点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CV 微信技术交流群
转载自:机器之心 | 作者:香港大学、腾讯ARC Lab
本文提出了一个全新的借口任务用于视频文本预训练,叫做多项选择题(MCQ)。通过训练辅助的BridgeFormer根据视频内容回答文本构成的选择题,来学习细粒度的视频和文本特征,并实现下游高效的检索。该研究已被 CVPR 2022 收录为 Oral。
用于文本视频检索的多模态预训练工作主要采用两类方法:“双流”法训练两个单独的编码器来约束视频级别和语句级别的特征,忽略了各自模态的局部特征和模态间的交互;“单流”法把视频和文本联结作为联合编码器的输入来进行模态间的融合,导致下游检索非常低效。
本文提出一个全新的带有参数化模块的借口任务(pretext task),叫做“多项选择题”(MCQ),通过训练 BridgeFormer 根据视频内容回答文本构成的选择题,来实现细粒度的视频和文本交互,并在下游时移除辅助的 BridgeFormer,以保证高效的检索效率。

BridgeFormer: Bridging Video-text Retrieval with Multiple Choice Questions
论文地址:https://arxiv.org/abs/2201.04850
代码地址:https://github.com/TencentARC/MCQ
1. 背景
用于视频文本检索的多模态模型,需要理解视频内容、文本语义、以及视频和文本之间的关系。现有的视频文本预训练工作可以分为两大类。
第一类 “双流” 法如下图(a)所示,训练两个单独的编码器来分别获取视频级别和语句级别的特征,利用对比学习(contrastive learning)来优化特征。这一方法可以实现高效的下游检索,因为在检索时只需要用点积来计算视频和文本特征的相似度。但这种方法因为仅仅约束两个模态的最终特征,忽略了每个模态自身的局部信息,以及视频和文本之间细粒度的关联。
第二类 “单流法” 如下图(b)所示,将视频和文本联结作为联合编码器的输入来进行模态间的融合,并训练一个分类器来判别视频和文本是否匹配。这一做法可以在局部的视频和文本特征之间建立关联,但是它在下游检索时非常低效,因为文本和每一个候选视频,都需要被联结送入模型来获取相似度。
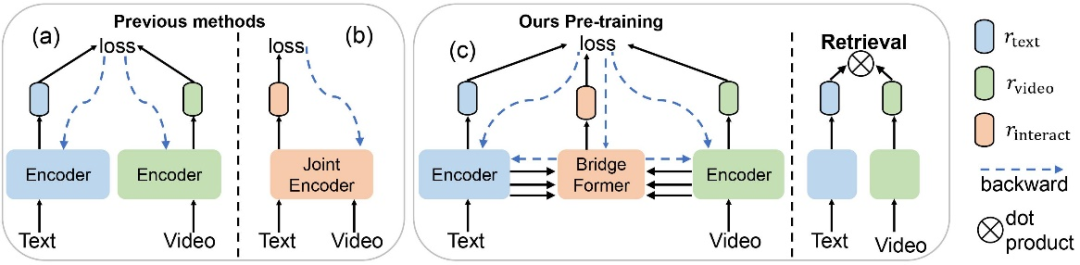
本文的出发点是希望集上述两大类方法的优点,即学习细粒度的视频和文本特征的同时,实现下游高效的检索。
具体来说,如上图(c)所示,基于双编码器的结构,该研究进一步设计一个参数化模块 BridgeFormer 作为视频和文本局部特征的纽带。该研究提出一个新的借口任务来约束 BridgeFormer,由于 BridgeFormer 联结了视频和文本的每一层特征,对 BridgeFormer 的约束进而会优化视频和文本的特征。辅助的 BridgeFormer 只用于预训练,在下游检索时被移除,从而保证了高效的双编码器结构可用于检索。
2. 启发
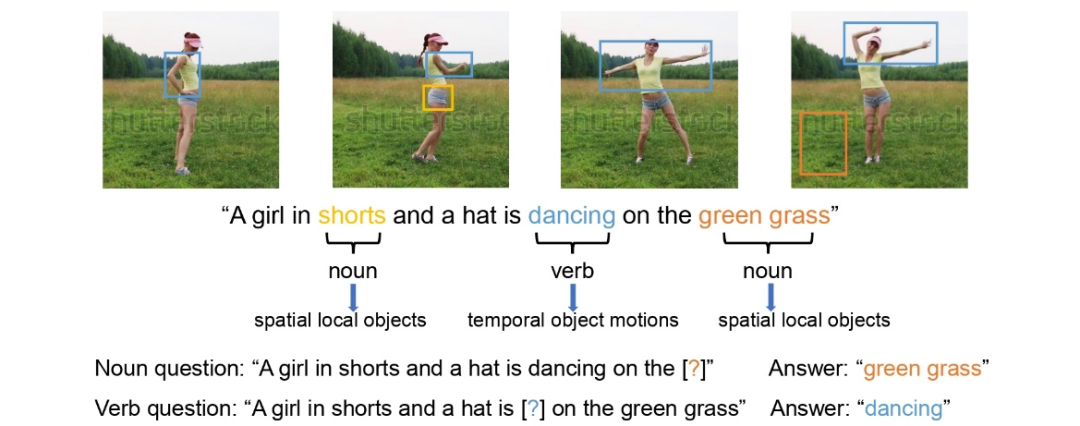
给定一个视频和它对应的文本描述,该研究观察到文本里的名词和动词短语包含丰富的语义信息。
如下图所示,该视频的文本描述为:“一个穿着短裤,戴着帽子的女孩正在绿草地上跳舞”。这其中,名词短语 “短裤” 和“绿草地”对应着视频里的空间局部物体,动词短语 “跳舞” 则可以反映视频里女孩的时序移动。因此,该研究通过抹去文本里的名词和动词短语,来分别构造名词问题和动词问题,那么正确的答案自然是被抹去的短语自身。比如当抹去名词短语“绿草地”,就构成了名词问题“一个穿着短裤,戴着帽子的女孩正在哪里跳舞”,答案就是“绿草地”。同理当抹去动词短语“跳舞”,就构成了动词问题“一个穿着短裤,戴着帽子的女孩正在绿草地上做什么”,答案就是“跳舞”。
该研究提出一个带有参数化模块 BridgeFormer 的借口任务叫做多项选择题(MCQ),训练 BridgeFormer 通过求助视频特征,回答由文本特征构成的选择题,从而实现细粒度的视频和文本交互。在下游检索时移除 BridgeFormer,来保证高效的检索效率。
3. 方法
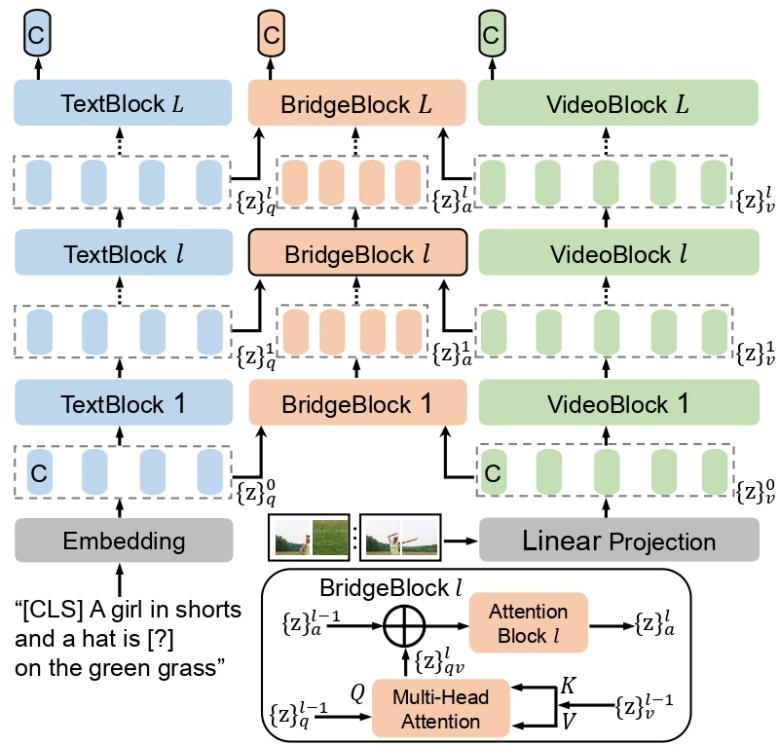
如下图所示,该研究的方法包含一个视频编码器 VideoFormer,用来从原始的视频帧提取视频特征;一个文本编码器 TextFormer,用来从自然语言提取文本特征。该研究通过抹去文本描述里的名词短语或动词短语,来分别构造名词问题和动词问题。以对比学习的形式,训练 BridgeFormer 通过求助 VideoFormer 提取到的局部视频特征,从多个选项里挑选出正确的答案。这里,多个选项由一个训练批次里所有被抹去的短语构成。
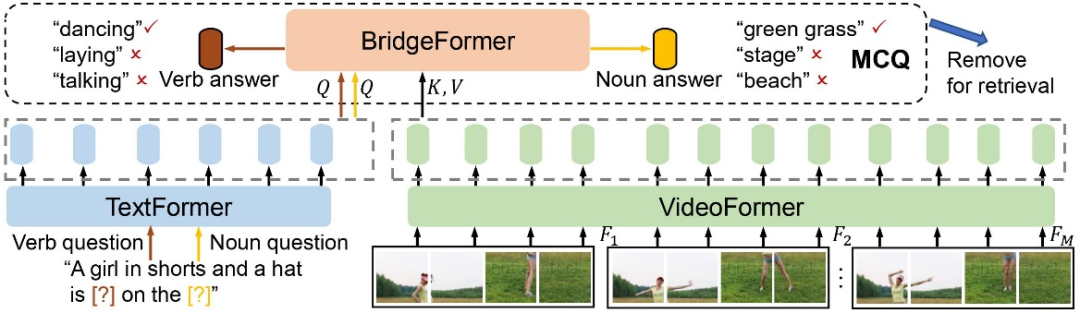
这一辅助的预训练目标会促使 VideoFormer 提取视频里准确的空间内容,使得 BridgeFormer 能够回答出名词问题,并捕获到视频里物体的时序移动,使得 BridgeFormer 能够回答出动词问题。这样的训练机制使得 VideoFormer 更能感知视频里的局部物体和时序动态。视频和文本局部特征的关联也通过问题和回答这样的形式得到了有效的建立。由于 BridgeFormer 联结了视频和文本的每一层特征,对 BridgeFormer 的约束就会进而优化视频和文本的特征。因此辅助的 BridgeFormer 只用于预训练,在下游检索时可以被移除,从而保留高效的双编码器结构。
4. 预训练流程
如下图所示,该研究预训练流程包含三个部分,来分别优化三个统一的对比学习(contrastive learning)形式的预训练目标:
1. 拉近视频和文本正样本对特征间的距离,并拉远负样本对特征间的距离(一个视频和它对应的文本描述被视为正样本对,否则就是负样本对)。
2. 训练 BridgeFormer 回答名词问题,也就是拉近 BridgeFormer 输出的名词回答特征和 TextFormer 输出的正确答案的名词特征间的距离,并拉远名词回答特征和其他名词特征间的距离。
3. 训练 BridgeFormer 回答动词问题,也就是拉近 BridgeFormer 输出的动词回答特征和 TextFormer 输出的正确答案的动词特征间的距离,并拉远动词回答特征和其他动词特征间的距离。
这里该研究使用对比学习来优化多项选择题形式的预训练目标,而不是采用传统的“masked word prediction”,也就是随机 mask 一句话里的一些单词,训练模型预测出被 mask 的单词。采用本文的这种做法有如下三个优势:
传统的 “masked word prediction” 约束模型预测出被 mask 的单词,会使得模型专注于解码 low-level 的单词本身,破坏了对模态间 high-level 的特征表达的学习。相比之下,该研究的 MCQ 以对比学习的形式拉近 BridgeFormer 输出的回答特征和 TextFormer 输出的答案特征间的距离,从而使模型专注于学习模态间 high-level 的语义信息。
该研究抹除文本里包含明确语义信息的动词和名词短语来构造有意义的问题,而传统的方法只是随机 mask 一些可能没有任何语义信息的单词。
由于问题的特征和答案的特征都是由 TextFormer 得到,这一做法可以视为对文本的 data augmentation,从而增强 TextFormer 对自然语言的语义理解能力。
消融实验也显示,相比于传统的“masked word prediction”,该研究的对比学习形式的借口任务 MCQ 在下游测评取得了更好的实验结果。
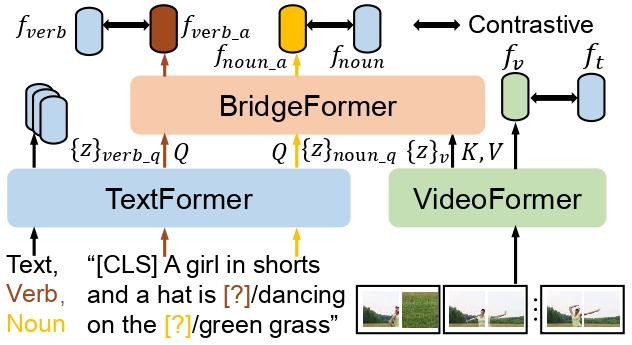
5. 模型结构
如下图所示,该研究的模型包含一个视频编码器 VideoFormer,一个文本编码器 TextFormer,和一个辅助的编码器 BridgeFormer。每一个编码器由一系列 transformer 模块构成。TextFormer 输出的每一层问题文本特征被视为 query,VideoFormer 输出的每一层视频特征被视为 key 和 value,被送入 BridgeFormer 相应层来执行跨模态的注意力机制,以获得回答特征。
6. 可视化
6.1 BridgeFormer 如何回答名词问题
下图为可视化名词问题特征和视频特征之间的注意力。在第二列和第五列,文本里蓝色的名词短语被抹除,构成了名词问题 Q1。在第三列和第六列,文本里绿色的名词短语被抹除,构成了名词问题 Q2。在第一个例子里,当 “一对老年夫妻” 被抹去,构成问题 “谁在喝咖啡”,BridgeFormer 专注于描绘人物面貌的视频特征上。而当“一盘面包” 被抹去,构成问题 “在他们面前的桌子上有什么”,BridgeFormer 把注意力集中在桌子上的物体区域。在第四个例子里,当“足球” 被抹去,构成问题 “家长和小孩在玩什么”,BridgeFormer 专注于可以和动词“玩” 构成关联的物体特征上。而当 “乡间草地” 被抹去,构成问题“家长和小孩在哪里踢足球”,BridgeFormer 把注意力放在了视频背景特征上。我们可以观察到,BridgeFormer 关注具有特定物体信息的视频区域来回答名词问题,这表明了 VideoFormer 可以从视频中提取准确的空间内容,并且 TextFormer 可以理解问题的文本语义。

6.2 BridgeFormer 如何回答动词问题
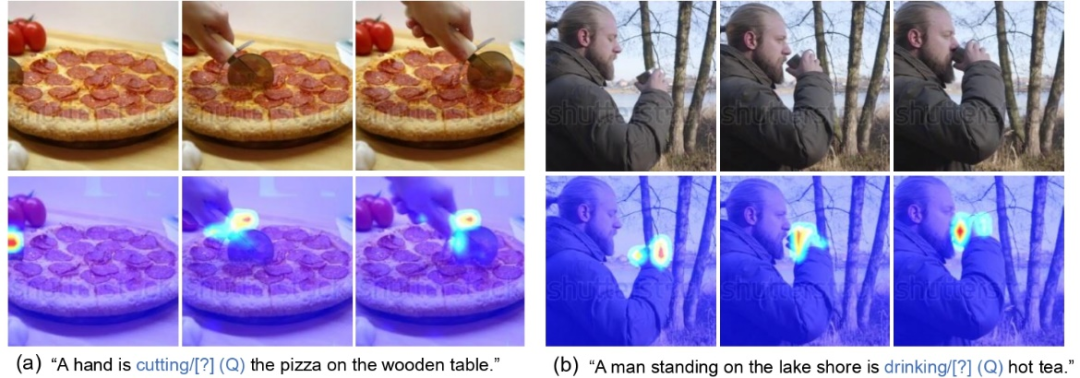
下图为可视化动词问题特征和视频特征之间的注意力。下图依次展示了一个视频里采样得到的三帧。文本里蓝色的动词短语被抹除,构成了动词问题。在左边的例子里,当 “切” 这个动词被抹去,构成问题 “一双手正在如何操作比萨饼”,BridgeFormer 关注比萨饼上餐具的移动。在右边的例子里,当“喝” 这个动词被抹去,构成问题“站在河边的男人正在怎么操作热茶”,BridgeFormer 关注握着杯子的手的移动。我们可以观察到,BridgeFormer 集中注意力在物体的移动上来回答动词问题,这表明 VideoFormer 捕获到了视频的时序动态。
7. 实验
7.1 预训练数据
该研究在图像数据集 Google Conceptual Captions 和视频数据集 WebVid-2M 上进行预训练,前者包含 3.3M 的图像 - 文本对,后者包含 2.5M 的视频 - 文本对。考虑到计算量,该研究没有使用大规模的 HowTo100M 数据集进行预训练。不过,该研究用 HowTo100M 来进行大规模的文本到视频的 zero-shot 检索测评。
7.2 下游任务
文本到视频的检索
该研究在 MSR-VTT、MSVD、LSMDC、DiDeMo 和 HowTo100M 上进行测评。采用两种测评准则,包括 zero-shot 和 fine-tune。
动作识别
该研究在 HMDB51 和 UCF101 上进行测评。采用三种测评准则,包括 linear、fine-tune 和 zero-shot。其中 zero-shot 的动作识别可以被视为是视频到文本的检索,其中动作类别的名称被视为是文本描述。
7.3 实验结果
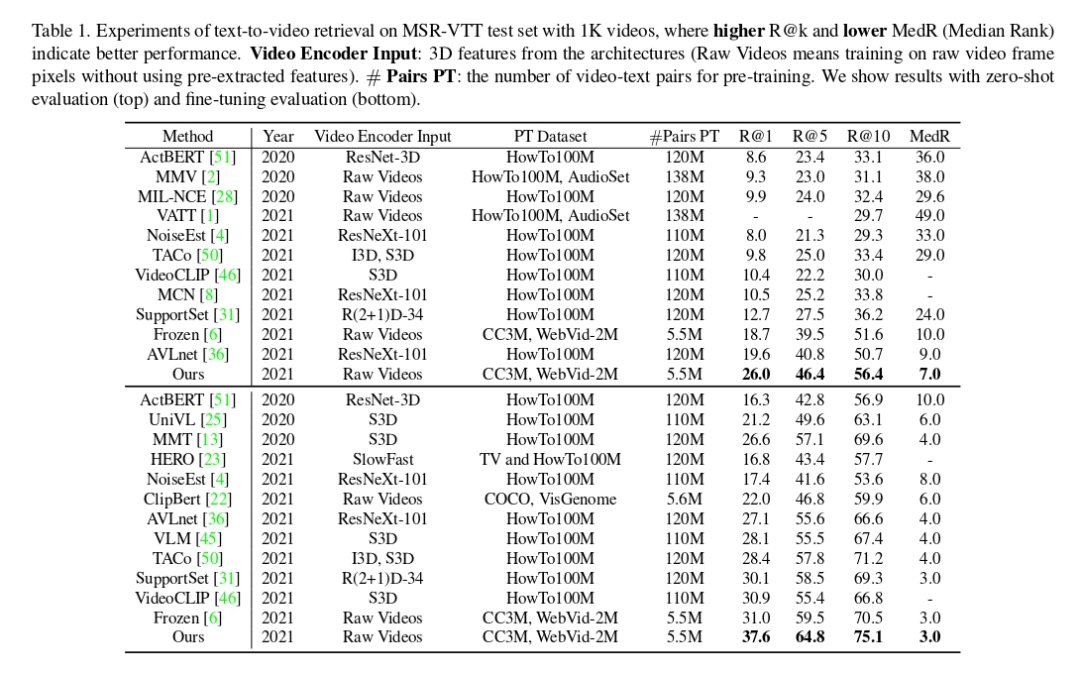
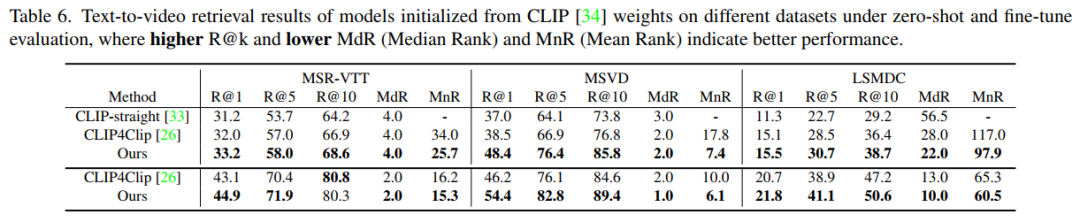
在 MSR-VTT 数据集上,文本到视频的检索结果如下表格所示。表格上面的行显示了 zero-shot 测评结果,下面的行显示了 fine-tune 的测评结果。可以看到本文方法相比于之前的方法,在两种测评基准下都有了大幅度的提升。该研究所用模型直接以原始视频帧作为输入,不依赖任何预先提取的视频特征。
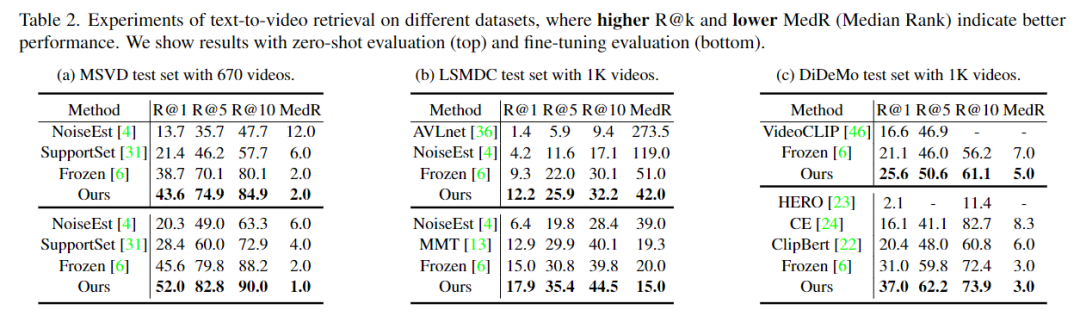
在 MSVD、LSMDC、DiDeMo 上,文本到视频的检索结果如下表格所示。本文模型同样在 zero-shot 和 fine-tune 的测评基准下,都取得了最好的结果。
该研究进一步使用 CLIP 的权重来初始化本文模型,在 MSR-VTT、MSVD 和 LSMDC 上,文本到视频的检索结果如下表格所示。该研究的借口任务 MCQ 同样可以提升基于 CLIP 的视频文本预训练的性能。
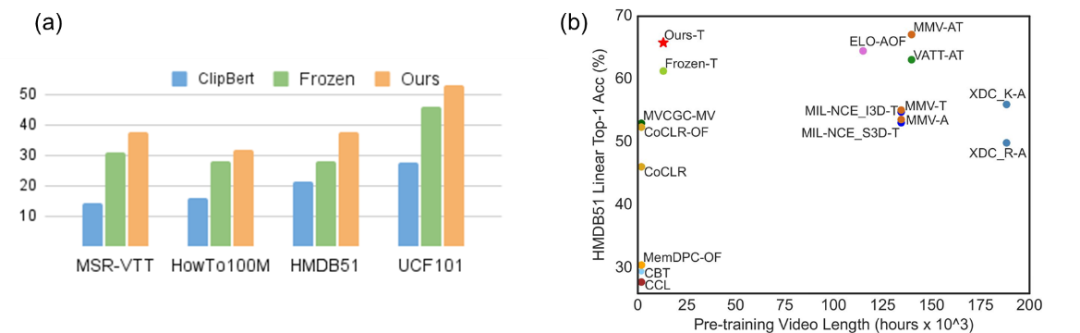
在 HMDB51 和 UCF101 上测评 zero-shot 动作识别结果如下图(a)所示,本文方法明显超出了 baseline。该研究进一步通过测评 linear 动作识别来衡量模型的单模态视频表征能力。如下图(b)所示,本文方法在时长相对较短的视频数据上进行预训练,取得了理想的结果。这显示了该研究的借口任务 MCQ 可以通过对文本语义的有效利用,增强视频的表征学习。
更多的实验结果和消融实验,参见论文。
8. 总结
本文提出了一个全新的借口任务用于视频文本预训练,叫做多项选择题(MCQ)。这一借口任务加强了局部视频和文本特征的细粒度的关联,并且实现了高效的下游检索。一个参数化模块 BridgeFormer 被训练通过借助视频特征,回答由文本特征构成的选择题,并且在下游任务时可以被移除。本文模型在文本到视频检索和零样本动作识别多个测评基准的结果,显示了 MCQ 这一借口任务的有效性。
点击进入—> CV 微信技术交流群
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()