一、电商项目的大致流程
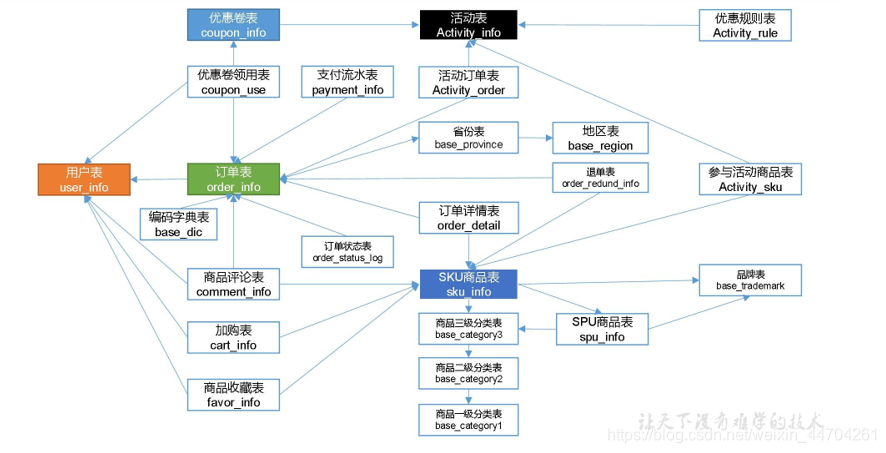
1.1 电商业务表结构
本电商数仓系统涉及到的业务数据表结构关系。这 24 个表以订单表、用户表、SKU 商品表、活动表和优惠券表为中心,延伸出了优惠券领用表、支付流水表、活动订单表、订单详情表、订单状态表、商品评论表、编码字典表退单表、SPU 商品表等,用户表提供用户的详细信息,支付流水表提供该订单的支付详情,订单详情表提供订单的商品数量等情况,商品表给订单详情表提供商品的详细信息。本次讲解只以此 24 个表为例,实际项目中,业务数据库中表格远远不止这些。
二、业务数据生成
2.1 数据导入

csdn上已经上传了资源

将sql导入,这里注意的是mysql版本最好选用mysql5.7的版本,不要高版本,会出现一些问题,如果想自己多尝试解决,可以使用8的版本
sql导入之后:
2.2 生成业务数据
生成业务日志
- 在 hadoop102 的/opt/module/目录下创建 db_log 文件夹
- 把 gmall2020-mock-db-2020-04-01.jar 和 application.properties 上 传 到 hadoop102 的
/opt/module/db_log 路径上。 - 修改 application.properties文件
logging.level.root=info
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://192.168.109.135:3306/gmall?characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8
spring.datasource.username=gmall
spring.datasource.password=gmall
logging.pattern.console=%m%n
mybatis-plus.global-config.db-config.field-strategy=not_null
#业务日期
mock.date=2020-06-18
#是否重置
mock.clear=0
#生成新用户数量
mock.user.count=100
#男性比例
mock.user.male-rate=20
#用户数据变化概率
mock.user.update-rate:20
#收藏取消比例
mock.favor.cancel-rate=10
#收藏数量
mock.favor.count=100
#购物车数量
mock.cart.count=30
#每个商品最多购物个数
mock.cart.sku-maxcount-per-cart=3
#购物车来源 用户查询,商品推广,智能推荐, 促销活动
mock.cart.source-type-rate=60:20:10:10
#用户下单比例
mock.order.user-rate=95
#用户从购物中购买商品比例
mock.order.sku-rate=70
#是否参加活动
mock.order.join-activity=1
#是否使用购物券
mock.order.use-coupon=1
#购物券领取人数
mock.coupon.user-count=1000
#支付比例
mock.payment.rate=70
#支付方式 支付宝:微信 :银联
mock.payment.payment-type=30:60:10
#评价比例 好:中:差:自动
mock.comment.appraise-rate=30:10:10:50
#退款原因比例:质量问题 商品描述与实际描述不一致 缺货 号码不合适 拍错 不想买了 其他
mock.refund.reason-rate=30:10:20:5:15:5:5
注意: 这里需要修改数据库连接的一些信息,和生成数据的时间
- 生成数据
java -jar gmall2020-mock-db-2020-04-01.jar
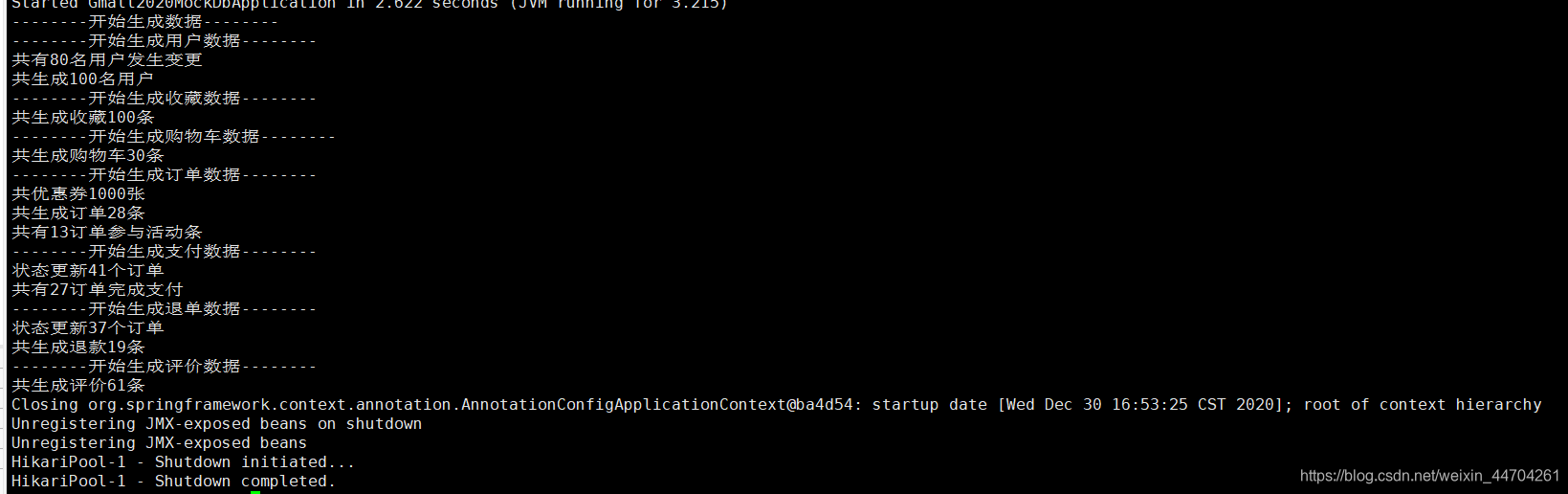
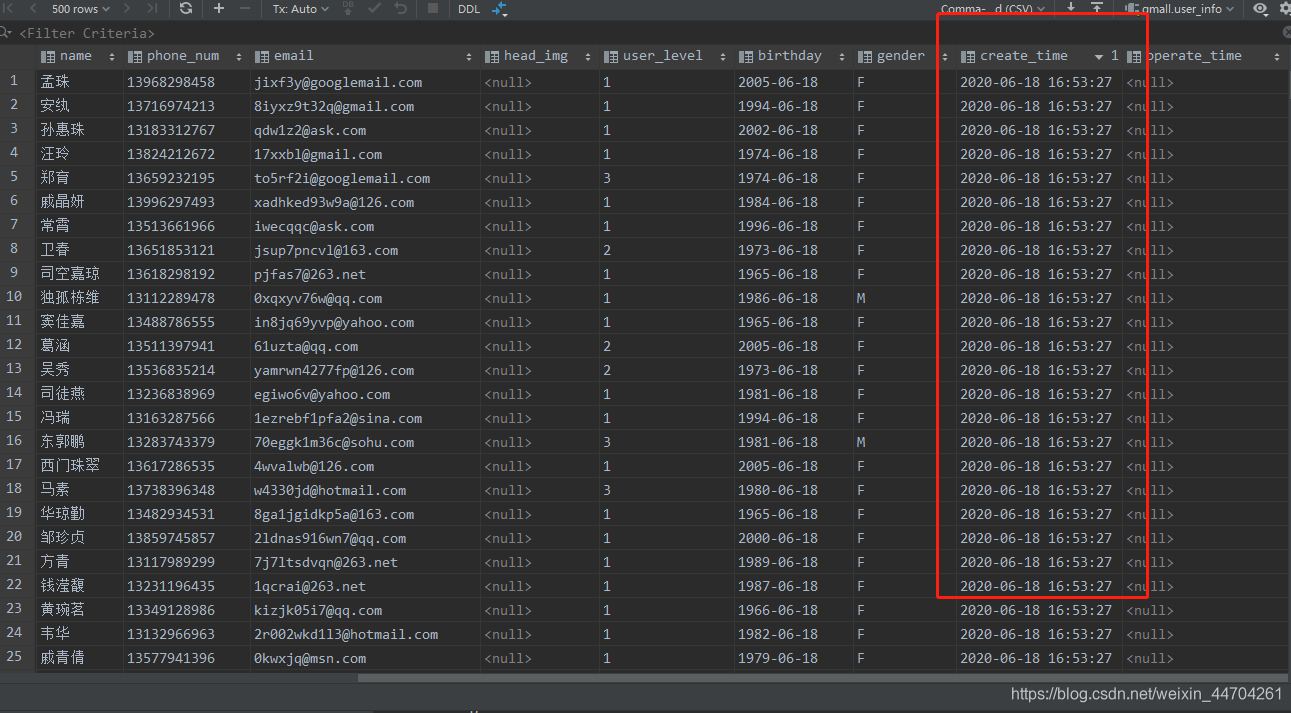
原始数据就准备好了
三、sqoop安装及数据导入HDFS
3.1 sqoop安装及配置
3.1.1 下载并解压
- 下载地址:http://mirrors.hust.edu.cn/apache/sqoop/1.4.6/
- 上传安装包 sqoop-1.4.7.bin hadoop-2.6.0.tar.gz 到 hadoop102 的/opt/software 路径中
- 解压 sqoop 安装包到指定目录,如:

3.1.2 修改配置文件
- 进入到/opt/module/sqoop/conf 目录,重命名配置文件
mv sqoop-env-template.sh sqoop-env.sh
- 修改配置文件
vim sqoop-env.sh
增加一下内容
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3 export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3 export HIVE_HOME=/opt/module/hive
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7 export ZOOCFGDIR=/opt/module/zookeeper-3.5.7/conf
- 拷贝JDBC 驱动
1)将 mysql-connector-java-5.1.48.jar 上传到/opt/software 路径
2)进入到/opt/software/路径,拷贝 jdbc 驱动到 sqoop 的 lib 目录下。
3.1.3 验证Sqoop
我们可以通过某一个 command 来验证 sqoop 配置是否正确:
[root@hadoop102 sqoop]$ bin/sqoop help
出现一些 Warning 警告(警告信息已省略),并伴随着帮助命令的输出:
3.1.4 测试sqoop连接数据库
bin/sqoop list-databases --connect jdbc:mysql://192.168.109.135:3306/ --username gmall --password gmall
3.2 同步策略
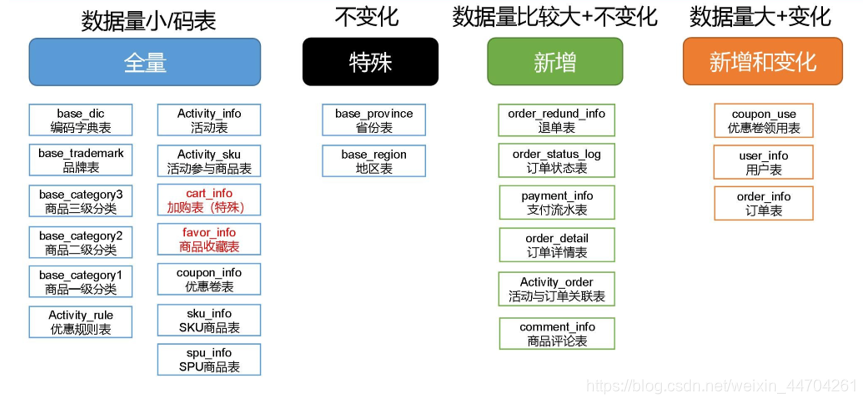
数据同步策略的类型包括:全量表、增量表、新增及变化表、特殊表
- 全量表:存储完整的数据。
- 增量表:存储新增加的数据。
- 新增及变化表:存储新增加的数据和变化的数据。
- 特殊表:只需要存储一次。
3.2.1 全量同步策略

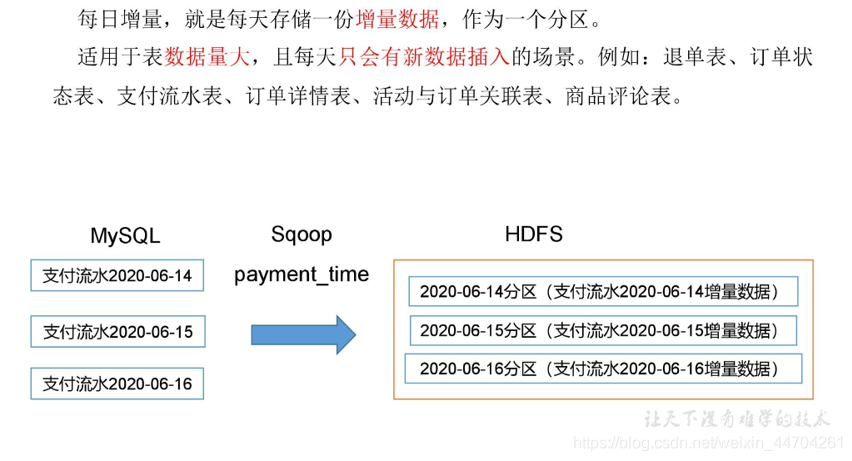
3.2.2 增量同步策略
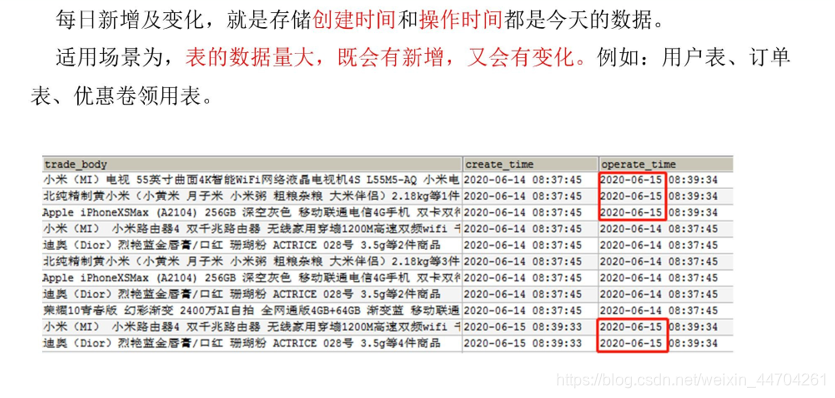
3.2.3 新增及变化策略
3.2.4 特殊策略
某些特殊的维度表,可不必遵循上述同步策略。
- 客观世界维度
没变化的客观世界的维度(比如性别,地区,民族,政治成分,鞋子尺码)可以只存一份固定值。 - 日期维度
日期维度可以一次性导入一年或若干年的数据。 - 地区维度省份表、地区表
3.3 业务数据导入HDFS
3.3.1 分析表同步策略
在生产环境,个别小公司,为了简单处理,所有表全量导入。
中大型公司,由于数据量比较大,还是严格按照同步策略导入数据。
3.3.2 脚本编写
在/usr/bin目录下创建:mysql_to_hdfs.sh
#! /bin/bash
sqoop=/opt/module/sqoop/bin/sqoop if [ -n "$2" ] ;then
do_date=$2 else
do_date=`date -d '-1 day' +%F`
fi
#
import_data(){
$sqoop import \
--connect jdbc:mysql://192.168.109.135:3306/gmall \
--username gmall \
--password gmall \
--target-dir /origin_data/gmall/db/$1/$do_date \
--delete-target-dir \
--query "$2 and \$CONDITIONS" \
--num-mappers 1 \
--fields-terminated-by '\t' \
--compress \
--compression-codec lzop \
--null-string '\\N' \
--null-non-string '\\N'
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer
/origin_data/gmall/db/$1/$do_date
}
import_order_info(){
import_data order_info "select
id,
final_total_amount,
order_status,
user_id,
out_trade_no,
create_time,
operate_time,
province_id,
benefit_reduce_amount,
original_total_amount,
feight_fee
from order_info
where (date_format(create_time,'%Y-%m-%d')='$do_date' or date_format(operate_time,'%Y-%m-%d')='$do_date')"
}
...

这里面有所有的脚本,这里就不粘贴了
说明 1:
[ -n 变量值 ] 判断变量的值,是否为空
– 变量的值,非空,返回 true
– 变量的值,为空,返回 false
说明 2:
查看 date 命令的使用,[root@hadoop102 ~]$ date --help
- 修改脚本权限
[atguigu@hadoop102 bin]$ chmod 777 mysql_to_hdfs.sh
- 初次导入
[root@hadoop102 bin]$ mysql_to_hdfs.sh first 2020-06-18
- 每日导入
[root@hadoop102 bin]$ mysql_to_hdfs.sh all 2020-06-19
然后就会开始执行map-reduce程序
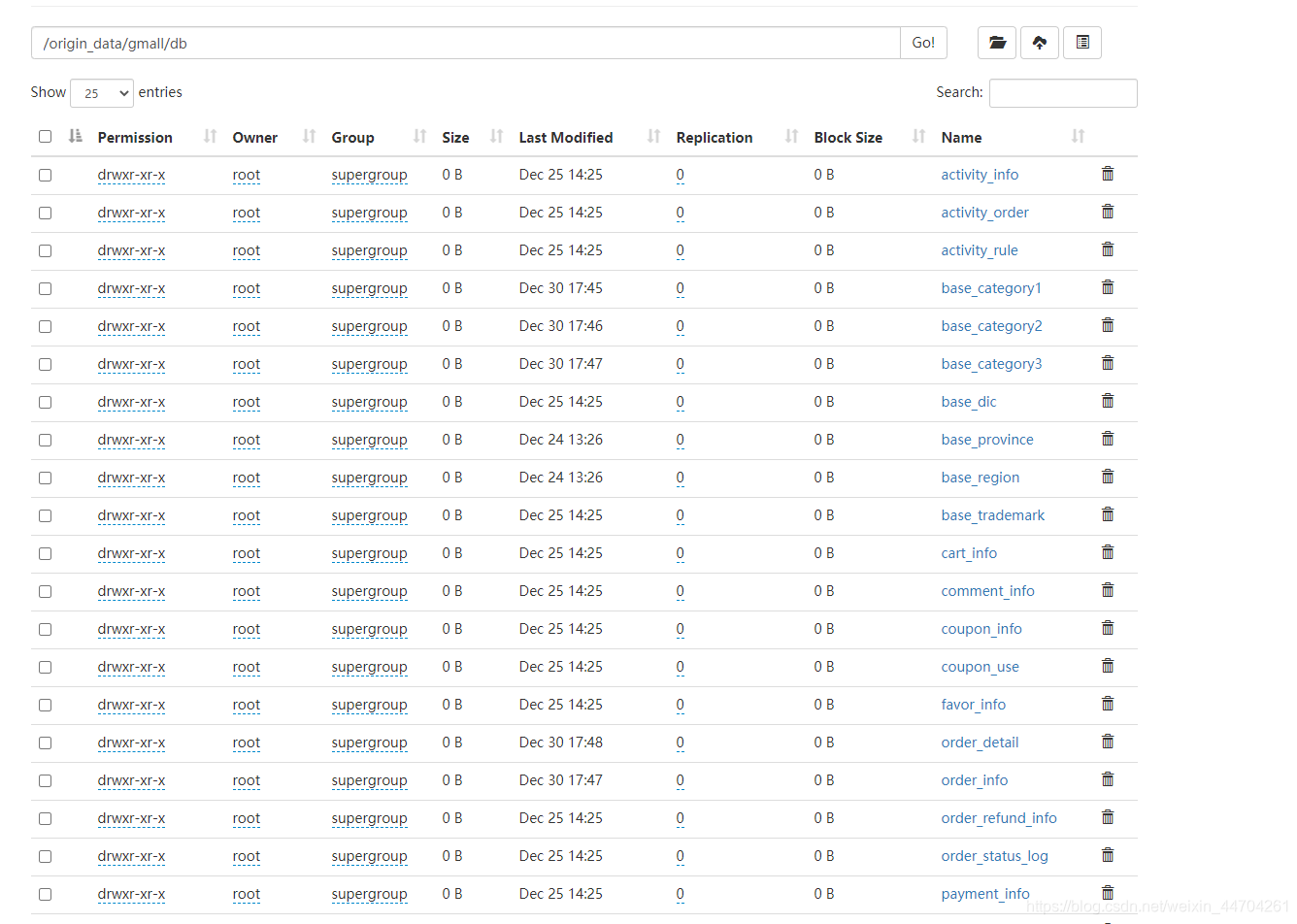
这样就导入成功了
总结
这个环节就是将所有的业务数据库里面的数据导入到hdfs
感谢大家阅、互相学习;
感谢尚硅谷提供的学习资料;
有问题评论或者发邮箱;
gitee:很多代码仓库;
[email protected]