
机器视觉在行业中的应用
机器视觉的发展背景
- 人工智能
人工智能(Artificial Intelligence, AI)是计算机科学的一个分支,其意在了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。该领域的研究包括机器人、语言识别、机器视觉、自然语言处理和专家系统等。
人工智能是一个比较大的领域,其中包括机器学习、深度学习、模式识别等,而神经网络是机器学习中的一种方法,深度学习又是神经网络方法中的一个子集。

- 机器视觉
机器视觉是人工智能的一个重要分支,其核心是使用“机器眼”来代替人眼。机器视觉系统通过图像/视频采集装置,将采集到的图像/视频输入到视觉算法中进行计算,最终得到人类需要的信息。
机器视觉的主要应用场景
- 人脸识别
人脸识别(Face Recognition)是基于人的面部特征信息进行身份识别的一种生物识别技术。它通过采集含有人脸的图片或视频流,并在图片中自动检测和跟踪人脸,进而对检测到的人脸进行面部识别。人脸识别可提供图像或视频中的人脸检测定位、人脸属性识别、人脸比对、活体检测等功能。 - 视频监控分析
视频监控分析是利用机器视觉技术对视频中的特定内容信息进行快速检索、查询、分析的技术。由于摄像头的广泛应用,由其产生的视频数据已是一个天文数字,这些数据蕴藏的价值巨大,靠人工根本无法统计,而机器视觉技术的逐步成熟,使得视频分析称为可能。通过这项技术,公安部门可以在海量的监控视频中搜寻到罪犯;在拥有大量流动人群的交通领域,该技术也被广泛应用于人群分析、防控预警等。 - 工业瑕疵检测
机器视觉技术可以快速获取大量信息,并进行自动处理。在自动化生产过程中,人们将机器视觉系统广泛应用于工业瑕疵诊断、工况监视和质量控制等领域。 - 图片识别分析
图片识别指人脸识别之外的静态图片识别,图片识别可应用于多种场景,目前应用比较多的是以图搜图、物体/场景识别、车型识别、人物属性、服装、时尚分析、鉴黄、货架扫描识别、农作物虫害识别等。 - 自动驾驶/驾驶辅助
自动驾驶汽车是一种通过计算机实现无人驾驶的智能汽车,它依靠人工智能、机器视觉、雷达、监控装置和全球定位系统协同合作,让计算机可以在没有任何人类主动操作的情况下,自动安全的操作机动车辆。机器视觉的快速发展促进了自动驾驶技术的成熟,使无人驾驶在未来成为可能。
自动驾驶技术链比较长,主要包含感知阶段、规划阶段和控制阶段三个部分。机器视觉技术主要应用在无人驾驶的感知阶段,其基本原理可概括如下:- 使用机器视觉获取场景中的深度信息,以帮助进行后续的图像语义理解,在自动驾驶中帮助探索可行驶区域和目标障碍物。
- 通过视频预估每一个像素的运动方向和运动速度。
- 对物体进行检测与追踪。在无人驾驶中,检测与追踪的目标主要是各种车辆、行人、非机动车。
- 对于整个场景的理解。最重要的有两点:第一是道路线检测,其次是在道路线检测下更进一步,即场景中的每一个像素都打成标签,这也称为场景分割或场景解析。
- 同步地图构建和定位技术。
- 三维图像视觉
三维图像视觉主要是对三维物体进行识别,其主要应用于三维机器视觉、双目立体视觉、三维重建、三维扫描、三维测绘、三维视觉测量、工业仿真等领域。三维信息相比二维信息,能够更全面、真实的反映客观物体,提供更大的信息量。近年来,三维图像视觉已经成为计算机视觉领域的重要课题,在虚拟现实、文物保护、机械加工、影视特技制作、计算机仿真、服装设计、科研、医学诊断、工程设计、刑事侦查现场痕迹分析、自动在线检测、质量控制、机器人及许多生产过程中得到越来越广泛的应用。 - 医疗影像诊断
医疗数据中有90%以上的数据来自于医疗影像。医疗影像领域拥有孕育深度学习的海量数据,医疗影像诊断可以辅助医生做出判断,提升医生的诊断效率。 - 文字识别
计算机文字识别,俗称光学字符识别(Optical Character Recognition),是利用光学扫描技术将票据、报刊、书籍、文稿及其他印刷品的文字转化为图像信息,再利用文字识别技术将图像信息转换为可以使用的计算机输入技术。 - 图像/视频的生成即设计
人工智能技术不仅可以对现有的图片、视频进行分析、编辑,还可以进行再创造。机器视觉技术可以快速、批量、自动化的进行图片设计,因此其可为企业大幅度节省设计人力成本。
图像识别前置技术
深度学习框架
- Theano
Theano是一个Python库,可用于定义、优化和计算数学表达式,特别是多维数组(numpy.ndarray)。它的诞生是为了执行深度学习中的大规模神经网络算法,从本质上而言,Theano可以被理解为一个数学表达式的编辑器:用符号式语言定义程序员所需的结果,并且Theano可以高效的运行GPU或CPU中。
Theano为之后的深度学习框架的开发奠定了基本的设计方向:以计算图为框架的核心,采用GPU加速计算。 - TensorFlow
TensorFlow可以看作是Theano的后继者,它们拥有相近的设计理念:它们都是基于计算图实现自动微分系统。TensorFlow使用数据流图进行数值计算,图中的节点代表数学运算,图中的边则代表在这些节点之间传递的多维数组(tensor)。 - MXNet
MXNet是亚马逊(Amazon)的李沐带队开发的深度学习框架。它拥有类似于Theano和TensorFlow的数据流图,为多GPU架构提供了良好的配置,有着类似于Lasagne和Blocks的更高级别的模型构建块,并且可以在你想象的任何硬件上运行(包括手机)。
MXNet以其超强的分布式支持,明显的内存、显存优化为人所称道。同样的模型,MXNet往往占用更小的内存和显存,并且在分布式环境下,MXNet展现出了明显优于其他框架的扩展性能。 - Keras
Keras是一个高层神经网络API,由纯Python语言编写而成,并使用TensorFlow、Theano及CNTK作为后端。Keras为支持快速实验而生,能够将想法迅速转换为结果。 - PyTorch
PyTorch是一个Python优先的深度学习框架,能够在强大的GPU加速的基础上实现张量和动态神经网络。 - Caffe
Caffe是基于C++语言编写的深度学习框架,作者是中国人贾杨清,它开放源码,提供了命令行,以及MATLAB和Python接口,清晰、可读性强、容易上手。
Numpy使用详解
Numpy(Numerical Python的简称)是高性能科学计算和数据分析的基础包,其提供了矩阵运算的功能。
- .ndarray:一个具有向量算术运算和复杂广播能力的多维数组对象。
- 用于对数组数据进行快速运算的标准数学函数。
- 用于读写磁盘数据的工具以及用于操作内存映射文件的工具。
- 非常有用的线性代数,傅里叶变换和随机数操作。
- 用于集成C/C++和Fortran代码的工具。
在学习图像识别的过程中,需要将图片转换为矩阵。即将对图片的处理简化Wie向量空间中的向量运算。基于向量运算,可以实现图像的识别。
-
创建数组
#1 Numpy中的array()导入向量 vector = np.array([1, 2, 3, 4]) #2 Numpy中的array()导入矩阵 matrix = np.array([[1, 'Tim'],[2, 'Joey'], [3, 'Johnny'], [4, 'Frank']])
-
创建Numpy数组
#1 通过创建Python列表(list)的方式来创建Numpy矩阵 nparray = np.array([i for i in range(10)]) #2创建数值都为0的向量 a = np.zeros(10) #输出:array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) a.dtype # 输出:dtype('float64') #3 创建的时候强制规定一种类型 np.zeros(10, dtype=int) #4 创建多维矩阵 np.zeros(shape=(3, 4))#代表创建的是3行4列的矩阵并且其数据类型为float64 #5 创建的矩阵的数值都为1 np.ones((3, 4)) #6 创建矩阵,自己指定默认数值 np.full((3, 5), 121) #创建3行5列的矩阵,默认值为121 #7 使用np.arange方法创建Numpy矩阵 np.arange(0, 20, 2) #前闭后开 #8 np.linspace方法(前闭后闭)进行矩阵等分 np.linspace(0, 10, 5) #9 生成随机数矩阵 #9-1 生成长度为10的向量,里面每一个数值都是介于0~10之间的整数。 np.random.randint(0, 10, 10) #9-2 加上参数名size np.random.randint(0, 5, size=5) #前闭后开 #9-3 生成3行5列的整数矩阵 np.random.randint(4, 9, size=(3,5)) #10 seed作用:希望每次生成的随机数都是固定的。 np.random.seed(1) #11 生成介于0~1之间的浮点数的向量或者矩阵 np.random.random(10) #生成0~1之间的浮点数,向量长度为10 np.random.random((2, 4))#生成0~1之间的浮点数,2行4列的矩阵 #12 正态分布 np.random.normal(loc=0, scale=1, size=shape)#表示生成一个正态分布,loc=0,说明以Y轴为对称轴的正态分布。scale正态分布的标准差,对应分布的宽度,scale越大,正态分布的曲线越矮胖,scale越小,曲线的宽度越高瘦。size(int或者整数元组)输出的值赋在shape里,默认为None。
-
获取Numpy属性
a = np.arange(15).reshape(3,5) print(a.shape) print(a.ndim) a.reshape(15, -1) #关心的是只要15行,列由计算机自己来算 a.reshape(-1, 15) #关心的是是要 15列,行由计算机自己来算
-
Numpy数组索引
#Numpy支持类似list的定位操作 matrix = np.array([[1, 2, 3], [20, 30, 40]]) print(matrix[0,1]
-
切片
matrix = np.array([[5, 10, 15], [20, 25, 30], [35, 40, 45]]) print(matrix[:, 1]) print(matrix[:, 0:2]) print(matrix[1:3, :]) print(matrix[1:3, 0:2])
-
Numpy中的矩阵运算
myones = np.ones([3, 3]) myeye = np.eye(3) #生成一个对角线的值为1,其余值都为0的三行三列矩阵 print(myeye) print(myones-myeye)
#1 矩阵之间的点乘 #矩阵真正的乘法必须满足第一个矩阵的列数等于第二个矩阵的行数,矩阵乘法的函数为dot。 mymatrix = np.array([[1, 2, 3], [4, 5, 6]]) a = np.array([[1, 2], [3, 4], [5, 6]]) print(mymatrix.shape[1] == a.shape[0]) print(mymatrix.dot(a)) #2 矩阵的转置是指将原来矩阵中的行变为列。 b = np.array([[1, 2, 3], [4, 5, 6]]) print(b.T) #3 矩阵的逆 #首先导入numpy.linalg,再用linalg的inv函数来求逆,矩阵求逆的条件是矩阵的行数和列数必须是相同的。 import numpy.linalg as lg A = np.array([[0, 1], [2, 3]]) invA = lg.inv(A) print(invA) print(A.dot(invA))
-
数据类型转换
Numpy ndarray数据类型可以通过参数dtype进行设定,而且还可以使用参数astype来转换类型,在处理文件时该参数会很实用。注意,astype调用会返回一个新的数组,也就是原始数据的备份。#将String转换成float vector = np.array(['1', '2', '3']) vector = vector.astype(float)
-
Numpy的统计计算方法
-
sum():计算矩阵元素的和;矩阵的计算结果为一个一维数组,需要指定行或者列。
-
mean():计算矩阵元素的平均值;矩阵的计算结果为一个一维数组,需要指定行或者列。
-
max():计算矩阵元素的最大值;矩阵的计算结果为一个一维数组,需要指定行或者列。
-
mean():计算矩阵元素的平均值。
-
median():计算矩阵元素中的中位数。
vector = np.array([5, 10, 15, 20]) vector.sum() matrix = np.array([[5, 10, 15], [20, 25, 30], [35, 40, 45]]) matrix.sum(axis=1) matrix.sum(axis=0)
-
-
Numpy 中的arg运算
#argmax函数是用来求一个array中最大值的下标。 index1 = np.argmax([1, 2, 6, 3, 2]) #argmin函数用于求一个array中最小值的下标。 index2 = np.argmin([1, 2, 6, 3, 2]) #矩阵的排序和索引 x = np.arange(15) print(x) np.random.shuffle(x)#随机打乱 print(x) sx = np.argsort(x)#从小到大排序,返回索引值 print(sx)
-
FancyIndexing
x = np.arange(15) ind = [3, 5, 8] print(x[ind]) #返回第3,5,8个元素 #从以维向量中构成新的维矩阵 np.random.shuffle(x) ind = np.array([[0, 2], [1, 3]]) #第一行需要取x向量中索引为0的像素,以及索引为2的元素; #第二行需要取x向量中索引为1的元素以及索引为3的元素。 print(x) print(x[ind]) #二维矩阵中,使用fancyindexing取数。 y = np.arange(16) Y = y.reshape(4, -1) row = np.array([0, 1, 2]) col = np.array([1, 2, 3]) print(Y[row, col])#相当于取三个点,分别是(0,1),(1, 2),(2, 3) print(Y[1:3, col])#相当于取第2,3行,以及需要的列
-
Numpy的数组比较
matrix = np.array([[5, 10, 15], [20, 25, 30], [35, 40, 45]]) m = (matrix == 25) print(m) second_column_25 = (matrix[:, 1] == 25) print(second_column_25) print(matrix[second_column_25, :]) vector = np.array([5, 10, 11, 12]) equal_to_five_and_ten = (vector == 5) & (vector == 10) print(equal_to_five_and_ten) equal_to_five_or_ten = (vector == 5) | (vector == 10) print(equal_to_five_or_ten) #计算小于等于3的元素个数 np.count_nonzero(x <= 3) #只要x中有一个元素等于0就返回True np.any(x == 0) #x中所有的元素都大于0才返回True np.all(x > 0)
图像分类值KNN算法
KNN的理论基础与实现
-
KNN算法的核心思想及距离度量
KNN最近邻算法,即找到最近的k个邻居,在前k个最近样本(k近邻)中选择最近的占比最高的类别作为预测类别。- 给定测试对象,计算它与训练集中每个对象的距离。
- 圈定距离最近的k个训练对象,作为测试对象的邻居。
- 根据这k个近邻对象所属的类别,找到占比最高的那个类别作为测试对象的预测类别。
在KNN算法中,有两个方面的因素会影响KNN算法的准确度:
-
一个是计算测试对象与训练集中各个对象的距离;
对于距离度量,一般使用两种比较常见的距离公式计算距离:曼哈顿距离和欧氏距离。

-
另一个因素就是k的选择。
-
KNN算法实现
import numpy as np import matplotlib.pyplot as plt import operator # 给出训练数据以及对应的类别 def createDataSet(): group = np.array([[1.0, 2.0], [1.2, 0.1], [0.1, 1.4], [0.3, 3.5], [1.1, 1.0], [0.5, 1.5]]) labels = np.array(['A', 'A', 'B', 'B', 'A', 'B']) return group, labels def kNN_classify(k, dis, X_train, x_train, Y_test): assert dis == 'E' or dis == 'M', 'dis must E or M, E代表欧式距离,M代表曼哈顿距离' num_test = Y_test.shape[0] # 测试样本的数量 labellist = [] # 使用欧拉距离作为距离度量 if (dis == 'E'): for i in range(num_test): # 实现欧拉距离 distances = np.sqrt(np.sum(((X_train - np.tile(Y_test[i], (X_train.shape[0], 1))) ** 2), axis=1)) nearest_k = np.argsort(distances) # 距离由小到大进行排序,并返回index值 topK = nearest_k[:k] # 选取前k个距离 classCount = { } for i in topK: # 统计每个类别的个数 classCount[x_train[i]] = classCount.get(x_train[i], 0) + 1 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) labellist.append(sortedClassCount[0][0]) return np.array(labellist) if __name__ == '__main__': group, labels = createDataSet() plt.scatter(group[labels == 'A', 0], group[labels == 'A', 1], color='r', marker='*') # 对于类别为A的数据集使用红色六角形表示 plt.scatter(group[labels == 'B', 0], group[labels == 'B', 1], color='g', marker='+') # 对于类别为B的数据集使用绿色十字形表示 plt.show() y_test_pred = kNN_classify(1, 'E', group, labels, np.array([[1.0, 2.1], [0.4, 2.0]])) print(y_test_pred) #输出['A' 'B']

图像分类识别
- 图像分类
所谓的图像分类问题就是将已有的固定的分类标签集合中最合适的标签分配给输入的图像。图像分类的任务就是预测一个给定图像包含了哪个分类标签(或者给出属于一系列不同标签的可能性)。 - 图像预处理
图像预处理不仅可以使得原始图像符合某种既定规则以便于进行后续的处理,而且可以帮助去除图像中的噪声。数据预处理还可以帮助减少后续的运算量以及加速收敛。常用的图像预处理操作包括归一化、灰度变换、滤波变换以及各种形态学变换等,随着深度学习技术的发展,一些预处理方式已经融合到深度学习模型中。
归一化可用于保证所有维度上的数据都在一个变化幅度上。通常可以使用两种方法来实现归一化:- 最值归一化,比如将最大值归一化为1,最小值归一化成-1;或者将最大值归一化成1,最小值归一化成0.
- 均值方差归一化,一般是将均值归一化成0,方差归一化成1。
KNN实战
-
KNN实现MNIST数据分类
#1.KNN实现MNIST数据分类 import torch from torch.utils.data import DataLoader import torchvision.datasets as dsets import torchvision.transforms as transforms batch_size = 100 #MNIST dataset trian_dataset = dsets.MNIST(root='../pymnist',#选择数据根目录 train=True,#选择训练集 transform=None,#不考虑使用任何数据预处理 download=True)#从网络上下载图片 test_dataset = dsets.MNIST(root='../pymnist',train=False, transform=None, download=True) #加载数据 train_loader = torch.utils.data.DataLoader(dataset=trian_dataset, batch_size=batch_size, shuffle=True) #将数据打乱 test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True) print('train_data:', trian_dataset.train_data.size()) print('train_labels:', train_dataset.train_labels.size()) print('test_data:', test_dataset.test_data.size()) print('test_labels:', test_dataset.test_labels.size()) #可视化处理 import matplotlib.pyplot as plt digit = trian_loader.dataset.train_data[0]#取第一个图片的数据 plt.imshow(digit, cmap=plt.cm.binary) plt.show() print(train_loader.dataset.train_labels[0])#输出对应的标签 #2.KNN实现MNIST数字分类 #两张图片使用L1距离来进行比较,逐个像素求查值,然后将所有差值加起来得到一个数值。如果两张图片一模一样,那么L1距离为0,但是如果两张图片差别很大,那么,L1de值将会非常大。 #3.验证KNN在MNIST上的效果 if __name__ == '__main__': X_train = train_loader.dataset.train_data.numpy()#需要转为numpy矩阵 mean_image = getXmean(X_train) X_train = centralized(X_train, mean_image) #X_trian = X_train.reshape(X_train.shape[0], 28*28)#需要reshape之后才能放入knn分类器 y_train = train_loader.dataset.train_labels.numpy() X_test = test_loader.dataset.test_data[:1000].numpy() X_test = X_test.reshape(X_test.shape[0], 28*28) X_test = centralized(X_test, mean_image) y_test = test_loader.dataset.test_labels[:1000].numpy() num_test = y_test.shape[0] y_test_pred = kNN_classify(5, 'M', X_train, y_train, X_test) num_correct = np.sum(y_test_pred == y_test) accuracy = float(num_correct) / num_test print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy)) #显示结果 import matplotlib.pyplot as plt mean_image = getXmean(X_train) cdata = centralized(test_loader.data.test_data.numpy(), mean_image) centralized(test_loader.dataset.test_data.numpy(), mean_image) cdata = cdata.reshape(cdata.shape[0], 28, 28) plt.imshow(cdata[0], cmap=plt.cm.binary) plt.show() print(test_loader.dataset.test_labels[0]) #4.KNN代码整合 def fit(self, X_train, y_train):#X_train代表的是训练数据集,而y_train代表的是对应训练集数据的标签 self.Xtr = X_train self.ytr = y_train def predict(self, k, dis, X_test): assert dis == 'E' or dis == 'M', 'dis must E or M' num_test = X_test.shape[0] #测试样本的数量 labellist = [] #使用欧拉公式作为距离度量 if (dis=='E'): for i in range(num_test): distances = np.sqrt(np.sum(((self.Xtr - np.title(X_test[i], (self.Xtr.shape[0], 1))) ** 2), axis=1)) nearest_k = np.argsort(distances) topK = nearest_k[:k] classCount = { } for i in topK: classCount[self.ytr[i]] = classCount.get(self.ytr[i], 0) + 1 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) labellist.append(sortedClassCount[0][0]) return np.array(labellist) -
KNN实现Cifar10数据分类
#1.cifar10数据集 import torch from torch.utils.data import DataLoader import torchvision.datasets as dsets batch_size = 100 #cifar10 dataset train_dataset = dsets.CIFAR10(root='../pycifar', train=True, download=True) test_dataset = dsets.CIFAR10(root='../pycifar', train=False, download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') digit = train_loader.dataset.train_data[0] import matplotlib.pyplot as plt plt.imshow(digit, cmap=plt.cm.binary) plt.show() print(classes[train_loader.dataset.trian_labels[0]]) #KNN在cifar10上的效果 def getXmean(X_train): X_train = np.reshape(X_train, (X_train.shape[0], -1)) mean_image = np.mean(X_train, axis=0)#求出训练集中所有图片每个像素位置上的平均值 return mean_image def centralized(X_test, mean_image): X_test = np.reshape(X_test, (X_test.shape[0], -1))#将图片从二维展开为一维 X_test = X_test.astype(np.float) X_test -= mean_image #减去均值图像,实现零均值 return X_test X_train = train_loader.dataset.train_data mean_image = getXmean(X_train) X_train = centralized(X_train, mean_image) y_trian = train_loader.dataset.train_labels X_test = test_loader.dataset.test_data[:100] X_test = centralized(X_test, mean_image) y_test = test_loader.dataset.test_labels[:100] num_test = len(y_test) y_test_pred = kNN_classify(6, 'M', X_train, y_train, X_test) num_correct = np.sum(y_test_pred == y_test) accuracy = float(num_correct) / num_test print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
模型参数调优
- 方法一,选择整个数据集进行测试。
- 方法二,将整个数据集拆分成训练集和测试集,然后在测试集中选择合适的超参数。
- 方法三,将整个数据集拆分成训练集、验证集和测试集,然后在验证集中选择合适的超参数,最后在测试集上进行测试。
- 方法四,使用交叉验证,将数据分成若干份,将其中的各份作为验证集之后给出平均准确率,最后将评估得到的合适的超参数在测试集中进行测试。
使用方法四做测试。
class Knn:
def __init__(self):
pass
def fit(self, X_train, y_train):
self.Xtr = X_train
self.ytr = y_train
def predict(self, k, dis, X_test):
assert dis == 'E' or dis == 'M', 'dis must E or M'
num_test = X_test.shape[0]
labellist = []
if (dis == 'E'):
for i in range(num_test):
distances = np.sqrt(np.sum(((self.Xtr - np.title(X_test[i], (self.Xtr.shape[0], 1))) ** 2), axis=1))
nearest_k = np.argsort(distances)
topK = nearest_k[:k]
classCount = {
}
for i in topK:
classCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
labellist.append(sortedClassCount[0][0])
return np.array(labellist)
if(dis = 'M'):
for i in range(num_test):
distances = np.sum(np.abs(self.Xtr - np.tile(X_test[i], (self.Xtr.shape[0], 1))), axis=1)
nearest_k = np.argsort(distances)
topK = nearest_k[:k]
classCount = {
}
for i in topK:
classCount[self.ytr[i]] = classCount.get(self.ytr[i], 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
labellist.append(sortedClassCount[0][0])
return np.array(labellist)
X_train = train_loader.datset.train_data
X_train = X_train.reshape(X_train.shape[0], -1)
mean_image = getXmean(X_train)
X_train = centralized(X_train, mean_image)
y_train = train_loader.dataset.train_labels
y_train = np.array(y_train)
X_test = test_loader.dataset.test_data
X_test = X_test.reshape(X_test.shape[0], -1)
X_test = centralized(X_test, mean_image)
y_test = test_loader.dataset.test_labels
y_test = np.array(y_test)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20]
num_training = X_train.shape[0]
X_train_folds = []
y_train_folds = []
indices = np.array_split(np.arange(num_training), indices_or_sections=num_folds)
for i in indices:
X_trian_folds.append(X_train[i])
y_train_folds.append(y_train[i])
k_to_accuracies = {
}
for k in k_choices:
acc = []
for i in range(num_folds):
x = X_trian_folds[0:i] + X_train_folds[i+1:]
x = np.concatenate(x, axis=0)
y = y_train_folds[0:i] + y_train_folds[i+1:]
y = np.concatenate(y)
#对label进行同样的操作
test_y = y_train_folds[i]
#单独拿出验证集
test_y = y_train_folds[i]
classifier = Knn()
#定义model
classifier.fit(x, y)
#读入训练集
#dist = classifier.compute_distances_no_loops(test_x)
#计算距离矩阵
y_pred = classsifier.predict(k, 'M', test_x)
#预测结果
accuracy = np.mean(y_pred == test_y)
#计算准去率
acc.append(accuracy)
k_to_accuracies[k] = acc
#计算交叉验证的平均准去率
#输出准确度
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))
#plot the raw observations
import matplotlib.pyplot as plt
for k in k_choices:
accuracies = k_to_accuracies[k]
plt.scatter([k] * len(accuracies), accuracies)
#plot the trend line with error bars that correspond to standard deviation
accuracies_mean = np.array([np.mean(v) for k, v in sorted(k_to_accuracies.items())])
accuracies_std = np.array([np.std(v) for k,v in sorted(k_to_accuracies.items())])
plt.errorbar(k_choices, accuracies_mean, yerr=accuracies_std)
plt.title('Cross-validation on k')
plt.xlabel('k')
plt.ylabel('Cross-validation accuracy')
plt.show()
机器学习基础
线性回归模型
- 线性关系:变量之间的关系是一次函数,也就是说当一个自变量 x x x和因变量 y y y的关系被画出来时呈现的是一条直线,当两个自变量 x 1 x_1 x1, x 2 x_2 x2和因变量 y y y的关系被画出来时呈现的是一个屏幕。反之,如果一个自变量 x x x和因变量 y y y的关系为非线性关系,那么它们的关系被画出来时呈现的是一条曲线,而如果两个自变量 x 1 x_1 x1, x 2 x_2 x2和因变量 y y y的关系为非线性关系时,那么它们的关系被画出来时呈现的就是一个曲面。用数学表达式来解释, y = a × x 1 + b × x 2 + c y=a\times x_1+b\times x_2+c y=a×x1+b×x2+c的自变量和因变量就是线性关系,而 y = x 2 , y = s i n ( x ) y=x_2,y=sin(x) y=x2,y=sin(x)的自变量 和因变量就是非线性关系。
- 回归问题:即预测一个连续问题的数值。
线性回归主要用于处理回归问题,少数情况用于处理分类问题。
-
一元线性回归
一元线性回归是用来描述自变量和因变量都只有一个的情况,且自变量和因变量之间呈线性关系的回归模型,一元线性回归可以表示为 y = a × x + b y=a \times x + b y=a×x+b,其中只有 x x x一个自变量, y y y为因变量, a a a为斜率(有时候也称为 x x x的权重), b b b为截距。-
一元线性回归算法的实现思路
import numpy as np import matplotlib.pyplot as plt if __name__ == '__main__': x = np.array([1, 2, 4, 6, 8]) y = np.array([2, 5, 7, 8, 9]) x_mean = np.mean(x) y_mean = np.mean(y) denominator = 0.0 numerator = 0.0 for x_i, y_i in zip(x, y): numerator += (x_i - x_mean) * (y_i - y_mean) #按照a的公式得到分子 denominator += (x_i - x_mean) ** 2 #按照a的公式得到分母 a = numerator / denominator #得到a b = y_mean - a * x_mean #得到b y_predict = a * x + b plt.scatter(x, y, color='b') plt.plot(x, y_predict, color='r') plt.xlabel('管子的长度', fontproperties='simHei', fontsize=15) plt.ylabel('收费', fontproperties='simHei', fontsize=15) plt.show() -
一元线性回归的算法封装
import numpy as np class SimpleLinearRegressionSelf: def __init__(self): """初始化Simple linear regression模型""" self.a_ = None self.b_ = None def fit(self, x_train, y_train): assert x_train.ndim == 1, '一元线性回归模型仅处理向量,而不能处理矩阵' x_mean = np.mean(x_train) y_mean = np.mean(y_train) denominator = 0.0 numerator = 0.0 for x_i, y_i in zip(x_train, y_train): numerator += (x_i - x_mean) * (y_i - y_mean)#按照a的公式得到分子 denominator += (x_i - x_mean) ** 2 #按照a的公式得到分母 self.a_ = numerator / denominator self.b_ = y_mean - self.a_ * x_mean return self def predict(self, x_test_group): return np.array([self._predict(x_test) for x_test in x_test_group]) #对输入向量集合中的每一个向量都进行一次预测,预测的具体实现被封装在_predict函数中 def _predict(self, x_test): return self.a_ * x_test + self.b_ #求取每一个输入的x_test以得到预测值的具体实现。 def mean_squared_error(self, y_true, y_predict): return np.sum((y_true - y_predict) ** 2) / len(y_true) def r_square(self, y_true, y_predict): return 1 - (self.mean_squared_error(y_true, y_predict) / np.var(y_true)) import numpy as np from book.lr.LinearRegressionSelf import SimpleLinearRegression if __name__ == '__main__': x = np.array([1, 2, 4, 6, 8]) y = np.array([2, 5, 7, 8, 9]) lr = SimpleLinearRegression() #封装模型的类名 lr.fit(x, y) #训练模型得到a和b print(lr.predict([7])) print(lr.r_square([8,9], lr.predict([6,8])))
-
-
多元线性回归
import numpy as np from numpy import linalg class MLinearRegressin: def __init__(self): self.coef_ = None #代表的是权重 self.interception_ = None #代表的是截距 self._theta = None #代表的是权重+截距 #X_train代表的是矩阵X大写,y_train代表的是向量y小写 def fit(self, X_train, y_train): assert X_train.shape[0] == y_train.shape[0],'训练集的矩阵行数与标签的行数保持一致' ones = np.ones((X_train.shape[0], 1)) X_b = np.hstack((ones, X_train)) #将X矩阵转为X_b矩阵,其中第一列为1,其余不变 self._theta = linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train) self.interception_ = self._theta[0] self.coef_ = self._theta[1:] return self def predict(self, X_predict): ones = np.ones((X_predict.shape[0], 1)) X_b = np.hstack((ones, X_predict)) #将X矩阵转为X_b矩阵,其中第一列为1,其余不变。 return X_b.dot(self._theta) #得到的即为预测值 def mean_squared_error(self, y_true, y_predict): return np.sum((y_true - y_predict) ** 2) / len(y_true) def score(self, X_test, y_test):#使用r square y_predict = self.predict(X_test) return 1 - (self.mean_squared_error(y_test, y_predict) / (np.var(y_test)))
逻辑回归模型
逻辑回归模型就是在线性回归的基础上加一个Sigmoid函数对线性回归的结果进行压缩,令其最终预测值在一个范围内。Sigmoid函数的作用就是将一个连续的数值压缩到一定的范围之内,它将最终预测值的范围压缩到0-1之间。虽然逻辑回归也有回归这个词,但由于这里的自变量和因变量呈现的是非线性关系,因此,严格意义上将逻辑回归模型属于非线性模型。逻辑回归模型则通常用来处理二分类问题。在逻辑回归中,计算出的预测值是一个0-1的概率值,通常以0.5为分界线,如果预测的概率值大于0.5则会将最终结果归为1这个类别,如果预测的概率值小于等于0.5则会将最终结果归为0这个类别。
-
Sigmoid函数
p = 1 1 + e − z p = \frac {1}{1 + e^{-z}} p=1+e−z1
z z z是线性回归的方程式, p p p表示计算出来的概率,范围在0-1之间。 -
梯度下降法
梯度下降算法(GradientDescent Optimization)是常用的最优化方法之一,“最优化方法”属于运筹学方法,是指在某些约束条件下,为某些变量选取哪些值,可以使得设定的目标函数达到最优的问题。最优化方法有很多种,常见的有梯度下降法、牛顿法、共轭梯度法,等等。 -
学习率 η \eta η的分析
学习率是一个需要认知调整的参数,过小会导致收敛过慢,而过大又可能会导致模型不收敛。 -
逻辑回归的损失函数
c o s t = − 1 m ∑ i = 1 m ( y i l o g ( s i g m o i d ( x b i ⋅ θ T ) ) + ( 1 − y i ) l o g ( 1 − s i g m o i d ( x b i ⋅ θ T ) ) ) cost = - \frac{1}{m} \sum_{i=1}^{m}(y^ilog(sigmoid(x_b^i \cdot \theta^T))+(1-y^i)log(1-sigmoid(x_b^i \cdot \theta^T))) cost=−m1i=1∑m(yilog(sigmoid(xbi⋅θT))+(1−yi)log(1−sigmoid(xbi⋅θT))) -
Pythn 实现逻辑回归
class LogisticRegression: def __init__(self): """初始化Logistic regression模型""" self.coef_ = None #维度 self.intercept_ = None #截距 self._theta = None def _sigmoid(x): y = 1.0 / (1.0 + np.exp(-x)) return y def fit(self, X_train, y_train, eta=0.01, n_iters=1e4): assert X_train.shape[0] == y_train.shape[0],'训练数据集的长度需要与标签长度保持一致' #计算损失函数 def J(theta, X_b, y): p_predict = self._sigmoid(X_b.dot(theta)) try: return -np.sum(y * np.log(p_predict) + (1 - y) * np.log(1 - p_predict)) / len(y) except: return float('inf') #求sigmoid梯度的导数 def dJ(theta, X_b, y): x = self._sigmoid(X_b.dot(theta)) return X_b.T.dot(x - y) / len(X_b) #模拟梯度下降 def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8): theta = initial_theta i_iter = 0 while i_iter < n_iters: gradient = dJ(theta, X_b, y) last_theta = theta theta = theta - eta * gradient i_iter += 1 if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon): break return theta X_b = np.hstack([np.ones((len(X_train), 1)), X_train]) initial_theta = np.zeros(X_b.shape[1])#列向量 self._theta = gradient_descent(X_b, y_train, initial_theta, eta, n_iters) self.intercept_ = self._theta[0] #截距 self.coef_ = self._theta[1:] #维度 return self def predict_proba(self, X_predict): X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict]) return self._sigmoid(X_b.dot(self._theta)) def pedict(self, X_predict): proba = self.predict_proba(X_predict) return np.array(proba > 0.5, dtype='int')
神经网络基础
神经网络
神经网络包含了三个层,分别是:输入层(红色表示),隐藏层(紫色表示)以及输出层(绿色表示)。

- 神经元
在神经网络中,神经元模型是一个包含输入、输出与计算功能的模型。

一个神经网络的训练算法就是让权重值调整到最佳,以使得整个网络的预测(或者分类)效果最好。

神经元的个数对分类效果的影响。一般来说,更多神经元的神经网络可以表达更复杂的函数。然而这既是优势也是不足,优势是可以分类更复杂的数据,不足是可能会造成对训练数据的过拟合。过拟合(overfitting)是指网络对数据中的噪声有很强的拟合能力,而么有重视数据之间潜在的基本关系。 - 激活函数
激活函数的作用是,在所有隐藏层之间添加一个激活函数,这样输出的就是一个非线性函数了,神经网络的表达能力就更加强大。
每一层的输出通过这些激活函数之后,就会变得比以前复杂很多,从而提升了神经网络模型的表达能力。对于隐藏层到输出层是否需要激活函数,则还需要根据经验啦进行判断,一般来说,输出层最主要的任务是将输出结果与真实结果进行比较,然后通过反向传播更新权重。因为数据经过激活函数的输出之后区间是由范围的,所以一般情况下不会考虑在隐藏层输出层支架使用激活函数(分类问题除外,如果面对的二分类的问题,则可以考虑使用sigmoid函数作为隐藏层和输出层之间的激活函数;如果面对的是多分类的问题,则可以考虑使用softmax作为隐藏层和输出层之间的激活函数)。-
sigmoid函数

sigmoid函数会造成梯度消失,sigmoid函数在靠近0和1这两端的时候,因为曲线变得非常的平缓,所以梯度几乎变为了0,如果梯度接近于0,那就几乎没有任何信息来更新了,这样会造成模型的不收敛。另外,如果使用sigmoid函数,那么在初始化权重的时候也必须非常小心;如果初始化的时候权重太大,那么激活会导致大多数神经元变得饱和,从而没有办法更新参数了。 -
Tanh函数
Tanh是双曲正切函数,和sigmoid函数的曲线是比较相近的。相同的是,这两个函数在输入很大或是很小的时候,输出都几乎是平滑的,当梯度很小时,将不利于权重更新;不同之处在于输出区间,tanh的输出区间是在(-1,1)之间,而且整个函数是以0Wie中心的,这个特点比sigmoid要好。

-
ReLU函数
线性整流函数(Rectified Linear Unit, ReLU),又称Wie修正线性单元,ReLU是一个分段函数,其公式为 f ( x ) = m a x ( 0 , x ) f(x)=max(0, x) f(x)=max(0,x)。大于0的数将直接输出,小于0的数则输出为0,在0这个地方虽然不连续,但其他也同样适合做激活函数。ReLU是目前应用较为广泛的激活函数,其优点为在随机梯度下降的训练中收敛很快,在输入为正数的时候,不存在梯度饱和问题,ReLU函数只有线性关系,不管是前向传播还是反向传播逗比sigmoid函数要快很多(sigmoid要计算指数,计算速度会比较慢)。

-
- 前向传播
神经网络前向传递过程的四个关键步骤:- 输入层 的每个节点,都需要与隐藏层的每个节点做点对点的计算,计算的方法是加权求和+激活函数。
- 利用隐藏层计算出的每个值,再使用相同的方法,与输出层进行计算(简单神经元网络结构)。
- 隐藏层大量使用ReLU函数之前广泛使用sigmoid作为激活函数,而输出层如果是二分类问题则一般使用sigmoid函数;如果是多分类问题则一般使用softmax作为激活函数。
- 起初输入层的数值将通过网络计算分别传播到隐藏层,再以相同的方式传播到输出层,最终的输出值将与样本值进行比较,计算出误差,这个过程称为前向传播。
输出层
神经网络可以用于处理分类问题以及回归问题,一般而言,如果是二分类问题,则从隐藏层到输出层使用sigmoid函数作为激活函数,如果是多分类问题,则从隐藏层到输出层使用softmax函数;对于回归问题我们一般不使用激活函数。
-
softmax
softmax分类器的输出是每个类别的概率。在Logistics regression二分类问题中,可以使用sigmoid函数将输入 w x + b wx + b wx+b映射到(0,1)区间中,从而得到属于某个类别的概率。在处理多分类的问题上,分类器最后的输出单元需要使用softmax函数进行数值处理。softmax函数的定义为 S i = e V i ∑ j C e V j S_i = \frac{e^{V_i}}{\sum_j^Ce^{V_j}} Si=∑jCeVjeVi。其中 V i V_i Vi表示的是分类器前级输出单元的输出。 i i i表示类别索引,总的类别个数为 C C C。 S i S_i Si表示的是当前元素d额指数与所有元素指数和的比值。softmax将多分类的输出数值转化为相对概率,因此更容易理解和比较。在实际应用中,需要对 V V V进行一些数值处理:即 V V V中的每个元素减去 V V V中的最大值。 D = m a x ( V ) , S i = e V i − D ∑ j C e V j − D D = max(V), S_i = \frac{e^{V_i-D}}{\sum_j^Ce^{V_j-D}} D=max(V),Si=∑jCeVj−DeVi−D。
一般来说,神经网络是将输出值最大的神经元所对应的类别作为识别结果,而且即使使用softmax函数也只会改变值的大小而不能改变神经元的位置;另外指数函数的运算也需要一定的计算机运算量,因此可以考虑在多分类问题中省去softmax函数。 -
one-hotencoding
-
输出层的神经元个数
输出层的神经元数量应根据实际需要解决的 问题来决定。对于分类问题,输出层的神经元个数一般会与类别的数量保持一致。 -
MNIST数据集的前向传播
#MNIST dataset train_dataset = dset.MNIST(root='../pymnist', train=True, transform=transforms.ToTensor(), download=False) test_dataset = dsets.MNIST(root='../pymnist', train=False, transform=transforms.ToTensor(), download=False) def init_network(): network = { } weight_scale = 1e-3 network['W1'] = np.random.randn(784, 50) * weight_scale network['b1'] = np.ones(50) newwork['W2'] = np.random.randn(50, 100) * weight_scale network['b2'] = np.ones(100) network['W3'] = np.random.randn(100, 10) * weight_scale network['b3'] = np.ones(10) return network def forward(network, x): w1, w2, w3 = network['W1'], network['W2'], network['W3'] b1, b2, b3 = network['b1'], network['b2'], network['b3'] a1 = x.dot(w1) + b1 z1 = _relu(a1) a2 = z1.dot(w2) + b2 z2 = _relu(a2) a3 = z2.dot(w3) + b3 y = a3 return y network = init_network() accuracy_cnt = 0 x = test_dataset.test_data.numpy.reshape(-1, 28*28) labels = test_dataset.test_labels.numpy() for i in range(len(x)): y = forward(network, x[i]) p = np.argmax(y) if p == labels[i]: accuracy_cnt += 1 print('Accuracy:' + str(float(accuracy_cnt) / len(x) * 100) + '%')
批处理
import numpy as np
def _softmax(x):
if x.ndim == 2:
c = np.max(x, axis=1)
x = x.T - c #溢出对策
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
c = np.max(x)
exp_x = np.exp(x - c)
return exp_x / np.sum(exp_x)
accuracy_cnt = 0
batch_size = 100
x = test_dataset.test_data.numpy().reshape(-1, 28*28)
labels = test_dataset.test_labels.numpy()
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = forward(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == labels[i:i+batch_size])
print('Accuracy:' + str(float(accuracy_cnt) / len(x) * 100) + '%')
广播原则
广播原则指的是如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符,或者其中一方的长度为1,则认为它们是广播兼容的。广播会在缺失和(或)长度为1的维度上进行。广播发生的两种情况:
- 一种是两个数值的维数不相等,但是它们的后缘维度的轴长相符;
- 另外一种是有一方的长度为1。
import numpy as np
arr1 = np.array([[0, 0, 0], [1, 1, 1], [2, 2, 2], [3, 3, 3]])#(4,3)
arr2 = np.array([1, 2, 3])#(3,)
arr_sum = arr1 + arr2
print(arr1.shape)
print(arr2.shape)
print(arr_sum)

import numpy as np
arr1 = np.array([[0, 0, 0], [1, 1, 1], [2, 2, 2], [3, 3, 3]])#(4, 3)
arr2 = np.array([[1], [2], [3], [4]])#(4, 1)
arr_sum = arr1 + arr2
print(arr1.shape)
print(arr2.shape)
print(arr_sum)

损失函数
神经网络模型训练得以实现是经过前向传播计算Loss,根据Loss的值进行反向推导,并进行相关参数的调整。由此可见,Loss是指导参数进行调整的方向性的指导,是很关键的值,如果Loss随意指示下降的方向,那么可能会出现的问题是,无论经过多少次迭代,都是没有目标的随意游走。
-
均方误差

-
交叉熵误差
-
Mini-batch
Mini-batch是一个一次训练数据集的一小部分,而不是整个训练集的技术。它可以使内存较小、不能同时训练整个数据集的电脑也可以训练模型。Mini-batch从运算的角度来说是低效的,因为你不能在所有样本中都计算Loss值。但是 这个点小的代价也比根本不能运行模型要划算。其余随机梯度下降(SGD)结合在一起使用时也很有帮助,使用方法是在每一代训练之前,都对数据进行随机混洗,然后创建mini-batches,对每一个mini-batch,都使用梯度下降训练网络权重。因为这些batches是随机的,因此其实是在对每个batch做随机梯度下降(SGD)的操作。
最优化
损失函数可以量化某个具体权重集W的质量,即一系列的W所得到的损失函数值,值越小表示预测值越接近真实值。而最优化的目标就是找到能够使损失函数值最小化的一系列W。
- 随机初始化
- 跟随梯度(数值微分)

-
梯度

-
梯度下降法
虽然梯度的方向g 不一定指向函数的最小值(可能存在局部最小值的可能性,因而没有找到全局最小值),但的确是沿着它的方向尽可能的减少函数的值。 -
神经网络的梯度下降法
神经网络的学习也要求梯度,这里的梯度所代表的是损失函数中关于权重以及偏移量的梯度。
-
基于数值微分的反向传播
- 激活函数的定义
- 损失函数以及数值微分的计算逻辑
- 定义神经网络
- 查看损失值
基于测试集的平均
神经网络学习的目的就是需要掌握泛化能力,因此要评价神经网络的泛化能力,就必须使用不包含在训练数据中的数据。
- batchsize:批大小。在深度学习中,一般采用SGD训练,即每次训练都在训练集中提取batchsize个样本进行训练。
- iteration:一个iteration等于使用batchsize个样本训练一次。
- epoch:一个epoch等于使用训练集中的全部样本训练一次
误差反向传播
虽然数值微分实现起来比较容易,但是在计算上花费的时间却比较多。误差反向传播法是一个高效计算权重以及偏置量的梯度方法。
激活函数层的实现
通过计算图来理解误差反向传播法,计算图被定义为有向图,其中,节点对应于数学运算,计算图是表达和评估数学表达式的一种方式。
-
ReLU反向传播实现
用计算图的思路来实现ReLU激活函数的方向传播。class Relu: def __init__(self): self.x = None def forward(self, x): self.x = np.maximum(0, x) out = self.x return out def backward(self, dout): dx = dout dx[self.x <= 0] = 0 return dx -
Sigmoid反向传播实现
class _sigmoid: def __init__(self): self.out = None def forward(self, x): out = 1 / (1 + np.exp(-x)) self.out = out return out def backward(self, dout): dx = dout * self.out * (1 - self.out) return dx
Affine(全连接层)层的实现
Affine的英文翻译是神经网络中的一个全连接层。仿射(Affine)的意思是前面一层中的每一个神经元都连接到当前层中的每一个神经元。在许多方面,这是神经网络的‘标准’层。仿射层通常被加在卷积神经网络或循环神经网络中作为最终预测前的输出的顶层。仿射岑给的一般形式为 y = f ( W ∗ x + b ) y = f(W*x + b) y=f(W∗x+b),其中, x x x是层输入, W W W是参数, b b b是一个偏置量, f f f是一个非线性激活函数。
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.x = None
self.dW = None
self.db = None
def forward(self, x):
self.x = x
out = np.dot(x, self.W) + self.b
return out
def backword(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
return dx
Softmaxwithloss层的实现

class SoftmaxWithLoss:
def __init__(self):
self.loss = None #损失
self.p = None #Softmax的输出
self.y = None #监督数据代表真值,one-hot vector
def forward(self, x, y):
self.y = y
self.p = softmax(x)
self.loss = cross_entropy_error(self.p, self.y)
return self.loss
def backward(self, dout=1):
batch_size = self.y.shape[0]
dx = (self.p - self.y) / batch_size
return dx
基于数值微分和误差反向传播的比较
两种求梯度的方法:
- 基于数值微分的方法:数值微分的优点在于其实现起来非常简单,一般情况下,数值微分实现起来太容易出错,对数值微分来说,它的计算非常耗时。
- 基于误差反向传播的方法:误差反向传播法的实现非常复杂,且容易出错。对误差反向传播来说,可以快速高效的进行梯度计算。
比较数值微分和误差反向传播的结果(两者应该是非常接近的),以确认书写的反向传播逻辑是否正确,这样的操作就称为梯度确认(gradientcheck)。
from collections import OrderedDict
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
#初始化权重
self.params = {
}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
#生成层
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.lastLayer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
#x:输入数据,y:监督数据
def loss(self, x, y):
p = self.predict(x)
p = np.argmax(y, axis=1)
if y.ndim != 1:
y = np.argmax(y, axis=1)
accuracy = np.sum(p == y) / float(x.shape[0])
return accuracy
#x:输入数据,y:监督数据
def numerical_gradient(self, x, y):
loss_W = lambda W: self.loss(x, y)
grads = {
}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, y):
#forward
self.loss(x, y)
#backward
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
#设定
grads = {
}
grads['W1']. grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2']. grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
x_batch = x_train[:100]
y_batch = y_train[:100]
grad_numerical = network.numerical_gradient(x_batch, y_batch)
grad_backprop = network.gradient(x_batch, y_batch)
for key in grad_numerical.keys():
diff = np.average(np.abs(grad_backprop[key] - grad_numerical[key]))
print(key + ':' + str(diff))
通过反向传播实现MNIST识别
使用数值微分求梯度的方式来实现MNIST识别,虽然比价简单,但是在计算上要耗费较多的时间。误差反向传播方法可以快速高效的进行梯度计算。
正则化惩罚
通过向损失函数增加一个正则化惩罚,可以向某些特定的权重添加一些偏好,对其他权重则不添加,以此来消除模糊性。最常用的正则化惩罚是L2范式,L2范式通过对所有参数进行逐元素的平方惩罚来抑制大数值的权重。
PyTorch实现神经网络图像分类
PyTorch的使用
-
Tensor
#1 Numpy和Tensor的相互转换 import torch import numpy as np np_data = np.arange(8).reshape((2, 4))#定义一个numpy的二维数组 torch_data = torch.from_numpy(np_data)#numpy->tensor print(np_data) print(torch_data) np_data2 = torch_data.numpy()#tensor->numpy print(np_data2) #2 tensor 做矩阵运算 np_data = np.array([[1, 2], [3, 5]]) torch_data = torch.from_numpy(np_data) print(np_data) print(np_data.dot(np_data)) print(torch_data.mm(torch_data)) -
Variable
Tensor是PyTorch中的基础组件,但是构建神经网络需要能够构建计算图的Tensor,即Variable(简单理解就是Variable是对Tensor的一种封装)。其操作属性与Tensor是一样的,但是每个Variable都包含了三个属性(data、grad以及creator):Variable中的Tensor本身通过.data来进行访问、对应Tensor的梯度通过.grad进行访问,以及创建这个Variable的Function的应用通过。grad_fn进行访问,该引用可用于回溯整个创建链路,如果是用户自己创建Variable,则其grad_fn为None。

from torch.autograd import Variable #导入Variable import torch x_tensor = torch.randn(10, 5)#从标准正态分布中返回多个样本值 #将Tensor变成Variable x = Variable(x_tensor, requires_grad=True)#默认Variable是不需要求梯度的,所以用这个方式申明需要对其进行求梯度的操作 print(x.data) print(x.grad) print(x.grad_fn) -
激活函数
使用PyTorch来构建激活函数import torch from torch.autograd import Variable import matplotlib.pyplot as plt tensor = torch.linspace(-6, 6, 200) tensor = Variable(tensor) np_data = tensor.numpy() #定义激活函数 y_relu = torch.relu(tensor).data.numpy() y_sigmoid = torch.sigmoid(tensor).data.numpy() y_tanh = torch.tanh(tensor).data.numpy() plt.figure(1, figsize=(8,6)) plt.subplot(221) plt.plot(np_data, y_relu, c='red', label='relu') plt.lengend(loc='best') plt.subplot(222) plt.plot(np_data, y_sigmoid, c='red', label='sigmoid') plt.lengend(loc='best') plt.subplot(223) plt.plot(np_data, y_tanh, c='red', label='tanh') plt.legend(loc='best') plt.show() -
损失函数
-
均方误差损失函数
PyTorch中均方误差算函数被封装成MSELoss函数,其调用方法如下:torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean') #调用参数说明 #size_average(bool, optional):基本弃用。默认情况下,损失是批次(batch)中每个损失元素的平均值。对于某些损失,每个样本均有多个元素。如果将字段size_average设置为False,则需要将每个batch的损失相加。当reduce设置为False时忽略。默认值为True。 #reduce(bool, optional):基本弃用。默认情况下,根据size_average,对每个batch中结果的损失进行平均或求和。当reduce为False时,返回batch中每个元素的损失并忽略size_average。默认值为True。 #reduction(string, optional):手粗元素包含3中操作方式,即none、mean和sum.'none':不做处理。'mean':输出的总和除以输出中元素的数量。'sum':输出的和。注意:size_average和reduce基本已被弃用,而且指定这两个args中的任何一个都将覆盖reduce。默认值为mean。 -
交叉熵损失函数
PyTOrch中的交叉损失函数将nn.LogSoftmax()和nn.NLLLoss()合并在一个类中,函数名为CrossEntropyLoss()。CrossEntropyLoss是多分类任务中常用的损失函数,在PyTorch中的调用方法如下:torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean') #调用参数说明 #weight(Tensor, optional):多分类任务中,手动给出每个类别权重的缩放量。若果给出,则其是一个大小等于类别个数的张量。 #size_average(bool,optional):已基本弃用。默认情况下,损失是batch中每个损失元素的平均值。对于某些损失,每个样本都包含了多个元素。如果将字段size_average设置为False,则将每个小批量的损失相加。当reduce为False时则忽略。默认值为True。 #ignore_index(int, optional):指定被忽略且不对输入梯度做贡献的目标值。当size_average为True时,损失则是未被忽略目标的平均。 #reduction(bool,optional):已基本弃用。默认情况下,根据size_average,对每个batch中结果的损失进行平均或求和。当reduce为False时,返回batch中每个元素的损失并忽略size_average。默认值为True。 #reduction(string,optional):输出元素有3种操作方式,即none、mean和sum。‘none’:不做处理。‘mean’:输出的总和除以输出的元素的数量。‘sum’:输出的和。注意:size_average和reduce正在被弃用,而且指定这两个阿如果是中的任何一个都将覆盖reduce。默认值为mean。 #官方示例代码 loss = nn.CrossEntropyLoss() input = torch.randn(3, 5, requires_grad=True) target = torch.empty(3, dtype=torch.long).random_(5) output = loss(input, target) output.backward()PyTorch是不支持one-hot编码类型的,输入的都是真实的target,所以如果输入的真实分类是one-hot编码的话则需要自行转换,即将target one-hot的编码格式转换为每个样本的列表,在传给CrossEntropyLoss。完整代码如下:
import torch form torch import nn import numpy as np #编码one-hot def one_hot(y): """y:(N)的一维Tensor,值为每个样本的类别 out: y_onehot:转换为one_hot编码格式 """ y = y.view(-1, 1) y_onehot = torch.FloatTensor(3, 5) #In your for loop y_onehot.zero() y_onehot.scatter_(1, y, 1) return y_onehot def cross_entropy_one_hot(target): #解码 _, labels = target.max(dim=1) return labels x = np.array([1, 2, 3]) x_tensor = torch.from_numpy(x) print(one_hot(x_tensor)) x2 = np.array([[0, 1, 0, 0, 0]]) x2_tensor = torch.from_numpy(x2) print(cross_entropy_one_hot(x2_tensor))
-
PyTorch实战
-
PyTorch实战之MNIST分类
#1 数据准备 import torch from torch.utils.data import DataLoader import torchvision.datasets as dsets import torchvision.tansforms as transforms batch_size = 100 #MNIST dataset train_dataset = dsets.MNIST(root='../pyminist', trian=True, transform=transforms.ToTensor(), download=True) test_dataset = dsets.MNIST(root='../pymnist', train=False, transform=transforms.ToTensor(), download=True) #加载数据 train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True) #原始数据 print('train_data:', train_dataset.train_data.size()) print('trian_labels:', trian_dataset.train_labels.size()) print('test_data:', test_dataset.test_data.size()) print('test_labels:', test_dataset.test_labels.size()) #将数据打乱取小批次 print('批次的尺寸:', trian_loader.batch_size) print('load_train_data:', trian_loader.dataset.train_data.shape) print('load_train_labels:', train_loader.dataset.train_labels.shape) #2 定义神经网络 import torch.nn as nn import torch input_size = 784 #mnist的像素为28*28 hidden_size = 500 num_classes = 10 #输出为10个类别分别对应于0-9 #创建神经网络 class Neural_net(nn.Module): #初始化函数,接受定义输入特征的维数,隐含层特征维数以及输出层特征维数 def __init__(self, input_num, hidden_size, out_put): super(Neural_net, self).__init__() self.layer1 = nn.Linear(input_num, hidden_size)#从输入到隐藏层的线性处理 self.layer2 = nn.Linear(hidden_size, out_put)#从隐藏层到输出层的线性处理 def forward(self): out = self.layer1(x) #输入层d凹隐藏层的线性j计算 out = torch.relu(out) #隐藏层激活函数 out = self.layer2(out) #输出车个,注意,输出层直接接Loss return out net = Neural_net(input_num, hidden_size, num_classes) print(net) #3 训练 #optimization from torch.autograd import Variable import numpy as np learning_rate = 1e-1 #学习率 num_epoches = 5 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate)#使用随机梯度下降 for epoch in range(num_epoches): print('current epoch = %d' % epoch) for i, (images, labels) in enumerate(train_loader): images = Variable(images.view(-1, 28, 28)) labels = Variable(labels) outputs = net(images)#将数据集传入网络做前向计算 loss = criterion(outputs, labels)#计算loss optimizer.zero_grad()#在做反向传播之前先清除下网络状态 loss.backward()#loss 反向传播 optimizer.step()#更新参数 if i % 100 == 0: print('current loss = %.5f' % loss.item()) print('finished training') # 4测试集准确度测试 #做prediction total = 0 correct = 0 for images, labels in test_loader: images = Variable(images.view(-1, 28*28)) outputs = net(images) _, predicts = torch.max(outputs.data, 1) total += (predicts == labels).sm() print('Accuracy = %.2f' % (100 * correct / total)) -
PyTorch实战之Cifar10分类
#1 数据准备 import torch from torch.utils.data import DataLoader import torchvision.datasets as dsets import torchvision.transforms as transforms batch_size = 100 #MNIST dataset train_dataset = dsets.CIFAR10(root='../pycifar', train=True, transform=transforms.ToTensor(), download=True) test_dataset = dsets.CIFAR10(root='../pycifar', train=False, transform=transforms.ToTensor(), download=True) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=bach_size, shuffle=True) #2 定义神经网络 from torch.autograd import Variable import torch.nn as nn import torch input_size = 3072 hidden_size = 500 hidden_size2 = 200 num_classes = 10 num_epoches = 5 batch_size = 100 learning_rate = 0.001 #定义两层神经网络 class Net(nn.Module): def __init__(self, input_size, hidden_size, hidden_size2, num_classes): super(Net, self).__init__() self.layer1 = nn.Linear(input_size, hidden_size) self.layer2 = nn.Linear(hidden_size, hidden_size2) self.layer3 = nn.Linear(hidden_size2, num_classes) def forward(self, x): out = torch.relu(self.layer1(x)) out = torch.relu(self.layer2(out)) out = self.layer3(out) return out net = Net(input_size, hidden_size, hidden_size2, num_classes) print(net) # 3 训练 #optimization from torch.autograd import Variable import numpy as np learning_rate = 1e-3 num_epoches = 5 ciriterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate) for epoch in range(num_epoches): print('current epoch = %d' % epoch) for i, (images, labels) in enumerate(train_loader): image = Variable(images.view(images.size(0), -1)) labels = Variable(labels) optimizer.zero_grad() outputs = net(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() if i % 100 == 0: print('current loss = %.5f' % loss.item()) print('Finished training') # 4 测试集准确度测试 #prediction total = 0 correct = 0 for images, labels in test_loader: images = Variable(images.view(images.size(0), -1)) outputs = net(images) _,predicts = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicts == labels).sum() print('Accuracy = %.2f' % (100 * correct / total))
卷积神经网络
卷积神经网络(Convolutional Neural Network, CNN)是一种深度前馈神经网络,目前在图片分类、图片检索、目标检测、目标分割、目标跟踪、视频分类、姿态估计等图像视频相关领域中已有很多较为成功的应用。
卷积神经网络基础
-
全连接层(Fully Connected Layer)
全连接层是神经网络的一个隐藏层,包含权重向量和激活函数。对于图片,要通过全连接层,首先要将其拉伸为一维向量作为神经网络隐藏层的输入,然后该向量与权重向量做点乘操作,再将点乘后 结果作为激活函数的输入,最终,激活函数输出的结果便是全连接层的最终结果。

-
卷积层(Convolutional Layer)
卷积层与连接层不同,它保留了输入图像的空间特征,不需要对图像进行一维向量的拉伸,对图像不需要做任何改变。在卷积层中,引入卷积核(常简称为卷积,有时也称为滤波器)。卷积的大小可以在实际需要时自定义其长和宽。其通道个数通常设置为与输入图片通道数量一致。



-
池化层(pooling)
池化是对图片进行压缩(降采样)的一种方法。池化层对原始特征层的信息进行压缩,是卷积神经网络中很重要的一步。绝大多数情况下,卷积层、c池化层、激活层三者几乎像一个整体一样常常共同出现。


-
批规范化层(BatchNorm)
批规范化层是为了加速神经网络的收敛过程以及提高训练过程中的稳定性。虽然深度学习被证明有效,但它的训练过程始终需要精心调试,比如精心设置初始化参数、使用较小的学习率等。
在使用卷积神经网络处理图像数据时,往往是几张图片被同时输入到网络中一起进行前向计算,误差也是将该batch中所有图片的误差累计起来一起回传。BatchNorm方法其实就是对一个batch中的数据根据公式做了归一化。

常见卷积神经网络结构

-
AlexNet
AlexNet主要由5个卷积层和3个全连接层组成,最后一个全连接层通过Softmax最终产生的结果将作为输入图片在1000个类别(ILSVRC图片分类比赛有1000个类别)上的得分。

- 使用ReLU作为激活函数:收敛速度快
- 使用多种方法避免过拟合
- 数据增强:在图像领域,最简单也最常用的避免过拟合的方法就是对数据集的增强。
- 对原始图片做随机裁剪。
- 还有一些常见的额数据增强方法,AlexNet并没有全部用到。例如训练时对原始图片进行随机的上下、左右翻转,平移,缩放,旋转灯,这些在实践中都有很好的效果。
- 使用dropout:该方法一方面是为了避免过拟合,另一方面是使用更有效的方式进行模型融合。具体方法是在训练时让神经网络中每一个中间层神经元以5的一定倍数的概率(例如0.5)置为0.当某个神经元被置为0时,它便不会参与前传播以及反向回传的计算。因此每当有一个新的图片输入时就意味着网络随机采样出一个新的网络结构,而真正的整个网络的权重一直是共享的。从感性的角度来讲,dropout的存在也强迫了神经网络学习出更稳定的特征(因为在训练过程中随机屏蔽一些圈中的同时还要保证算法的效果,因此学习出来的模型相对来说更稳定)。预测时使用所有的神经元,但需要将其输出均乘以0.5.
- 数据增强:在图像领域,最简单也最常用的避免过拟合的方法就是对数据集的增强。
-
VGGNet


VGG16Net的网络结构以及每一层计算所对应的需要消耗的内存和计算量。从表中可以看出,内存消耗主要来自于早期的卷积,而参数量的激增则发生在后期的全连接层。如下图所示。

-
GoogLeNet
GoogLeNet最初的想法很简单,就是若想要得到更好的预测效果,就要增加网络的复杂度,即从两个角度出发:网络深度和网络宽度。但这个思路哟两个较为明显的问题。- 首先,更复杂的网络意味这更多的参数,就算是ILSVRC这种包含了1000类标签的数据也很容易过拟合。
- 其次,更复杂的网络会带来更大的计算资源的消耗,而且个kernel个数设计不合理导致kernel中的参数没有被完全利用(多数权重都趋近0)时,会导致大量计算资源的浪费。
GoogLeNet引入了inception结构来解决这个问题。其中涉及了大量的数学推导和原来。下面以简单的方式解释inception设计的初衷。





-
ResNet
ResNet的提出是革命性的,它为解决神经网络中因为网络深度导致的“梯度消失”问题提供了一个非常好的思路。
为了解决神经网络过深导致的梯度消失问题,ResNet巧妙的引入了残差结构,将输出层 H ( X ) = F ( X ) H(X)=F(X) H(X)=F(X)改为 H ( X ) = F ( X ) + X H(X)=F(X)+X H(X)=F(X)+X,所以就算网络结构很深,梯度也不会消失了。
除了残差结构之外,ResNet还沿用了前人的一些可以提升网络性能的效果和设计,如堆叠式残差结构,每个残差模块又由多个小尺度kernel组成,整个ResNet除最后用于分类的全连接层以外都是卷积的,这大大提升了计算速度。
ResNet网络深度哟34、50/101、152等多种,50层以上的ResNet也借鉴了类似GoogLeNet的思想,在细节上使用了bottleneck的设计方式。


-
其他网络结构
-
Wide ResNet:认为残差结构比深度更重要,设计了更宽的残差模块,实验证明50层加宽残差网络效果比152层的原ResNet网络效果好。

-
ResNeXT:与Wide ResNet不同,ResNeXT在ResNet的基础上通过加宽inception个数的方式 扩展残差模块。

-
DenseNet:在DenseNet中,每一层都与其他层相关联,这样的设计也大大缓解了“梯度消失”的问题。

-
VGG16实现Cifar10分类
-
训练
#1 载入数据 import torch import torchvision import torchvision.transforms as transforms #使用torchvision可以很方便的额下载cifar10数据集,而torchvision下载的数据集为[0,1]的PILImage格式,需要将张量Tensor归一化到[-1,1] transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))])#将[0,1]归一化到[-1, 1] trainset = torchvision.datasets.CIFAR10(root='../pycifar10/data', train=True, download=True, transform=transform) trianloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2) testset = torchvision.datasets.CIFAR10(root='../pycifar10/data', train=False, download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=2) cifar10_classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') #查看训练数据 import numpy as np dataiter = iter(trainloader)#随机从训练数据中取一些数据。 images, labels = dataiter.next() images.shape #(4, 3, 32, 32) batch_size=4 torchvision.utils.save_image(images[1], 'test.jpg') cifar10_classes[labels[j]] # 2 构建卷积神经网络 import math import torch import torch.nn as nn cfg = { 'VGG16':[64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']} class VGG(nn.Module): def __init__(self, net_name): super(VGG, self).__init__() #构建网络的卷积层和池化层,最终输出命名features,因为通常认为经过这些操作的输出为含图像空间信息的特征层。 self.features = self._make_layers(cf[net_name]) #构建卷积层之后的全连接层以及分类器 self.classifier = nn.Sequential( nn.Dropout(), nn.Linear(512, 512), nn.ReLU(True), nn.Dropout(), nn.Linear(512, 512), nn.ReLU(True), nn.Linear(512, 10)) #初始化权重 for m in self.modules(): if isinstance(m, nn.Conv2d): n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels m.weight.data.normal_(0, math.sqrt(2. / n)) m.bias.data.zeros_() def forward(self, x ): x = self.features(x)#前向传播的时候先经过卷积层和池化层 x = x.view(x.size(0), -1) x = self.calssifier(x)#再将features(得到网络输出的特征层)的结果拼接到分类器上 return x def _make_layers(self, cfg): layers = [] in_channels = 3 for v in cfg: if v == 'M': layers += [nn.MaxPool2d(kernel_size=2, stride=2)] else: layers += [nn.Conv2d(in_channels, v, kernel_size=3, padding=1), nn.BatchNorm2d(v), nn.ReLU(inplace=True)] in_channels = v return nn.Sequential(*layers) net = VGG('VGG16') # 3 定义损失函数和优化方法 import torch.optim as optim criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # 4 卷积神经网络训练 for epoch in range(5): train_loss = 0.0 for batch_idx, data in enumerate(trainloader, 0): #初始化 inputs, labels = data #获取数据 optimizer.zero_grad()#先将梯度置为0 #优化过程 outputs = net(inputs)#将数据输入到网络,得到第一轮网络前向传播的预测结果outputs loss = criterion(outputs, labels)#预测结构outputs和labels通过之前定义的交叉熵计算损失。 loss.backward()#误差反向传播 optimizer.step()#随机梯度下降法优化权重 #查看网络训练状态 train_loss += loss.item() if batch_idx % 2000 == 1999:#每迭代2000个batch打印看一次当前网络收敛情况 print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, train_loss / 2000)) trian_loss = 0.0 print('Saving epoch %d model ...' % (epoch + 1)) state = { 'net': net.state_dict(), 'epoch': epoch + 1,} if not os.path.isdir('checkpoint'): os.mkdir('checkpoint') torch.save(state, './checkpoint/cifar10_epoch_%d.ckpt' % (epoch + 1)) print('Finished Trainig') -
预测评估
# 5 批量计算整个测试集预测效果 correct = 0 total = 0 with torch.no_grad(): for data in testloader: images, labels = data outputs = net(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item()#当标记的label种类和预测的种类一致时认为正确,并计数。 print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total)) #分别查看每个类的预测效果 class_correct = list(0. for i in range(10)) class_total = list(0. for i in range(10)) with torch.no_grad(): for data in testloader: images, labels = data outputs = net(images) _, predicted = torch.max(outputs, 1) c = (predicted == labels).squeeze() for i in range(4): label = labels[i] class_correct[label] += c[i].item() class_total[label] += 1 for i in range(10): print('Accuracy of %5s : %2d %%' %(cifar10_classes[i], 100 * class_correct[i] / class_total[i]))
目标检测
- 定位+分类:对于仅有一个目标的图片,检测出该目标所处的位置以及该目标的类别。
- 目标检测:对于有多个目标的图片,检测出所有目标所处的位置即类别。
定位+ 分类
定位+分类问题是分类到目标检测的一个过渡问题,从单纯的图片分类到分类后给出目标所处的位置,再到多目标的类别和位置。
定位当作回归问题,具体步骤如下:
- 训练或下载一个分类模型。
- 在分类网络最后一个卷积层的特征层(feature map)上添加’regression head’。神经网络中不同的“head”通常用来训练不同的目标,每个“head”的损失函数和优化方向均不相同。如果想让一个网络实现多个功能,那么通常是在神经网络后面接多个不同功能的“head”。
- 同时训练“classification head”和“regression head”,为了同时训练分类和定位(定位是回归问题)两个问题,最终损失函数是分类和定位两个“head”产生的损失的加权和。
- 在预测时同时使用分类和回归“head”得到分类+ 定位的结果。分类预测出的结果就是C个类别,回归预测的结果可能u两种:一种是类别无关,输出4个值;另一种是类别相关,输出4*C个值。

目标检测
-
R-CNN

- 选出潜在目标候选框(ROI):R-CNN使用selective search的方法选出了2000个潜在物体后选框。
- 训练一个好的特征提取器:R-CNN提出者使用卷积神经网络AlexNet提取4096维的特征向量,AlexNet网络要求需要输入的图片尺寸是固定的,而ROI尺寸大小不定,需要将每个ROI调整到指定尺寸,调整尺寸的方法有多种。

为了获得一个好的特征提取器,一般会在ImageNet预训练好的模型基础上做调整(因为ImageNet预测的种类较多,特征学习相对比较完善),唯一的改动就是将ImageNet中的1000个类别的输出改为(C+1)个输出,其中,C是真实需要预测的类别个数,1是背景类。新特征的训练方法是使用随机梯度下降(Stochastic Gradient Descent)。

- 训练最终的分类器
为每个类别单独训练一个SVM分类器。SVM的训练也需要选择正负样本,R-CNN的提出者做了一个实验来选择最优IOU阈值,最终仅仅选择真实值的矩形框作为正样本。 - 训练回归模型
为每个类别训练一个回归模型,用来微调ROI与真实矩形框位置和大小的偏差。
预测阶段可分为如下几个步骤:
- 使用selective search方法先选取2000个ROI
- 所有ROI调整为特征提取网络所需的输入大小并进行特征提取,得到与2000个ROI对应的2000个4096维的特征向量。
- 将2000个特征向量分别输入到SVM中,得到每个ROI预测的类别。
- 通过回归网络微调ROI的位置。
- 最终使用非极大值抑制(Non-Maximum Suppression, NMS)方法对同一个类别的ROI进行合并得到最终检测结果。NMS的原理是得到每个矩形框的分数(置信度),如果两个矩形框的IOU超过指定阈值,则仅仅保留分数大的那个矩形框。
R-CNN存在的问题:
- 不论是训练还是预测,都需要对selective search出来的2000个ROI全部通过CNN的forward过程来获取特征,这个过程花费的时间会非常长。
- 卷积神经网络的特征提取器和用来预测分类的SVM是分开的,也就是特征提取的过程不会因SVM和回归的调整而更新。
- R-CNN具有非常复杂的操作流程,而且每一步都是分裂的,如特征提取器通过Softmax分类获得,最终的分类结果由SVM获得,矩形框的位置则是通过回归方式获得。
-
Fast R-CNN


具体训练步骤如下所示:- 将整张图片和ROI直接输入到全卷积的CNN中,得到特征层和对应在特征层上的ROI(特征层的ROI信息可用其几何位置加卷积坐标公式推导得出)。
- 与R-CNN泪水,为了使用不同尺寸的ROI可以统一进行训练,Fast R-CNN将每块候选区域通过池化的方法调整到指定的MN,此时特征层上将调整后的ROI作为分类器的训练数据。与R-CNN不同的是,将分类和回归任务合并到一起进行训练,这样就将整个流程串联起来。Fast R-CNN的池化先将整张图通过卷积神经网络进行处理,然后在特征层上找到ROI对应的位置并取出,对取出的ROI进行池化(此处的池化方式有很多)。池化后,全部2000个MN个训练数据通过全连接层并分别经过2个head:softmax分类以及L2回归,最终的损失函数是分类和回归的损失函数的加权和。利用这种方式即可实现端到端的训练。

Fast R-CNN极大的提升了目标检测训练和预测的速度。Regionproposal占用了绝大多数的时间。
-
Faster R-CNN
Faster R-CNN是在Fast R-CNN的基础上构建一个小的网络,直接产生Region Proposal来代替其他方法(如selective search)得到ROI。这个小型的网络被称为区域预测网络(Region Proposal Network,RPN)。

RPN的核心思想是构建一个小的全卷积网络,对于任意大小的图片,输出ROI的具体位置以及ROI是否为物体。RPN网络在卷积神经网络的最后一个特征层上滑动。如下图所示,灰色的网格表示卷积神经网络的特征层,红框表示RPN的输入,其大小为33,而后连接到256维的一个低维向量上。这个33的窗口滑动经过整个特征层,并且每次计算都将经过这256维的向量并最终输出2个结果:该33滑动窗口位置中是否有物体,以及该滑动窗口对应物体的矩形框位置。右图是将RPN网络旋转90度的图,input维度9即33的滑动窗口大小。为了适应多种形状的物体,RPN定义了k种不同尺度的滑窗(因为有的目标是长的,有的是扁的,有的是大的,有的是小的,统一用33的滑窗难以很好的拟合多种情况),专业名词为anchor,每个anchor都是以特征层(feature map)上的像素点为中心并且根据其尺度大小进行后续计算。在Faster-RCNN论文中,滑窗在特征层的每个位置上使用3种大小和3种比例,共33=9种anchor。

RPN包含2类输出:二分类网络输出是否为物体,回归网络返回矩形框位置对应的4个值。首先,针对分类任务,对于滑窗产生的每一个anchor都计算该anchor与真实标记矩形框的IOU。当IOU大于0.7时,便认为该anchor中含有物体;当IOU小于0.3时,便认为该anchor中不包含物体;当IOU介于0.3-0.7时,则不参与网络训练的迭代过程。对于回归任务,定义的anchor中心点的横、纵坐标以及anchor的宽、高,学习目标为anchor与真实bbox在这四个值上的偏移。RPN为一个全卷积网络,可以用随机梯度下降的方式端到端的进行训练。训练的过程中能与真实物体矩形框相交的IOU大于0.7的anchor并不多,它们绝大多数都是负样本,因此会导致正负样本比例严重失衡,从而影响识别效果。因此,在RPN训练的过程,对每个batch进行随机采样(每个batch中有256个样本)并保证正负样本的比例为1:1,而当正样本数量小于128时,取全部的正样本,其余的则随机使用负样本进行补全。
使用RPN产生ROI的好处是可以与检测网络共享卷积层,使用随机梯度下降的方式端到端的进行训练。Faster R-CNN的训练过程如下:-
使用ImageNet预训练好的模型训练一个RPN。
-
使用ImageNet预训练好的模型,以及第1步里产生的建议区域训练Fast R-CNN,得到物体的实际类别以及微调的矩形框位置。
-
使用第2步中的网络初始化RPN,固定前面的卷积层,只调整RPN层的参数。
-
固定前面的卷积层,只训练并调整Fast R-CNN的FC层。

-
-
YOLO
由于在R-CNN的系列算法中需要先获取大量的proposal,但是proposal之间又有很大的重叠,会带来很多重复的工作。YOLO改变基于proposal预测的思路,将输入图片划分成 S ∗ S S*S S∗S个小格子,在每个小格子中做预测,最终将结果合并。- YOLO对于网络输入图片的尺寸有要求,首先需要将图片缩放到指定尺寸(448*448),再将图片划分成 S ∗ S S*S S∗S的小格。
- 在每个小格里进行这样几个预测:该小格是否包含物体?包含物体对应的矩形框位置以及该小格对应C个类别的分数是多少?因此,每个小格需要预测的维度为 B ∗ ( 1 + 4 ) + C B*(1+4)+C B∗(1+4)+C,其中,B代表每个小格最多可能交叠物体的个数,1为该格是否包含物体的置信度,4用来预测矩形框,C表示任务中所有可能的类别个数(不包含背景)。因此,YOLO网络最终特征层的大小为 S ∗ S ∗ ( B ∗ 5 + C ) S*S*(B*5+C) S∗S∗(B∗5+C)。

YOLO直接将输入图片划分为 S ∗ S S*S S∗S个小格,不需要产生proposal,所以速度比FasterR-CNN快很多,但是因为其粒度较粗,所以精度相比Faster R-CNN略逊一筹。YOLO的主要贡献是诶目标检测提供了另外一种思路,并使实时目标检测成为可能。
-
SSD
SSD同时借鉴了YOLO网格的思想和Faster R-CNN的anchor机制,使SSD可以在进行快速预测的同时又可以相对准确的获取目标的位置。

SSD的特点:- 使用多尺度特征层进行检测。在Faster R-CNN的RPN中,anchor是在干网络的最后一个特征层上生成的,而在SSD中,anchor不仅是在最后一个特征层上产生的,而且在几个高层特征层处同时也在产生anchor。这些层大小依次递减,使得SSD可以检测不同尺度的目标。
- SSD中所有特征层产生的anchor都将经过正负样本的筛选,然后进行分类分数以及Bbox位置的学习。即特征层上生成的正负样本将直接进行最终的分类(ClassNum个类别)以及Bbox的学习,不像Faster R-CNN那样先在第一步学习是否有物体(只有0/1两个类别)以及Bbox位置,然后在第二步学习最终的分类(ClassNum个类别)以及对Bbox位置的微调。
SSD实现VOC目标检测
-
PASCAL VOC数据集
PASCAL(Pattern Analysis, Statistical Modelling and Computational Learning)VOC(Visual Object Classes)数据集。从2005年到2012年,每年都会举办一场图像识别比赛.该数据集包含20类目标,具体如下:- person - bird, cat, cow, dog, horse, sheep - aeroplane, bicycle, boat, bus, car, motorbike, train - bottle, chair, dining table, potted plant, sofa, tv/monitor数据集共包含5类标注数据,其中,目标检测和分割是PASCAL VOC最常用来做实验的2组数据,5类标注数据具体如下:
- 图片分类:判断某个分类是否在图片上。
- 目标检测:检测出图片中物体的位置并给出矩形框。
- 分割:对于图片中的每个像素,区分出其属于20类目标中的哪一种,如果都不是则为背景,分割包含语义分割和实例分割两种数据。
- 人体行为识别:在净值图片中预测人的行为,共10类行为。
- 大规模图像识别:ImageNet分类任务,后续可以参考ImageNet比赛。
.
└── VOC2012 #2012年数据
├── Annotations #保存图像的各种label标签数据的xml文件,与JPEGImages中的图片一一对应,包含目标的类别、位置等信息,解释图片内容等等
├── ImageSets #存放拆分好的训练和测试数据列表,txt文件,train为训练数据+val为验证数据=trainval为训练验证数据,末尾正负1表示正负样本
│ ├── Action #存放人的动作(如running、jumping等等),总共10类动作。
│ ├── Layout #存放具有人体部位的数据(人的head、hand、feet等等)
│ ├── Main #存放图像物体识别的数据,总共分为20类。
│ └── Segmentation #存放物体分割的数据
├── JPEGImages #存放所有的原始图片,包括训练图片和测试图片,共17125张彩色图片,2913张用于分割,“年份_编号.jpg”命名格式,横向图500*375左右,纵向图375*500左右,基本不会偏差超过100。
├── SegmentationClass #存放进行语义分割的真实label,标注出每一个像素的类别
├── SegmentationClassRaw #标注出物体的轮廓
└── SegmentationObject #存放实例分割的真实label,标注出每一个像素属于哪一个物体
-
数据准备
Python的__getitem__方法读取数据。#voc_dataset.py from os import listdir #解析VOC数据路径时使用 from os.path import join from random import random from PIL import Image, ImageDraw import xml.etree.ElementTree #用于解析VOC的xmllabel import torch import torch.utils.data as data import torchvision.transforms as transforms from sampling import sampleEzDetect __all__ = ['vocClassName', 'vocClassID', 'vocDataset'] vocClassName = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] def getVOCInfo(xmlFile): root = xml.etree.ElementTree.parse(xmlFile).getroot() anns = root.findall('object') bboxes = [] for ann in anns: name = ann.find('name').txt newAnn = { } newAnn['category_id'] = name bbox = ann.find('bndbox') newAnn['bbox'] = [-1, -1, -1, -1] newAnn['bbox'][0] = float(bbox.find('xmin').text) newAnn['bbox'][1] = float(bbox.find('ymin').text) newAnn['bbox'][2] = float(bbox.find('xmax').text) newAnn['bbox'][3] = float(bbox.find('ymax').text) bboxes.append(newAnn) return bboxes class vocDataset(data.Dataset): def __inti__(self, config, isTraining=True): super(vocDataset, self).__init__() self.isTraining = isTraining self.config = config normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) self.transformer = transforms.Compose([transforms.ToTensor(), normalize]) def __getitem__(self, index): item = None if self.isTraining: item = allTrainingData[index % len(allTrainingData)] else: item = allTestingData[index % len(allTestingData)] img = Image.open(item[0]) #item[0]为图像数据 allBoxes = getVOCInfo(item[1]) #item[1]为通过getVOCINFO函数解析出真实label的数据 imgWidth, imgHeight = img.size targetWidth = int((random()*0.25 + 0.75) * imgWidth) targetHeight = int((random()*0.25 + 0.75)*imgHeight) #对图片进行随机crop,并保证Bbox大小 xmin = int(random() * (imgWidth - targetWidth)) ymin = int(random() * (imgHeight - targetHeight)) img = img.crop((xmin, ymin, xmin + targetWidth, ymin + targetHeight)) img = img.resize((self.congif.targetWidth, self.config.targetHeight), Image.BILINEAR) imgT = self.tansformer(img) imgT = imgT * 256 #调整bbox bboxes = [] for i in allBboxes: xl = i['bbox'][0] - xmin yt = i['bbox'][1] - ymin xr = i['bbox'][2] - xmin yb = i['bbox'][3] - ymin if xl < 0: xl = 0 if xr >= targetWidth: xr = targetWidth - 1 if yt < 0: yt = 0 if yb >= targetHeight: yt = targetHeight - 1 xl = xl / targetWidth xr = xr / targetWidth yt = yt / targetHeight yb = yb / targetHeight if (xr - xl) >= 0.05 and yb - yt >= 0.05: bbox = [vocClassID[i['category_id']], xl, yt, xr, yb] bboxes.append(bbox) if len(bboxes) == 0: return self[index + 1] target = sampleEzDetect(self.config, bboxes) #对测试图片进行测试 draw = ImageDraw.Draw(img) num = int(target[0]) for j in range(0, num): offset = j * 6 if (target[offset + 1] < 0): break k = int(target[offset + 6]) trueBox = [target[offset + 2], target[offset + 3], target[offset + 4], target[offset + 5]] predBox = self.config.predBoxes[k] draw.rectangle([trueBox[0] * self.config.targetWidth, trueBox[1] * self.targetHeight, trueBox[2] * self.comfig.targetWidth, trueBox[3] * self.config.targetHeight]) drawrectange([predBox[0] * self.targetWidth, predBox[1] * self.targetHeight, predBox[2] * self.targetWidth, predBox[3] * self.targetHeight], None, 'red') del draw img.save('/tmp/{}.jpg'.format(index)) return imgT, target def __len__(self): if self.isTraining: num = len(allTrainingData) - (len(allTrainingData) % self.config.batchSize) return num else: num = len(allTestingData) - (len(allTestingData) % self.config.batchSize) return num vocClassID = { } for i in range(len(vocClassName)): vocClassID[vocClassName[i]] = i + 1 print vocClassID allTrianingData = [] allTestingData = [] allFloder = ['./VOCdevkit/VOC2007'] for floder in allFloder: imagePath = join(floder, 'JPEGImages') infoPath = join(floder, 'Annotations') index = 0 for f in listdir(imagePath): if f.endswith('.jpg'): imageFile = join(imagePath, f) infoFile = join(infoPath, f[:-4] + '.xml') if index % 10 == 0: allTestingData.append((imageFile, infoFile)) else: allTrainingData.appen((imageFile, infoFile)) index = index + 1 -
构建模型
#model.py import os import math import torch import torch.nn as nn from torch.autograd import Variable from torch.autograd import Function import torch.nn.funtional as F import torchvision.models as models from sampling import buildPredBoxes __all__ = ['EzDetectConfig', 'EzDetectNet', 'ReorgModule'] class EzDetectConfig(object): def __init__(self, batchSize=4, gpu=False): super(EzDetectConfig, self).__init__() self.batchSize = batchSize self.gpu gpu self.classNum = 21 self.targetWidth = 330 self.targetHeight = 330 self.featureSize = [[42, 42], [21, 21], [11, 11], [6, 6], [3, 3]] #[min, max, ratio,] priorConfig = [[0.10, 0,25, 2], [0.25, 0.40, 2, 3], [0.40, 0.55, 2, 3], [0.55, 0.70, 2, 3], [0.70, 0.85, 2]] self.mboxes = [] for i in range(len(priorConfig)): minSize = priorConfig[i][0] maxSize = priorConfig[i][1] meanSize = math.sqrt(minSize * maxSize) ratios = priorCOnfig[i][2:] #sapect ratio 1 for min and max self.mboxes.append([i, minSIze, minSize]) self.mboxes.append([i, meanSize, meanSize]) #other aspect ratio for r in ratios: ar = math.sqrt(r) self.mboxes.append([i, minSize * ar, minSize / ar]) self.mboxes.append([i, minSize / ar, minSize * ar]) self.predBoxes = buildPredBoxes(self) class EzDetectNet(nn.Module): def __init__(self, config, pretrained=False): super(EzDetectNet, self).__init__() self.config = config resnet = models.resnet50(pretrained) self.conv1 = resnet.conv1 self.bn1 = resnet.bn1 self.relu = rsnet.relu self.maxpool = resnet.maxpool self.layer1 = resnet.layer1 self.layer2 = resnet.layer2 self.layer3 = resnet.layer3 self.layer4 = resnet.layer4 self.layer5 = nn.Sequential( nn.Conv2d(2048, 1024, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(1024), nn.ReLU(), nn.Conv2d(1024, 1024, kernel_size=3, stride=2, padding=1, bias=False), nn.BatchNorm2d(1024). nn.ReLU()) self.layer6 = nn.Sequential( nn.Conv2d(1024, 512, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(512), nn.LeakyReLU(0.2), nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1, bias=False), nn.VatchNorm2d(512), nn.LeakyReLU(0.2)) inChannels = [512, 1024, 2048, 1024, 512] self.locConvs = [] self.confConvs = [] for i inrange(len(config.mboxes)): inSize = inChannels[config.mboxes[i][0]] confConv = nn.Conv2d(inSize, config.classNumber, kernel_size=3, stride=1, padding=1, bias=True) locConv = nn.Conv2d(inSize, 4, kernel_size=3, stride=1, padding=1, bias=True) self.locConvs.append(locConv) self.confConvs.append(confConv) super(EzDetectNet, self).add_module('{}_conf'.format(i), confConv) super(EzDetectNet, self).add_module('{}_loc'.format(i), locConv) def forward(self, x): batchSize = x.size()[0] x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) l2 = self.layer2(x) l3 = self.layer3(l2) l4 = self.layer4(l3) l5 = self.layer5(l4) l6 = self.layer6(l5) featureSource = [l2, l3, l4, l5, l6] confs = [] locs = [] for i in range(len(self.config.mboxes)): x = featureSource[self.config.mboxes[i][0]] loc = self.locConvs[i](x) loc = conf.permute(0, 2, 3, 1) loc = loc.contiguous() loc = loc.view(batchSIze, -1, 4) locs.append(loc) conf = self.confConvs[i](x) conf = conf.permute(0, 2, 3, 1) conf = conf.contiguous() conf = conf.view(batchSIze, -1, self.config.classNumber) confs.append(conf) locResult = torch.cat(locs, 1) confResult = torch.cat(confs, 1) rerurn confResult, locRessultEzDetectConfig类可用于定义一些配置,如网络输入图片的大小、每个特征层 的大小、每个特征层anchor的尺寸比例等。
-
定义Loss
#loss.py import torch import torch.nn as nn from torch.autograd import Variable from torch.autograd import Function import torch.nn.functional as F from bbox import bboxIOU, encodeBox __all__ = ['EzDetectLoss'] def buidbboxTarget(config, bboxOut, target): bboxMasks = torch.ByteTensor(bboxOut.size()) bboxMasks.zeros_() bboxTarget = torch.FloatTensor(bboxOut.size()) batchSize = target.size()[0] for i in range(0, batchSize): num = intarget(target[i][0]) for j in range(0, num): offset = j * 6 cls = int(target[i][offset + 1]) k = int(target[i][offset + 6]) trueBox = [target[i][offset + 2], target[i][offset + 3], target[i][offset + 3], target[i][offset + 4], target[i][offset + 5]] predBox = config.predBoxes[x] ebox = encodeBox(config, trueBox, predBox) bboxMasks[i, k, :] = 1 bboxMasks[i, k, 0] = ebox[0] bboxMasks[i, k, 1] = ebox[1] bboxMasks[i, k, 2] = ebox[2] bboxMasks[i, k, 3] = ebox[3] if(config.gpu): bboxMasks = bboxMasks.cuda() bboxTarget = bboxTarget.cuda() return bboxMasks, bboxTarget def buildConfTarget(config, confOut, target): bachSize = confOut.size()[0] boxNumber = confOut.size()[1] confTarget = torch.LongTensor(batchSize, boxNumber, config.classNumber) confMasks = torch.ByteTensor(confOut.size()) confMasks.zeros_() confScore = torch.nn.functional.log_softmax(Variable(confOut.view(-1, config.classNumber), requires_grad=False)) confScore = confScore.data.view(batchSize, boxNumber, config.classNumber) #positive samples pnum = 0 for i in range(0, batchSize): num = int(target[i][0]) for j in range(0, num): offset = j * 6 k = int(target[i][offset + 6]) cls = int(target[i][offset + 1]) if cls > 0: confMasks[i, k, :] = 1 confTarget[i, k, :] = cls confScore[i, k, :] = 0 pnum = pnum + 1 else: confScore[i, k, :] = 0 #negtive samples(background) confScore = confScore.view(-1, config.classNumber) confScore = confScore[:, 0].contiguous().view(-1) scoreValue, scoreIndex = torch.sort(confScore, 0, descending=False) for i in range(pnum * 3): b = scoreIndex[i] // boxNumber k = scoreIndex[i] % boxNumber if (confMasks[b, k, 0] > 0): break confMasks[b, k, :] = 1 confTarget[b, k, :] = 0 if (config.gpu): confMasks = confMasks.cuda() confTarget = confTarget.cuda() return confMasks, confTarget class EzDetectLoss(nn.Module): def __init__(self, config, pretrained=False): super(EzDetectLoss, self).__init__() self.config = config self.confLoss = nn.CrossEntropyLoss() self.bboxLoss = nn.SmoothL1Loss() def forward(self, confOut, bboxOut, target): batchSize = target.size()[0] #building loss of conf confMasks, confTarget = buildConfTarget(self.config, confOut.data, target) confSamples = confOut[confMasks].view(-1, self.config.classNumber) confTarget = confTarget[confMasks].view(-1, self.config.classNumber) confTarget = confTarget[:, 0].contiguous().view(-1) confTarget = Variable(confTarget, requires_grad=False) confLoss = self.confLoss(confconfSamples, confTarget) #building loss of bbox bboxMasks, bboxTarget = buildbboxTarget(self.config, bboxOut.data, target) bboxSamples = bboxOut[bboxMasks].view(-1, 4) bboxTarget = bboxTarget[bboxMasks].view(-1, 4) bboxLoss = self.bboxLoss(bboxSamples, bboxTarget) return confLoss, bboxLoss -
SSD训练细节
#sampling.py import random import torch import torch.nn as nn from torch.autograd import Variable from torch.autograd import Function from bbox import bboxIOU __all__ = ['buildPredBoxes', 'sampleEzDetect'] def buildPredBoxes(config): predBoxes = [] for i in range(len(config.mboxes)): l = config.mboxes[i][0] wid = config.featureSize[l][0] hei = conconfig.featureSize[l][1] wbox = config.mboxes[i][1] hbox = config.mboxes[i][2] for y in range(hei): for x in range(wid): xc = (x + 0.5) / wid #x,y位置都取每个feature map像素点的中心值来计算 yc = (y + 0.5) / hei xmin = xc - wbox / 2 ymin = yc - hbox / 2 xman = xc + wbox / 2 ymax = yc + hbox / 2 predBoxes.append([xmin, ymin, xmax, ymax]) return predBoxes def sampleEzDetect(config, bboxes):#在voc_dataset.py的vocDataset类中用到的sampleEZDetect函数 #preparing pred boxes predBoxes = config.predBoxes #preparing ground truth truthBoxes = [] for i in range(len(bboxes)): truthBoxes.append([bboxes[i][1], bboxes[i][2], bboxes[i][3], bboxes[i][4]]) #computing iou iouMatrix = [] for i in predBoxes: ious = [] for j in truthBoxes: ious.append(bboxIOU(i, j)) iouMatrix.append(ious) iouMatrix = torch.FloatTensor(iouMatrix) iouMatrix2 = iouMatrix.clone() ii = 0 selectedSamples = torch.FloatTensor(128*1024) #positive samples from bi-direction match for i in range(len(bboxes)): iouViewer = iouMatrix.view(-1) iouValues, iouSequence = torch.max(iouViewer, 0) predIndex = iouSequence[0] // len(bboxes) bboxIndex = iouSequence[0] % len(bboxes) if (iouValues[0] > 0.1): selectedSamples[ii * 6 + 1] = bboxes[bbboxIndex][0] selectedSamples[ii * 6 + 2] = bboxes[bbboxIndex][1] selectedSamples[ii * 6 + 3] = bboxes[bbboxIndex][2] selectedSamples[ii * 6 + 4] = bboxes[bbboxIndex][3] selectedSamples[ii * 6 + 5] = bboxes[bbboxIndex][4] selectedSamples[ii * 6 + 6] = predIndex ii = ii + 1 else: break iouMatrix[:, bboxIndex] = -1 iouMatrix[predIndex, :] = -1 iouMatrix2[predIndex, :] = -1 #also samples with high iou for i in range(len(selectedSamples)): v, _ = iouMatrix2[i].max(0) predIndex = i bboxIndex = _[0] if(v[0] > 0.7):#anchor与真实值IOU大于0.7的为正样本 selectedSamples[ii * 6 + 1] = bboxes[bbboxIndex][0] selectedSamples[ii * 6 + 2] = bboxes[bbboxIndex][1] selectedSamples[ii * 6 + 3] = bboxes[bbboxIndex][2] selectedSamples[ii * 6 + 4] = bboxes[bbboxIndex][3] selectedSamples[ii * 6 + 5] = bboxes[bbboxIndex][4] selectedSamples[ii * 6 + 6] = predIndex ii = ii + 1 elif (v[0] > 0.5): selectedSamples[ii * 6 + 1] = bboxes[bbboxIndex][0] * (-1) selectedSamples[ii * 6 + 2] = bboxes[bbboxIndex][1] selectedSamples[ii * 6 + 3] = bboxes[bbboxIndex][2] selectedSamples[ii * 6 + 4] = bboxes[bbboxIndex][3] selectedSamples[ii * 6 + 5] = bboxes[bbboxIndex][4] selectedSamples[ii * 6 + 6] = predIndex ii = ii + 1 selectedSamples[0] = ii return selectedSamples def encodeBox(config, box, predBox): pcx = (predBox[0] + predBox[2]) / 2 pcy = (predBox[1] + predBox[3]) / 2 pw = (predBox[2] - predBox[0]) ph = (predBox[3] - predBox[1]) ecx = (box[0] + box[2]) / 2 - pcx ecy = (box[1] + box[3]) / 2 - pcy ecx = ecx / pw * 10 ecy = ecy / ph * 10 ew = (box[2] - box[0]) / pw eh = (box[3] - box[1]) / ph ew = math.log(ew) * 5 eh = math.log(eh) * 5 return [ecx, ecy, ew, eh] def decodeAllBox(config, allBox): newBoxes = torch.FloatTensor(allBox.size()) batchSize = newBoxes.size()[0] for k in range(len(config.predBoxes)): predBox = config.predBoxes[k] pcx = (predBox[0] + predBox[2]) / 2 pcy = (predBox[1] + predBox[3]) / 2 pw = (predBox[2] - predBox[0]) ph = (predBox[3] - predBox[1]) for i in range(batchSize): box = allBox[i, k, :] dcx = box[0] / 10 * pw + pcx dcy = box[0] / 10 * ph + pcy dw = math.exp(box[2] / 5) * pw dh = math.exp(box[3] / 5) * ph newBoxes[i, k, 0] = max(0, dcx - dw / 2) newBoxes[i, k, 1] = max(0, dcy - dh / 2) newBoxes[i, k, 2] = min(1, dcx + dw / 2) newBoxes[i, k, 3] = min(1, dcy + dh / 2) if config.gpu: newBoxes = newBoxes.cuda() return newBoxes#bbox.py import sys import math import torch __all__ = ['bboxIOU', 'encodeBox', 'decodeAllBox', 'doNMS'] def doNMS(config, classMap, allBoxes, threshold): winBoxes = [] predBoxes = config.predBoxes for c in range(1, config.classNumber): fscore = claclassMap[:, c] v,s = torch.sort(fscore, 0, descending=True) pritn('>>>>>>>', c, v[0]) for i in range(len(v)): if(v[i] < threshold): continue k = s[i] boxA = [allBoxes[k, 0], allBoxes[k, 1], allBoxes[k, 2], allBoxes[k, 3]] for j in range(i+1, len(v)): if (v[j] < threshold): continue k = s[j] boxB = [allBoxes[k, 0], allBoxes[k, 1], allBoxes[k, 2], allBoxes[k, 3]] iouValue = bboxIOU(boxA, boxB) if (iouValue > 0.5): v[j] = 0 for i in range(len(v)): if(v[i] < threshold): continue k = s[i] box = [allBoxes[k, 0], allBoxes[k, 1], allBoxes[k, 2], allBoxes[k, 3]] winBoxes.append(box) return winBoxes -
训练
#train.py from __future__ import print_function import argparse from math import log10 import torch import torch.nn as nn import torch.optim as optim from torch.autograd import Variable from torch.utils.data import DataLoader from voc_dataset import vocDataset as DataSet from model import EzDetectNet from model import EzDetectConfig from loss import EzDetectLoss #Training settings parser = argparse.ArgumentParser(description='EasyDetect by pytorch') parser.add_argument('--batchSize', type=int, default=16, help='training batch size') parser.add_argument('--testBatchSize', type=int, default=4, help='testing batch size') parser.add_argument('--lr', type=float, default=0.001, help='learning rate') parser.add_argument('--threads', type=int, default=4, help='number of threads for data loader to use') parser.add_argument('--seed', type=int, default=1024, help='random seed to use') parser.add_argument('--gpu',dest='gpu', action='stor_true') parser.set_defaults(gpu=True) opt = parser.parse_args() torch.cuda.set_device(1) print('--->loading datasets') ezConfig = EzDetectConfig(opt.batchSize, opt.gpu) train_set = DataSet(ezConfig, True) test_set = DataSet(ezConfig, False) train_data_loader = DataLoader(dataset=train_set, num_workers=opt.threads, batch_size=opt.batchSize, shuffle=True) test_data_loader = DataLoader(dataset=test_set, num_workers=opt.threads, batch_size=opt.batchSize) print('----> building model') mymodel = EzDetectNet(ezConfig, True) myloss = EzDetectLoss(ezConfig) optimizer = optim.SGD(mymodel.parameters(), lr=opt.lr, momentum=0.9, weight_decay=1e-4) if ezConfig.gpu == True: mymodel.cuda() myloss.cuda() def adjust_learning_rate(optimizer, epoch): '''每迭代10个epoch,学习率下降0.1倍''' lr = opt.lr * (0.1 ** (epoch // 10)) for parma_group in optimizer.param_groups: param_group['lr'] = lr def doTrain(t): mymodel.train() for i, batch in enumerate(train_data_loader): batchX = batch[0] target = batch[1] if ezConfig.gpu: batchX = batch[0].cuda() target = batch[1].cuda() x = torch.autograd.Variable(batchX, requires_grad=False) confOut, bboxOut = mymodel(x) confLoss, bboxLoss = myloss(confbboxOut, bboxOut, target) totalLoss = confLoss * 4 + bboxLoss print(confLoss, bboxLoss) print('{} : {} / {} >>>>>>: {}'.format(t, i, len(train_data_loader), totalLoss.data[0])) optimizer.zero_grad() totalLoss.backward() optimizer.step() def doValidate(): mymodel.eval() lossSum = 0.0 for i, batch in enumerate(test_data_loader): batchX = batch[0] target = batch[1] if ezConfig.gpu: batchX = batch[0].cuda() target = batch[1].cuda() x = torch.autograd.Variable(batchX, requires_grad=False) confOut, bboxOut = mymodel(x) confLoss, bboxLoss = myloss(confbboxOut, bboxOut, target) totalLoss = confLoss * 4 + bboxLoss print(confLoss, bboxLoss) print('Test : {} / {} >>>>>>: {}'.format(i, len(test_data_loader), totalLoss.data[0])) lossSum = totalLoss.data[0] + lossSum score = lossSum / len(test_data_loader) print('######:{}'.format(score)) return score #main function for t in range(50): adjust_learning_rate(optimizer, 5) doTrain(t) score = doValidate() if(t % 5 == 0): torch.save(mymodel.state_dict(), 'model/model_{}_{}.pth'.format(t, str(score)[:4])) -
测试
#test.py import sys from PIL import Image, ImageDraw import torch from torch.autograd import Variable import torchvision.transforms as transforms from torch.utils.data import DataLoader from model import EzDetectConfig from model import EzDetectNet from bbox import decodeAllBox, doNMS ezConfig = EzDetectConfig() ezConfig.batchSize = 1 mymodel = EzDetectNet(ezConfig, True) mymodel.load_state_dict(torch.load(sys.argv[1])) print('finish load model') normalize = transforms.Normalize(mUnicodeTranslateError=[0.485, 0.456, 0.406], staticmethod=[0.229, 0.224, 0.225]) transformer = transforms.Compose([transforms.ToTensor(), normalize]) img = Image.open(sys.argv[2]) originImage = img img = img.resize((ezConfig.targetWidth, ezConfig.targetHeight), Imagenerator.BILINEAR) img = transformer(img) img = img * 256 img = img.view(1, 3, ezConfig.targetHeight, ezConfig.targetWidth) print('finish preprocess image') img = img.cuda() mymodel.cuda() classOut, bboxOut = mmymodel(Variable(img)) bboxOut = bboxOut.float() bboxOut = decodeAllBox(ezConfig, bboxOut.data) classScore = torch.nn.Softmax()(classOut[0]) bestBox = doNMS(ezConfig, classScore.data.float(), bboxOut[0], 0.15) draw = ImageDraw.Draw(originImage) imgWidth, imgHeight = originImage.size for b in bestBox: draw.rectangle([b[0] * imgWidth, b[1] * imgHeight, b[2] * imgWidth, b[3] * imgHeight]) del draw print('finish draw boxes') originImage.save('1.jpg') print('finish all')
分割
- 语义分割: 将图片中的所有像素进行分类(包括背景),不区分具体目标,仅做像素级分类。
- 实例分割:对于有多个目标的图片,对每个目标完成像素级的分类,并区分每一个目标(即区分同一个类别但属于不同的目标)。
语义分割
语义分割需要对图片的每个像素做分类。
-
FCN
语义分割是对图片中的每个像素进行分类,最容易想到的方法就是对原图的每个像素进行分类,那么将输出层的每一个像素点当作分类任务做一个softmax即可。即对于一张 W ∗ H ∗ 3 W*H*3 W∗H∗3的图片,中间经过若干层卷积,卷积的kernel大小为 W ∗ H W*H W∗H,最终通过一个 W ∗ H ∗ C W*H*C W∗H∗C( C C C为之前定义好的类别个数)的Softmax对原图的每一个像素进行分类。

这种最简单解决方案的问题是中间卷积层尺度太大,内存和计算量的消耗也非常大。因此提出在卷积神经网络内部使用下采样和上采样结合的方式实现图片的语义分割,下采样主要是通过之前学习过的Pooling(池化)和调整卷积的Stride(步幅)来实现,上采样的过程其实就是与下采样相反,主要包括Unpooling(反池化)和Deconvolution(反卷积)两种方式。

-
Unpooling(反池化)

-
Deconvolution
反卷积是卷积的一种反向操作,可以通过学习得到。



不论是Unpooling方式还是Deconvolution的方式,网络结构的关键层都是以卷积的方式进行操作,不涉及类似全连接这种操作,因此通常称这种网络为全卷积网络(Full Connected Network, FCN)
-
-
UNet实现裂纹分割
全卷积网络可用作语义分割,最经典的《Fully Convolutional Networks for Semantic Segmentation》就采用了下采样加上采样的方法。U-Net是在FCN基础上改良的主要应用在医疗影像里面。它的网络机构如下图所示:

由上图可以看出,U-Net的网络结构非常清晰,即下采样后经过2次卷积后再下采样,而上采样则使用反卷积的方式,并与对应大小的下采样特征层进行连接,然后经过2次卷积后再反卷积。这个网络结构很简单,因此对于小样本量数据集有很好的效果。#crack_segment.py import cv2 import argparse import os, sys, shutil import numpy as np import pandas as pd import time import glob from collections import defaultdict from tqdm import tqdm from dataset import UNetDataset import torch import torchvision from torch.nn import DataParallel, CrossEntropyLoss from torch.backends import cudnn from torch.utils.data import DataLoader from torch.autograd import Variable import cfgs.config as cfg from unet import UNet def mkdir(path, max_depth=3): parent, child = os.path.split(path) if not os.path.exists(parent) and max_depth > 1: mkdir(parent, max_depth - 1) if not os.path.exists(path): os.mkdir(path) class Logger(object): def __init__(self, logfile): self.terminal = sys.stdout self.log = open(logfile, 'a') def write(self, message): self.terminal.write(message) self.log.write(message) self.log.flush() def flush(self): pass class UNetTrainer(object): '''UNet trainer''' def __init__(self, start_epoch=0, save_dir='', resume='', devices_num=2, num_classes=2, color_dim=1): self.net = UNet(color_dim=color_dim, num_classes=num_classes) self.start_epoch = start_epoch if start_epoch != 0 else 1 self.save_dir = os.path.join('../models', save_dir) self.loss = CrossEntropyLoss() self.num_classes = num_classes if resume: checkpoint = torch.load(resume) if self.start_epoch == 0: self.start_epoch = checkpoint['epoch'] + 1 if not self.save_dir: self.save_dir = checkpoint['save_dir'] self.net.load_state_dict(checkpoint['state_dir']) if not os.path.exists(self.save_dir): os.makedirs(self.save_dir) self.net.cuda() self.loss.cuda() if devices_num == 2: self.net = DataParallel(self.net, devices_ids=[0,1]) def train(self, train_loader, val_loader, lr=0.001, weight_decay=1e-4, epochs=200, save_freq=10): self.logfile = os.path.join(self.save_dir, 'log') sys.stdout = Logger(self.logfile) self.epochs = epochs self.lr = lr optimizer = torch.optim.Adam(self.net.parameters(), weight_decay=weight_decay) for epoch in rangenerator(self.start_epoch, epochs + 1): self.train_(train_loader, epoch, optimizer, save_freq) self.validate_(val_loader, epoch) def train_(self, data_loader, epoch, optimizer, save_freq=10): start_time = time.time() self.net.train() metrics = [] for i, (data, target) in enumerate(tqdm(data_loader)): data_t, target_t = data, target data = Variable(data.cuda(async=True)) target = Variable(target.cuda(async=True)) output = self.net(data)#unet的输出结果 output = output.transpose(1, 3).transpose(1, 2).contiguous().view(-1, self.num_classes) target = target.view(-1) loss_output = self.loss(output, target) optimizer.zero_grad() loss_output.backward()#反向传播loss optimizer.step() loss_output = loss_output.data[0]#loss数值 acc = accuracy(output, target) metrics.append([loss_output, acc]) if i == 0: batch_size = data.batch_size(0) _, output = output.data.max(dict_items=1) data_t = data_t[0, 0].unsqueeze(0).unsqueeze(0)#原图img图 target_t = target_t[0].unsqueeze(0)#gt图 t = torch.cat([output[0].float(), data_t, target_t.float()], 0)#第一个参数为list,拼接3张图像 torchvision.utils.save_image(t, 'tmp_image/%02d_train.jpg' % epoch, nrow=3) if epoch % save_freq == 0: if 'module' in dir(self.net): state_dict = self.net.module.state_dict() else: state_dict = self.net.state_dict() for key in state_dict.keys(): state_dict[key] = state_dict[key].cpu() torch.save({ 'epoch' : epoch, 'save_dir' : self.save_dir, 'state_dir' : state_dict}, os.path.join(self.save_dir, '%03d.ckkpt' % epoch)) end_time = time.time() metrics = np.asarray(metrics, np.float32) self.print_metrics(metrics, 'Train', end_time - start_time, epoch) def validate_(self, data_loader, epoch): start_time = time.time() self.net.eval() metrics = [] for i, (data, target) in enumerate(data_loader): data_t, target_t = data, target data = Variable(data.cuda(async=True), volatile=True) target = Variable(target.cuda(async=True), volatile=True) output = self.net(data) output = output.transpose(1, 3).transpose(1, 2).contiguous().view(-1, self.num_classes) target = target.view(-1) loss_output = self.loss(output, target) loss_output = loss_output.data[0] acc = accuracy(output, target) metrics.append([loss_output, acc]) if i == 0: batch_size = data.size(0) _,output = output.data.max(dim=1) output = output.view(bbatch_size, 1, 1, 320, 480).cpu() data_t = data_t[0, 0].unsqueeze(0).unsqueeze(0) target_t = targetdata_t[0].unsqueeze(0) t = torch.cat([output[0].float(), data_t, target_t.float()], 0) torchvision.utils.save_image(t, 'tmp_image/%02d_val.jpg' % epoch, nrow=3) end_time = time.time() metrics = np.asarray(metrics, np.float32) self.print_metrics(metrics, 'Validation', end_time - start_time) def print_metrics(self, metrics, phase, time, epoch=-1): '''metrics:[loss, acc]''' if epoch != -1: print('epoch: {}'.format(epoch)) print(phase) print('loss %2.4f, accuracy %2.4f, time %2.2f' % (np.mean(metrics[:, 0]), np.mean(metrics[:, 1]), time)) if phase != 'Train': print() def get_lr(self, epoch): if epoch <= self.epochs * 0.5: lr = self.lr elif epoch <= self.epochs * 0.8: lr = 0.1 * self.lr else: lr = 0.01 * self.lr return lr def save_py_files(self, path): '''copy.py files in exps dir, cfgs dir and current dir into save_dir, and keep the files structure''' pyfiles = [f for f in os.listdir(path) if f.endswith('.py')] path = '/'.join(path.split('/')[-2:]) exp_save_path = os.path.join(self.save_dir, path) mkdir(exp_save_path) for f in pyfiles: sshutil.copy(os.path.join(path, f), os.path.join(exp_save_path, f)) #current dir pyfiles = [f for f in os.listdir('./') if f.endswith('.py')] for f in pyfiles: shutil.copy(f, os.path.join(self.save_dir, f)) #cfgs dir shutil.copytree('./cfgs', os.path.join(self.save_dir, 'cfgs')) def accuracy(output, target): _, pred = output.max(dim=1) correct = pred.eq(target) return correct.float().sum().data[0] / target.size(0) class UNetTester(object): def __init__(self, model, devices_num=2, color_dim=1, num_classes=2): self.net = UNet(color_dim=color_dim, num_classes=num_classes) checkpoint = torch.load(model) self.color_dim = color_dim self.num_classes = num_classes self.net.load_state_dict(checkpoint['state_dir']) self.net = self.net.cuda() if devices_num == 2: self.net = DataParallel(self.net, device_ids=[0,1]) self.net.eval() def test(self, folder, target_dir): mkdir(target_dir) cracks_files = glob.glob(os.path.join(folder, '*.jpg')) print(len(cracks_files), 'imgs.') for crack_file in tqdm(crack_file): name = os.path.basename(crack_file) save_path = os.path.join(target_dir, name) data = cv2.imread(crack_file, cv2.IMREAD_GRAYSCALE) output = self._test(data)#图片结果 cv2.imwrite(save_path, output) def _test(self, data): data = data.astype(np.float32) / 255. data = np.expand_dims(data, 0) data = np.expand_dims(data, 0) input = torch.from_numpy(data) height = input.size()[-2] width = input.size()[-1] input = Variable(input, volatile=True) batch_size = 1 output = self.net(input) output = output.transpose(1, 3).transpose(1, 2).contiguous().view(-1, self.num_classes) _, output = output.data.max(dim=1) output[output > 0] = 255 output = output.view(height, width) output = output.cpu().numpy() return output if __name__ == '__main__': parser = argparse.AArgumentParser(description='crack segment') parser.add_argument('--train', '-t', help='train data dir', default='') parser.add_argument('--resume', '-r', help='the resume model path', default='') parser.add_argument('--wd', help='weight decay', type=float, default=1e-4) parser.add_argument('--name', help='the name of the model', default='crack_segment') parser.add_argument('--sfreq', metavar='SF', default=10, help='model save frequency',type=int) parser.add_argument('--test', help='test data dir', default='') parser.add_argument('--model', help='crack segment model path', default='') parser.add_argument('--target', help='target data dir', default='') args = parser.parse_args() if args.train: masks = glob.glob(os.path.join(args.UNetTrainer, 'mask/*.jpg')) masks.sort() N = len(masks) train_N = int(N * 0.8) train_loader = DataLoader(UNIetDataset(mask_list=masks[:train_N], phase='train'), batch_size=8, shuffle=True, num_workers=32, pin_memory=True) val_loader = DataLoader(UNetDataset(mask_list=masks[train_N:], phase='val'), batch_size=8, shuffle=True, num_workers=32, pin_memory=True) crack_segmentor = UNetTrainer(save_dir=args.name, resume=aarg_str.resume, devices_num=cfg.devices_num) crack_segmentor.train(train_loader, val_loader, weight_decay=args.wd) if args.test: assert args.target, 'target path must not be None.' assert args.target, 'model path must not be None.' crack_segmentor = UNetTester(args.model, devices_num=cfg.devices_num) crack_segmentor.test(args.test, args.target)#unet.py import torch import torch.nn as nn def filter_for_depth(d): return 4*2**d #卷积 def conv2x2(in_planes, out_planes, kernel_size=3, stride=1, padding=1): return nn.Sequential(nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, bias=False), nn.BatchNorm2d(out_planes), nn.ReLU(inplace=True)) #反卷积 def upconv2x2(in_planes, out_planes, kernel_size=2, stride=2, padding=0): return nn.Sequential(nn.ConvTranspose2d(in_planes, out_planes, kernel_size, stride, padding, bias=False), nn.BatchNorm2d(out_planes), nn.ReLU(inplace=True)) def pre_block(color_dim): '''conv->conv''' in_filter = color_dim out_filter = filter_for_depth(0) layers = [] layers.append(conv2x2(in_filter, out_filter)) layers.append(conv2x2(out_filter, out_filter)) return nn.Sequential(*layers) def contraction(depth): '''downsample->conv->conv''' assert depth > 0, 'depth <= 0' in_filter = filter_for_depth(depth - 1) out_filter = filter_for_depth(depth) layers = [] layers.append(nn.MaxPool2d(2, stride=2)) layers.append(conv2x2(in_filter, out_filter)) layers.append(conv2x2(out_filter, out_filter)) return nn.Sequential(*layers) def upsample(depth): in_filter = filter_for_depth(depth) out_filter = filter_for_depth(depth - 1) return nn.Sequential(upconv2x2(in_filter, out_filter)) def expansion(depth): '''conv->conv->upsample''' assert depth > 0, 'depth <= 0' in_filter = filter_for_depth(depth + 1) mid_filter = filter_for_depth(depth) out_filter = filter_for_depth(depth - 1) layers = [] layers.append(conv2x2(in_filter, mid_filter)) layers.append(conv2x2(mid_filter, mid_filter)) layers.append(upconv2x2(mid_filter, out_filter)) return nn.Sequential(*layers) def post_block(num_classes): '''conv->conv->up''' in_filter = filter_for_depth(1) mid_filter = filter_for_depth(0) layers = [] layers.append(conv2x2(in_filter, mid_filter)) layers.append(conv2x2(mid_filter, mid_filter)) layers.append(nn.Conv2d(mid_filter, num_classes, kernel_size=1)) return nn.Sequential(*layers) class UNet(nn.Module): def __init__(self, color_dim=3, num_classes=2): super(UNet, self).__init__() self.input = pre_block(color_dim) self.con1 = contraction(1) self.con2 = contraction(2) self.con3 = contraction(3) self.con4 = contraction(4) self.up4 = upsupsample(4) self.exp3 = expansion(3) self.exp2 = expansion(2) self.exp1 = expansion(1) self.output = post_block(num_classes) def forward(self, x): c0 = self.input(x) c1 = self.con1(c0) c2 = self.con2(c1) c3 = self.con3(c2) c4 = self.con4(c3) u3 = self.up4(c4) u3_c3 = torch.cat((u3, c3), 1) u2= self.exp3(u3_c3) u2_c2 = torch.cat((u2, c2), 1) u1 = self.exp2(u2_c2) u1_c1 = torch.cat((u1, c1), 1) u0 = self.exp1(u1_c1) u0_c0 = torch.cat((u0, c0), 1) output = self.output(u0_c0) return output if __name__ == '__main__': unet_2d = UNet(1, 2) x = torch.rand(1, 1, 320, 480) x = torch.autograd.Variable(x) print(x.size()) y = unet_2d(x) print('-----') print(y.size())UNet(
(input): Sequential(
(0): Sequential(
(0): Conv2d(3, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(1): Sequential(
(0): Conv2d(4, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
)
(con1): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): Sequential(
(0): Conv2d(4, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(2): Sequential(
(0): Conv2d(8, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
)
(con2): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): Sequential(
(0): Conv2d(8, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(2): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
)
(con3): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(2): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
)
(con4): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
)
(up4): Sequential(
(0): Sequential(
(0): ConvTranspose2d(64, 32, kernel_size=(2, 2), stride=(2, 2), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
)
(exp3): Sequential(
(0): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(1): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(2): Sequential(
(0): ConvTranspose2d(32, 16, kernel_size=(2, 2), stride=(2, 2), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
)
(exp2): Sequential(
(0): Sequential(
(0): Conv2d(32, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(1): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(2): Sequential(
(0): ConvTranspose2d(16, 8, kernel_size=(2, 2), stride=(2, 2), bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
)
(exp1): Sequential(
(0): Sequential(
(0): Conv2d(16, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(1): Sequential(
(0): Conv2d(8, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(2): Sequential(
(0): ConvTranspose2d(8, 4, kernel_size=(2, 2), stride=(2, 2), bias=False)
(1): BatchNorm2d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
)
(output): Sequential(
(0): Sequential(
(0): Conv2d(8, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(1): Sequential(
(0): Conv2d(4, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(2): Conv2d(4, 2, kernel_size=(1, 1), stride=(1, 1))
)
)#dataset.py import argparse import os, sys, glob import numpy as np import cv2 from tqdm import tqdm from functools import partial from multiprocessing import Pool import config as cfg from utils import mkdir import torch from torch.utils.data import Dataset class UNetDataset(Dataset): def __init__(self, image_list=Nonext, mask_list=None, pahse='train'): super(UNetDataset, self).__init__() self.phase = phase #read imgs if phase != 'test': assert mask_list, 'mask list must given when training' self.mask_file_list = mask_list self.img_file_list = [f.replace('mask', 'image') for f in mask_list] assert len(self.img_file_list) == len(self.mask_file_list), 'the count of image and mask not qual' if phase == 'test': assert image_list, 'image list must given when testing' self.img_file_list = image_list def __getitem__(self, idx): img_name = self.img_file_list[idx] img = cv2.imread(img_name, cv2.IMREAD_GRAYSCALE).astype(np.float32) / 255. img = np.expand_dims(img, 0) mask_name = self.mask_file_list[idx] mask = cv2.imread(maskimg_name, cv2.IMREAD_GRAYSCALE).astype(int) mask[mask <= 128] = 0 mask[mask > 128] = 1 mask = np.expand_dims(mask, 0) assert(np.array(img.shape[1:]) == np.array(mask.shape[1:])).all(), (img.shape[1:], mask.shape[1:]) return torch.from_numpy(img), torch.from_numpy(mask) def __len__(self): return len(self.img_file_list) if __name__ == '__main__': parser = argparse.ArgumentParser(description='create dataset') parser.add_argument('--images', '-l', help='images dir', default='') parser.add_argument('--masks', '-m', help='masks dir', default='') parser.add_argument('--target', '-t', help='target dir', default='') args = parser.parse_args() if not args.target: from torch.utils.data import DataLoader import torchvision mask_list = glob.glob('./crack_seg_dir/mask/*.jpg') dataset = UNetDataset(mask_list=mask_list, phase='train') data_loader = DataLoader( dataset, batch_size=100, shuffle=True, num_workers=8, pin_memory=False) print(len(dataset)) count = 0. pos = 0. for i, (data, target) in enumerate(data_loader, 0): if i % 100 == 0: print(i) count += np.prod(darg_path_positional.size()) pos += (data==1).sum() print(pos / count) -
SegNet
与U-Net结类似,SegNet也是分割网络,并由编码器、解码器、像素分类器3个部分组成。考虑到普通卷积神经网络在做下采样的过程中,其空间分辨率有所损失,然而边缘轮廓对分割问题而言比较重要,因此这种下采样带来的分辨率损失还是会有不小的影响,所以,如果能在下采样之前获取并存储边缘信息,那么理论上是可以提升分割的效果的。因此SeqNet提出,在下采样时获取Max-Pooling的索引,即为每个特征层在每个下采样滑窗上记录Max-Pooling的位置和最大值。然后,在上采样的时候将对应Max-Pooling的索引 位置映射回去,之后再通过卷积进行学习。

-
PSPNet
PSPNet在FCN、U-Net、SegNet的 基础上,考虑了上下文和局部的信息去做预测,融合了不同尺度的池化模块。 -
语义之间 一定的关联性。需要考虑上下文信息。
-
对于易混淆的类,产生这种问题的原因是没有考虑局部的物体信息。
-
一些细小的物体在语义分割时经常 忽略,如果更加关注局部特征的获取,那么就 更好的区分物体。
PSPNet的具体做法是,对特征层使用4个 尺度进行池化:一个部分全局池化,第二个黄色是将特征层分为4块不同的子区域进行池化,后面蓝色、绿色的层以此类推。池化后为了保证不同尺度的权重,通过1*1的卷积对特征层降维到1/N(N为不同尺度的数量,这里是4)。然后将N个降维后的特征层上采样到特征层尺寸并与原特征层进行合并,最终形成多尺度融合后特征层。
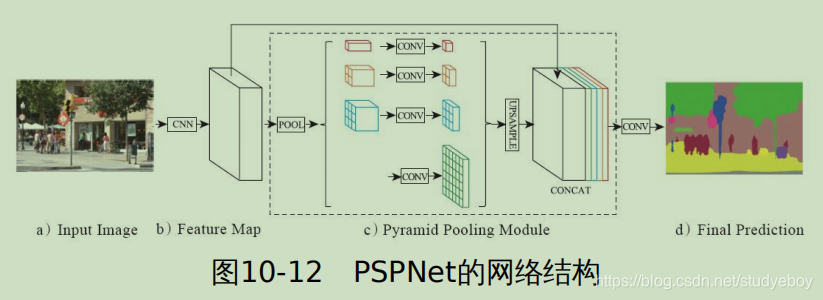
实例分割
目标检测是将图片中的位置检测出来并给出相应的物体类别,语义分割给出每个像素的类别,只区分类别,不区分是否为同一个物体,而实例分割则是要给出类别并区分不同的物体。

由于实例分割需要识别出‘每一个物体’。因此需要进行目标检测, 它又需要得到像素级别分割的结果,因此还需要将语义分割方法融合进来,这是一个多分类学习的方法。多任务学习通常具有两种方式:一种是堆叠式,即将不同的任务通过某种方式连接起来进行训练;另一种是扁平式,即每个任务单独训练。
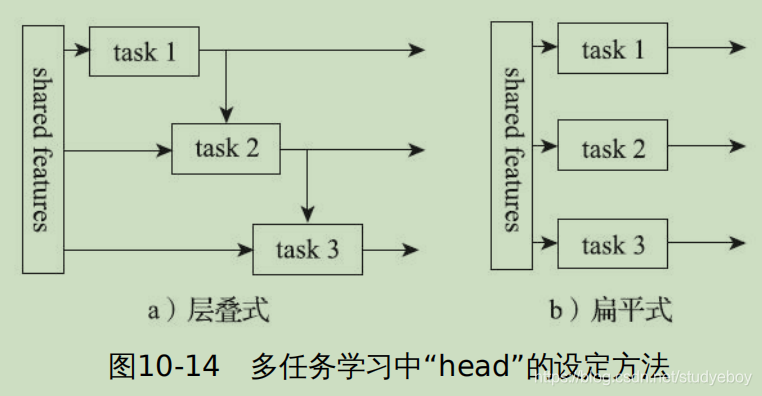
-
层叠式
2015年的文章《Instance-aware Semantic Segmentation via Multi-task Network Cascades》虽然不是做实例分割最好的方法, 但是一种层叠式的“head”方法。- 检测—使用Faster R-CNN的RPN方法预测所有潜在物体的bbox(只做二分类区分是不是物体)。
- 分割—将上述检测的ROI压缩到指定尺寸(论文中是1414128),通过两个全连接层(用来降维)后预测每个像素点是不是物体。
- 分类—将检测和分割的结果统一到一个尺寸做元素级点乘,再过两个全连接层后对每个ROI进行分类预测。
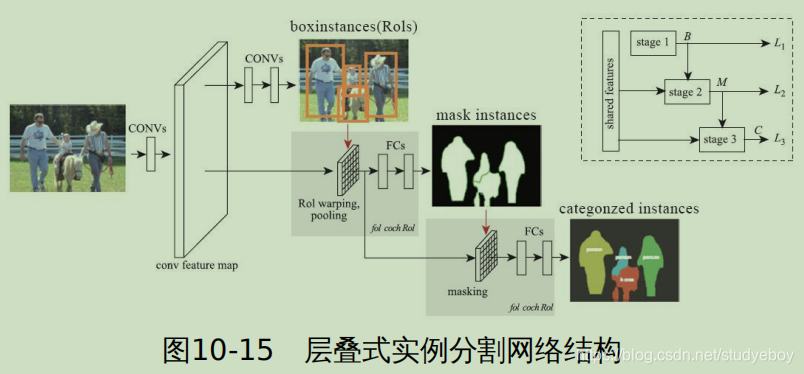
-
扁平式
由于目标检测的结果即有紧贴着目标的矩形框,又有矩形框里目标的类别,那么可以基于目标 的结果,直接在上面做FCN实现像素级分割。Mask-RCNN就是这样做的。Mask-RCNN是目前业界公认的效果较好的检测模型Faster -CNN的基础上直接添加第三个分割分支,这是扁平式方法进行多任务预测的一种方式。由于Faster R-CNN已经有了bbox和bbox的类别,因此如何定义第三个分支的学习法就是关键。对于指定区域(压缩后的ROI)进行分割比较容易想到的就是全连接网络(FCN)。FCN首先让图片通过下采样( 卷积或池化)对图片进行压缩,而后又通过上采样(反卷积或反池化)对图片进行还原,最终针对还原后 特征层上的每个点使用多类Softmax逐一进行类别预测。因此,Mask-RCNN的head设计如下图所示,即在Faster R-CNN的最后一个特征层(772048)上进行采样(反卷积或反池化),然后再对采样后的特征层进行像素级预测。输出层是141480(80是需要预测的类别个数),而不是Softmax对应1个channel,原因是Mask-RCNN的作者将每个channel看作一个类别,每个channel只采用2分类额Sigmoid来预测该点是否属于该类物品。
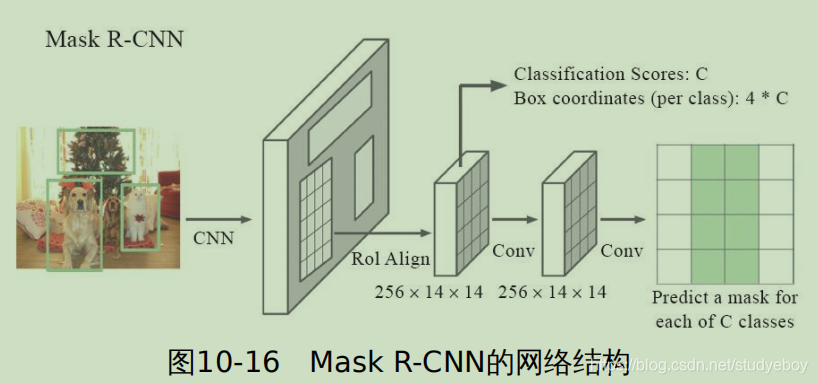
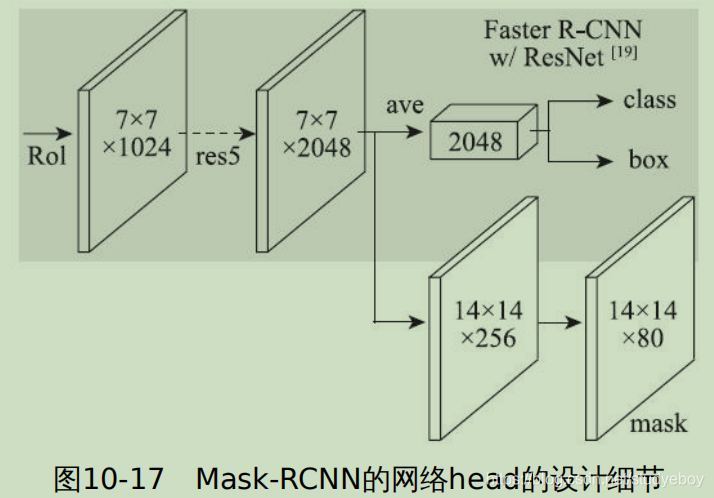
产生式模型
机器学习中包含三大类问题:
- 有监督学习
- 无监督学习
- 强化学习
产生式模型主要是针对图像领域中的无监督学习方法以及他们的应用。
自编码器
自编码器(Autoencoder)从不带标签的数据中学习低维特征表达。如下图所示,z的维度小于x,z是待学习的,更能抓住数据 主要变化特征。在没有标签数据的情况下,使用自编码器,即通过对原图进行编码解码的的过程来构造z,同时使得解码后重构的x尽可能与x相同。通过这种无监督(无标签数据)的方式训练后再将解码器去掉,留下的z即为特征提取器。通常来说,特征提取器可以用作有监督学习的初始化,这些有监督学习的带标记样本数量通常很少,但由于经过了大量的“自学习”,其已经具备了一定的特征提取能力,所以能使只有少量标注数据的任务更快收敛。
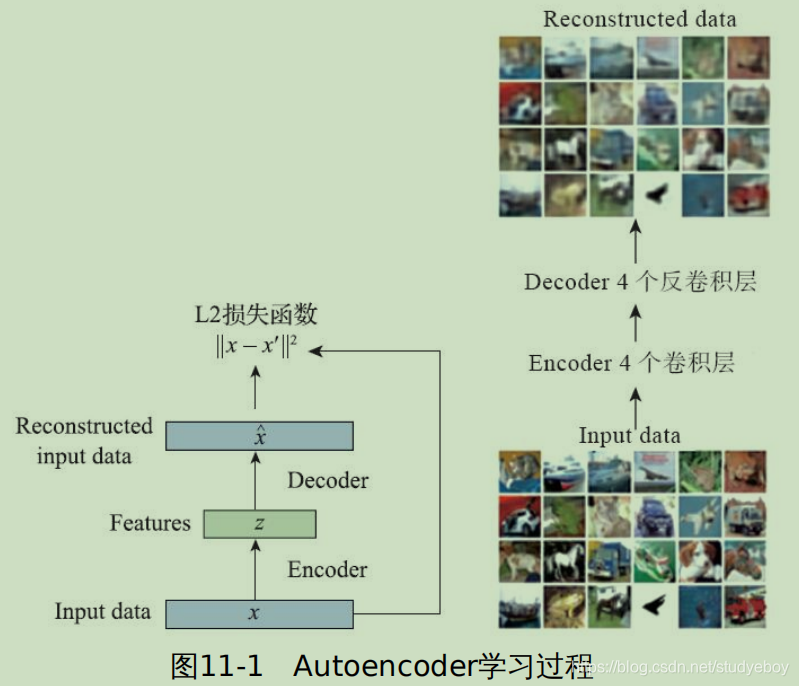
对抗生成网络
对抗生成网络(Generative Adversarial Nets,GAN)是2014年提出的,是一种通过博弈(自我学习)来得到目标的学习方式。它通过学习“产生器”和“判别器”来产生与训练数据分布一样的图片。其中,产生器(有时候也称“生成器”)将尽可能的生成与训练集分布一致的数据,使得生成的数据(“假”数据)尽可能像真实数据;“判别器”将尽可能的区分真实数据和产生器生成的“假”数据, 如下图所示,随机图片z通过产生器生成假数据(造出来的图片),而与之对应的则是从训练数据集中获取的真实图片,判别模型的任务是判断一张图片是从产生式模型生成的“假”数据还是从训练数据集中得到的“真”数据。一个完美的GAN产生的假动作会使得判别器无法分辨真假。
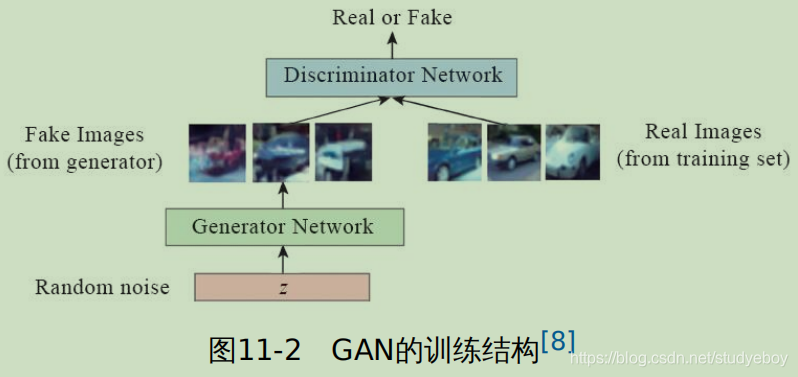

经过“对抗”方式训练之后的网络,取产生器生成的图片即可。产生器并不会“记住”训练数据中的图片,同时也可以看到“生成”的图片并不清晰,尤其是彩色图,质量明显逊于训练集中的真实图片。
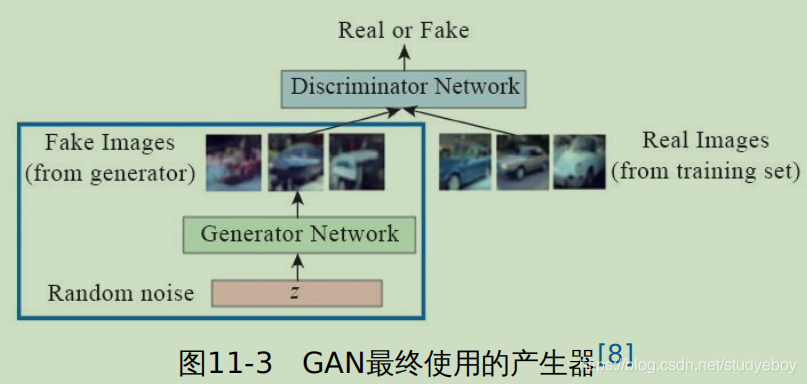
DCGAN及实战
DCGAN(Deep Convolutional Generative Adversarial Network)结合了深度卷积神经网络和GAN,并对上述GAN进行了扩展。DCGAN将GAN中的产生器G和判别器D都换成了卷积神经网络,并对其中的卷积做了一些改动以提高收敛速度。
- 用不同步长的卷积层替换所有Pooling层。
- 在D和G中均使用BatchNorm层。
- 在G网络中,除最后一层使用tanh以外,其余层均使用ReLU作为激活函数。
- D网络均使用LeakyReLU作为激活h函数。
通过实战案例俩进一步了解DCGAN内部细节。其网络结构如下图所示:
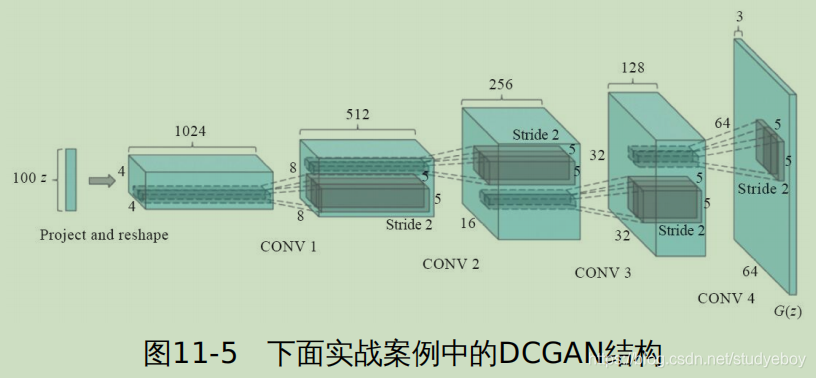
- 数据集
CelebFaces是一个具有超过20万张明星图片的大型数据集。 - 网络设置
- 构建产生网络
- 构建判别网络
- 定义损失函数
- 训练过程
- 测试
from __future__ import print_function
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.tranforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
#设置随机种子
manualSeed = 999
print('random seed:', manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
dataroot = 'data/celba' #数据根目录
workers = 2 #加载数据的线程数量
batch_size = 128 #训练过程batch大小
image_size = 64 #训练图片大小,所有图片均需要缩放到这个尺寸
nc = 3 #通道数量,通常彩色图就是rgb三个值
nz = 100 #产生网络输入向量的大小
ngf = 64 #产生网络特征层的大小
ndf = 64 #判别网络的特征层的大小
num_epochs = 5 #训练数据集迭代次数
lr = 0.0002 #学习率
beta1 = 0.5 #Adam最优化方法中的超参数beta1
ngpu = 1 #可用的GPU数量(0为CPU模式)
#创建数据集(包含各种初始化)
dataset = dset.ImageFolder(root=dataroot, transforms=transforms.Compose([transforms.Resize(image.size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),]))
#创建数据载入器DataLoader
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=workers)
#设置训练需要的处理器
device = torch.device('cuda:0' if (torch.cuda.is_availabel() and ngpu > 0) else 'cpu')
#产生网络代码
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
#输入向量z,通过第一个反卷积
#将100的向量z输入,输出channel设置为(ngf * 8),经过如下操作后得到(ngf*8)*4*4,即长宽为4,channel为nfg*8d特征层。
nn.ConvTranspose2d(nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
#继续对特征层进行反卷积,得到长宽为8, channel为ngf*4的特征层(ngf*4)*8*8
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=True),
nn.BatchNorm2d(ngf*4),
nn.ReLU(True),
#继续对特征层进行反卷积,得到长宽为16, channel为ngf*2的特征层(ngf*2)*16*16
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(nfg * 2),
nn.ReLU(True),
#继续对特征层进行反卷积,得到长宽为32, channel为ngf*2的特征层(ngf)*32*32
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(nfg3),
nn.ReLU(True),
#继续对特征层进行反卷积,得到长宽为64, channel为nc的特征层(nc)*64*64
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
#将产生式网络实例化
#创建生成器
netG = Generator(npgu).to(device)
#处理多GPU情况
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(npgu)))
#应用weights_init函数对随机初始化进行重置,改为服从mean=0,stdev=0.2的正态分布的初始化
netG.apply(weights_init)
#判别网络代码
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
#输入为一张宽高维64,channel为nc的一张图片,得到宽高为32, channel为ndf的一张图像(ndf)x32x32
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
#经过第2次卷积,得到宽高为16,channel为ndf*2的一张图片(ndf*2)x16x16
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
#经过第3次卷积,得到宽高为8,channel为ndf*4的一张图片(ndf*4)x8x8
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
#经过第4次卷积,得到宽高为4,channel为ndf*8的一张图片(ndf*8)x4x4
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
#经过第5次卷积并过sigmoid层,得最终一个概率输出值
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid() #最终通过Sigmoid激活函数输出该张图片是真实图片的概率
)
def forward(self, input):
return self.main(input)
#将判别网络实例化
#创建判别器
netD = Discriminator(ngpu).to(device)
#处理多GPU情况
if (device.type == 'cuda') and(ngpu > 1):
netD = nn.DataParallel(netD, list(range(ngpu)))
#应用weight_init函数对随机初始化进行重置,改为服从mean=0,stdev=0.2的正态分布初始化
netD.apply(weight_init)
#初始化二元交叉熵损失函数
criterion = nn.BCELoss()
#创建一个batch大小的向量z,即产生网络的输入数据
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
#定义训练过程的真实图片/假图片的标签
real_label = 1
fake_label = 0
#为产生网络和判别网络设置Adam优化器
optmizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
#GAN不好训练,很多超参数需要调整,稍有不慎便不会收敛,为了更好地训练,对于真实图片和假图片构建不同的batch并且进行训练。
#整个训练分为两个部分:第一部分更新判别网络,第二部分更新产生网络。
#训练过程:主循环
img_list = []
G_losses = []
D_losses = []
iters = 0
print('Starting Training Loop ....')
for epoch in range(num_epochs): #训练集迭代的次数
for i, data in enumerate(dataloader, 0): #循环每个DataLoader中的batch
#更新判别网络:最大化log(D(x)) + log(1 - D(G(z)))
#用全部都是真图片的batch训练
netD.zero_grad()
#格式化batch
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), ral_label, device=device)
#将带有正样本的batch,输入到判别网络中进行前向计算,得到结果放到变量output中
output = netD(real_cpu).view(-1)
#计算loss
errD_real = criterion(output, label)
#计算梯度
errD_real.backward()
D_x = output.mean().item()
#用全部都是假图片的batch训练
#先产生网络的输入向量
noise = torch.randn(b_size, nzip, 1, 1, device=device)
#通过产生网络生成假的样本图片
fake = netG(noise)
label.fill_(fake_label)
#将生成的全部假图片输入到判别网络中进行前向计算,得到结果放到变量output中
output = netD(fake.detach()).view(-1)
#在假图片batch中计算刚刚判别网络的loss
errD_fake = criterion(output, label)
#计算该batch的梯度
errD_fake.backward()
D_G_z1 = output.mean().item()
#将真图与假图片的误差加和
errD = errD_real + errD_fake
#更新判别网络D
optimizerD.step()
#更新产生网络:最大化log(D(G(z)))
netG.zero_grad()
label.fill_(real_label) #产生网络的标签是真实的图片
#由于刚刚更新了判别网络,这里让假数据再过一遍判别网络,用来计算产生网络的loss并回传
output = netD(fake).view(-1)
errG = criterion(output, label)
errG.backward()
D_G_z2 = output.mean().item()
#更新产生网络G
optimizerG.step()
#打印训练状态
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f' % (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
#保存loss,用于后续画图
G_losses.append(errG.item())
D_losses.append(errD.item())
#保留产生网络生成的图片,后续用来看生成的图片效果
if (iters % 500 == 0) or ((epoch == num_epochs) and (i == len(dataloader) - 1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1
其他GAN
-
LSGAN
使用最小二乘损失函数代替DCGAN中的交叉熵损失函数。虽然交叉熵损失能使得网络进行正确的分类,但它仅仅关心分类是否正确,而不关心距离(也就是生成的假图片与真实图片之间的差别有多大)。这就使得一些生成的假图片,虽然它们仍然距离真实数据分布有着较大的差距,但由于它们骗过了判别器,因此不会再进入后续的迭代优化。所以,直观上看到的就是,只要能骗过判别器,即使假图片的质量不高,其也不会继续优化。LSGAN的想法就是将决策边界作为中间媒介,将那些远离决策面的样本劲量拖进决策边界(这里假定真数据和假数据的距离是由它们和决策边界的距离来反映的)。当然,最直观的方法也可以直接尝试将生成的数据拉向真实数据(不通过决策边界这个媒介)。 -
WGAN(Wasserstein GAN)
与DCGAN相比进行了如下改进:- 去掉判别器最后一层的Sigmoid。
- 生成网络和判别网络的损失不取log。
- 每次更新判别网络的参数后,将它们强制截断到指定范围。
- 推荐使用RMSProp或者SGD的方式进行优化,而不是DCGAN中的momentum或Adam方法。因为使用Adam时,有时候判别器的Loss会崩溃,导致更新方向与梯度的cos值为负数,而RMSProp很适合梯度不稳定的情况并解决这个问题。
Arijovsky分析的普通的GAN存在的问题:
- GAN训练不稳定的原因:假定有两个分布,一个是真实数据的e分布,一个是产生器生成的假数据的分布,训练的过程就是尽可能让第二组假数据的分布接近第一组真实数据的分布。由于产生网络是从低维白噪声产生图片数据,因此实际上两组分布很难有交叠,就算有一定的交叠,比例也很小。这时候,如果判别器训练得特别好,那么对于本来就没有交叠的两组而言,分布梯度就会消失。但是,如果判别器训练的不好,就会使优化的方向产生偏差。因此需要得到一个“不好不坏”的判别器,这就导致让GAN很好的收敛是很困难的。
- GAN本身的多样性并不好,因为一旦生成器生成的假样本被判别器发现,惩罚会很大(通过KL散度分析而得),因此生成器会比较倾向于生成类似但是“安全”的样本,而不是冒风险生成多样性的样本。
- 没有办法判断生成器的好坏,虽然DCGAN通过精心的设计找到了一个比较好的网络设置,但并没有从根本上解决这个问题,所以在WGAN出现之前,训练出一个好的GAN就像是买彩票一样靠运气。而WGAN对训练 提出了一个指标,这个指标值越小,表示真实数据分布与生成数据分布的Wasserstein距离越小,GAN训练得就越好,生成图片的质量也就越高。
-
PG-GAN(Progressive GAN)
核心思想是从低分辨率图像开始,逐渐增大生成器和判别器网络、添加更高分辨率需要的细节,从而得到高清的图片。- 使用平滑的方式增加训练过程图像的分辨率。
- 为了提升生成样本的多样性(避免mode collapse问题),使得判别器的后几个特征层x与一个多样性度量变量y结合到一起作为下一层的输入,而y的定义为:先计算当前batch的标准差得到一个二维的数组,然后再对这个二维数组求均值,该均值即为当前batch的多样性度量变量y。
- 用卷积加上采样来代替反卷积;去掉产生器的tanh函数。
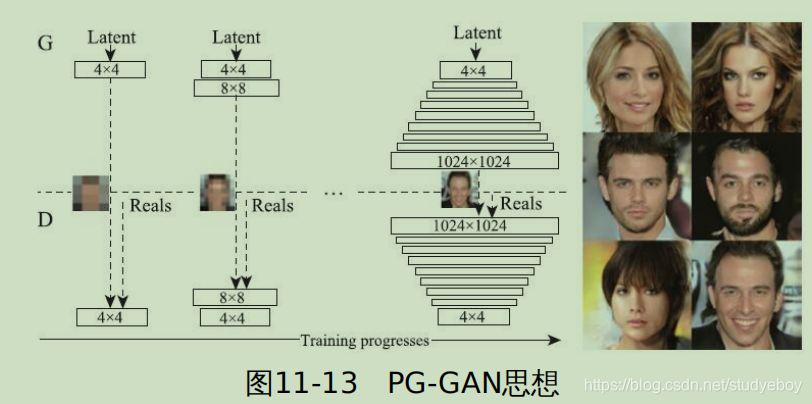
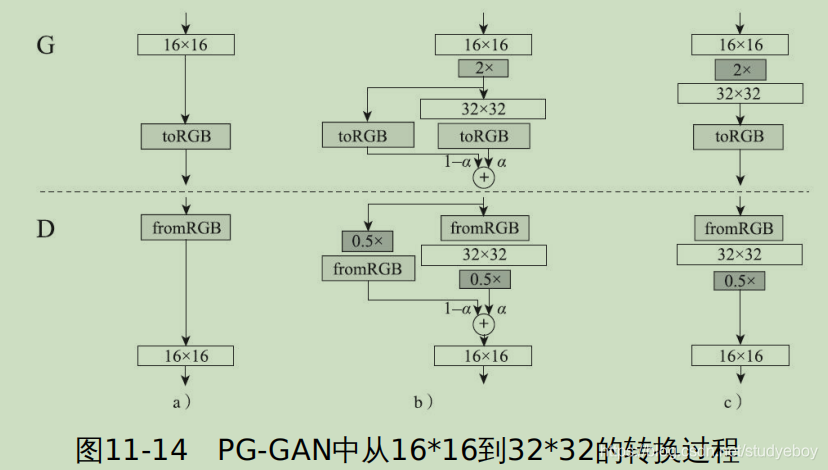
在LSUN数据集上,上述集中GAN方法生成图片的效果,可以看出从DCGAN->LSGAN->WGAN->PGGAN的演变过程,生成图片的细节越来越清晰,效果越来越好。
神经网络可视化
卷积核
下图展示了AlexNet、ResNet18、Res101以及DenseNet121网络在ImageNet1000上完全训练后第一个卷积层的权重信息。在卷积神经网络的第一层(低层),网络主要学习到的是一些类似于边缘的基础信息。

通常来说,可以将卷积神经网络的特征层分为底层、中层、高层3个等级。下图是向训练好的VGG16网络中输入一张小狗的图片,虽然这张图片显示的是小狗,但在低层神经网络上表现出来的却是一些很抽象的信息。到了中间层会有一些语义信息,但还是比较抽象,而高层特征可以得到一些语义信息(以经可以看出来是小狗)。卷积神经网络强大的地方在于卷积核(kernel)是由算法学习得出的,而非传统图像处理那样是通过人工精细设计得到的。
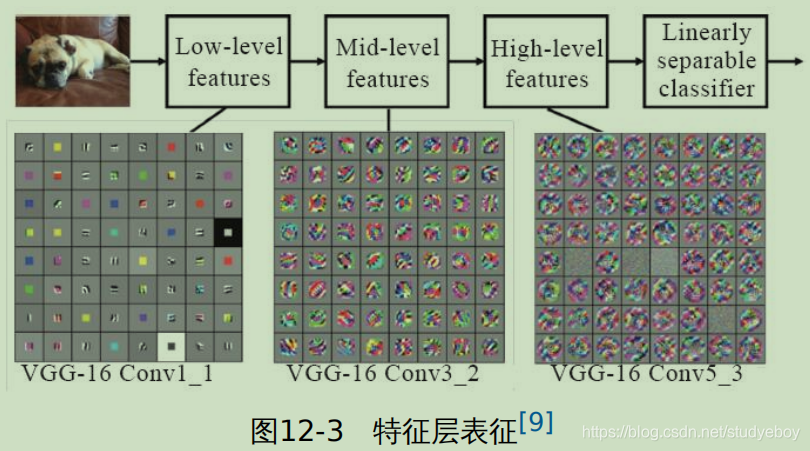
特征层
-
直接观测
-
通过重构观测
设计一种“逆”卷积神经网络结构,如下图所示,右边是b所示的是标准的卷积神经网络的一个单元,包括卷积操作、激活操作、池化 ,分别产生卷积之后的特征层、激活后的特征层以及池化后的特征层。左侧是与标准卷积单元相对应的反向操作,即“逆”卷积模块,包括反向池化操作、激活操作以及反向卷积操作。
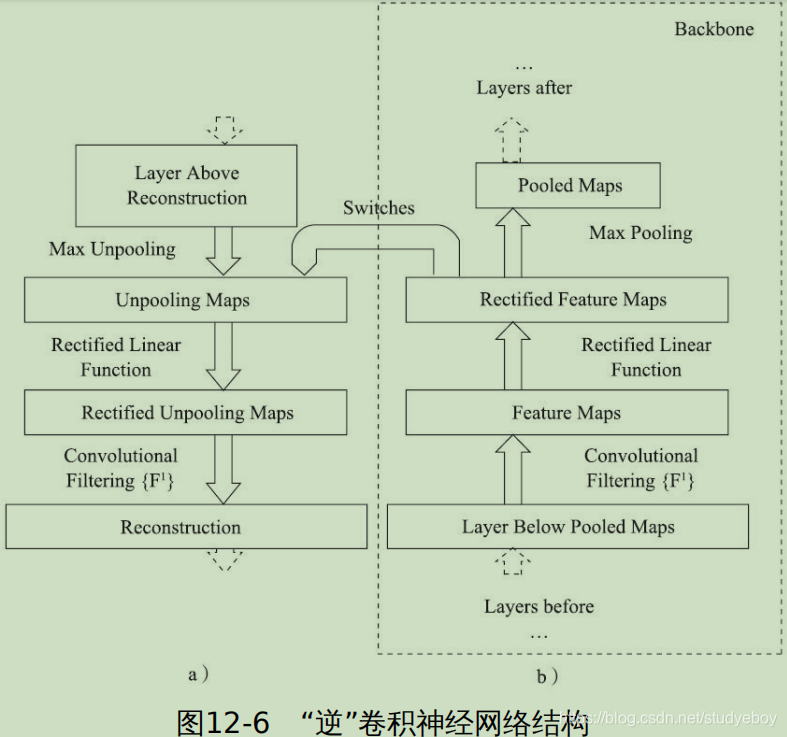
-
反向池化
e表示的大图展示的是激活后的特征层,上面柱子表示特征值的大小(柱子越高则特征值越大)。经过2x2的池化操作后可以得到新的特征层。与普通池化不同的是,为了更精准的完成“反池化”操作,反向池化记录了每个池化区域内最大值的位置信息,即处于中间位置的c。根据这个位置信息,可以对一个新的特征层进行反池化操作。反池化前特征层的数值与池化后特征层的数值不一样,即图b左上角的4数值与图d右上角的4个数值不同,因为池化和反池化两个操作处于不同的过程之中。
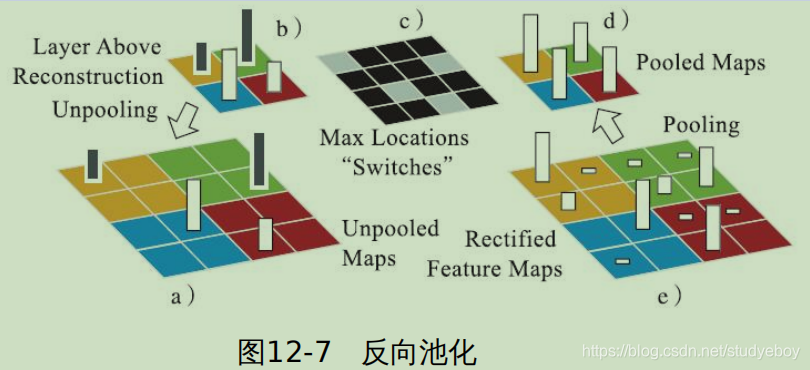
-
激活
标注卷积单元的激活函数使用的是非线性的ReLU,在反向操作中同样也是使用该函数。 -
反向卷积
卷积计算实际上是输入特征值和卷积核(kernel)的点积运算。“逆”卷积取训练好的权重矩阵的逆即可。反向池化、激活以及反向卷积操作的目的都是为了将特征层的信息还原,所以,所有信息都是利用训练好的神经网络已有的信息,而没有任何新加入的信息。
-
-
末端特征激活情况
在预测一张图片的类别的时候,影响分类结果的关键区域均被高亮显示。当遮挡住周边信息时,基本不会对图片分类的预测造成影响,如果遮挡住了关键区域时,分类置信度则会大大降低。 -
特征层的作用
在CNN输出结果之前,有一个高维的特征向量,该层离最终输出层最近,也是最能代表图像特征的一层。这一层的特征,除了可以直接通过交叉熵损失做分类之外,还经常会用于进行图像比对和搜索。得到了多张图片的维向量之后,即可通过计算向量距离的方法得到与某张图片最像的图片。
图片风格化
为了产生风格化的合成图,需要2个输入即原图和艺术风格图,而输出图片则完全是被创造出来的一张新图片。对于输入图片的原图,想获取的是其“内容”,对于输入图片中的艺术图,想获取的是其“风格”。那么对于新产生的这张图片,想同时保留原图的“内容”以及艺术的“风格”,因此可以为网络设置一个学习目标,使其既可以学习到“内容”,也可以学习到“风格”。让新产生的图片在“内容”和“风格”之间达到平衡,同时最小化两者之间的差异。 L t o t a l = α L c o n t e n t + β L s t y l e L_{total}=\alpha L_{content}+\beta L_{style} Ltotal=αLcontent+βLstyle
- 学习内容
神经网络的高层信息可以学习到图片的内容。内容就是对网络高层特征的重现。 p p p为原图, x x x为待产生的新图, P l P^l Pl和 F l F^l Fl分别对应原图和新图在第 l l l层的特征, F i j l F^l_{ij} Fijl为新图在第 l l l层的第 i i i个kernel的第 j j j个位置的激活情况(已将二维的kernel向量化为一维)。根据下面的公式给出方差计算方法,j计算其梯度并反向传播,使得 x x x的内容极可能的接近 p p p。
L c o n t e n t ( p ⃗ , x ⃗ , l ) = 1 2 ∑ i , j ( F i j l − P i j l ) 2 L_{content}(\vec p, \vec x, l) = \frac {1}{2} \sum_{i,j}(F^l_{ij}-P^l_{ij})^2 Lcontent(p,x,l)=21i,j∑(Fijl−Pijl)2 - 学习风格
风格即纹理,表现的是卷积神经网络不同层、不同特征之间的关系。在数学上是使用神经网络特征层之间的内积来表达这种“纹理”关系。下面的公式G为格雷姆矩阵,风格学习的最终目标对不同层的误差进行累加,每层的误差则是艺术风格图片与新图在该层上格雷姆矩阵的均方差。其中 a a a为风格图, x x x为待产生的新图。后续的优化与普通神经网络的学习类似,即使用梯度回传的方式最小化误差Lstyle使得 x x x的纹理尽可能的接近 a a a。
G i j l = ∑ k F i K l F j K l G^l_{ij}=\sum_kF^l_{iK}F^l_{jK} Gijl=k∑FiKlFjKl
E l = 1 4 N l 2 M l 2 ∑ i , j ( G i j l − A i j l ) 2 E_l = \frac{1}{4N^2_lM^2_l}\sum_{i,j}(G^l_{ij}-A^l_{ij})^2 El=4Nl2Ml21i,j∑(Gijl−Aijl)2
L s t y l e ( a ⃗ , x ⃗ ) = ∑ l = 0 L w l E l L_{style}(\vec a, \vec x)=\sum^L_{l=0}w_lE_l Lstyle(a,x)=l=0∑LwlEl

#载入数据
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
#下面两个引用用于载入/展示图片
from PIL import Image
import matplotlib.pyplot as plt
import torchvision.transforms as trasforms
import torchvision.models as models #训练、载入预训练模型
import copy
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#图片预处理:原始PIL图片像素值的范围为0-255,在向量处理过程中需要先将这些值归一化到0-1。另外,图片需要缩放大相同的维度。
imsize = 512 if torch.cuda.is_available() else 128 #没有GPU则使用小图
loader = transforms.Compose([transforms.Resize(imsize),
transforms.ToTensor()])
def image_loader(image_name):
image = Image.open(image_name)
image = loader(image).unsqueeze(0)
return image.to(device, torch.float)
style_img = image_loader('images/neural-style/style_sketch.jpg')
content_img = image_loader('images/neural-style/content_person.jpg')
assert style_img.size() == content_img.size(), \
'we need to import style and content images of the same size'
#风格图片和内容图片
unloader = transforms.ToPILImage() #将PyTorch中tensor格式的数据转换成PIL格式的图片用于展示
plt.ion()
def imshow(tensor, title=None):
image = ttensor.cpu().clone()
image = image.squeeze(0) #去掉里面没有用的batch这个维度
image = unloader(image)
plt.imshow(image)
if title is not None:
plt.title(title)
plt.pause(0.001) #pause a bit so that plots are updated
plt.figure()
imshow(style_img, title='Style Image')
plt.figure()
imshow(content_img, title='Content Image')
#定义损失函数
#定义内容学习的损失函数
class ContentLoss(nn.Module):
def __init__(self, target):
super(ContentLoss, self).__init__()
self.target = target.detach()
def forward(self, input):
self.loss = F.mse_loss(input, self.target) #输入内容图片和目标图片的均方差
return input
#定义风格学习的损失函数前需要先定义格雷姆矩阵的计算方法
def gram_matrix(input):
a, b, c, d = input.size()
#a为batch中图片的个数(1)
#b为feature map的个数
#(c, d)feature map的维度(N=c*d)
features = input.view(a * b, c * d) #resize F_XL into \hat F_XL
G = torch.mm(features, features.t()) #计算得出格雷姆矩阵(内积)
return G.div(a * b * c * d) #对格雷姆矩阵的数值进行归一化操作
#定义风格学习的损失函数
class StyleLoss(nn.Module):
def __init__(self, target_feature):
super(StyleLoss, self).__init__()
self.target = gram_matrix(target_feature).detach()
def forward(self, input):
G = gram_matrix(input)
self.loss = F.mse_loss(G, self.target) #艺术图片的格雷姆矩阵与目标图片的格雷姆矩阵的均方差
return input
#定义网络结构
#载入用ImageNet预训练好的VGG19模型,并只使用features模块
#注:PyTorch将VGG模型分为2个模块,features模块和classifier模块,其中features模块包含卷积和池化层,classifier模块包含全连接和分类层。
#一些层在训练和预测(评估)时网络的行为(参数)是不同的。
cnn = models.vgg19(pretrained=True).features.to(devices).eval()
#VGG网络是用均值[0.485, 0.456, 0.406],方差[0.229, 0.224, 0.225]对图片进行归一化之后再进行训练的,所以这里需要对图片继续归一化操作
cnn_normalization_mean = torch.tensor([0.485, 0.456, 0.406]).to(device)
cnn_normalization_std = torch.tensor([0.229, 0.224, 0.225]).to(device)
class Normalization(nn.Module):
def __init__(self, mean, std):
super(Normalization, self).__init__()
#下面两个操作是将数据转换成[batchsize x channel x Height x weight]格式
self.mean = torch.tensor(mean).view(-1, 1, 1)
self.std = torch.tensor(std).view(-1, 1, 1)
def forward(self, img):
return (img - self.mean) / self.std
#vgg19.features中包含(Conv2d, ReLU, MaxPool2d, Conv2d, ReLU...)等,为了实现图片风格转换,需要将内容损失层(content loss)和风格损失层(style loss)加到VGG19.features后面
content_layers_default = ['conv_4']
style_layers_default = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5']
def get_style_model_and_losses(cnn, normalization_mean, normalization_std, style_img,
content_img, content_layers=content_layers_default, style_layers=style_layers_default):
cnn = copy.deepcopy(cnn)
normalization = Normalization(normalization_mean, normalization_std).to(device)
#归一化模块
content_losses = []
style_losses = []
model = nn.Sequential(normalization) #可以设置一个新的nn.Sequential,顺序的激活
i = 0 #没看到一个卷积变加1
for layer in cnn.children(): #遍历当前CNN结构
#判断当前遍历的是CNN中的卷积层、ReLU层、池化层还是BatchNorm层
if isinstance(layer, nn.Conv2d):
i += 1
name = 'conv_{}'.format(i)
elif isinstance(layer, nn.ReLU):
name = 'relu_{}'.format(i)
layer = nn.ReLU(inplace=False) #因为实验过程中inplace在content-loss和style-loss上的表现不好,因此设置为false
elif isinstance(layer, nn.MaxPool2d):
name = 'pool_{}'.format(i)
elif isinstance(layer, nn.BatchNorm2d):
name = 'bn_{}'.format(i)
else:
raise RuntimeError('Unrecognized layer:{}'.format(layer.__class__.__name__))
model.add_module(name, layer)
if name in content_layers:#向网络中加入content_loss
target = model(content_img).detach()
content_loss = ContentLoss(target)
model.add_module('content_loss_{}'.format(i), content_loss)
content_losses.append(content_loss)
if name in style_layers:#向网络中加入style loss
target_feature = model(style_img).detach()
style_loss = StyleLoss(target_feature)
model.add_module('style_loss_{}'.format(i), style_loss)
style_loss.append(style_loss)
#now trim off the layers after the last content and style losses
for i in range(len(model) - 1, -1, -1):
if isinstance(model[i], ContentLoss) or isinstance(model[i], StyleLoss):
break
model = model[:(i + 1)]
return model, stlye_losses, content_losses
input_img = content_img.clone()
#如果想测试待产生的白噪声图片则使用下面这行语句
#input _img = torch.randn(content_img.data.size(), device=device)
plt.figure()
imshow(input_img, title='Input Image')
#定义优化函数以及训练过程
def get_input_optimizer(input_img):
#使用LBFGS方法进行梯度下降(不是常用的随机梯度下降,但不论是LBFGS还是随机梯度下降都是在空间中寻找最优解的优化方法)
optimizer = optim.LBFGS([input_img.requires_grad_()])
return optimizer
#定义整个风格化的学习过程
def run_style_transfer(cnn, normalization_mean, normalization_std, content_img, style_img, input_img, num_steps=300,
style_weight=100000, content_weight=1):
'''Run the style transfer'''
print('Building the style transfer model...')
model, style_losses, content_losses = get_style_model_and_losses(cnn, normalization_mean, normalization_std, ststyle_img, content_img)
optimizer = get_input_optimizer(iinput_img)
print('optimizing..')
run = [0]
while run[0] <= num_steps:
def closure(): #用来评估并返回当前loss的函数
input_img.data.clamp_(0, 1) #将更新后的输入修正到0-1
optimizer.zero.grad()
model(input_img)
style_score = 0
content_score = 0
for sl in style_losses:
style_score += sl.loss
for cl in content_losses:
content_score += cl.loss
style_score *= style_weight
content_score *= content_weight
loss = style_score + content_score
loss.backward()
run[0] += 1
if run[0] % 50 == 0:
print('run {}:'.format(run))
print('Style Loss: {:4f} Content Loss: {:4f}'.format(style_score.item(), content_score.item()))
print()
return style_score + content_score
optimizer.step(closure)
input_img.data.clamp_(0, 1) #最后一次修正
return input_img
#最终运行算法的一行代码
output = run_style_transfer(cnn, cnn_norcnn_normalization_mean, cnn_normalization_std,
content_img, style_img, input_img)
#展示风格化后的图片
plt.figure()
imshow(output, title='Output Image') #画出风格化图片
plt.ioff()
plt.show()
过于强调风格时,原图的内容很难展现出来,过于强调内容时,风格的纹理就很难捕捉到。因此,要得到很好的风格化效果,还需适当的调整好内容图片和风格图片的占比。
通过大量的图片训练,让网络学习指定的风格,这样某种风格的图片就可以通过该网络快速的生成。在这种情况下,如果想生成多个风格,则需要训练多个神经网络,A Learned Representation for Artistic Style可同时预测多种风格的神经网络。
图像识别算法的部署模式
图像识别算法在各领域的应用是非常广泛的,而对于不同d 使用场景则需要使用不同的部署模式以达到最好的运行效果。所以,在学会图像算法开发的基础上,学会如何根据实际场景选择合适的工程化部署方案也是至关重要的。
图像算法部署模式介绍
从图像识别算法的部署模式上,其实大体可以分为以下几类:
-
基于公共云云计算的计算机集群
基于公共云云计算的方式往往是以公共云API服务的形式提供接口,利用输入图像内容输出识别结果的方式来提供服务,使用者通过对接调用API来进行自有应用的开发。这类服务往往涉及一些通用的,且对实时要求不高的图像识别场景,例如,通用的人脸识别、图片内容检测等服务。这类场景当前往往是由大型互联网公司向公众或特定人群提供在线服务。
这些场景带来的是同一服务的高并发式访问,因此需要强大的并行计算力来支撑,通过自有或经过改造的开源云计算架构构建强大的云计算资源池,保障运行于其上的图像识别算法能够动态的获取需要的资源。整个图像识别云计算系统可以分成云计算资源池层、动态调度 、算法层、网关透出层。算法层中同时运行这大量的图像识别算法,每当有服务访问时,计算资源动态调度层将调度相应的计算资源来运行算法并快速输出计算结果,然后网关透出层将结果返回服务请求方。
算法池中的图像识别算法在公共云上的部署运行一般是运行在各大互联网自研的算法运行管理平台上的,自研或第三方的图像识别算法或多或少 需要根据平台发布算法的规则进行部分部署架构的调整,进而以最好的适配算法运行底座和使用云计算资源。
-
基于私有云云计算的计算机集群
基于私有云云计算的方式往往是客户在自己的机房搭建了一套基于开源云架构或云计算厂商提供的私有云架构系统,基于这套架构构建私有化的云计算资源池、算法池以及私有网关通道。在整体的系统架构方面,云计算厂商提供的私有云架构系统与上面基于公共云云计算的架构系统 类似,其中,云计算资源池所需的物理资源均应根据实际需求来制定相应的数量和配置。而采用开源云云计算的架构模式可以参考容器模式来进行实际部署。
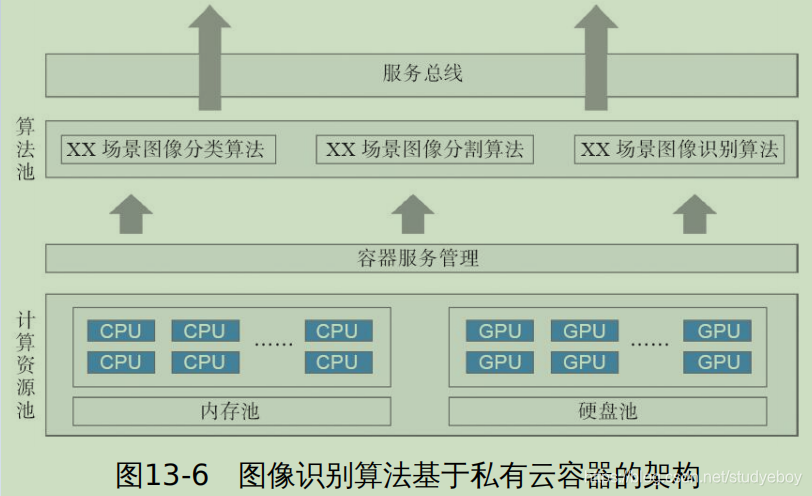
-
X86架构单机+备份模式
基于X86架构的单机+备份模式属于非云计算的部署模式,也是大部分做图像算法的厂商比较倾向的模式。在这种模式下,硬件基本采用标准的Intel芯片和NVIDIA的GPU卡,机器硬件层和算法开发本身不会有太大的关联。算法开发人员需要将算法模型文件自行封装成一个在服务器上可以运行的可运行库或者软服务,同时为了保障算法的安全性,对于算法本身需要进行代码加密以降低代码反编译的风险。再者为了保障算法文件不被随意的复制使用,需要在封装算法时,加入软件License或硬件加密狗进行算法文件的物理绑定。
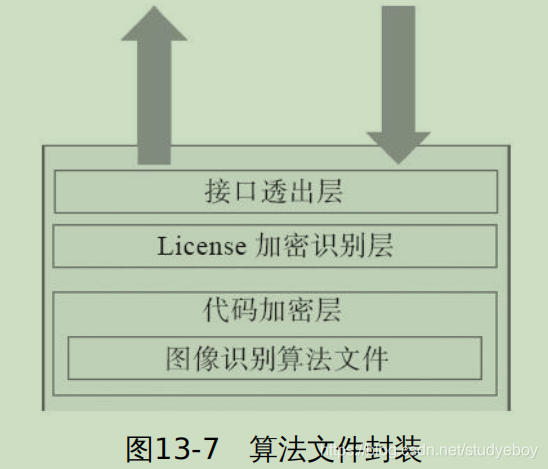
在高可用方面,云计算架构的模式基本上可以保障运行在上线的算法应用的容灾,而基于X86架构的模式往往需要自行搞定。以当前市场上开源的Nginx来做高可用为例,在X86架构下,整体的部署架构基本上可以参考下图。
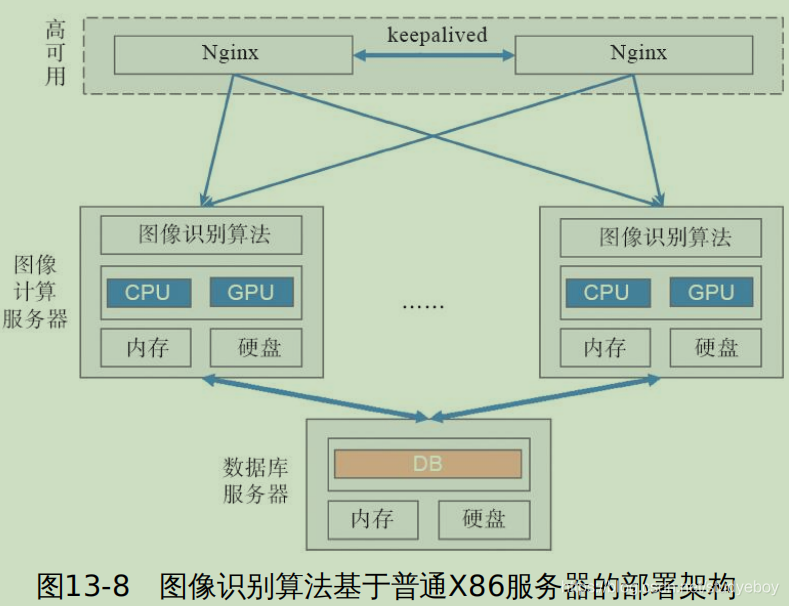
在这种部署模式下,图像算法的开发需要自行进行算法模型文件的服务化封装,以及对于算法文件的加密和License授权鉴权方面的开发对接工作。 -
基于ARM的单片机/工控机/专用硬件
基于ARM的单片机/工控机/专用硬件的部署模式,从当前的芯片情况来看,图像算法想要部署运行的话,不只需要算法和实际硬件运行强耦合,同时,还会涉及各类加速方案才能够带动复杂的图像算法在ARM芯片上的流畅运行。总体来说,基于ARM的单片机/工控机/专用硬件的部署模式需要算法开发人员与硬件生产商具有同步设计、同步开发的节奏,只有这样才能够保障硬件和算法的关联度较好。
实际应用场景和部署模式的匹配
- 公共云部署模式
公有云计算的租用模式 - 私有云计算部署模式
客户在自己的机房中建设一套私有云计算集群。 - X86架构单机+备份部署模式
只要提供图像算法就能够正常运转的物理资源。 - 基于ARM的部署模式
需要在基于ARM架构的硬件内部完成计算并快速输出结果。