目录
1- Flume
https://flume.apache.org/
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
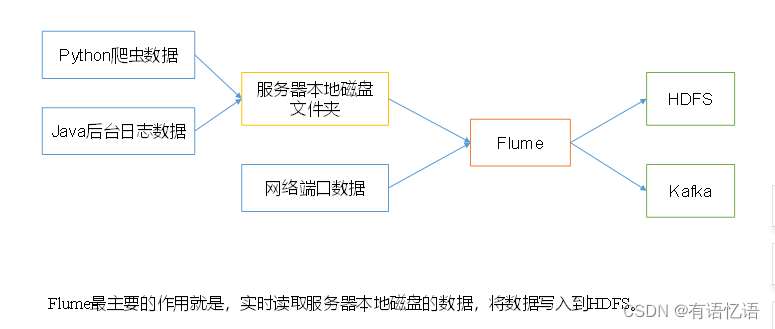
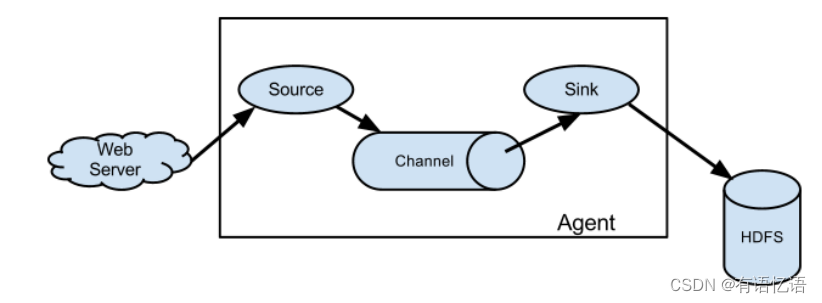
Agent
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的,是Flume数据传输的基本单元。
Agent主要有3个部分组成,Source、Channel、Sink。
Source
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink是完全事务性的。在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除事件。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。
Event
传输单元,Flume数据传输的基本单元,以事件的形式将数据从源头送至目的地。
Flume作为Hadoop的组件,是由Cloudera专门研发的分布式日志收集系统。尤其近几年随着Flume的不断完善,用户在开发过程中使用的便利性得到很大的改善,Flume现已成为Apache Top项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源上收集数据的能力。
Flume采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据。ZooKeeper本身可保证配置数据的一致性和高可用性。另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master节点之间使用Gossip协议同步数据。
Flume针对特殊场景也具备良好的自定义扩展能力,因此Flume适用于大部分的日常数据采集场景。因为Flume使用JRuby来构建,所以依赖Java运行环境。Flume设计成一个分布式的管道架构,可以看成在数据源和目的地之间有一个Agent的网络,支持数据路由。
Flume支持设置Sink的Failover和加载平衡,这样就可以保证在有一个Agent失效的情况下,整个系统仍能正常收集数据。Flume中传输的内容定义为事件(Event),事件由Headers(包含元数据,即Meta Data)和Payload组成。
Flume提供SDK,可以支持用户定制开发。Flume客户端负责在事件产生的源头把事件发送给Flume的Agent。客户端通常和产生数据源的应用在同一个进程空间。常见的Flume 客户端有Avro、Log4J、Syslog和HTTP Post。
1) Flume官网地址
http://flume.apache.org/
2)文档查看地址
http://flume.apache.org/FlumeUserGuide.html
3)下载地址
http://archive.apache.org/dist/flume/
2- Fluentd
Fluentd是另一个开源的数据收集架构,如图1所示。Fluentd使用C/Ruby开发,使用JSON文件来统一日志数据。通过丰富的插件,可以收集来自各种系统或应用的日志,然后根据用户定义将日志做分类处理。通过Fluentd,可以非常轻易地实现像追踪日志文件并将其过滤后转存到 MongoDB 这样的操作。Fluentd可以彻底地把人从烦琐的日志处理中解放出来。
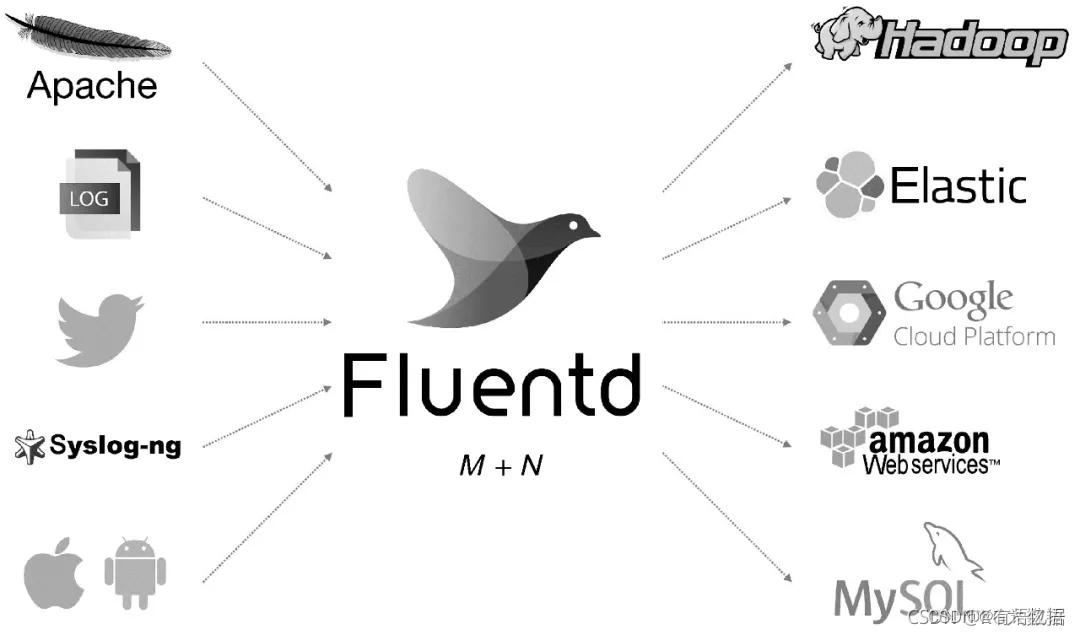
Fluentd具有多个功能特点:安装方便、占用空间小、半结构化数据日志记录、灵活的插件机制、可靠的缓冲、日志转发。Treasure Data公司对该产品提供支持和维护。另外,采用JSON统一数据/日志格式是它的另一个特点。相对Flume,Fluentd配置也相对简单一些。
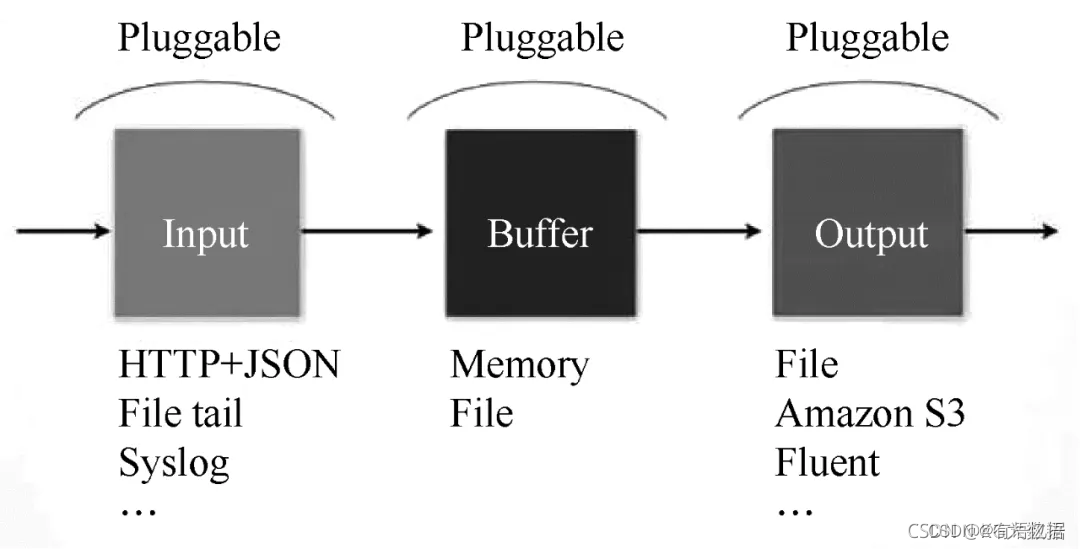
Fluentd的扩展性非常好,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd具有跨平台的问题,并不支持Windows平台。
Fluentd的Input/Buffer/Output非常类似于Flume的Source/Channel/Sink。Fluentd架构如图2所示。
3- Logstash
Logstash是著名的开源数据栈ELK(ElasticSearch,Logstash,Kibana)中的那个L。因为Logstash用JRuby开发,所以运行时依赖JVM。Logstash的部署架构如图3所示,当然这只是一种部署的选项。
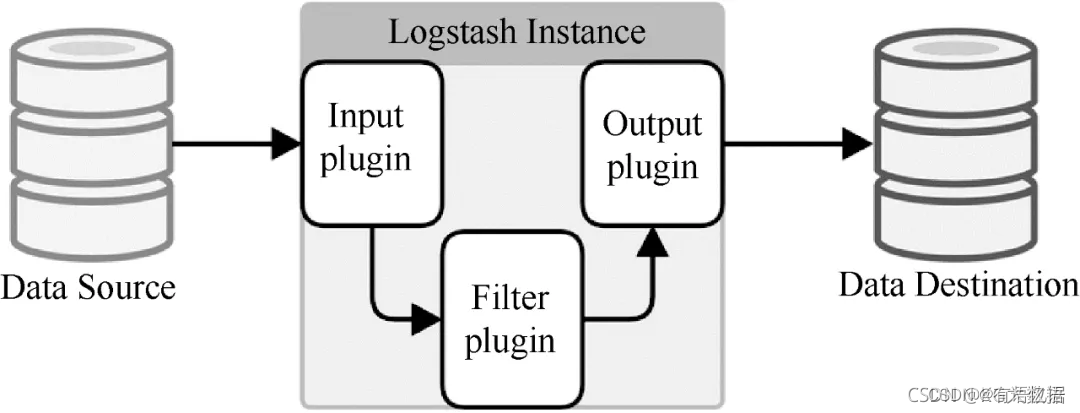
一个典型的Logstash的配置如下,包括Input、Filter的Output的设置如下所示:
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other_vhosts_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
}
}
filter {
grok {
match => {
"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {
"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {
}
Redis {
host=>"192.168.1.1"
data_type => "list"
key => "Logstash"
}
}
几乎在大部分的情况下,ELK作为一个栈是被同时使用的。在你的数据系统使用ElasticSearch的情况下,Logstash是首选。
4- Chukwa
该项目目前已经不活跃,不做介绍。
5- Scribe
Scribe是Facebook开发的数据(日志)收集系统。其官网已经多年不维护,不做介绍。
6- Splunk
不支持故障转移,不做介绍。
7- Scrapy
Python的爬虫架构叫Scrapy。Scrapy是由Python语言开发的一个快速、高层次的屏幕抓取和Web抓取架构,用于抓取Web站点并从页面中提取结构化数据。Scrapy的用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个架构,任何人都可以根据需求方便地进行修改。它还提供多种类型爬虫的基类,如BaseSpider、Sitemap爬虫等,最新版本提供对Web 2.0爬虫的支持。
Scrapy运行原理如下图所示。
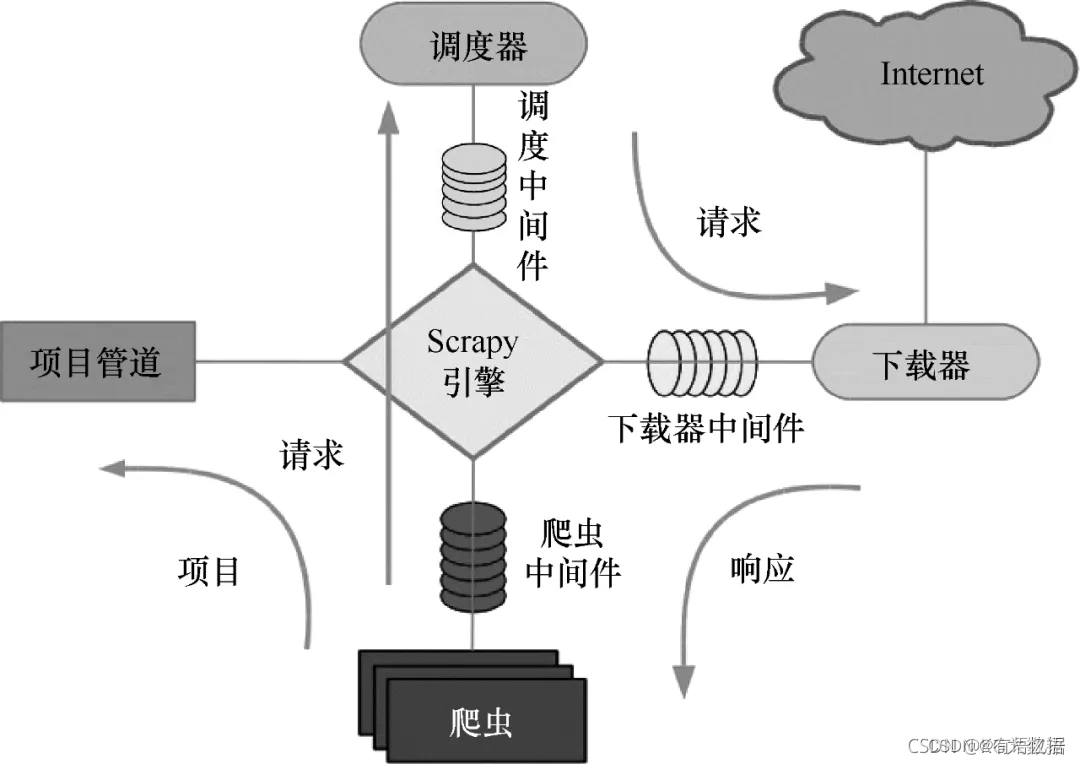
Scrapy的整个数据处理流程由Scrapy引擎进行控制。Scrapy运行流程如下:
(1)Scrapy引擎打开一个域名时,爬虫处理这个域名,并让爬虫获取第一个爬取的URL。
(2)Scrapy引擎先从爬虫那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
(3)Scrapy引擎从调度那里获取接下来进行爬取的页面。
(4)调度将下一个爬取的URL返回给引擎,引擎将它们通过下载中间件发送到下载器。
(5)当网页被下载器下载完成以后,响应内容通过下载器中间件被发送到Scrapy引擎。
(6)Scrapy引擎收到下载器的响应并将它通过爬虫中间件发送到爬虫进行处理。
(7)爬虫处理响应并返回爬取到的项目,然后给Scrapy引擎发送新的请求。
(8)Scrapy引擎将抓取到的放入项目管道,并向调度器发送请求。
(9)系统重复第(2)步后面的操作,直到调度器中没有请求,然后断开Scrapy引擎与域之间的联系。
8- Kafka
在流式计算中,Kafka一般用来缓存数据,Flink通过消费Kafka的数据进行计算。
1)Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
2)Kafka最初是由LinkedIn公司开发,并于 2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
3)Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
4)无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
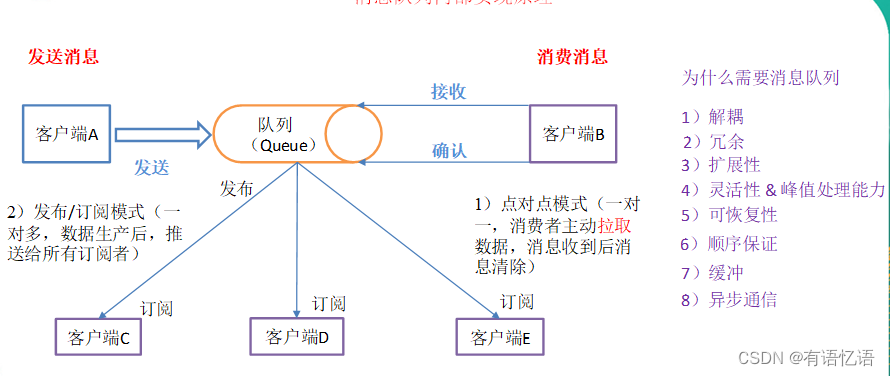
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
(2)发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
9- Datax
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
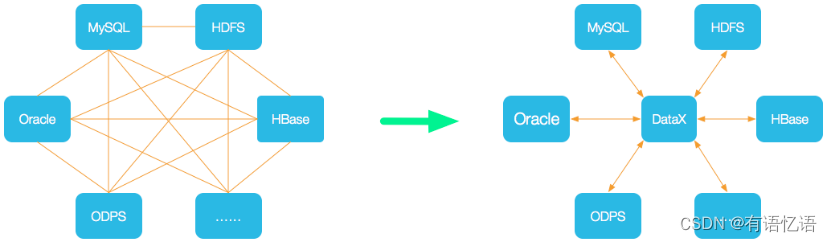
框架设计
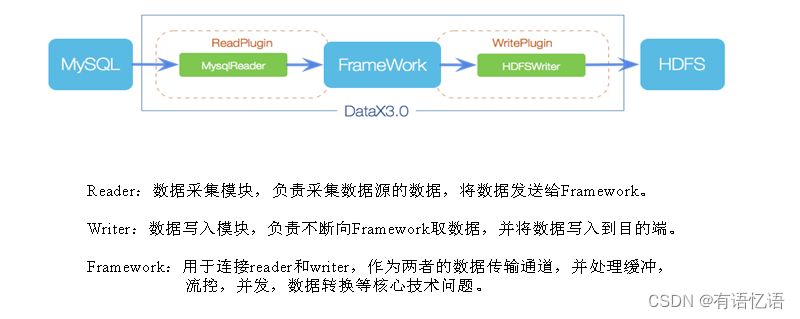
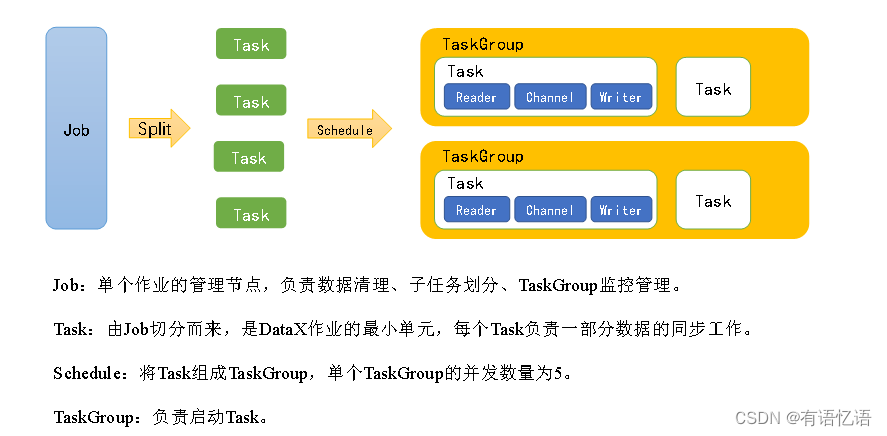
运行原理
下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
源码地址:https://github.com/alibaba/DataX
10-日志采集
根据产品的类型 又有可以分为:
浏览器页面 的日志采集
客户端 的日志采集
浏览器页面采集:
主要是收集页面的 浏览日志(PV/UV等) 和 交互操作日志(操作事件)。
这些日志的采集,一般是在页面上植入标准的统计JS代码来进执行。但这个植入代码的过程,可以在页面功能开发阶段由开发同学手动写入,也可以在项目运行的时候,由服务器在相应页面请求的时候动态的植入。
事实上,统计JS在采集到数据之后,可以立即发送到数据中心,也可以进行适当的汇聚之后,延迟发送到数据中心,这个策略取决于不同场景的需求来定。
页面日志在收集上来之后,需要在服务端进行一定的清晰和预处理。
比如 清洗假流量数据、识别攻击、数据的正常补全、无效数据的剔除、数据格式化、数据隔离等。
客户端日志采集:
一般会开发专用统计SDK用于APP客户端的数据采集,也称之为埋点。
客户端数据的采集,因为具有高度的业务特征,自定义要求比较高,因此除应用环境的一些基本数据以外,更多的是从 “按事件”的角度来采集数据,比如 点击事件、登陆事件、业务操作事件 等等。
基础数据可由SDK默认采集即可,其它事件由业务侧来定义后,按照规范调用SDK接口。
因为现在越来越多APP采用Hybrid方案,即 H5 与 Native相结合的方式,因此对于日志采集来说,既涉及到H5页面的日志,也涉及到Native客户端上的日志。在这种情况下,可以分开采集分开发送,也可以将数据合并到一起之后再发送。
常规情况下是推荐将 H5上的数据往Native上合并,然后通过SDK统一的发送。这样的好处是 既可以保证采集到的用户行为数据在行为链上是完整的,也可以通过SDK采取一些压缩处理方案来减少日志量,提高效率。
APP上的数据采集,还有一点比较重要的就是唯一ID了,所有的数据都必须跟唯一ID相关联,才能起到更好的分析作用,至于移动设备唯一ID我在上一篇文章中有详细讲到。
日志收集,还有很重要的一条原则就是 “标准化”、“规范化”,只有采集的方式标准化、规范化,才能最大限度的减少收集成本,提高日志收集效率、更高效的实现接下来的统计计算。
11-数据源数据同步
根据同步的方式 可以分为:
- 直接数据源同步
- 生成数据文件同步
- 数据库日志同步
直接数据源同步:
是指直接的连接业务数据库,通过规范的接口(如JDBC)去读取目标数据库的数据。这种方式比较容易实现,但是如果业务量比较大的数据源,可能会对性能有所影响。
生成数据文件同步:
是指从数据源系统现生成数据文件,然后通过文件系统同步到目标数据库里。
这种方式适合数据源比较分散的场景,在数据文件传输前后必须做校验,同时还需要适当进行文件的压缩和加密,以提高效率、保障安全。
数据库日志同步:
是指基于源数据库的日志文件进行同步。现在大多数数据库都支持生成数据日志文件,并且支持用数据日志文件来恢复数据。因此可以使用这个数据日志文件来进行增量同步。
这种方式对系统性能影响较小,同步效率也较高。
数据采集本身不是目的,只有采集到的数据是可用、能用,且能服务于最终应用分析的数据采集才是根本。