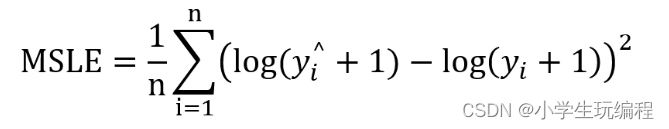在Keras框架中有如下几种loss损失函数:
①mean_squared_error或mse:均方误差是反映估计量与真实量之间差异程度的期望值,常被用于评价数据的变化程度,预测数据的精确度。
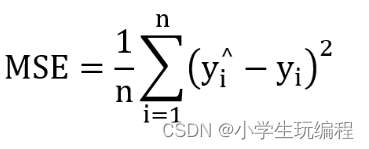
②mean_absolute_error或mae:模型预测值 f(x) 与样本真实值 y 之间距离的平均值。

参考文章:Metric评价指标及损失函数-Error系列之平均绝对误差(Mean Absolute Error,MAE)
③mean_absolute_percentage_error或mape:平均绝对值百分比误差则是用真实值与预测值的差值比例进行计算的,通常会乘以百分比进行计算,一般用于回归计算。这是销量预测最常用的指标,在实际的线上线下销量预测中有着非常重要的评估意义。
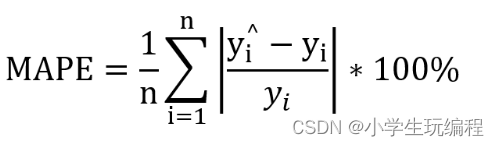
参考文章:TensorFlow 2.0 深度学习实战 —— 详细介绍损失函数、优化器、激活函数、多层感知机的实现原理
④categorical_crossentropy和binary_crossentropy:
二分类问题:
如果是二分类问题,即最终的结果只能是两个分类中的一个,则损失函数loss使用binary_crossentropy。
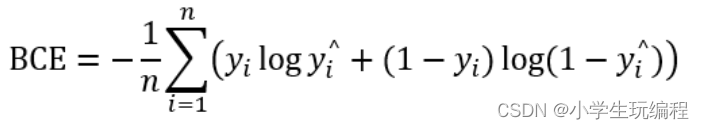
多分类问题:
对于多分类问题,在选择损失函数loss时,主要是看数据是如何编码的:
1.如果是分类编码(one-hot编码),则使用categorical_crossentropy。
我对one-hot编码的理解是:one-hot编码就是在标签向量化的时候,每个标签都是一个N维的向量(N由自己确定),其中这个向量只有一个值为1,其余的都为0。也就是将整数索引i转换为长度为N的二进制向量,这个向量只有第i个元素是1,其余的都是0。
Keras有内置的将标签向量化的方法:
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
2.如果是整数编码,则使用sparse_categorical_crossentropy。
我对整数编码的理解是:整数编码就是对所有标签都放到一个向量中,每个标签对应向量的一个值。
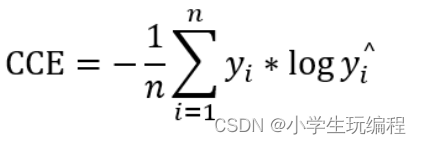
参考文章:损失函数的选择:binary_crossentropy、categorical_crossentropy、sparse_categorical_crossentropy
⑤mean_squared_logarithmic_error:一般用于回归计算。当目标具有指数增长的趋势时, 该指标最适合使用, 例如人口数量, 跨年度商品的平均销售额等。