[译]基于深度残差学习的图像识别
Deep Residual Learning for Image Recognition
微软研究院
{kahe, v-xiangz, v-shren, jiansun}@microsoft.com
摘要:神经网络的训练因其层次加深而变得愈加困难。我们所提出的残差学习框架可以更轻松的对比前人所提深很多的网络进行训练。相对于之前网络所学习的是无参考的函数,我们显著改进的网络结构可根据网络的输入对其残差函数进行学习。我们提供的详实经验证据表明对这样的残差网络进行寻优更加容易,并且随网络层次的显著加深可以获得更好的准确率。我们利用ImageNet数据集验证了深达152层残差网络——尽管这个网络的深度是VGG网络[41]的8倍,然而复杂度却相对较低。该残差网络对ImageNet测试集的错误率为3.57%,这个结果取得了2015年ILSVRC分类任务的第一名。此外,我们分析了分别用100层和1000层网络对CIFAR-10数据集的处理。
表示深度对于很多类型的视觉识别任务至关重要。我们仅依赖于较深的表示,将对COCO物品检测数据集的处理结果提高了28%。深度残差网络是我们提交给ILSVRC和COCO 2015比赛的核心,同时也在ImageNet物品检测、ImageNet地理位置检测、COCO物品检测和COCO分割中赢得了第一名。
1 引言
深度卷积神经网络[22, 21]的提出引发了图像分类方法的一系列突破[21, 50, 40]。深度网络自然集成了低、中、高层特征表示[50]的多层次端对端形式的分类器,多层特征可以通过网络层堆叠的数量(网络深度)来丰富其表达。最近的实证[41, 44]显示网络的深度是极其重要的,其中挑战ImageNet数据集的优秀成果[41, 44, 13, 16]都是采用“较深”[41]的模型,深度从16层[41]至30层[16]不等。很多其他的重要视觉识别任务[8, 12, 7, 32, 27]也很大程度上得益于较深的网络模型。
网络深度非常重要,但也存在一些问题:是否能够简单的通过增加更多的网络层次学习到更好的网络?解决这个问题的障碍之一是臭名昭著的所谓梯度消失(爆炸)问题[1, 9],这从根本上妨碍了网络收敛,虽然这个问题已被广泛讨论,并试图通过一些办法加以解决,包括通过规范初始化[23, 9, 37, 13]和引入中值规范化层[16]的方式使得多达几十层的利用随机梯度下降(SGD)方法使得反馈网络[22]的求解得以收敛。
虽然这些较深的网络得以收敛,一个所谓的退化(degradation)问题也暴露了出来,即随着网络深度的增加,准确率(accuracy)增长的速率会很快达到饱和(这可能也并不奇怪)然后就很快的下降了。令人意外的是,此类退化问题并不是由于过拟合造成的,而且,对一个合适的深度网络模型增加更多的层次会使得训练误差更高,这曾被报告于[11, 42]并且也被我们的实验充分验证了,图1展示了一个典型的案例。
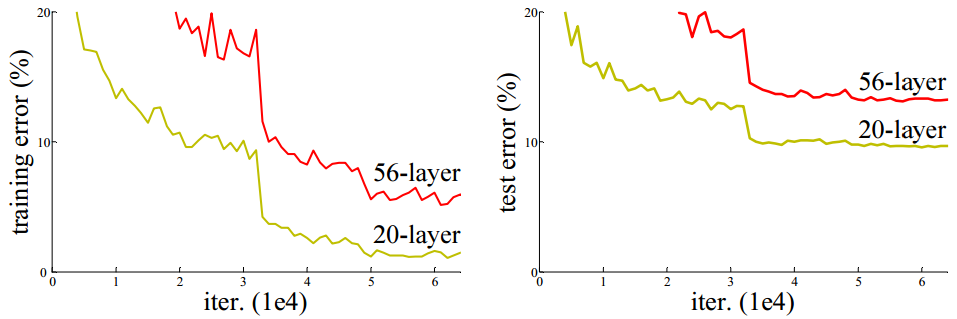
图1 利用20层和56层的平凡网络对于CIFAR-10数据集的训练误差(左图)和测试误差(右图)。可见越深的网络会产生越大的训练误差和测试误差。ImageNet数据集上发生的类似现象见图4。
退化问题(对训练的准确度而言)表明了并不是所有的系统都能容易的达到优化。让我们考虑一个较为浅层的结构以及另一个作为对比以此为基础但包含了较多网络层次、相对较深的结构。对于构造更深的网络模型的方法之一是在所增加的层次上均采用恒等映射(Identity Mapping),而其他层次则是直接使用已经学习好的浅层网络。这种构造方法的存在意在使得加深后的模型所产生的训练误差不应高于它所基于的较浅的模型。然而,经验表明我们从手头的办法中无法找到和这种构造式方法一样好或者更优的解决方案(或者是无法在可行的时间的完成更深网络的构造)。
在本文中,我们提出一种深度残差学习框架来解决退化问题。我们利用多层网络拟合一个残差映射,而不是寄希望于每组少数的几个层的网络层就可以直接拟合出我们所期望的实际映射关系。正式的,我们用H(x)表示所期望得到的实际映射,我们使得堆叠的非线性多层网络去拟合另一个映射关系F(x) := H(x)-x,那么实际的映射关系即可表示为F(x)+x。我们认为对残差映射寻优可能会比直接对原始的参考映射寻优更为方便。更进一步的,如果一个识别映射是被优化了的,相比于利用一个堆叠的非线性组合拟合一个恒等映射,则使得其残差值趋于0值会更加容易一些。
公式F(x)+x可以通过添加了“捷径连接(shortcut connections)”的前向神经网络实现(见图2)。捷径连接[2, 34, 49]是指一种跳过一个或多个层次的连接。在我们的案例中,所使用的捷径连接仅仅是进行恒等映射(identify mapping),它们的输出被加入到堆叠层次的输出中(见图2)。恒等映射捷径连接的增加并没有引入新的参数也没有增加计算复杂度。整个网络仍然可以通过SGD反向传播进行端到端的训练,也可以利用常用的库(如:Caffe[19])加以实现而不用修改求解方法。
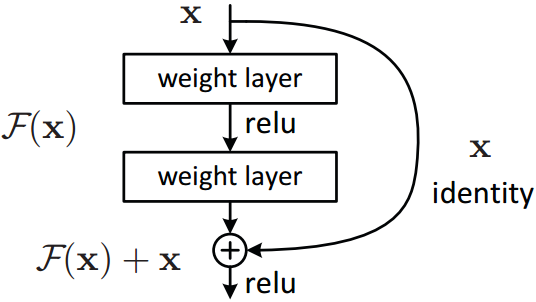
图2 残差学习:一个构建单元
我们基于ImageNet数据集[36]进行详尽实验,演示了退化问题,并对我们提出的方法进行了评估。结果表明:1)我们提出的超深度残差网络更便于优化,而其所对应的平凡网络(即简单通过层次堆叠而成的网络)的训练误差却随着网络层次的加深而变大;2)我们所提出的深度残差网络更容易在增加深度时获得精度的提高,明显优于之前的网络结构所得到的结果。
类似的现象也可以通过对于CIFAR-10数据集[20]的实验看到,实验结果表明对网络寻优的难度和我们所提出的方法的效果并不局限于特定的数据集。我们对该数据集展示了对深度为100层网络的训练,尝试了深达1000层的网络。
对于ImageNet分类数据集[36],我们通过超深的残差网络获得了很好的结果。我们的152层残差网络是目前已知最深的应用于ImageNet数据集的网络,然而其复杂度却低于VGG网络[41]。我们的方法最终对ImageNet测试数据集的误差为3.57%,位列前五,并且获得了2015年ILSVRC分类比赛的第一名。超深度的表示对于其他的识别任务也有很好的泛化能力,这使得我们在2015年ILSVRC&COCO比赛中赢得了ImageNet物品检测、ImageNet地理定位、COCO物品检测和COCO图像分割的第一名。事实表明,残差学习方法是具有一般性的,我们也希望它能够被进一步应用于其他视觉和非视觉类问题的解决。
2 相关工作
残差表示。在图像识别中,VLAD[18]是通过基于词典的残差向量来进行编码表示的,而Fisher向量[30]则可以被认为是VLAD[18]的概率版本。它们都是很好的用于图像检索和分类的浅层表示方法[4, 48]。矢量量化,残差向量编码[17]都比对原始向量直接编码更为有效。
在低级视觉和计算机图形学中,对偏微分方程(Partial Differential Equation, PDE)的求解,通常是用多重网格(Multigrid)法[3]对系统中多尺度的子问题重新建模,每个子问题负责求解出较粗粒度或较细粒度的残差。除多重网格法外,级联基预处理[45, 46]也被用于求解上述的偏微分方程,它是基于表示了两个尺度间残差的量来进行的。通过文献[3, 45, 46]可知这些求解方法比不考虑残差的求解方法能够更加快速的收敛。对这些方法的研究表明一个好的模型重构或预处理将有利于模型的优化。
捷径连接。捷径连接的相关工作所基于的实践和理论上[2, 34, 49]已经被研究了相当长时间。早期的关于训练多层感知器网络(MLP, multi-layer perceptrons)的实践包括通过在网络的输入层和输出层之间增加一个线性层[34, 49]。在文献[44, 24]中,少量的中间层被直接连接到了附加的分类器来解决梯度消失或梯度爆炸的问题。文献[39, 38, 31, 47]则提出了层响应置中(centering layer responses)、梯度和传播误差,是采用的捷径连接的办法。在文献[44]中,使用了一种由捷径分支和少量较深的分支构成的“开端(inception)”层。
和我们同期的工作也有一些,文献[42, 43]提出的“高速公路网络(highway networks)”展示了附设了门函数的捷径连接[15]。这些所谓的门函数是数据相关的且需要进行参数调整,对比而言,我们的恒等捷径是无需调参的。当门捷径“关闭”(趋零)时,高速公路网络中的层表示是非残差函数,相反的,我们对残差函数的学习贯穿了我们的方法;我们的恒等捷径不需要关闭,因此信息总是被透传过去,并藉此学习残差函数。此外,高速公路网络也没有演示出随着网络深度很大程度的加大,准确率是否得到了提升。
3 深度残差学习
3.1 残差学习
让我们考虑H(x)是一个将通过若干堆叠的网络层(不需要一定是整个网络)进行映射关系的拟合,这里用x表示对这些层中第一层的输入。多层非线性层次可以逐渐逼近某个复杂函数的假设等价于它可以渐进的逼近残差函数,即H(x)-x(这里假设输入和输出是相同维度的)。也就是说,与其指望这些堆叠的层能够逼近H(x),我们也可以显式的用它们来逼近残差函数F(x) := H(x)-x。如此,对应的原函数即为F(x)+x。尽管采用这两种形式都有可能渐进的逼近到目标函数(根据上述假设),然而学习的难度可能会存在差异。
此番重构的动因是由于退化问题中所表现出的反直觉的现象(图1(左图))。正如我们在引言里对这个问题所作出的说明那样,如果能够以恒等映射的方式来构建所增加的层,一个加深模型的训练误差就不会大于它所基于的较浅模型。退化问题表明利用多个非线性网络层对于恒等映射作逼近可能会存在求解上的困难。通过残差学习的办法重构这个方法,当恒等映射达到最优,则求解可能就仅仅是简单的更新多个非线性网络层中的权重来求解恒等映射关系。
在实际案例中,恒等映射不大可能一开始就已经达到最优,然而我们重新构造的模型可能有助于问题求解的预处理环节。若最优函数接近于一个恒等映射而不是一个零值映射,求解时可能更容易通过参考一个恒等映射的办法确定扰动,而不是将其作为全新的函数来学习。我们通过实验(图7)展示了完成了学习的残差网络一般响应较小,这表明恒等映射是一种合理的预处理手段。
3.2 利用捷径作恒等映射
我们对每组网络层采用残差学习。一个构造块如图2所示。正式的,在本文中我们将每个构造块定义为:
此处,x和y分别表示构造块的输入和输出向量。函数F(x, {Wi })表示将被学习到的残差映射。图2所示的例子包含两层,F=W2σ(W1x)中的σ表示ReLU[29]的参数且为了简化符号省略了偏置项。操作F+x是通过捷径连接进行逐元素的相加。我们在加法之后所得到的模型具有二阶非线性(如图2中的σ(y))。
公式(1)中的捷径连接并未引入新的参数或计算复杂度。这不仅便于应用而且在我们对普通和残差网络进行对比时也尤为重要,这样我们可以公平对普通和残差网络在参数数量、深度、宽度和计算代价相同的情况下作比较(除了几乎可以忽略不计的逐元素加法运算)。
在公式(1)中的x和F的维度必须相同,如果不是这样(例如当输入或输出通道的数量发生改变时),我们可以在捷径连接上作一个线性投影Ws来满足维数相等的条件,即:
我们同样也可以在公式(1)中使用方块矩阵Ws。然而我们将通过实验展示恒等映射就足以经济的解决退化问题,因此,Ws将仅仅被用来解决维数匹配的问题。
残差函数F的形式具有一定的灵活性。本文实验包括了F为两层或三层时的情形(图5)。虽然更多的层次数量也是可行的,而当F仅有一层时,公式(1)将等同于一个线性层,即y=W1x+x,这样一来就没有什么优势可言了。
我们同时指出尽管上述的数学公式为简明起见都是对于全关联层而言的。它们对于卷积层也同样具有可行性,此时的函数F(x, {Wi })将表示多个卷积层,而逐元素的加法运算则是对于各通道中的两个特征图的。
3.3 网络结构
我们对于多种类型的普通和残差网络进行了试验,所观察到了颇具一致性的现象。为了给讨论提供实证,接下来我们将描述应用于ImageNet数据集的两种网络结构。
平凡网络。我们的普通基准网络(图3-中图)主要是受VGG网络理论的启发[41] (图3-左图)。多数的卷积层的过滤器尺寸为3×3并且在设计时遵从下列两条简单的规则:(i)对于相应大小的输出特征图尺寸,层中必须含有相同数量的过滤器;(ii)若特征图尺寸减半时,则需要倍增过滤器数量来保持各层的时间复杂度。我们通过步长为2的卷积层直接进行降采样。最终的网络包括了一个全局的均值池化层和1000路装备了softmax激活函数的全连接层。含有权重的网络层总计有34层(图3-中图)。
值得注意的是我们的模型包含了较少的过滤器并且相对于VGG网络(图3-左图)具有较低的计算复杂度。我们层数为34的网络的基本计算量为36亿FLOPs (包括乘法运算和加法运算),大约仅为VGG-19(196亿FLOPs)的18%。
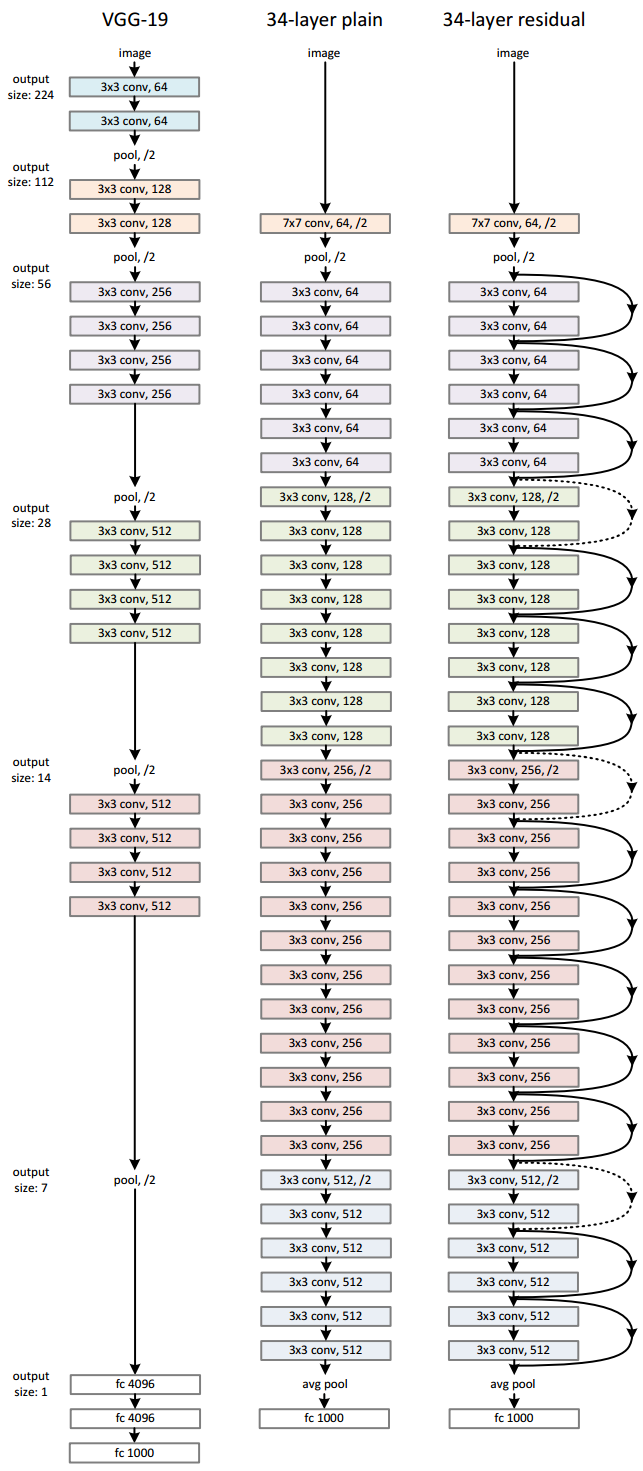
图3 针对ImageNet的网络架构样例
左:作为对比的VGG-19模型[ 41](196亿FLOPs)
中:含有权重参数的层数为34的平凡网络(36亿FLOPs)
右:含有权重参数的层数为34的残差网络(36亿FLOPs)
点画线所标记的捷径上作了升维操作。表1中展示了更多的细节和其他变量
残差网络。基于上述的平凡网络,我们增加了一些捷径连接(见图3,右图)后,则将网络转化为与之对应的残差版网络。当网络的输入维度和输出维度相等时可以直接应用公式(1)所示的恒等捷径(图3中的实线捷径)。当维数增加时(图3中的点画线捷径),我们考虑了两种策略:(A)捷径依然采用恒等映射,对于维数增加带来的空缺元素补零,这种策略将引入新的参数;(B)利用公式(2)所示的投影捷径来匹配维数(通过1×1的卷积层实现)。对于这两种策略,当捷径连接了两个尺寸的特征图时,它们将依步长2进行排布。
3.4 实现
我们针对ImageNet数据集的实现是根据[21, 41]的实践来实现的。图片按其短边作等比缩放后按照[256,480]区间的尺寸随机采样进行尺度增强[41]。随机的从图像或其水平镜像采样大小为224×224的剪裁图像,并将剪裁结果减去像素均值[21]。进行标准色彩增强[21]。我们使用了批量正规化(Batch Normalization, BN)[16]。我们按照文献[13]初始化网络权重,分别从零开始训练平凡网络和残差网络。我们所采用的SGD的最小批量大小为256。学习速率被初始化为0.1,并且在每次遇到错误率平台区时除以10,对各模型都迭代60万次进行训练。我们使用了权值衰减惩罚技术,其速率参数设为0.0001,冲量参数设为0.9。参考文献[16]的实践结果,我们并没有使用dropout技术[14]。
在测试时,为了对结果作对比我们采用了标准的10折测试[21]。为了获得最佳的结果,我们采用了文献[41, 13]所使用的全连接卷积形式的网络,最终结果为对多个尺寸图像(图像分别等比缩放为短边长度{224,256,384,480,640})的实验结果得分取平均值。
4 实验
4.1 ImageNet分类数据集
我们利用包括了1000个分类的ImageNet 2012分类数据集[36]对我们的方法进行验证。各模型均利用128万幅训练图像进行训练,再利用5万幅交叉验证图像进行评估。我们用10万幅测试图像得到最终结果,最终结果是由测试服务器报告的。我们还分别验证了第1和前5的错误率。
平凡网络。我们首先对18层和34层的平凡网络进行验证。34层的平凡网络如图3(中图)所示,18层的平凡网络则与其形式类似。表1中给出了网络架构的细节。
表2中的结果表明了较深的34层平凡网络的交叉验证错误率要高于较浅的18层平凡网络。为了揭示其原因,在图4(左图)中我们比较了训练过程中训练错误和交叉验证错误的变化情况。我们观察到了退化问题——在整个的训练过程中,34层的平凡网络的训练误差较高,尽管18层平凡网络仅仅是34层平凡网络的一部分。
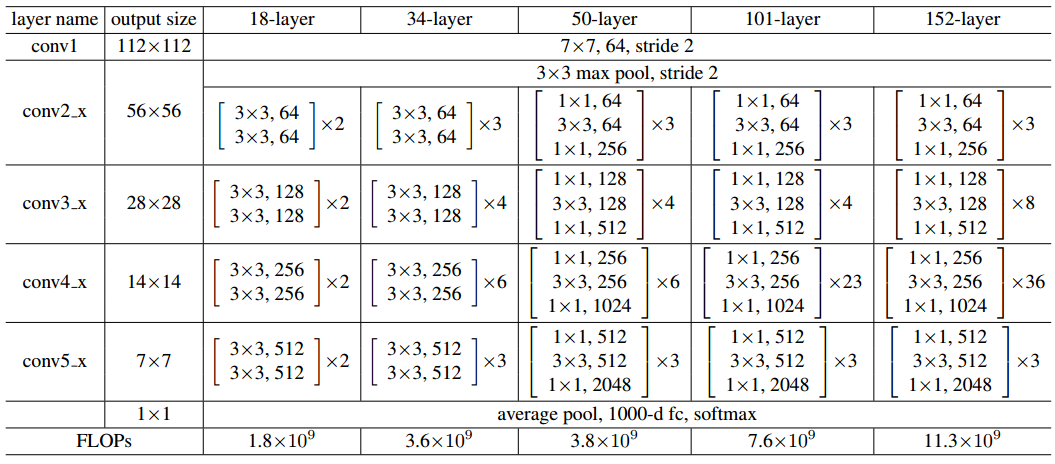
表1 针对ImageNet的架构
工作块的配置见方括号中(亦可见于图5),几种类型的块堆叠起来构成网络架构。降采样采用的是步长为2的conv3_1,conv4_1和conv5_1
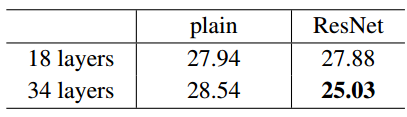
表2 对ImageNet数据集作交叉验证时的最大错误率(%,10折测试)
此处的残差网络没有在其对应的平凡网络中引入新的参数变量,图4展示了训练过程
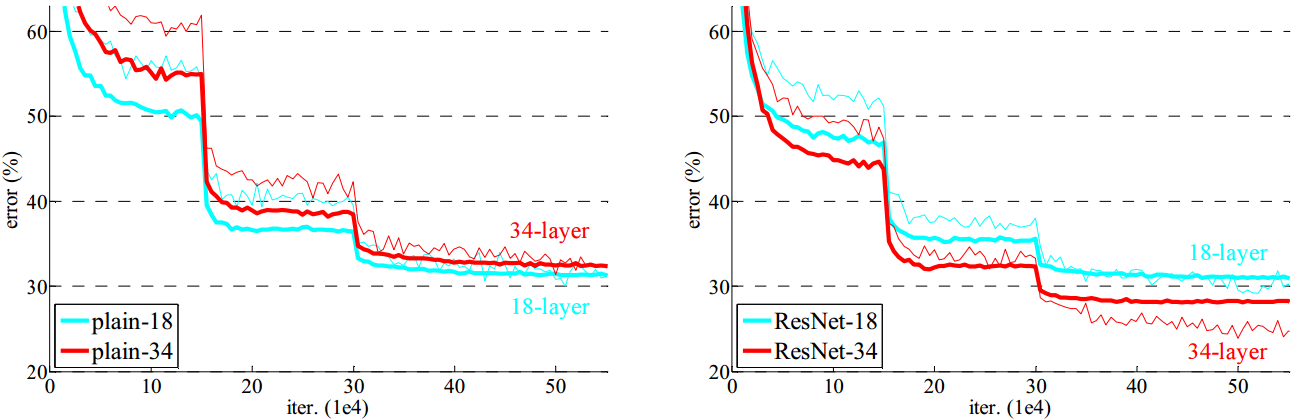
图4 用ImageNet数据集进行训练
细线指明了训练误差的变化情况,粗线则指明了交叉验证错误率的变化情况
左图:18层和34层平凡网络的情况
右图:18层和34层残差网络的情况
在本图中,残差网络没有在其对应的平凡网络中引入新的参数变量
我们认为这种模型优化困难不大可能是由于梯度消失造成的。这些平凡网络的训练是基于BN[16]的,这保证了前向传播信号的变异系数不为零值。同时,我们确认了在BN求解时的反向传播过程中的梯度值是正常的。即无论是前向传播还是反向传播过程中的信号都没有出现梯度消失的现象。事实上,34层的平凡网络仍然可以获得有竞争力的精度值(见表3),这某种意义上表明这个方法是可行的。我们猜测深度平凡网络可能潜在的具有较低的收敛速率,而这不利于训练误差的降低。未来还将进一步探究这种优化困难的原因。
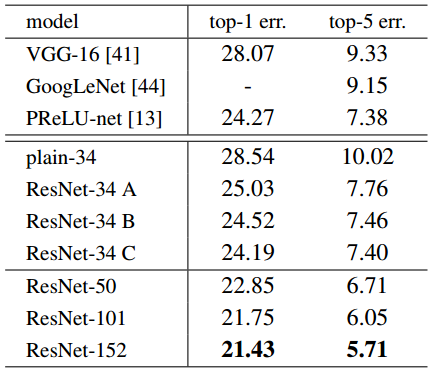
表3 对ImageNet数据集进行交叉验证时的错误率(%,10折测试)
VGG-16是基于我们的测试。ResNet-50/101/152测试采用B方法仅适用投影法来增加维数
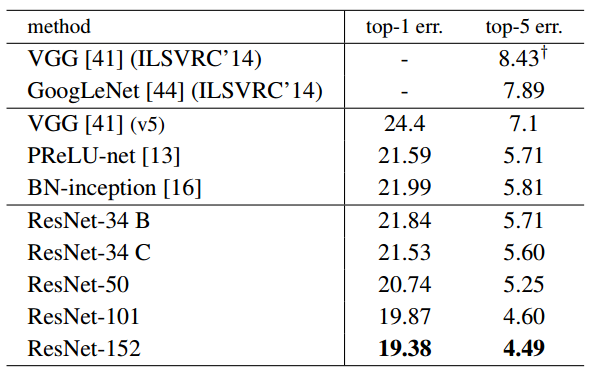
表4 单个模型对ImageNet数据集进行交叉验证时结果的错误率(%)(除了带有标记的那个是对于测试集的)
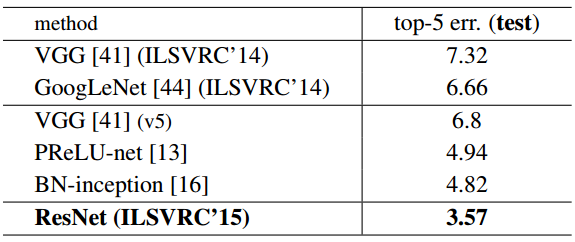
表5 组合模型的错误率(%)
前5的错误率是由测试服务器汇报的对于ImageNet测试集的
残差网络。现在我们来验证18层和34层的残差网络(Residual Nets, ResNets)。残差网络的基本结构和上述的平凡网络是相同的,除了在每对3×3的过滤器间增加了捷径连接(图3(右图))。在第一个对比中(表2和图4(右图)),我们在所有的捷径使用恒等映射并且对多出的维度补零(方案A),因此相对所基于的平凡网络并没有引入新的参数。
针对表2和图4,我们有3个主要的观察。首先,在使用残差学习方法时情况发生了好转——34层的残差网络的效果优于18层的残差网络(提高了约2.8%)。更重要的是,34层的残差网络的训练误差对于交叉验证数据具有泛化能力。这表明退化问题在这种情况下被较好的控制了,即我们能够在增加网络深度时获得更高的准确率。
其二,相比于所基于的平凡网络,34层的残差网络降低了约3.5%的最大错误率(见表2),这是得益于训练误差的成功降低(对比图4(右图)和图4(左图))。这个对比证实了残差学习对于深度学习系统是有效的。
最后,我们认为18层的平凡和残差网络的准确度是接近的(见表2),然而18层的残差网路的收敛速度更快一些(对比图4中的右图和左图) 。当网络不是“太深”时(这里是18层),现有的SGD求解方法仍然可以在平凡网络上得到一个较好的结果。在这种情形下,残差网络通过使得加快了在训练初期的收敛速度方便了模型的优化。
恒等快捷连接(identity shortcut)和投影快捷连接(projection shortcut)的对比。我们已经展示了无需参数的恒等映射快捷连接是有助于训练的。下面我们看一下投影快捷连接(公式(2))。在表3中我们对比了三个方案:(A)利用补零快捷连接进行升维,所有快捷连接都无需参数(和表2及图4(右图)一样);(B)用投影快捷连接进行升维,同时其他快捷连接采用恒等映射;(C)所有的快捷连接均为投影连接。
表3展示了3种方案均优于平凡网络,B略优于A。我们认为这是由于A方案中的补零方法所获得的维数并没有残差学习。方案C较多的优于方案B,我们认为这是由于投影快捷连接中额外引入的若干参数(30个)导致的。然而,方案A、B、C见的差异不大也表明了投影快捷连接并不是解决退化问题的关键。因此,为了降低存储和时间复杂度以及模型大小,我们在后文中并没有采用方案C。恒等快捷方式对于不增加下文将介绍的瓶颈架构复杂度尤为重要。
深度瓶颈架构。我们接下来将描述我们针对ImageNet数据集而涉及的深度学习网络。因为我们需要考虑到我们能够接受的训练时间,我们将单元块的设计改为了所谓瓶颈式的设计[4]。对于每个残差函数F,我们采用3个网络层来对其进行描述(如图5),3个网络层次分别为1×1,3×3和1×1的卷积层,这里11的层是用来减少或增加(恢复)维度的,这使得那个3×3的层如同瓶颈一般具有较小的输入和输出维度。图5中给出了一个例子,这些设计具有相同的时间复杂度。
无需进行参数调整的恒等快捷连接对于瓶颈架构非常重要。如果将图5(右图)的恒等快捷连接替换为投影快捷连接,可见当快捷连接被连接到两个高维的端点时,时间复杂度和模型尺寸都翻倍了。因此恒等快捷连接使得所设计的瓶颈结构更加有效。
50层的残差网络:我们将34层网络中的每2层一组构成的块替换为这种3层的瓶颈块,得到了一个50层的残差网络(表1)。我们使用方案B来作升维。这个模型的基础计算量为38亿FLOPs。
101层和152层的残差网络:我们利用表1所述的3层块构建101层和152层的残差网络。值得一提的是,尽管网络深度增加了很多,152层的残差网络(113亿FLOPs)比VGG-16/19网络(153/196亿FLOPs)的时间复杂度更低。
50/101/152层的残差网络比34层的残差网络的准确度有显著提高(见表3和表4)。我们没有观察到退化问题并且随着网络的加深取得了明显的准确率增长。由表3和表4可以观察到由深度增加带来的各方面好处。
与先进方法的对比。在表4中我们已经与当前最好的单模型结果进行了比较。我们采用的34层基准残差网络获得了具有竞争力的准确度。我们的152层单模型残差网络对于前五的验证错误为4.49%。这个单模型结果超过了所有先前的综合模型获得的结果(见表5)。我们组合了6个不同深度的模型组成一个综合模型(在模型提交时仅使用了两个152层),对于表5所示的测试集获得了3.57%的前五错误率。这个结果获得了ILSVRC 2015的第一名。
4.2 对CIFAR-10数据集的结果和分析
我们对CIFAR-10数据集[20]进行了进一步的研究,它包括了分为10类的5万的训练图像和1万的测试图像。我们展示了利用训练集进行训练和利用测试集进行验证的实验。我们所针对的极深网络的行为,而不是推进最先进方法的结果,因此我们主要是使用下述的简单网络架构。
简单和残差网络结构遵从图3(中图和右图)。这个网络的输入为32×32的图像,每个图像的数据都减去了像素均值。第一层是一个3×3的卷积层。然后我们对于尺寸分别为{32, 16, 8}的特征图分别使用一组包括了6n个3×3卷积层,对于每个尺寸的特征图使用2n个层,即过滤器的数量分别为{16, 32, 64}。降采样是通过步长为2的卷积进行的。这个网络终止于一个全局的平均化池,一个10路的全连接层和一个softmax层。以上共计有6n+2层权重层。下表小结了该网络架构:
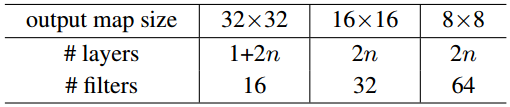
在使用快捷连接的地方,它连接了一组3×3的网络层(总计有3n个快捷连接)。在该数据集上我们对于各情形使用的均是恒等快捷方式(即方案A)。
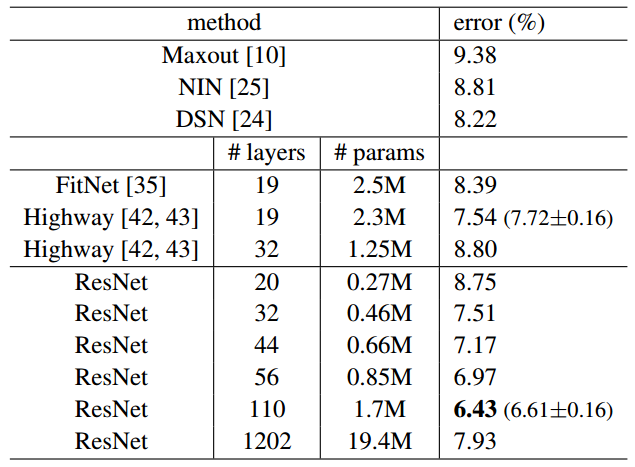
表6 对于CIFAR-10测试集的分类错误
表中方法都进行了数据增强。对于ResNet-110,我们效仿文献[ 43]将算法重复运行了5次,并且展示了所得结果的最优值(最优的mean+std)。
因此我们的残差模型与它所源于的平凡网络具有完全相同的深度、快读和参数数量。
我们使用的权重损失参数为0.0001,冲量参数为0.9,并且我们采用文献[13]的方法初始化权重值和BN[16]方法进行网络训练,但不采用dropout技术。这些模型在2个GPU上以128为单位进行小批量训练。我们设置初始学习率为0.1,在第32k和第48k次迭代时除以10,在64k迭代时种植训练,训练和交叉验证数据集的划分为45k和5k。我们在训练阶段采用了文献[24]提出的简单数据增强策略:每个边填充4像素宽度,并对原图像或其水平翻转图像裁剪尺寸为32×32的图像块。在验证时,我们仅仅通过32×32大小的图像来进行。
我们比较了n={3, 5, 7, 9}的情况,对应的网络结构分别为20层,32层,44层和56层。图6(右图)表明了平凡网络。平凡网络受其深度的影响很大,深度增大时其训练错误也随着增大。这种现象与在对ImageNet数据集(见图4(左图))和MNIST数据集(参见文献[42])测试时的现象类似,这表明了优化难度是一个根本性的问题。
图6(中图)展示了残差网络的表现,也和对ImageNet数据集的案例情形类似(图4(右图)),我们的残差网络成功克服了优化难度问题,并展示了随着深度的增加准确度也跟着增加。
我们进一步研究当n=18时对应的110层残差网络。在这个情形下,我们发现初始学习速率设置为0.1对于网络收敛而言有些过大了。因此我们采用0.01的初始学习速率来进行热身学习直到训练错误低于80%(大约400次迭代以后),然后回到0.1的学习速率继续训练。其余的训练方案和前文类似。这个110层的网络很好的收敛了(图6(中图))。它的参数数量要少于诸如FitNet[35]和Highway[42]等其他较深的网络或较浅的网络(表6),然而其结果不亚于先进算法的结果(为6.43%,见表6)。
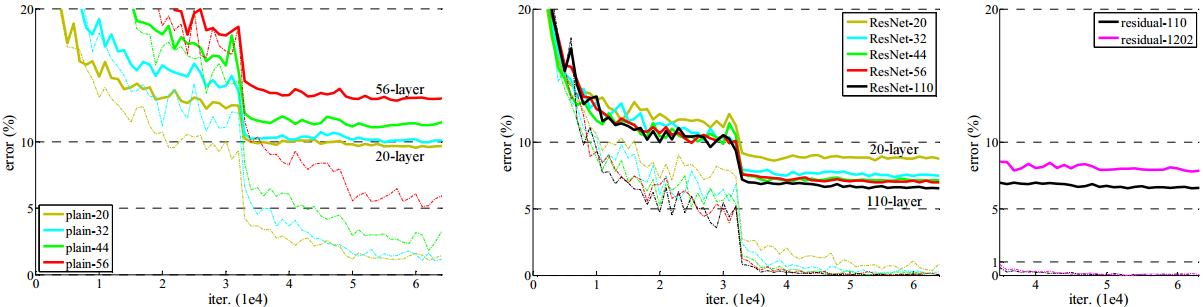
图6 对CIFAR-10数据集进行训练
点画线表示训练误差,粗线表示测试误差
左图:平凡网络。110层的平凡网络的错误率超过60%因此并未展示
中图:残差网络
右图:具有110层和1202层的残差网络
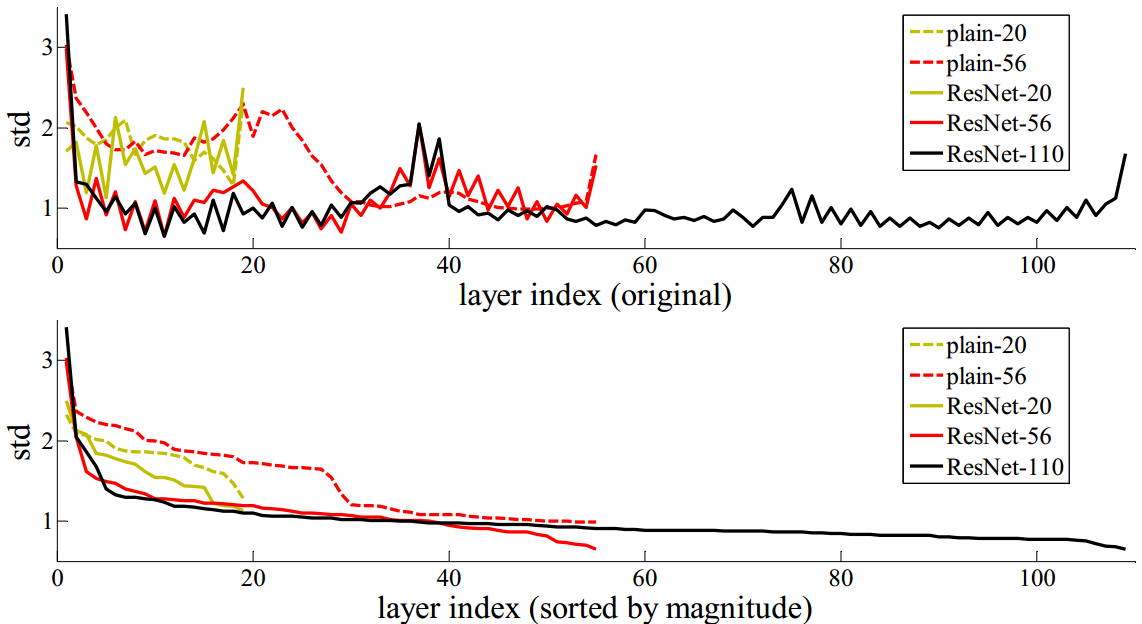
图7 对CIFAR-10的层响应标准差(std)
这些响应是3×3层的输出,在BN和非线性化之前
上图:各层按照原始次序展示
下图:响应按照降续排列
网络层响应分析。图7展示了层响应的标准差(std)。响应是指的每个3×3层的输出值,在BN之后以及其他非线性层(ReLU/addition)之前。对于残差网络而言,分析结果表示出了残差函数的响应强度的变化情况。图7展示了残差网络通常比其它所对应的平凡网络具有较小的响应。这些结果支持了我们的原始动机(见本文3.1节),即残差函数一般可能比非残差函数更接近于零值。同时,我们通过对于图7中20层、56层和110层残差网络数据的比较,也注意到层次较深的残差网络的响应值较小。也就是说,层次越多,则残差网络中的每个层次对于信号的改变越小。
超过1000层网络的探索。我们探索了一个超深的超过1000层的深度学习模型。这里我们设置n=200即网络层数为1202层,训练过程如上所述。我们的方法表明没有出现优化困难,利用这个千层的网络得到了小于0.1%(图6(右图))的训练误差。而测试误差也相当不错(为7.93%,见表6)。
然而,对于这种超深的网络还是存在一些未决的问题。对于1202层网络的测试结果要劣于110层网络的测试结果,尽管两者的训练误差是相仿的。我们认为这是由于过拟合造成。1202层的网络相对于它的数据集尺寸来说可能大(19.4M)的有点没有必要了。诸如maxout[10]和dropout[14]等强力的正则化方法通常被用来对于这个数据集获取最优的结果([10, 25, 24, 35])。在本文中,我们并未采用maxout/dropout,设计上而言是为了仅通过增大或减少网络结构的深度来引入正则化,且不偏离所针对的优化困难的问题。然而结合更强的正则化方法对结果进一步改善,我们将在未来研究。
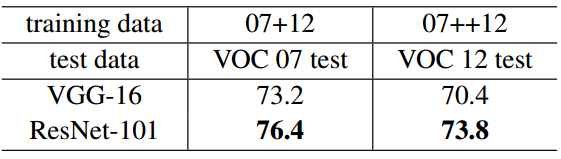
表7 利用基线方法Faster R-CNN对于PASCAL VOC物品检测数据集的mAP(%)
更好的结果见表10和表11

表8 利用基线方法Faster R-CNN对于COCO验证数据集的mAP(%)
更好的结果见表9
4.3 对于PASCAL和MS COCO数据集的物品识别
我们的方法对于其他识别任务具有很好的性能泛化能力。表7和表8展示了对2007年和2012年的PASCAL VOC数据集[5]和COCO数据集[26]的基线结果。我们用Faster R-CNN[32]作为检测方法。这里我们所感兴趣的是在将VGG-16[41]替换为ResNet-101后所带来的性能改善情况。两种检测模型的实现(见附件)类似,因此增益只能是由于网络结构的改良引入。值得注意的是,在对于COCO数据集进行挑战是我们获得的结果比COCO标准测试(mAP@[.5, .95]提升了6.0%,相对提升量达28%,这个增益仅仅是由于学习到的表示。
基于深度残差网络,我们在2015年ILSVRC & COCO比赛中获得了若干个第一名:ImageNet物品检测数据集,ImageNet位置定位数据集,COCO物品检测数据集和COCO图像分割数据集。详细结果参见附件。
参考文献
[1] Y. Bengio, P. Simard, and P. Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on NeuralNetworks, 5(2):157–166, 1994.
[2] C. M. Bishop. Neural networks for pattern recognition. Oxforduniversity press, 1995.
[3] W. L. Briggs, S. F. McCormick, et al. A Multigrid Tutorial. Siam,2000.
[4] K. Chatfield, V. Lempitsky, A. Vedaldi, and A. Zisserman. The devilis in the details: an evaluation of recent feature encoding methods.In BMVC, 2011.
[5] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The Pascal Visual Object Classes (VOC) Challenge. IJCV,pages 303–338, 2010.
[6] S. Gidaris and N. Komodakis. Object detection via a multi-region &semantic segmentation-aware cnn model. In ICCV, 2015.
[7] R. Girshick. Fast R-CNN. In ICCV, 2015.
[8] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. InCVPR, 2014.
[9] X. Glorot and Y. Bengio. Understanding the difficulty of trainingdeep feedforward neural networks. In AISTATS, 2010.
[10] I. J. Goodfellow, D. Warde-Farley, M. Mirza, A. Courville, andY. Bengio. Maxout networks. arXiv:1302.4389, 2013.
[11] K. He and J. Sun. Convolutional neural networks at constrained timecost. In CVPR, 2015.
[12] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deepconvolutional networks for visual recognition. In ECCV, 2014.
[13] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers:Surpassing human-level performance on imagenet classification. InICCV, 2015.
[14] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, andR. R. Salakhutdinov. Improving neural networks by preventing coadaptation of feature detectors. arXiv:1207.0580, 2012.
[15] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neuralcomputation, 9(8):1735–1780, 1997.
[16] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deepnetwork training by reducing internal covariate shift. In ICML, 2015.
[17] H. Jegou, M. Douze, and C. Schmid. Product quantization for nearestneighbor search. TPAMI, 33, 2011.
[18] H. Jegou, F. Perronnin, M. Douze, J. Sanchez, P. Perez, andC. Schmid. Aggregating local image descriptors into compact codes.TPAMI, 2012.
[19] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick,S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture forfast feature embedding. arXiv:1408.5093, 2014.
[20] A. Krizhevsky. Learning multiple layers of features from tiny images. Tech Report, 2009.
[21] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classificationwith deep convolutional neural networks. In NIPS, 2012.
[22] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard,W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural computation, 1989.
[23] Y. LeCun, L. Bottou, G. B. Orr, and K.-R. Muller. Efficient backprop. ¨In Neural Networks: Tricks of the Trade, pages 9–50. Springer, 1998.
[24] C.-Y. Lee, S. Xie, P. Gallagher, Z. Zhang, and Z. Tu. Deeplysupervised nets. arXiv:1409.5185, 2014.
[25] M. Lin, Q. Chen, and S. Yan. Network in network. arXiv:1312.4400,2013.
[26] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan,P. Dollar, and C. L. Zitnick. Microsoft COCO: Common objects in ′context. In ECCV. 2014.
[27] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networksfor semantic segmentation. In CVPR, 2015.
[28] G. Montufar, R. Pascanu, K. Cho, and Y. Bengio. On the number of ′linear regions of deep neural networks. In NIPS, 2014.
[29] V. Nair and G. E. Hinton. Rectified linear units improve restrictedboltzmann machines. In ICML, 2010.
[30] F. Perronnin and C. Dance. Fisher kernels on visual vocabularies forimage categorization. In CVPR, 2007.
[31] T. Raiko, H. Valpola, and Y. LeCun. Deep learning made easier bylinear transformations in perceptrons. In AISTATS, 2012.
[32] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towardsreal-time object detection with region proposal networks. In NIPS,2015.
[33] S. Ren, K. He, R. Girshick, X. Zhang, and J. Sun. Object detectionnetworks on convolutional feature maps. arXiv:1504.06066, 2015.
[34] B. D. Ripley. Pattern recognition and neural networks. Cambridgeuniversity press, 1996.
[35] A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, andY. Bengio. Fitnets: Hints for thin deep nets. In ICLR, 2015.
[36] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma,Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenetlarge scale visual recognition challenge. arXiv:1409.0575, 2014.
[37] A. M. Saxe, J. L. McClelland, and S. Ganguli. Exact solutions tothe nonlinear dynamics of learning in deep linear neural networks.arXiv:1312.6120, 2013.
[38] N. N. Schraudolph. Accelerated gradient descent by factor-centeringdecomposition. Technical report, 1998.
[39] N. N. Schraudolph. Centering neural network gradient factors. InNeural Networks: Tricks of the Trade, pages 207–226. Springer,1998.
[40] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization and detectionusing convolutional networks. In ICLR, 2014.
[41] K. Simonyan and A. Zisserman. Very deep convolutional networksfor large-scale image recognition. In ICLR, 2015.
[42] R. K. Srivastava, K. Greff, and J. Schmidhuber. Highway networks.arXiv:1505.00387, 2015.
[43] R. K. Srivastava, K. Greff, and J. Schmidhuber. Training very deepnetworks. 1507.06228, 2015.
[44] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In CVPR, 2015.
[45] R. Szeliski. Fast surface interpolation using hierarchical basis functions. TPAMI, 1990.
[46] R. Szeliski. Locally adapted hierarchical basis preconditioning. InSIGGRAPH, 2006.
[47] T. Vatanen, T. Raiko, H. Valpola, and Y. LeCun. Pushing stochastic gradient towards second-order methods–backpropagation learning with transformations in nonlinearities. In Neural InformationProcessing, 2013.
[48] A. Vedaldi and B. Fulkerson. VLFeat: An open and portable libraryof computer vision algorithms, 2008.
[49] W. Venables and B. Ripley. Modern applied statistics with s-plus.1999.
[50] M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional neural networks. In ECCV, 2014.