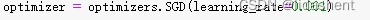文章目录
前言
流程
回归问题预测连续值,在某个区间内变动.
常见的线性回归问题模型是y=ax+b,然而现实世界由于大量的数据偏差以及复杂度,同时还有大量的噪声,往往达不到如此的精确解,实际解决问题时需要考虑噪声的存在

对于噪声,往往我们已经假设了它符合高斯0-1分布,如果噪声是随机的就无法推算了
问题在于这组数据是如何分布的
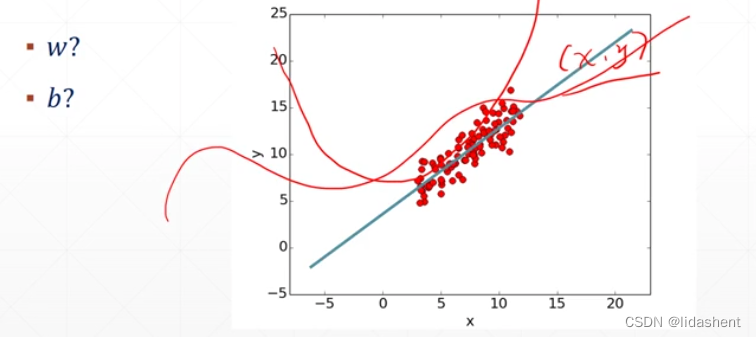
一小组数据在某个区间内的函数图像究竟是如何?
如何去求解wb?来自主优化其数据迭代?
在此之前设定一个评价函数

预测值和真实值得平方和越来越小时,loss函数将起作用
问题是如何自动更新合适的w和b来达到这个效果?
要确保w和b快速收敛,准确的沿数据的变化走向进行预测,loss越小越准
准确的说w和b沿着loss函数下降的方向前进
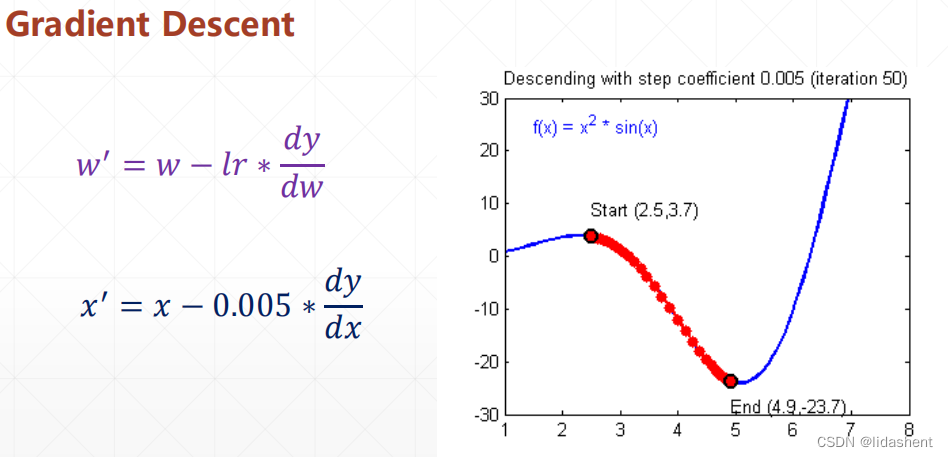
lr代表步长,这个需要合适设置避免进入相对最小值
衰减因子则代表着沿着增大的导数的反方向前进,如果导数为正,则是图像是数据增大方向,则x变小寻找山谷,如果导数为负,则图像数据减小方向,则x增大,寻找山谷如是
(数据图像,导数图像,对导数的变化求最小值的方向)
比如当前位置3.2,导数-23.3 则,位移变化方向是 3.3165
x=3.2-(-23.3*0.005) x2=x-△w
这只是w的一种情况,然后看b,二维向量图,从随机点开始进行梯度下降
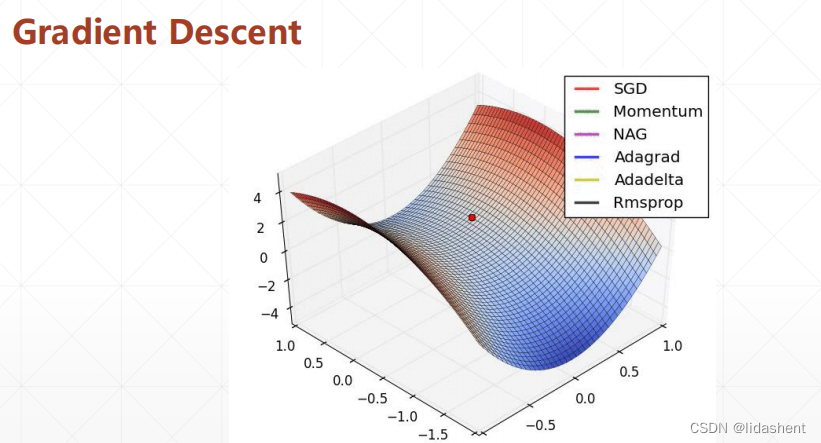
三个轴分别代表了w,b和z轴loss,
公式为

运行后会自动找到合适的wb对数据进行公式建模
预测值和真实值之间的平方差成为了loss函数,这样将求解最佳wb的问题变成了求解最小loss的问题
然后loss代表梯度,w和b向着梯度减小的方向前进,每次梯度变化可能非常大,因此需要进行步伐控制
δloss代表平均值loss.总loss/len样本数量
因此计算loss代码为
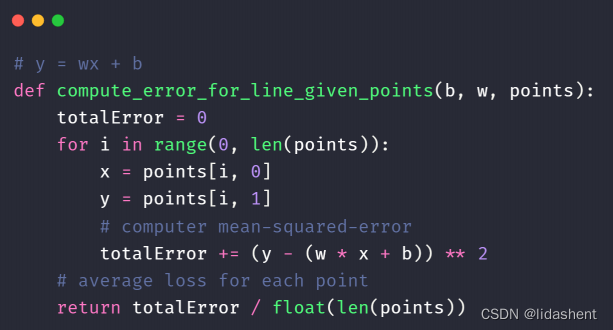
数学原理

x^2求导得到2x,所以δloss/δw=2xxxxx +2xxxxx…
b导数为1,因此…
根据loss对w和b的导数,确定那里是梯度下降的方向,对w和b进行更新,变相的求loss下降的方向
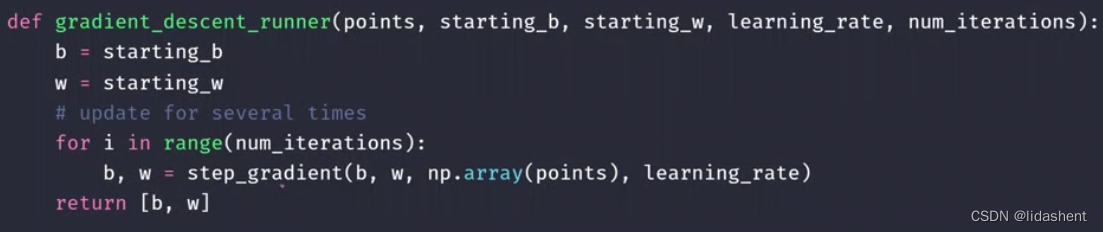
代码实现为:

然后不断迭代就得到了应有的w和b权重
基于线性模型建立的有如下三种
线性模型
二分类模型(sigmod函数用于划分01)
多分类模型

案例操作
使用numpy实现与tensorflow对比实现两者
tensorflow2.4运行即可,带数据与代码
https://www.aliyundrive.com/s/LmAms9tzWdq
从minist数据集理解多分类问题
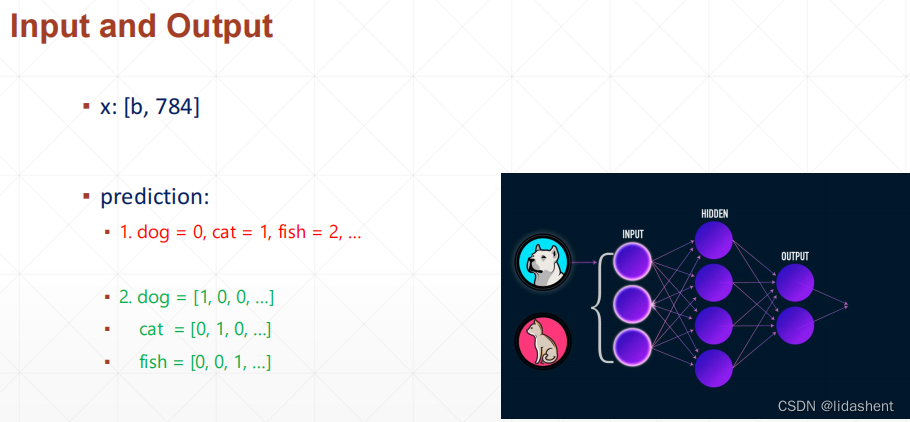
minist数据集是0-9的手写数字数据集,每张图片张量为(28,28,1),分别意味着行,列,rgb

实际使用中需要压缩信息,为一维,(1,784),展开方式为行末对行首,从上至下
问题是如此的图像如何进行10种类型分类?
对于结果如果使用1234种类则存在大小关系等等,这是不科学的,因为每个种类的概率是独立的,没有顺序的
因此使用one-hoting编码更为合适,独立输出每个类别的概率,合为1

使用y=wx+b,简化模型
此处x为一维矩阵,784列
w为(784,10), b为10
从矩阵的基本乘除方法得知,则每张图片的识别为(1,784) * (784,10)=(1,10) ,创建了权重矩阵和偏置矩阵对图像进行描述
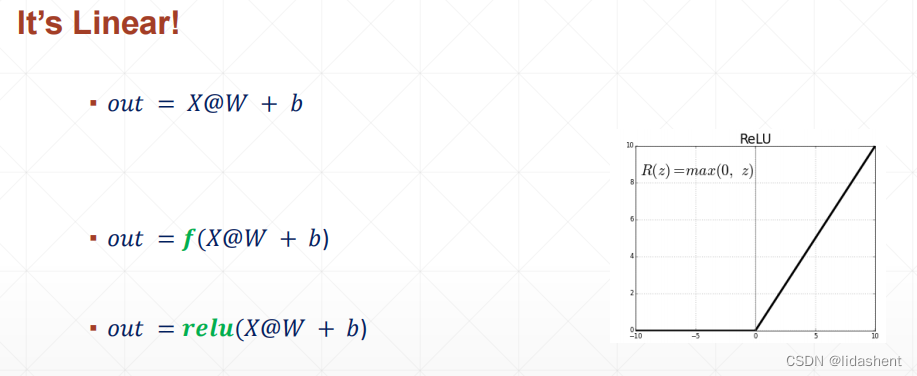
然而,模型过于简单,实际上图像的内容千差万别,简单的模型并不能有效提取图像的特征
因此需要使用一个激活函数对y=wx+b进行非线性转化,使之更加贴近虚拟的真实数据分布曲线,可以看做模型曲线就是由众多的y=wx+b进行描述的
然而,一层往往还不够,还需要激活多次才能让曲线足够贴合,这样就有了隐藏层的概念,即是多层网络对图像进行逐次降维,防止一层网络的识别不准问题
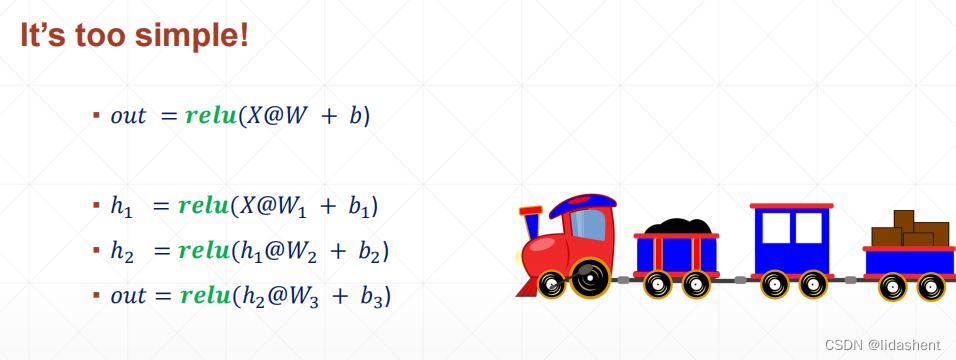
先将图像由784维度,转到512维度,再次转为256,最后降维到10得到分类

然而,如何评价网络设计的好坏呢?如果降维不准确,如何反复迭代呢?数据如何反向传播优化wb呢?
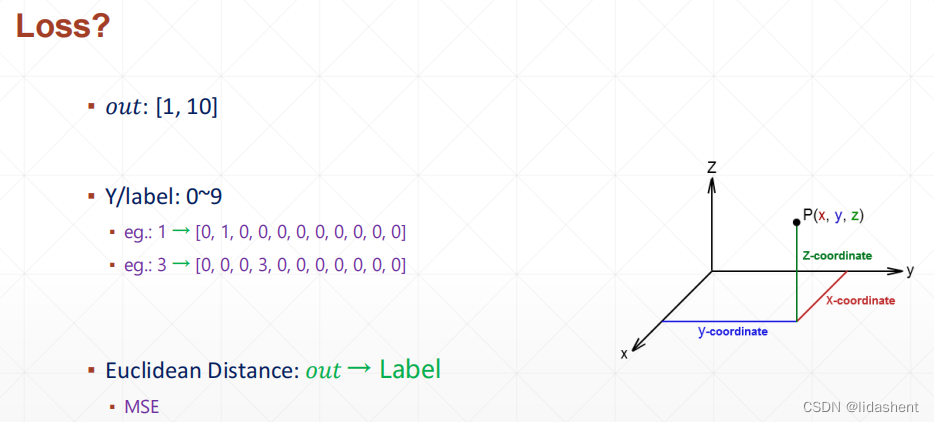
输出分类中的一种,计算真实值和预测值之间的欧式几何距离∑(y-out)^2
如图所示
数学模型如下,随机初始化wb,然后进行迭代得到更新后的wb,使用wb矩阵进行预测,计算损失值loss

然后计算loss下降曲线,反向更新wb,计算loss的导数方向步伐前面已经有讲述,直到得到最小loss

顺便这里讲述一下为什么使用GPU而不是cpu进行图形加速计算?
因为cpu的架构设计是顺序串行的,而gpu的大量核心堆叠的并行架构,往往计算核心数量达到4000以上
图像处理大量的像素点生成使用多核计算更为高效

minist手写识别实践
https://www.aliyundrive.com/s/6oxtQpsCdTh
讲解
minist数据可以从网络上下载,四个文件
也可以直接用代码自动加载,从网路上下载,太过于有名而地址被直接集成到函数中了
tensorflow的datasets包集成了mnist
这里使用了60k的训练集,图片维度和标签如下
此时y还没有进行独热编码

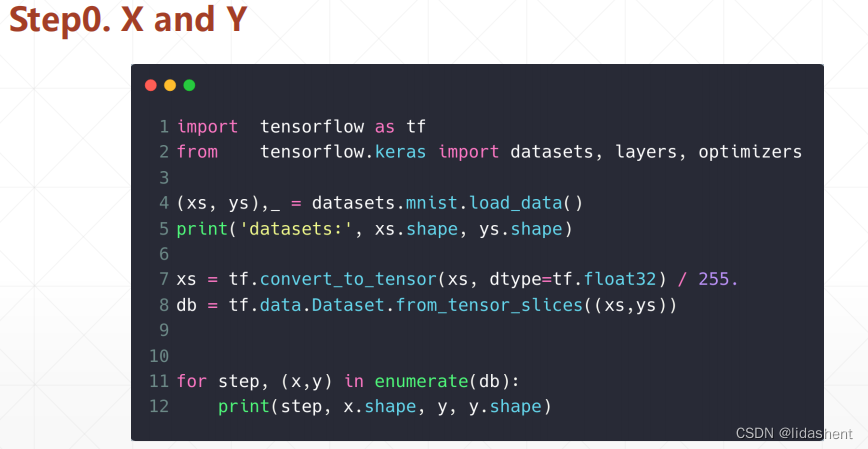
需要注意的是拿到的数据是numpy格式,要使用gpu加速还需要转化为tensor格式

当然数据集不可能一张张图片进行计算,所以有一个batch概念,代表数据块,容纳多少图片进行运算
然后是全连接层,逐步降维

对于w和b使用给定的规则进行更新