1、查询设置
1.1、增大内存
一个查询任务,在单个 BE 节点上默认使用不超过 2GB 内存,内存不够时, 查询可能
会出现‘Memory limit exceeded’。
SHOW VARIABLES LIKE “%mem_limit%”;
exec_mem_limit 的单位是 byte,可以通过 SET 命令改变 exec_mem_limit 的值。如改
为 8GB。
SET exec_mem_limit = 8589934592;
上述设置仅仅在当前 session 有效, 如果想永久有效, 需要添加 global 参数。
SET GLOBAL exec_mem_limit = 8589934592;
1.2、修改超时时间
doris 默认最长查询时间为 300s, 如果仍然未完成, 会被 cancel 掉,查看配置:
SHOW VARIABLES LIKE “%query_timeout%”;
可以修改为 60s
SET query_timeout = 60;
同样, 如果需要全局生效需要添加参数 global。
set global query_timeout = 60;
当前超时的检查间隔为 5 秒,所以小于 5 秒的超时不会太准确。
1.3、查询重试和高可用
当部署多个 FE 节点时,用户可以在多个 FE 之上部署负载均衡层来实现 Doris 的高
可用。
1.3.1 代码方式
自己在应用层代码进行重试和负载均衡。比如发现一个连接挂掉,就自动在其他连接上
进行重试。应用层代码重试需要应用自己配置多个 doris 前端节点地址。
1.3.2 JDBC Connector
如果使用 mysql jdbc connector 来连接 Doris,可以使用 jdbc 的自动重试机制:
jdbc:mysql://[host1][:port1],[host2][:port2][,[host3][:port3]]...
[/[database]][?propertyName1=propertyValue1[&propertyName2=proper
tyValue2]...]
1.3.3 ProxySQL 方式
ProxySQL 是灵活强大的 MySQL 代理层, 是一个能实实在在用在生产环境的 MySQL 中
间件,可以实现读写分离,支持 Query 路由功能,支持动态指定某个 SQL 进行 cache,支持动态加载配置、故障切换和一些 SQL 的过滤功能。
Doris 的 FE 进程负责接收用户连接和查询请求,其本身是可以横向扩展且高可用的,
但是需要用户在多个 FE 上架设一层 proxy,来实现自动的连接负载均衡。
1)安装 ProxySQL (yum 方式)
配置 yum 源
#vim /etc/yum.repos.d/proxysql.repo
[proxysql_repo]
name= ProxySQL YUM repository
baseurl=http://repo.proxysql.com/ProxySQL/proxysql-
1.4.x/centos/\$releasever
gpgcheck=1
gpgkey=http://repo.proxysql.com/ProxySQL/repo_pub_key
执行安装
#yum clean all
#yum makecache
#yum -y install proxysql
查看版本
#proxysql --version
设置开机自启动
#systemctl enable proxysql
#systemctl start proxysql
#systemctl status proxysql
启动后会监听两个端口, 默认为 6032 和 6033。6032 端口是 ProxySQL 的管理端口,
6033 是 ProxySQL 对外提供服务的端口 (即连接到转发后端的真正数据库的转发端口)。
#netstat -tunlp
2)ProxySQL 配置
ProxySQL 有配置文件 /etc/proxysql.cnf 和配置数据库文件/var/lib/proxysql/proxysql.db。
这里需要特别注意:如果存在如果存在"proxysql.db"文件(在/var/lib/proxysql 目录下),则ProxySQL 服务只有在第一次启动时才会去读取 proxysql.cnf 文件并解析;后面启动会就不会读取 proxysql.cnf 文件了!如果想要让 proxysql.cnf 文件里的配置在重启 proxysql 服务后生效(即想要让 proxysql 重启时读取并解析 proxysql.cnf 配置文件),则需要先删除/var/lib/proxysql/proxysql.db 数据库文件,然后再重启 proxysql 服务。这样就相当于初始化启动 proxysql 服务了,会再次生产一个纯净的 proxysql.db 数据库文件(如果之前配置了proxysql 相关路由规则等,则就会被抹掉)
(1)查看及修改配置文件:主要是几个参数,在下面已经注释出来了,可以根据自己
的需要进行修改
#vim /etc/proxysql.cnf
datadir="/var/lib/proxysql" #数据目录
admin_variables=
{
admin_credentials="admin:admin" #连接管理端的用户名与密码
mysql_ifaces="0.0.0.0:6032" #管理端口,用来连接 proxysql 的管
理数据库
}
mysql_variables=
{
threads=4 #指定转发端口开启的线程数量
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033" #指定转发端口,用于连接后端 mysql 数
据库的,相当于代理作用
default_schema="information_schema"
stacksize=1048576
server_version="5.7.28" #指定后端 mysql 的版本
connect_timeout_server=3000
monitor_username="monitor"
monitor_password="monitor"
monitor_history=600000
monitor_connect_interval=60000
monitor_ping_interval=10000
monitor_read_only_interval=1500
monitor_read_only_timeout=500
ping_interval_server_msec=120000
ping_timeout_server=500
commands_stats=true
sessions_sort=true
connect_retries_on_failure=10
}
mysql_servers =
(
)
mysql_users:
(
)
mysql_query_rules:
(
)
scheduler=
(
)
mysql_replication_hostgroups=
(
)
(2)连接 ProxySQL 管理端口测试
#mysql -h 127.0.0.1 -P 6032 -u admin -p
查看 main 库(默认登陆后即在此库)的 global_variables 表信息
show databases;
use main;
show tables;
(3)ProxySQL 配置后端 Doris FE
使用 insert 语句添加主机到 mysql_servers 表中,其中:hostgroup_id 为 10 表示写组,
为 20 表示读组,我们这里不需要读写分离,无所谓随便设置哪一个都可以。
mysql -u admin -p admin -P 6032 -h 127.0.0.1
insert into mysql_servers(hostgroup_id,hostname,port)
values(10,'192.168.8.101',9030);
insert into mysql_servers(hostgroup_id,hostname,port)
values(10,'192.168.8.102',9030);
insert into mysql_servers(hostgroup_id,hostname,port)
values(10,'192.168.8.103',9030);
如果在插入过程中,出现报错:
ERROR 1045 (#2800): UNIQUE constraint failed:
mysql_servers.hostgroup_id, mysql_servers.hostname,
mysql_servers.port
说明可能之前就已经定义了其他配置,可以清空这张表 或者 删除对应 host 的配置
select * from mysql_servers;
delete from mysql_servers;
查看这 3 个节点是否插入成功,以及它们的状态。
select * from mysql_servers\G;
如上修改后,加载到 RUNTIME,并保存到 disk,下面两步非常重要,不然退出以后配置信
息就没了,必须保存
load mysql servers to runtime;
save mysql servers to disk;
(4)监控 Doris FE 节点配置
添 doris fe 节点之后,还需要监控这些后端节点。对于后端多个 FE 高可用负载均衡环
境来说,这是必须的,因为 ProxySQL 需要通过每个节点的 read_only 值来自动调整它们是属于读组还是写组。
首先在后端 master 主数据节点上创建一个用于监控的用户名。
在 doris fe master 主数据库节点行执行:
#mysql -h hadoop1 -P 9030 -u root -p
create user monitor@'192.168.8.%' identified by 'monitor';
grant ADMIN_PRIV on *.* to monitor@'192.168.8.%';
然后回到 mysql-proxy 代理层节点上配置监控
#mysql -uadmin -padmin -P6032 -h127.0.0.1
set mysql-monitor_username='monitor';
set mysql-monitor_password='monitor';
修改后,加载到 RUNTIME,并保存到 disk
load mysql variables to runtime;
save mysql variables to disk;
验证监控结果:ProxySQL 监控模块的指标都保存在 monitor 库的 log 表中。
以下是连接是否正常的监控(对 connect 指标的监控):
注意:可能会有很多 connect_error,这是因为没有配置监控信息时的错误,配置后如果
connect_error 的结果为 NULL 则表示正常。
select * from mysql_server_connect_log;
查看心跳信息的监控(对 ping 指标的监控)
select * from mysql_server_ping_log;
查看 read_only 日志此时也为空(正常来说,新环境配置时,这个只读日志是为空的)
select * from mysql_server_read_only_log;
load mysql servers to runtime;
save mysql servers to disk;
查看结果
select hostgroup_id,hostname,port,status,weight from mysql_servers;
(5)配置 Doris 用户
上面的所有配置都是关于后端 Doris FE 节点的,现在可以配置关于 SQL 语句的,包括:
发送 SQL 语句的用户、SQL 语句的路由规则、SQL 查询的缓存、SQL 语句的重写等等。
本小节是 SQL 请求所使用的用户配置,例如 root 用户。这要求我们需要先在后端 Doris
FE 节点添加好相关用户。这里以 root 和 doris 两个用户名为例。
首先,在 Doris FE master 主数据库节点上执行:
#mysql -h hadoop1 -P 9030 -u root -p
root 用户已经存在,直接创建 doris 用户:
create user doris@'%' identified by 'doris';
grant ADMIN_PRIV on *.* to doris@'%';
回到 mysql-proxy 代理层节点,配置 mysql_users 表,将刚才的两个用户添加到该表
中。
insert into mysql_users(username,password,default_hostgroup)
values('root','000000',10);
insert into mysql_users(username,password,default_hostgroup)
values('doris','doris',10);
加载用户到运行环境中,并将用户信息保存到磁盘
load mysql users to runtime;
save mysql users to disk;
select * from mysql_users\G
只有 active=1 的用户才是有效的用户。确保 transaction_persistent 为 1:
update mysql_users set transaction_persistent=1 where
username='root';
update mysql_users set transaction_persistent=1 where
username='doris';
load mysql users to runtime;
save mysql users to disk;
这里不需要读写分离,将这两个参数设为 true:
UPDATE global_variables SET variable_value='true' WHERE
variable_name='mysql-forward_autocommit';
UPDATE global_variables SET variable_value='true' WHERE
variable_name='mysql-autocommit_false_is_transaction';
LOAD MYSQL VARIABLES TO RUNTIME;
SAVE MYSQL VARIABLES TO DISK;
这样就可以通过 sql 客户端,使用 doris 的用户名密码去连接了 ProxySQL 了
(6)通过 ProxySQL 连接 Doris 进行测试
分别使用 root 用户和 doris 用户测试下它们是否能路由到默认的 hostgroup_id=10
(它是一个写组)读数据。下面是通过转发端口 6033 连接的,连接的是转发到后端真正的数据库。
mysql -udoris -pdoris -P6033 -h hadoop1 -e "show databases;"
到此就结束了,可以用 MySQL 客户端,JDBC 等任何连接 MySQL 的方式连接 ProxySQL 去操作 doris 了。
(7)验证:将 hadoop1 的 fe 停止,再执行
mysql -udoris -pdoris -P6033 -h hadoop1 -e "show databases;"
能够正常使用。
2、简单查询
1)简单查询
SELECT * FROM example_site_visit LIMIT 3;
SELECT * FROM example_site_visit ORDER BY user_id;
2)Join
SELECT SUM(example_site_visit.cost) FROM example_site_visit
JOIN example_site_visit2
WHERE example_site_visit.user_id = example_site_visit2.user_id;
select
example_site_visit.user_id,
sum(example_site_visit.cost)
from example_site_visit join example_site_visit2
where example_site_visit.user_id = example_site_visit2.user_id
group by example_site_visit.user_id;
3)子查询
SELECT SUM(cost) FROM example_site_visit2 WHERE user_id IN (SELECT
user_id FROM example_site_visit WHERE user_id > 10003);
3、Join查询
3.1 Broadcast Join
系统默认实现 Join 的方式,是将小表进行条件过滤后,将其广播到大表所在的各个节
点上,形成一个内存 Hash 表,然后流式读出大表的数据进行 Hash Join。
Doris 会自动尝试进行 Broadcast Join,如果预估小表过大则会自动切换至 Shuffle Join。
注意,如果此时显式指定了 Broadcast Join 也会自动切换至 Shuffle Join。
1)默认使用 Broadcast Join:
EXPLAIN SELECT SUM(example_site_visit.cost)
FROM example_site_visit
JOIN example_site_visit2
WHERE example_site_visit.city = example_site_visit2.city;
2)显式使用 Broadcast Join:
EXPLAIN SELECT SUM(example_site_visit.cost)
FROM example_site_visit
JOIN [broadcast] example_site_visit2
WHERE example_site_visit.city = example_site_visit2.city;
3.2 Shuffle Join(Partitioned Join)
如果当小表过滤后的数据量无法放入内存的话,此时 Join 将无法完成,通常的报错应
该是首先造成内存超限。可以显式指定 Shuffle Join,也被称作 Partitioned Join。即将小表和大表都按照 Join 的 key 进行 Hash,然后进行分布式的 Join。这个对内存的消耗就会分摊到集群的所有计算节点上。
SELECT SUM(example_site_visit.cost)
FROM example_site_visit
JOIN [shuffle] example_site_visit2
WHERE example_site_visit.city = example_site_visit2.city;
3.3 Colocation Join
Colocation Join 是在 Doris0.9 版本引入的功能,旨在为 Join 查询提供本性优化,来减少
数据在节点上的传输耗时,加速查询。
3.3.1 原理
Colocation Join 功能,是将一组拥有 CGS 的表组成一个 CG。保证这些表对应的数据分
片会落在同一个 be 节点上,那么使得两表再进行 join 的时候,可以通过本地数据进行直接join,减少数据在节点之间的网络传输时间。
➢ Colocation Group(CG):一个 CG 中会包含一张及以上的 Table。在同一个 Group
内的 Table 有着相同的 Colocation Group Schema,并且有着相同的数据分片分布。
➢ Colocation Group Schema(CGS):用于描述一个 CG 中的 Table,和 Colocation
相关的通用 Schema 信息。包括分桶列类型,分桶数以及副本数等。
一个表的数据,最终会根据分桶列值 Hash、对桶数取模的后落在某一个分桶内。假设
一个 Table 的分桶数为 8,则共有 [0, 1, 2, 3, 4, 5, 6, 7] 8 个分桶(Bucket),我们称这样一个序列为一个 BucketsSequence。每个 Bucket 内会有一个或多个数据分片(Tablet)。当表为单分区表时,一个 Bucket 内仅有一个 Tablet。如果是多分区表,则会有多个。
使用限制:
(1)建表时两张表的分桶列的类型和数量需要完全一致,并且桶数一致,才能保证多
张表的数据分片能够一一对应的进行分布控制。
(2)同一个 CG 内所有表的所有分区(Partition)的副本数必须一致。如果不一致,
可能出现某一个 Tablet 的某一个副本,在同一个 BE 上没有其他的表分片的副本对应。
(3)同一个 CG 内的表,分区的个数、范围以及分区列的类型不要求一致。
3.3.2 使用
1)建两张表,分桶列都为 int 类型,且桶的个数都是 8 个。副本数都为默认副本数。
CREATE TABLE `tbl1` (
`k1` date NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` int(11) SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
PARTITION BY RANGE(`k1`)
(
PARTITION p1 VALUES LESS THAN ('2019-05-31'),
PARTITION p2 VALUES LESS THAN ('2019-06-30')
)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
CREATE TABLE `tbl2` (
`k1` datetime NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` double SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
2)编写查询语句,并查看执行计划
explain SELECT * FROM tbl1 INNER JOIN tbl2 ON (tbl1.k2 = tbl2.k2);
HASH JOIN 处 colocate 显示为 true,代表优化成功。
3)查看 Group
SHOW PROC '/colocation_group';
当 Group 中最后一张表彻底删除后(彻底删除是指从回收站中删除。通常,一张表通过
DROP TABLE 命令删除后,会在回收站默认停留一天的时间后,再删除),该 Group 也会被自动删除。
4)修改表 Colocate Group 属性
ALTER TABLE tbl SET ("colocate_with" = "group2");
如果该表之前没有指定过 Group,则该命令检查 Schema,并将该表加入到该 Group
(Group 不存在则会创建)。
如果该表之前有指定其他 Group,则该命令会先将该表从原有 Group 中移除,并加入新
Group(Group 不存在则会创建)。
5)删除表的 Colocation 属性
ALTER TABLE tbl SET ("colocate_with" = "");
6)其他操作
当对一个具有 Colocation 属性的表进行增加分区(ADD PARTITION)、修改副本数时,
Doris 会检查修改是否会违反 Colocation Group Schema,如果违反则会拒绝。
3.4 Bucket Shuffle Join
Bucket Shuffle Join 是在 Doris 0.14 版本中正式加入的新功能。旨在为某些 Join 查询提
供本地性优化,来减少数据在节点间的传输耗时,来加速查询。
3.4.1 原理
Doris 支持的常规分布式 Join 方式包括了 shuffle join 和 broadcast join。这两种 join 都会
导致不小的网络开销:
举个例子,当前存在 A 表与 B 表的 Join 查询,它的 Join 方式为 HashJoin,不同 Join 类型的开销如下:
⚫ Broadcast Join: 如果根据数据分布,查询规划出 A 表有 3 个执行的 HashJoinNode,
那么需要将 B 表全量的发送到 3 个 HashJoinNode,那么它的网络开销是 3B,它的
内存开销也是 3B。
⚫ Shuffle Join: Shuffle Join 会将 A,B 两张表的数据根据哈希计算分散到集群的节点
之中,所以它的网络开销为 A + B,内存开销为 B。
在 FE 之中保存了 Doris 每个表的数据分布信息,如果 join 语句命中了表的数据分布列,
使用数据分布信息来减少 join 语句的网络与内存开销,这就是 Bucket Shuffle Join,原理如下图:
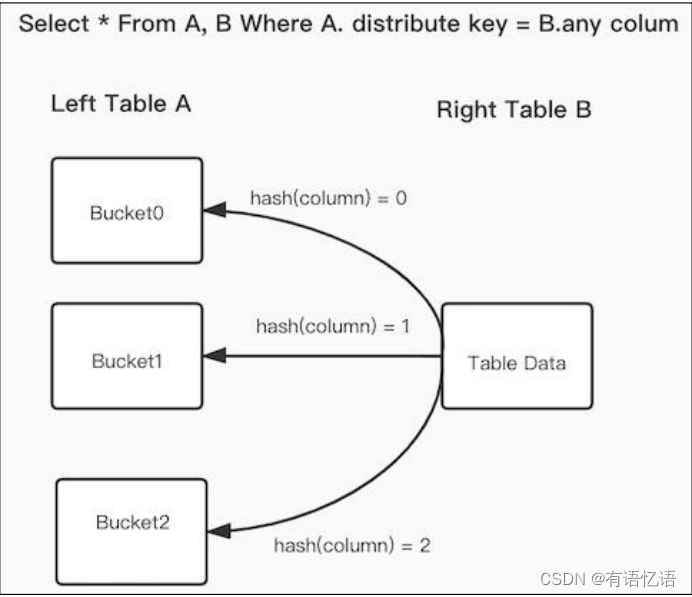
SQL 语句为 A 表 join B 表,并且 join 的等值表达式命中了 A 的数据分布列。而 Bucket
Shuffle Join 会根据 A 表的数据分布信息,将 B 表的数据发送到对应的 A 表的数据存储计算节点。Bucket Shuffle Join 开销如下:
⚫ 网络开销: B < min(3B, A + B)
⚫ 内存开销: B <= min(3B, B)
可见,相比于 Broadcast Join 与 Shuffle Join, Bucket Shuffle Join 有着较为明显的性能
优势。减少数据在节点间的传输耗时和 Join 时的内存开销。相对于 Doris 原有的 Join 方式,它有着下面的优点:
⚫ 首先,Bucket-Shuffle-Join 降低了网络与内存开销,使一些 Join 查询具有了更好的
性能。尤其是当 FE 能够执行左表的分区裁剪与桶裁剪时。
⚫ 其次,同时与 Colocate Join 不同,它对于表的数据分布方式并没有侵入性,这对于
用户来说是透明的。对于表的数据分布没有强制性的要求,不容易导致数据倾斜的
问题。
⚫ 最后,它可以为 Join Reorder 提供更多可能的优化空间。
3.4.2 使用
1)设置 Session 变量,从 0.14 版本开始默认为 true
show variables like '%bucket_shuffle_join%';
set enable_bucket_shuffle_join = true;
在 FE 进行分布式查询规划时,优先选择的顺序为 Colocate Join -> Bucket Shuffle Join ->Broadcast Join -> Shuffle Join。但是如果用户显式 hint 了 Join 的类型,如:
select * from test join [shuffle] baseall on test.k1 = baseall.k1;
则上述的选择优先顺序则不生效。
2)通过 explain 查看 join 类型
EXPLAIN SELECT SUM(example_site_visit.cost)
FROM example_site_visit
JOIN example_site_visit2
ON example_site_visit.user_id = example_site_visit2.user_id;
在 Join 类型之中会指明使用的 Join 方式为:BUCKET_SHUFFLE。
3.4.3 注意事项
(1)Bucket Shuffle Join 只生效于 Join 条件为等值的场景,原因与 Colocate Join 类似,它们都依赖 hash 来计算确定的数据分布。
(2)在等值 Join 条件之中包含两张表的分桶列,当左表的分桶列为等值的 Join 条件
时,它有很大概率会被规划为 Bucket Shuffle Join。
(3)由于不同的数据类型的 hash 值计算结果不同,所以 Bucket Shuffle Join 要求左表
的分桶列的类型与右表等值 join 列的类型需要保持一致,否则无法进行对应的规划。
(4)Bucket Shuffle Join 只作用于 Doris 原生的 OLAP 表,对于 ODBC,MySQL,ES 等外表,当其作为左表时是无法规划生效的。
(5)对于分区表,由于每一个分区的数据分布规则可能不同,所以 Bucket Shuffle Join
只能保证左表为单分区时生效。所以在 SQL 执行之中,需要尽量使用 where 条件使分区裁剪的策略能够生效。
(6)假如左表为 Colocate 的表,那么它每个分区的数据分布规则是确定的,Bucket
Shuffle Join 能在 Colocate 表上表现更好。
3.5 Runtime Filter
Runtime Filter 是在 Doris 0.15 版本中正式加入的新功能。旨在为某些 Join 查询在运
行时动态生成过滤条件,来减少扫描的数据量,避免不必要的 I/O 和网络传输,从而加速查询。
3.5.1 原理
Runtime Filter 在查询规划时生成,在 HashJoinNode 中构建,在 ScanNode 中应用。
举个例子,当前存在 T1 表与 T2 表的 Join 查询,它的 Join 方式为 HashJoin,T1 是一张事实表,数据行数为 100000,T2 是一张维度表,数据行数为 2000,Doris join 的实际情况是:
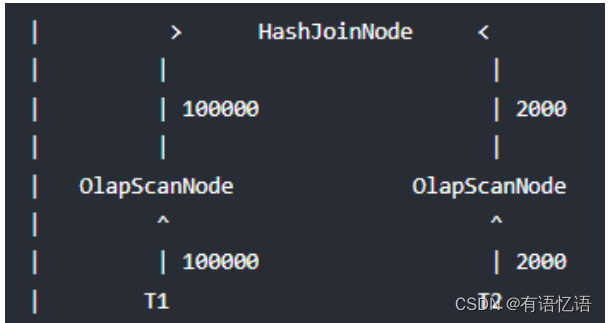
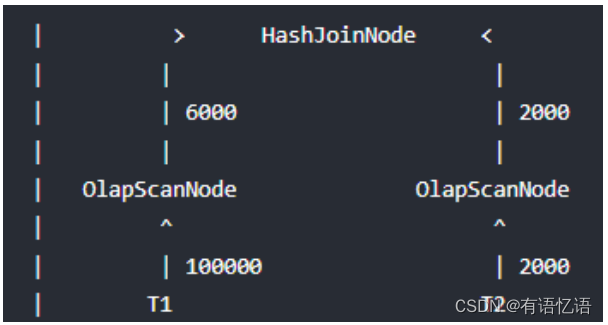
显而易见对 T2 扫描数据要远远快于 T1,如果我们主动等待一段时间再扫描 T1,等 T2
将扫描的数据记录交给 HashJoinNode 后,HashJoinNode 根据 T2 的数据计算出一个过滤条件,比如 T2 数据的最大和最小值,或者构建一个 Bloom Filter,接着将这个过滤条件发给等待扫描 T1 的 ScanNode,后者应用这个过滤条件,将过滤后的数据交给 HashJoinNode,从而减少 probe hash table 的次数和网络开销,这个过滤条件就是 Runtime Filter,效果如下:
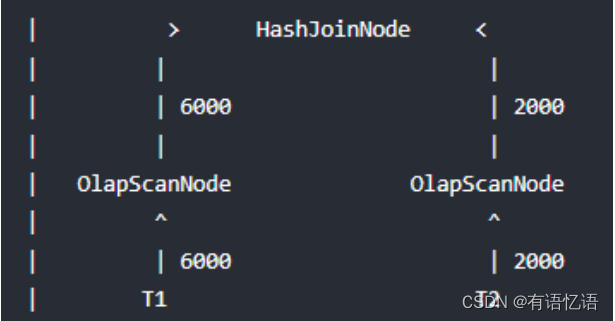
如果能将过滤条件(Runtime Filter)下推到存储引擎,则某些情况下可以利用索引来直
接减少扫描的数据量,从而大大减少扫描耗时,效果如下:
可见,和谓词下推、分区裁剪不同,Runtime Filter 是在运行时动态生成的过滤条件,即
在查询运行时解析 join on clause 确定过滤表达式,并将表达式广播给正在读取左表的
ScanNode,从而减少扫描的数据量,进而减少 probe hash table 的次数,避免不必要的 I/O 和网络传输。
Runtime Filter 主要用于优化针对大表的 join,如果左表的数据量太小,或者右表的数据
量太大,则 Runtime Filter 可能不会取得预期效果。
3.5.2 使用
1)指定 RuntimeFilter 类型
set runtime_filter_type="BLOOM_FILTER,IN,MIN_MAX";
2)建表
CREATE TABLE test (t1 INT) DISTRIBUTED BY HASH (t1) BUCKETS 2
PROPERTIES("replication_num" = "1");
INSERT INTO test VALUES (1), (2), (3), (4);
CREATE TABLE test2 (t2 INT) DISTRIBUTED BY HASH (t2) BUCKETS 2
PROPERTIES("replication_num" = "1");
INSERT INTO test2 VALUES (3), (4), (5);
3)查看执行计划
EXPLAIN SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;
可以看到:
HASH JOIN生成了 ID 为 RF000 的 IN predicate,其中test2.t2的 key values 仅在运行 时可知,在 OlapScanNode 使用了该 IN predicate 用于在读取test.t1`时过滤不必要的数据。
4)通过 profile 查看效果
set enable_profile=true;
SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;
查看对应 fe 节点的 webui,可以查看查询内部工作的详细信息:
http://hadoop1:8030/QueryProfile/
(1)可以看到每个 Runtime Filter 是否下推、等待耗时、以及 OLAP_SCAN_NODE 从
prepare 到接收到 Runtime Filter 的总时长。
RuntimeFilter:in:
- HasPushDownToEngine: true
- AWaitTimeCost: 0ns
- EffectTimeCost: 2.76ms
(2)在 profile 的 OLAP_SCAN_NODE 中可以查看 Runtime Filter 下推后的过滤效果和
耗时。
- RowsVectorPredFiltered: 9.320008M (9320008)
- VectorPredEvalTime: 364.39ms
3.5.3 具体参数说明
1) 大多数情况下,只需要调整 runtime_filter_type 选项,其他选项保持默认即可:
包括 BLOOM_FILTER、IN、MIN_MAX(也可以通过数字设置),默认会使用 IN,部
分情况下同时使用 Bloom Filter、MinMax Filter、IN predicate 时性能更高,每个类型含义如下:
(1)Bloom Filter: 有一定的误判率,导致过滤的数据比预期少一点,但不会导致最终
结果不准确,在大部分情况下 Bloom Filter 都可以提升性能或对性能没有显著影响,但在部分情况下会导致性能降低。
① Bloom Filter 构建和应用的开销较高,所以当过滤率较低时,或者左表数据量较
少时,Bloom Filter 可能会导致性能降低。
② 目前只有左表的 Key 列应用 Bloom Filter 才能下推到存储引擎,而测试结果显
示 Bloom Filter 不下推到存储引擎时往往会导致性能降低。
③ 目前 Bloom Filter 仅在 ScanNode 上使用表达式过滤时有短路(short-circuit)逻辑,
即当假阳性率(实际是假但误辨为真的情况)过高时,不继续使用 Bloom Filter,但当
Bloom Filter 下推到存储引擎后没有短路逻辑,所以当过滤率较低时可能导致性能降低。
(2)MinMax Filter: 包含最大值和最小值,从而过滤小于最小值和大于最大值的数据,
MinMax Filter 的过滤效果与 join on clause 中 Key 列的类型和左右表数据分布有关。
① 当 join on clause 中 Key 列的类型为 int/bigint/double 等时,极端情况下,如果左
右表的最大最小值相同则没有效果,反之右表最大值小于左表最小值,或右表最小值大
于左表最大值,则效果最好。
② 当 join on clause 中 Key 列的类型为 varchar 等时,应用 MinMax Filter 往往会导
致性能降低。
(3)IN predicate: 根据 join on clause 中 Key 列在右表上的所有值构建 IN predicate,使用构建的 IN predicate 在左表上过滤,相比 Bloom Filter 构建和应用的开销更低,在右表数据量较少时往往性能更高。
① 默认只有右表数据行数少于 1024 才会下推(可通过 session 变量中的
runtime_filter_max_in_num 调整)。
② 目前 IN predicate 已实现合并方法。
③ 当同时指定 In predicate 和其他 filter ,并且 in 的 过 滤 数 值 没 达 到runtime_filter_max_in_num 时,会尝试把其他 filter 去除掉。原因是 In predicate 是精确
的过滤条件,即使没有其他 filter 也可以高效过滤,如果同时使用则其他 filter 会做无用功。目前仅在 Runtime filter 的生产者和消费者处于同一个 fragment 时才会有去除非 in
filter 的逻辑。
2)其他查询选项通常仅在某些特定场景下,才需进一步调整以达到最优效果。通常只在性能测试后,针对资源密集型、运行耗时足够长且频率足够高的查询进行优化。
➢ runtime_filter_mode: 用于调整 Runtime Filter 的下推策略,包括 OFF、LOCAL、GLOBAL三种策略,默认设置为 GLOBAL 策略
➢ runtime_filter_wait_time_ms: 左表的 ScanNode 等待每个 Runtime Filter 的时间,默认1000ms
➢ runtime_filters_max_num: 每个查询可应用的 Runtime Filter 中 Bloom Filter 的最大数量,默认 10
➢ runtime_bloom_filter_min_size: Runtime Filter 中 Bloom Filter 的最小长度,默认 1048576(1M)
➢ runtime_bloom_filter_max_size: Runtime Filter 中 Bloom Filter 的最大长度,默认 16777216(16M)
➢ runtime_bloom_filter_size: Runtime Filter中Bloom Filter的默认长度,默认2097152(2M)
➢ runtime_filter_max_in_num: 如果 join 右表数据行数大于这个值,我们将不生成 IN
predicate,默认 1024
3.5.4 注意事项
(1)只支持对 join on clause 中的等值条件生成 Runtime Filter,不包括 Null-safe 条件,因为其可能会过滤掉 join 左表的 null 值。
(2)不支持将 Runtime Filter 下推到 left outer、full outer、anti join 的左表;
(3)不支持 src expr 或 target expr 是常量;
(4)不支持 src expr 和 target expr 相等;
(5)不支持 src expr 的类型等于 HLL 或者 BITMAP;
(6)目前仅支持将 Runtime Filter 下推给 OlapScanNode;
(7)不支持 target expr 包含 NULL-checking 表达式,比如 COALESCE/IFNULL/CASE,因为当 outer join 上层其他 join 的 join on clause 包含 NULL-checking 表达式并生成 Runtime Filter 时,将这个 Runtime Filter 下推到 outer join 的左表时可能导致结果不正确;
(8)不支持 target expr 中的列(slot)无法在原始表中找到某个等价列;
(9)不支持列传导,这包含两种情况:
(10)一是例如 join on clause 包含 A.k = B.k and B.k = C.k 时,目前 C.k 只可以下推给
B.k,而不可以下推给 A.k;
(11)二是例如 join on clause 包含 A.a + B.b = C.c,如果 A.a 可以列传导到 B.a,即 A.a和 B.a 是等价的列,那么可以用 B.a 替换 A.a,然后可以尝试将 Runtime Filter 下推给 B(如果 A.a 和 B.a 不是等价列,则不能下推给 B,因为 target expr 必须与唯一一个 join 左表绑定);
(12)Target expr 和 src expr 的类型必须相等,因为 Bloom Filter 基于 hash,若类型不
等则会尝试将 target expr 的类型转换为 src expr 的类型;
(13)不支持 PlanNode.Conjuncts 生成的 Runtime Filter 下推,与 HashJoinNode 的
eqJoinConjuncts 和 otherJoinConjuncts 不同,PlanNode.Conjuncts 生成的 Runtime Filter 在测试中发现可能会导致错误的结果,例如 IN 子查询转换为 join 时,自动生成的 join on clause将保存在 PlanNode.Conjuncts 中,此时应用 Runtime Filter 可能会导致结果缺少一些行。
4、SQL函数
1)查看函数名:
show builtin functions in test_db;
2)查看函数具体信息,比如查看 year 函数具体信息
show full builtin functions in test_db like 'year';
3)官网
https://doris.apache.org/zh-CN/sql-reference/sql-functions/date-time-functions/convert_tz.html