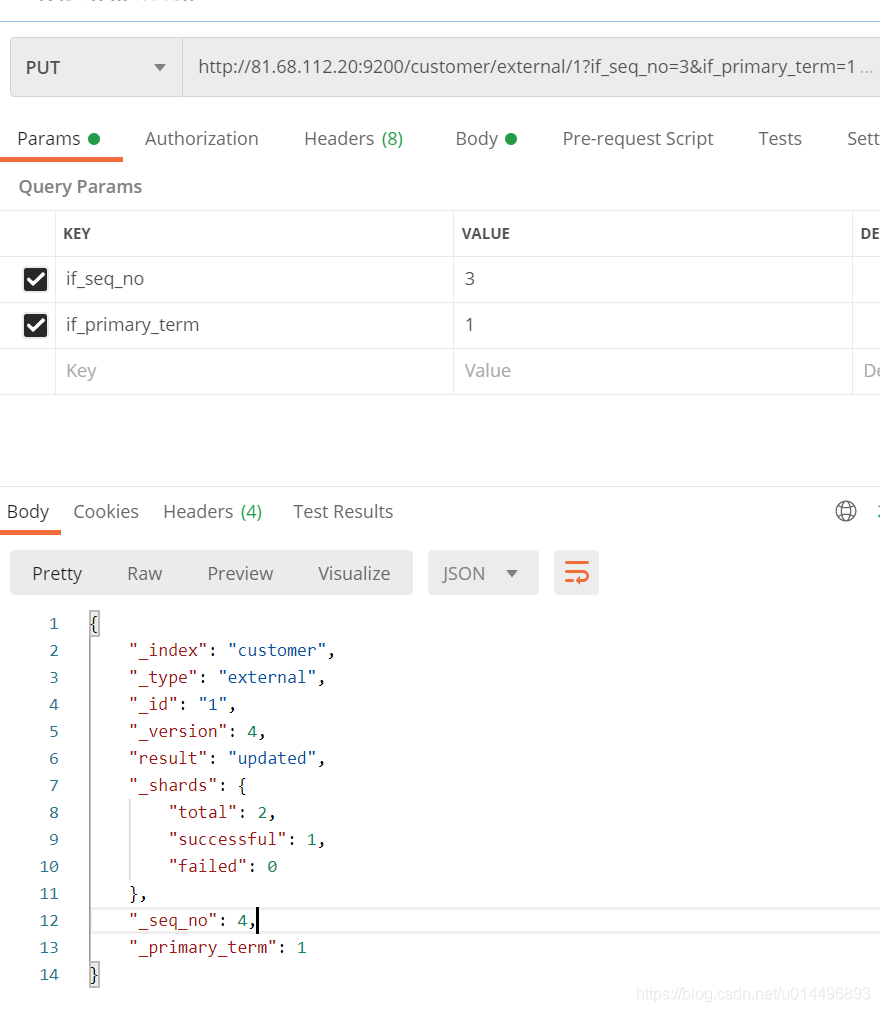
1.3.4 更新文档
POST customer/external/1/_update
{
"doc":{
"name":"John Doew"
}
}
或者
POST customer/external/1
{
"name":"John Doe2"
}
或者
PUT customer/external/1
{
"name":"jack"
}
不同:Post操作会对比源文档数据,如果相同不会有什么操作,文档 version 不增加 PUT操作总会将数据重新保存并增加 version 版本
带 _update 对比元数据如果一样就不进行任何操作
看场景
对于大并发更新,不带update
对于大并发查询并偶尔更新,带update 对比更新,重新计算分配规则
更新同时增加属性
POS customer/external/1/_update
{
"doc":{
"name":"Jane Doe","age":20}
}
PUT 和 POST 不带_update也可以
1.3.5 删除文档&索引
DELETE customer/external/1
DELETE customer
1.3.6 bulk 批量 API
POST customer/external/_bulk
{
"index":{
"_id":"1"}}
{
"name":"John Doe"}
{
"index":{
"_id":"2"}}
{
"name":"John Doe"}
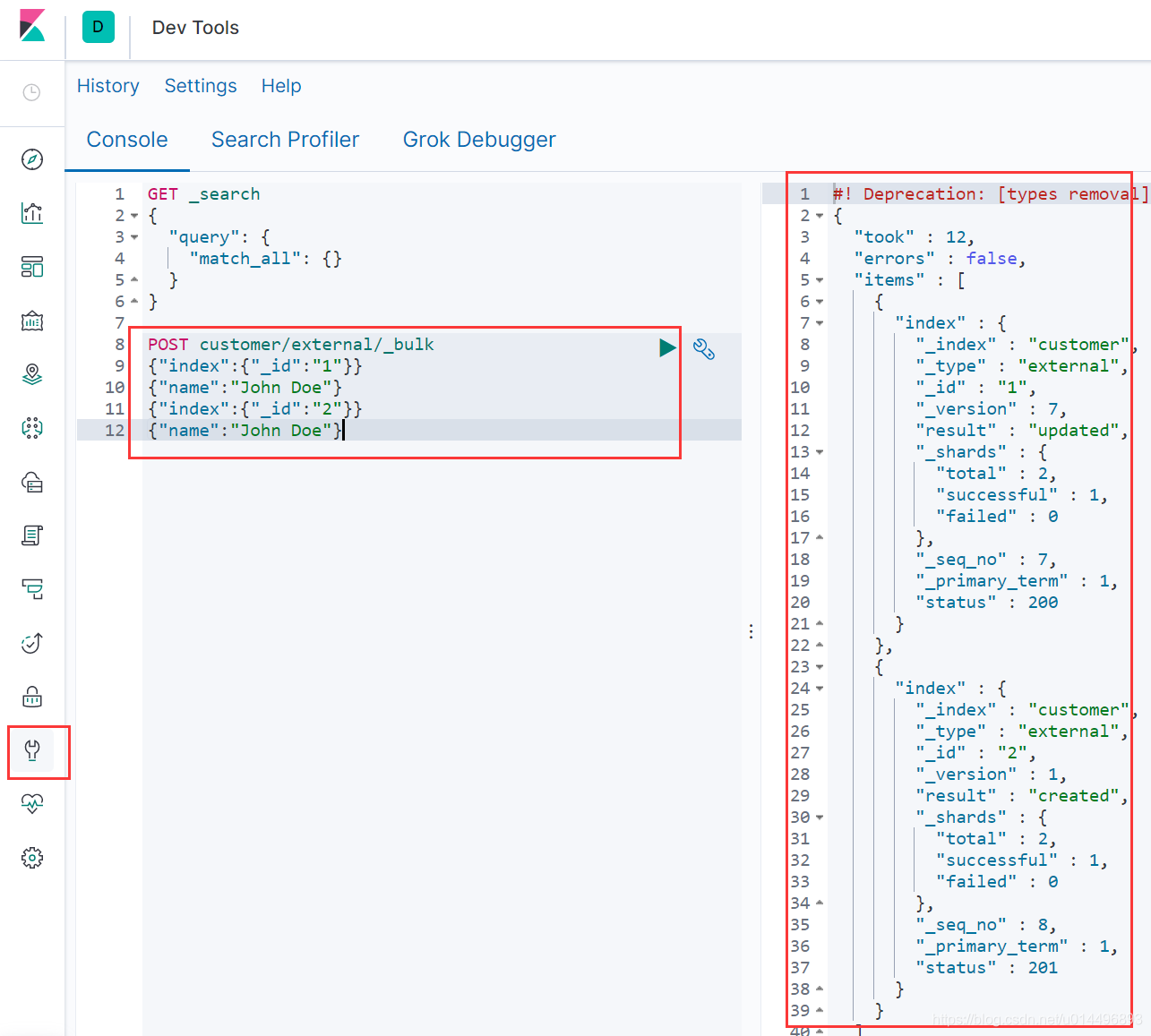
bulk API以此按顺序执行所有的action (动作)。如果一一个单个的动作因任何原因而失败,它将继续处理它后面剩余的动作。当bulkAPI 返回时,它将提供每个动作的状态(与发送的顺序相同),所以您可以检查是否一个指定的动作是不是失败了。
1.3.7 样本测试数据
我准备了一份顾客银行账户信息虚构的 JSON 文档样本,每个用户都有下列的 schema (模式):
{
"account_number": 1,
"balance": 39225,
"firstname": "Amber",
"lastname": "Duke",
"age": 32,
"gender": "M",
"address": "880 Holmes Lane",
"employer": "Pyrami",
"email": "[email protected]",
"city": "Brogan",
"state": "IL"
}
https://github.com/elastic/elasticsearch/blob/master/docs/src/test/resources/accounts.json
导入测试数据
POST bank/account/_bank
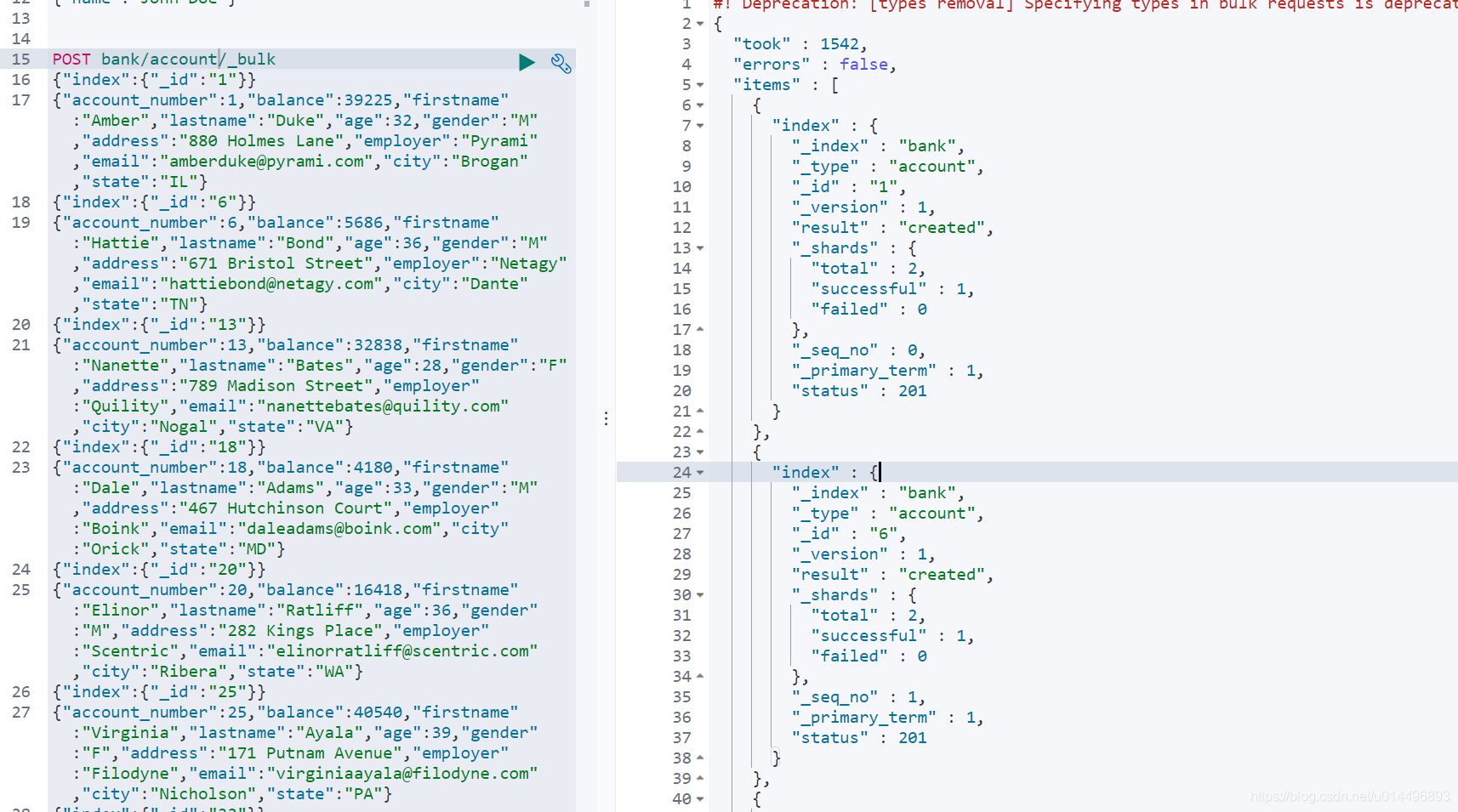
1.4 进阶检索
1.4.1 SearchAPI
ES 支持两种基本方式检索:
- 一个是通过使用 REST request URL,发送搜索参数,(uri + 检索参数)
- 另一个是通过使用 REST request bod 来发送他们,(uri + 请求体)
1、检索信息
一切检索从_search开始
GET /bank/_search 检索 bank 下的所有信息,包括 type 和 docs
GET /bank/_search?q=*&sort=account_number:asc 请求参数方式检索
响应结果解释 took - Elasticearch执行搜索的时间(毫秒)
time_ out - 告诉我们搜索是否超时
_shards - 告诉我们多少个分片被搜索了,以及统计了成功/失败的搜索分片 hit - 搜索结果 hits.total - 搜索结果 hits.hits - 实际的搜索结果数组(默认为前10的文档) sort - 结果的排序key (键) (没有则按 score 排序) score 和 max score - 相关性得分和最高得分(全文检索用)
uri + 请求体进行检查
GET /bank/_search
{
"query": {
"match_all": {
} },
"sort": [
{
"account_number": "asc" }
]
}
query 定义如何查询
match_all 查询类型【代表查询所有的所有】,es中可以在 query中 组合非常多的查询类型完成复杂查询
除了 query 参数之外,我们也可以传递其他的参数改变查询结构,如 sort,size
from + size 限定,完成分页功能
sort排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准
2、返回部分字段
GET bank/_search
{
"query":{
"match_all": {
}
},
"sort": [
{
"balance": {
"order": "desc"
}
}
],
"from": 5,
"size": 5,
"_source": ["firstname","lastname"]
}
3、match【匹配查询
基本类型(非字符串),精准匹配
GET bank/_search
{
"query":{
"match": {
"address": "mill lane"
}
}
}
全文检索按照评分进行排序,会对检索条件进行分词匹配
4、match_phrase【短语匹配】
将需要匹配的值当成一个整体单词(不分词)进行检索,只要包含有mill lane就能别检索到
GET /bank/_search
{
"query": {
"match_phrase": {
"address": "mill lane" } }
}
address.keyword表示精确匹配许需要完整的匹配上789 Madison,不分词
GET bank/_search
{
"query": {
"match": {
"address.keyword": "789 Madison"
}
}
}
5、multi_match【多字段匹配】
address或者city包含mill,类似mysql中 address like mill or city like mill
GET bank/_search
{
"query":{
"multi_match": {
"query": "mill",
"fields": ["address","city"]
}
}
}
6、bool 【复合查询】
bool 用来做复合查询
复合语句可以合并 任何 其他嵌套语句,包括复合语句,了解这一点是很重要的,这就意味着,复合语句之间可以互相嵌套,可以表达式非常复杂的逻辑
- must:必须达到 must 列举的所有条件,参与评分的
GET /bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
],
"must_not": [
{
"match":{
"age":"18"
}}
],
"should": [
{
"match": {
"lastname": "Wallace"
}}
]
}
}
}
- should:应该达到 should 列举的条件,如果达到会增加相关文档的评分,并不会改变查询的结果,如果 query 中只有 should 且只有一种匹配规则,那么 should的条件就会被作为默认匹配条件而去改变查询结果
"should": [
{
"match": {
"lastname": "Wallace"
}}
]
- must_not 必须不是指定的情况
"must_not": [
{
"match":{
"age":"18"
}}
],
7、filter【结果过滤】,不参与分数评分
并不是所有的查询都需要产生分数,特别是那些仅仅用于 filtering(过滤)的文档,为了不计算分数 ES 会自动检查场景并且优化查询的执行
GET /bank/_search
{
"query": {
"bool": {
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}
8、term
和 match 一样,匹配某个属性的值,全文检索字段用 match,其他非text字段匹配用 term
GET bank/_search
{
"query": {
"term": {
"address": "Madison"
}
}
}
9、aggregations(执行聚合)
聚合提供了从数据分组和提取数据的能力,最简单的聚合方法大致等于 SQL GROUP BY 和 SQL 聚合函数,在 ES 中,你有执行搜索返回 hits (命中结果) 并且同时返回聚合结果,把一个响应中的所有 hits(命中结果)分隔开的能力,这是非常强大有效的,你可以执行查询和多个聚合,并且在一个使用中得到各自的(任何一个的)返回结果,使用一次简洁简化的 API 来避免网络往返
搜索address中包含mill的所有人的年龄分布以及平均年龄
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 10
}
},
"ageAvg":{
"avg": {
"field": "age"
}
},
"balanceAvg":{
"avg": {
"field": "balance"
}
}
},
}
响应的结果:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 5.4032025,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "970",
"_score" : 5.4032025,
"_source" : {
"account_number" : 970,
"balance" : 19648,
"firstname" : "Forbes",
"lastname" : "Wallace",
"age" : 28,
"gender" : "M",
"address" : "990 Mill Road",
"employer" : "Pheast",
"email" : "[email protected]",
"city" : "Lopezo",
"state" : "AK"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "136",
"_score" : 5.4032025,
"_source" : {
"account_number" : 136,
"balance" : 45801,
"firstname" : "Winnie",
"lastname" : "Holland",
"age" : 38,
"gender" : "M",
"address" : "198 Mill Lane",
"employer" : "Neteria",
"email" : "[email protected]",
"city" : "Urie",
"state" : "IL"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "345",
"_score" : 5.4032025,
"_source" : {
"account_number" : 345,
"balance" : 9812,
"firstname" : "Parker",
"lastname" : "Hines",
"age" : 38,
"gender" : "M",
"address" : "715 Mill Avenue",
"employer" : "Baluba",
"email" : "[email protected]",
"city" : "Blackgum",
"state" : "KY"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "472",
"_score" : 5.4032025,
"_source" : {
"account_number" : 472,
"balance" : 25571,
"firstname" : "Lee",
"lastname" : "Long",
"age" : 32,
"gender" : "F",
"address" : "288 Mill Street",
"employer" : "Comverges",
"email" : "[email protected]",
"city" : "Movico",
"state" : "MT"
}
}
]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 38,
"doc_count" : 2
},
{
"key" : 28,
"doc_count" : 1
},
{
"key" : 32,
"doc_count" : 1
}
]
},
"ageAvg" : {
"value" : 34.0
},
"balanceAvg" : {
"value" : 25208.0
}
}
}
按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
GET bank/_search
{
"query":{
"match_all": {
}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 10
},
"aggs": {
"ageAvg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
查出所有年龄分布,并且这些年龄段中M的平均薪资和 F 的平均薪资以及这个年龄段的总体平均薪资
GET /bank/_search
{
"query": {
"match_all": {
}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"genderAgg": {
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
}
}
1.4.3 Mapping
2、映射
Mapping(映射)
Mapping 是用来定义一个文档(document),以及他所包含的属性(field)是如何存储索引的,类似与mysql中的字段类型,比如使用 mapping来定义的:
- 哪些字符串属性应该被看做全文本属性(full text fields)
- 那些属性包含数字,日期或者地理位置
- 文档中的所有属性是能被索引(_all 配置)
- 日期的格式
- 自定义映射规则来执行动态添加属性
查看 mapping 信息
GET bank/_mapping
3、新版本改变
-
关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但ES中不是这样的。elasticsearch 是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed 最终在Lucene,中的处理方式是一样的。
-
两个不同 type下的两个user_ name, 在ES同-个索引下其实被认为是同一一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同typpe中的相同字段称就会在处理中出现神突的情况,导致Lucene处理效率下降。
-
去掉type就是为了提高ES处理数据的效率。
ES 7.x
URL 中的 type 参数 可选,比如索引一个文档不再要求提供文档类型
ES 8.X
不在支持 URL 中的 type 参数
解决:
1、将索引从多类型迁移到单类型,每种类型文档一个独立的索引
2、将已存在的索引下的类型数据,全部迁移到指定位置即可,详见数据迁移
1、创建映射
PUT /my-index
{
"mappings": {
"properties": {
"age": {
"type": "integer" },
"email": {
"type": "keyword" },
"attrName" : {
"type" : "keyword",
"index" : false,
"doc_values" : false
}
}
}
}
此处的 “index”:false表示不被索引检索到,“doc_values” : false表示不支持聚合查询。
2、添加新的字段映射
PUT /my_index/_mapping
{
"properties":{
"employeeid":{
"type":"keyword",
"index":false
}
}
}
3、更新映射
对于已经存在的映射字段,我们不能更新,更新必须创建新的索引进行数据迁移
4、数据迁移
先创 new_twitter 的正确映射,然乎使用如下方式进行数据迁移
POST _reindex [固定写法]
{
"source":{
"index":"twitter"
},
"dest":{
"index":"new_twitter"
}
}
## 将旧索引的 type 下的数据进行迁移
POST _reindex
{
"source": {
"index":"twitter",
"type":"tweet"
},
"dest":{
"index":"twweets"
}
}
参考官网:
https://www.elastic.co/guide/en/elasticsearch/reference/7.10/mapping-types.html
参数映射规则:
https://www.elastic.co/guide/en/elasticsearch/reference/7.10/mapping-params.html#mapping-params
1.4.4 分词
一个 tokenizer(分词器)接收一个字符流,将之分割为独立的 tokens(词元,通常是独立的单词),然后输出 token 流
列如,witespace tokenizer 遇到的空白字符时分割文本,它会将文本 “Quick brown fox” 分割为 【Quick brown fox】
该 tokenizer (分词器)还负责记录各个term (词条)的顺序或 position 位置(用于phrase短语和word proximity词近邻查询),以及
term (词条)所代表的原始 word (单词)的start(起始)和end (结束)的 character offsets (字符偏移量) (用于 高亮显示搜索的内容)。
Elasticsearch 提供了很多内置的分词器,可以用来构建custom analyzers(自定义分词器)
1、安装 ik 分词器
注意:不能用默认的 elasticsearch-plugin.install xxx.zip 进行自动安装
https://github.com/medcl/elasticsearch-analysis-ik/releases
下载与 es对应的版本
安装后拷贝到 plugins 目录下,安装分词的步骤见
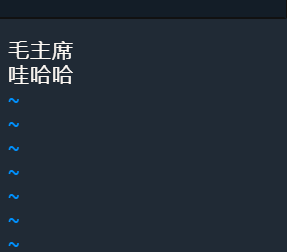
这里我们采用的是在nginx远程创建一个分词库来维护分词,
在nginx的与index.html同级目录下创建一个fenxi.txt文件,
这里我们是在nginx映射到主机的目录/usr/local/nginx/html/es 下来创建的fenci.txt
远程访问看是否生效
3、添加自定义词库
修改/usr/local/elasticsearch/plugins/ik/config中的IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.56.10/es/fenci.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
当想要添加其他词汇时候就可以在/usr/local/nginx/html/es/fenci.txt文件里面添加即可。