0、前言
本博文参考论文《Improving meta-learning model via meta-contrastive loss》讲述元学习在小样本学习中的应用,并在小样本学习的设定下,对学习所得的元知识进行正则化,提出元对比损失的正则化方法来提高元学习方法的性能。
1、理论基础
1.1 元学习方法
元学习框架被广泛用于解决小样本学习问题。小样本学习中的元学习方法大致可分为三类,基于度量的方法、基于模型的方法和基于梯度的方法。
-
基于度量的方法:这种方法的动机可以描述为学会去比较。例如,使用带有注意力块的递归神经网络作为特征抽取模型来学习如何评估欧几里得空间中示例之间的相似性。用原型(即样本的均值表征)表示每个类别,并利用欧几里德距离来测量测试样本与原型之间的相似性。与预定义的度量空间不同,使用神经网络自动学习度量函数。
-
基于模型的方法:这种方法通常采用额外的内存来存储过去的样本或精心设计的系统来引导对小样本数据学习得到的模型进行优化。使用循环神经网络作为高级模型来指导模型在特定任务中的更新。使用外部记忆增强神经网络来保存看到的样本,并利用它们通过几个样本来预测结果。这种方法通常非常复杂且难以训练。
-
基于梯度的方法:基于梯度的方法通常利用层次结构来学习元知识。与模型无关的元学习 (MAML)旨在为任务特定的学习模型学习一个良好的初始化。在新任务中,任务特定的模型可以在这个初始化的基础上通过几个梯度更新步骤获得。但是,MAML 仍然存在许多局限性。许多工作被提出来改进它。除了 MAML,一些基于梯度的方法建立在双层优化框架上,旨在将跨任务表示作为元知识,以帮助学习新任务。几乎所有基于梯度的方法都采用内循环学习过程,导致如何有效地优化基于梯度的方法成为一个问题。
1.2 元正则化
正则化是机器学习中一种有用的技术,可以显式设计以改进学习算法。Dropout是一种正则化,用于在训练期间从神经网络中随机删除神经单元(连同它们的连接),以防止单元过度共同适应,是深度学习中一种流行的正则化方法。在元学习模型中,有学者提出了一种元正则化来实现良好的跨域泛化,使用梯度丢失来缓解元学习中的过拟合问题,但是,它是针对基于 MAML 的方法进行定制的。
1.3 对比学习
对比学习是机器学习领域的热门话题,也是无监督学习工作的核心。对比学习的许多研究中使用对比损失来衡量表示空间中样本对的相似性,从而学习得到良好的数据表示。这种表示可以应用于许多下游任务。一些文献将该方法的成功归因于潜在表示之间互信息的最大化。
2、元学习在小样本学习任务中的应用
2.1 问题描述
标准的有监督学习问题通过一个任务采样得到训练数据,然后学习一个函数。在小样本学习的设定下,通常有一系列任务采样得到训练数据来学习先验知识(即确定一个良好的初始化模型),可以帮助特定任务下(新任务)使用少量标记数据就可以有效地训练新任务下的模型(在初始化条件下通过几个梯度更新步骤获得新任务下的模型)。每个任务包含一个少量注释数据的训练数据集和一个测试数据集 ;根据学习问题的不同,训练任务的形式也不同。比如,在小样本分类任务中,任务被描述为N类K样本的分类任务(给定共N个类,每个类有K个样本的分类任务),测试数据集包含同样的N个类,每个类有Q个样本;对于小样本回归问题,任务被描述为一个K样本的回归任务,训练数据集包含K个样本,测试数据集包含Q个样本。
考虑到小样本学习任务中,我们通常会收集一个包含少量注释数据的训练数据集(又称为support set)和一个包含大量测试数据的测试数据集(又称为query set)。有限的数据无法代表整体,会导致对整个数据集的描述存在偏差,因为support set通常是从数据分布的一小部分中采样得到的(如下图所示),这个问题导致support set和query set之间的数据差异。
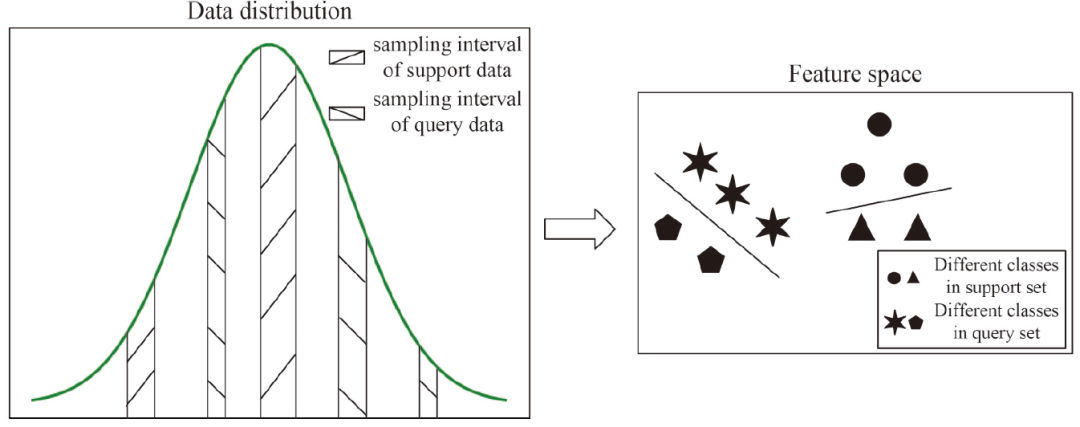
因此,从support set学习得到的模型在query set上不能表现出很好的泛化性。在小样本学习任务中,元学习的目的是学习有用的元知识作为先验知识,以帮助模型在数据量较少的情况下进行学习。因此,如何学习有用的元知识对于元学习模型至关重要。同时,在小样本学习的设定下,很少有相关的研究去利用适当的正则化技术来提高元学习方法的性能。
这篇文章专注于如何设计适当的元正则化来提高基于梯度的元学习模型在小样本学习中的性能。受对比学习的启发,这篇文章提出了一种元对比损失来帮助元学习模型对齐在support set和query set训练得到的模型。这样,元学习模型能学习到更好的元知识。实验结果表明,该方法与模型无关,可以在各种小样本学习场景中改进各种基于梯度的方法,可以应用于不同的学习问题。
2.2 元对比损失正则化方法
尽管基于梯度的元学习方法在小样本学习任务中取得了成功,但很少有文献关注为元学习方法设计元正则化以提升小样本学习的性能。论文《Improving meta-learning model via meta-contrastive loss》为了克服这个问题,提出了一种元对比损失将学习到的元知识正则化,从而具有更好的泛化性。文章的方法建立在先验知识的基础上,即support set和query set训练所得的模型应该在每个小样本学习任务的模型空间中很好地对齐。通过这种方式,从少量监督信息中学习得到的基础模型可以在包含许多未知样本的query set上表现出良好的泛化性能。
为了达到元学习对齐support set和query set训练所得模型的目的,受对比损失在对比学习中的作用的启发,定义元对比损失(元正则化项),并以最小化元对比损失实现模型的对齐。回顾对比学习,对比损失旨在最大化潜在空间中相同数据样本之间的一致性,以学习得到良好的表示。对比学习中需要特征表示进行配对,借鉴这个想法来实现模型的对齐。但是,学习得到的模型可能包含多个组成部分,例如是权重矩阵,而不是权重向量。
因此,在该文的元对比损失中,权重向量被视为“数据”,这不同于对比学习中将图像作为数据。在该文的方法中,与同一类别相关的权重向量应该在模型空间中对齐。 在数据集训练学习模型的过程中,假设有一个训练数据集S,可以通过一个损失函数学习得到以w为参数的模型,通过一个优化算法
,例如梯度下降,可以得到参数
。可以看出,数据集S和学习得到的参数
存在一一映射关系。从这个角度出发,学习得到的模型
可以看作是在模型空间中对应数据集S 的一种特征表示。对于小样本学习而言,在support set 上训练所得的基础模型也应该在query set 上有好的特征表示。通过所提出的元正则化方法在模型空间中对齐
和
,下图对该方法进行了简单的解释:
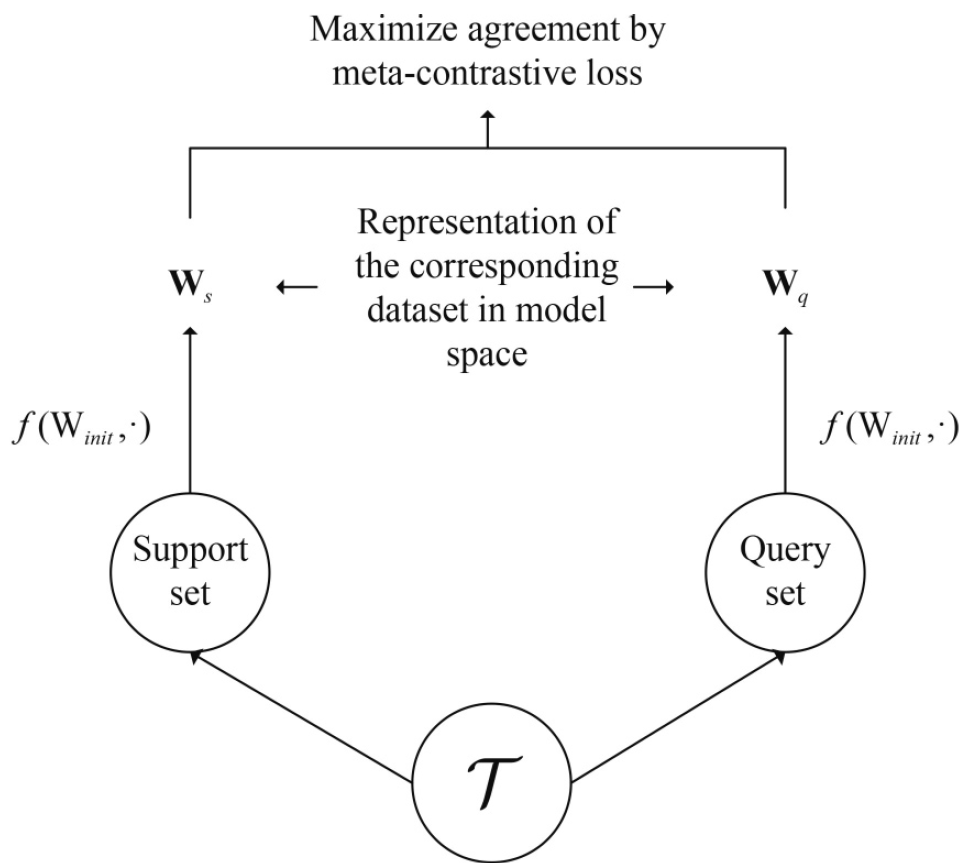
算法步骤:假设从任务集S中随机采样一个任务T,在T中的support set和query set被分别定义为,通过不同的元学习方法,在
上训练可以得到学习模型,分别定义为
;考虑到
包含C个权重向量,即
,
,正例对可以表示为
;然后,针对正例对
提出的元对比损失为:
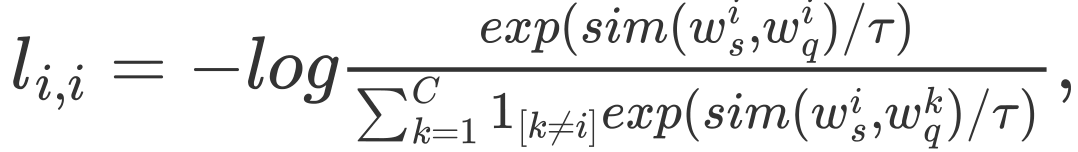
其中:为指示函数,即当时
时该函数值为1。
表示经过规范化的u和v的点积,即余弦相似度。
最后的损失是在中所有的正例对上计算所得的。算法1展示了该文提出的方法:

算法1中为本文提出的元对比损失正则化项。
3、总结
-
考虑到小样本学习任务中support set和query set之间的数据差异,设计了一种致力于消除这种差异的元对比损失,来提高基于梯度的元学习模型在小样本学习任务中的性能。
-
与无监督学习中传统的对比损失相比,这篇文章的方法侧重于任务级别,对齐模型空间中的参数矩阵,而传统的对比损失旨在对齐特征空间中的特征向量。
-
大量实验表明,这篇文章的方法可以提高各种基于梯度的元学习模型的性能,并且在小样本学习的分类任务和回归任务中表现良好。