提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、Batch size对于神经网络训练的影响
1.1 Mini-batch
1.倾向于更快的收敛(不需要遍历整个训练集来更新权重)
2.更大的批量大小可以让我们在更大程度上并行计算
3.较大的批大小往往对测试数据的泛化效果更差
在非并行化下训练下
batch size越大
1.训练损失减少的越慢
2.最小验证损失越高
3.每个epoch训练所需的时间更多
4.收敛到最小验证损失所需的epoch越多

在并行训练下
with tf.distribute.MirroredStrategy().scope()
补充
MirroredStrategy将模型的所有变量复制到每个 GPU,并将前向/后向传递计算批量分发到所有 GPU。然后,它使用 all-reduce 组合来自每个 GPU 的梯度,然后将结果应用于每个 GPU 的模型副本。本质上,它正在划分批次并将每个块分配给 GPU。 (将数据并行运行在多个模型上,组合梯度进行更新)
可以发现并行化使得每个epoch小批度计算较慢,而大批量计算速度更快。


1.2 为什么较小的批量性能更好
使用小批量的训练倾向于收敛到平坦的极小化,该极小化在极小化的小邻域内仅略有变化,而大批量则收敛到尖锐的极小化,这变化很大。平面minimizers 倾向于更好地泛化,因为它们对训练集和测试集之间的变化更加鲁棒 。

1.2.1 与大批量训练相比,小批量训练可以找到距离初始权重更远的最小值。
他们解释说,小批量训练可能会为训练引入足够的噪声,以退出锐化minimizers 的损失池,而是找到可能更远的平坦minimizers 。

 造成该现象的原因
造成该现象的原因
 如果我们使用 1 的批量大小,我们将在 a 的方向上迈出一步,然后是 b,最终在 a+b 表示的点上。(从技术上讲,b 的梯度将在应用 a 后重新计算,但我们现在先忽略它)。这导致平均批量更新大小为 (|a|+|b|)/2 — 批量更新大小的总和除以批量更新的数量。
如果我们使用 1 的批量大小,我们将在 a 的方向上迈出一步,然后是 b,最终在 a+b 表示的点上。(从技术上讲,b 的梯度将在应用 a 后重新计算,但我们现在先忽略它)。这导致平均批量更新大小为 (|a|+|b|)/2 — 批量更新大小的总和除以批量更新的数量。
但是,如果我们使用批量大小为 2,批量更新将改为由向量 (a+b)/2 表示 — 图 12 中的红色箭头。因此,平均批量更新大小为 |(a+b)/ 2| / 1 = |a+b|/2。
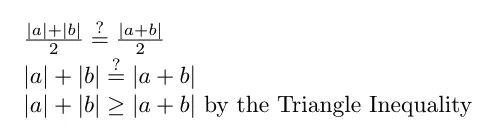
只有当所有 n 个向量都指向同一方向时,batch size=1 和 batch size=n 的平均批量更新大小才相同。
在某种意义上说,当我们扩大批量大小 |B_k| 时,梯度总和的大小相对较慢地扩大。这是因为梯度向量指向不同的方向,因此将批量大小(即要加在一起的梯度向量的数量)加倍并不会使生成的梯度向量总和的大小加倍。
1.2.2小批量训练找到更平坦的最小值
我们将锐度度量定义为最小值附近的最大损失



1.2.3 通过提高学习率可以提高大批量的性能吗
线性缩放规则:当 minibatch 大小乘以 k 时,将学习率乘以 k。


事实上,我们发现调整学习率确实消除了小批量和大批量之间的大部分性能差距。
此时大批量的最小值更加平坦,距离初始权重距离也变大。
 虽然调整学习率使大批量minimizers更平坦,但它们仍然比最小批量最小化器更锐利
虽然调整学习率使大批量minimizers更平坦,但它们仍然比最小批量最小化器更锐利
同时提高学习率也影响了训练时间
 由于大批量训练现在可以在与小批量训练大致相同的迭代次数中收敛,如图 所示,现在总体训练时间更短——批量大小 256 为 2197 秒,而批量为 3156 大小为 32。如果我们跨 4 个 GPU 并行化,则加速更加明显。
由于大批量训练现在可以在与小批量训练大致相同的迭代次数中收敛,如图 所示,现在总体训练时间更短——批量大小 256 为 2197 秒,而批量为 3156 大小为 32。如果我们跨 4 个 GPU 并行化,则加速更加明显。
1.2.4 小批量训练总是优于大批量训练吗?
因为学习率和批量大小密切相关——小批量在较小的学习率下表现最好,而大批量在较大的学习率下表现最好。
比如如下

因此,如果您注意到大批量训练在相同学习率下优于小批量训练,这可能表明学习率大于小批量训练的最佳值。
1.2.5 总结
1.线性缩放规则:当 minibatch 大小乘以 k 时,将学习率乘以 k。尽管我们最初发现大批量性能更差,但我们能够通过提高学习率来缩小大部分差距。我们看到这是由于较大的批次大小应用了较小的批次更新,这是由于批次内梯度向量之间的梯度竞争。
2.选择合适的学习率时,较大的批量尺寸可以更快地训练,特别是在并行化时。然而,当学习率没有针对较大的批量大小向上调整时,大批量训练可能比小批量训练花费的时间更长,因为它需要更多的训练时期来收敛。因此,您需要调整学习率以实现更大批量和并行化的加速。