源自:《计算机工程与应用》
作者:刘 兵,杨 娟,汪荣贵,薛丽霞
摘 要
小样本学习是视觉识别中的一个受关注的领域,旨在通过少量的数据来学习新的视觉概念。为了解决小样本问题,一些元学习方法提出从大量辅助任务中学习可迁移的知识并将其应用于目标任务上。为了更好地对知识进行迁移,提出了一种基于记忆的迁移学习方法。提出一种权重分解策略,将部分权重分解为冻结权重与可学习权重,在迁移学习中通过固定冻结权重,仅更新可学习权重的方式来减少模型需要学习的参数。通过一个额外的记忆模块来存储之前任务的经验,在学习新任务时,这些经验被用来初始化模型的参数状态,以此更好地进行迁移学习。通过在miniImageNet、tieredImageNet以及CUB数据集上的实验结果表明,相对于其他先进的方法,该方法在小样本分类任务上取得了具有竞争力甚至是更好的表现。
关键词
小样本学习;迁移学习;记忆模块;元学习
近年来,深度学习在图像分类[1-3]、目标检测[4-6]、机器翻译[7-8]等人工智能任务上取得了卓越的进展。在某些图像领域中,深度模型的分类、检测、识别能力已经接近甚至超越了人类。然而这些成就无不依赖于一个限制,即训练一个有效的深度模型需要大量的带标签样本。当训练样本不足时,深度模型很容易会产生过拟合问题,导致学习失败。对于深度模型而言通过少量样本进行学习是相当困难的任务,但对于人类来说却是十分简单的过程,例如,即使是从未见过“老虎”形象的孩子仅通过几张“老虎”图片就能习得“老虎”的视觉概念。受此启发,小样本学习应运而生。小样本学习任务是指在训练过程中,对于从未见过的类别,在给出这些类别的少量样本的情况下,仍然能学习到一个具有优秀辨别力的分类器。由于小样本学习关注于深度模型在样本量受限的情况下的学习问题,故小样本学习的应用非常广泛,例如,对医疗影像中的罕见病例进行识别分类来辅助诊断,或是在海量监控视频中对嫌疑人进行搜索识别来辅助侦察等。这些任务之间存在着明显的共性,即仅通过几张带标签的样本来学习一个有效的分类器,而不需要百万乃至千万级别的标注数据。除此之外,小样本学习还极大地减轻了样本标注的工作量。故旨在通过少量的标注样本来习得一个新视觉概念的小样本学习,正在吸引更多的关注。
小样本学习方法大致分为三种:数据增强、度量学习以及元学习。由于小样本学习中最根本的问题是训练样本的匮乏,故数据增强方法尝试借助一些额外信息来扩充当前的训练数据。一些典型方法[9]提出将样本映射到特征域,并在特征域进行增强,如将数据映射到语义空间,借助额外的语义信息对数据进行增强。然而数据增强方法生成的样本与原样本之间存在视觉相似性,很难从根本上解决模型因样本不足而产生的过拟合问题。度量学习方法的思想比较直接,它通过学习样本与特征之间的映射关系,将样本映射到一个公共的特征空间,在这个特征空间中,样本之间采用相似度进行度量,同类别之间的样本距离较近,不同类别之间的样本距离较远,查询样本通过寻找最近邻的类别来实现分类。然而由于极端的样本量限制,学习一个高质量的特征空间相当困难。与度量学习方法不同,元学习方法是任务级别的方法。元学习方法通过基础学习器与元学习器之间的协调工作,来得到一个最优的参数状态,模型基于该参数状态仅需少量样本的迭代学习即可习得新类别。具体而言,在学习过程中,基础学习器从每个独立任务中快速地获取知识并将这些知识传递给元学习器,元学习器通过积累大量任务上的总体知识来达到一个最优的参数状态,用该参数状态来更新基础学习器的参数,此时基础学习器便拥有了在新任务上快速学习的能力,因而适合小样本学习。
元学习中一个代表性的方法是MAML(modelagnostic meta-learning)[10]。在MAML的一轮迭代中,基础学习器学习多个独立任务,并在每个任务中将由误差产生的梯度信息传递给元学习器,元学习器通过累积这些任务上的梯度信息来获得经验风险最小化的梯度,进而优化元学习器参数,最后再用更新后的元学习器参数初始化基础学习器,来进行下一轮的迭代。由于元学习器学习大量任务的整体知识,故元学习器的参数在收敛时便具备了在各个任务上快速泛化的能力,此时用元学习器的参数来初始化基础学习器,通过若干次微调,基础学习器便可以快速学习新任务。
然而,MAML 通过微调基础学习器的学习方式依然困难重重,认为有两个因素限制MAML 的有效性。首先,在小样本学习中,基础学习器虽然具备在新任务上快速泛化的能力,但是相对于需要微调的参数量,用来微调的样本仍然过少,这会导致微调效果不佳。其次,基础学习器的初始化状态是元学习器在大量任务上习得的总体趋势,而在具体任务中并不是最优的状态,尤其是当新任务偏离总体趋势时,基础学习器的初始化状态并不足以支撑其在新任务上的微调。
为了解决这两个问题,提出了基于记忆的迁移学习方法,本文提出以下创新点:
-
(1)提出了权重分解策略来解决基础学习器中需要微调的参数量过多的问题。具体而言,将部分卷积层的权重进行分解,将具有泛化能力的部分作为泛化权重,对任务敏感的部分作为敏感权重。将预训练权重固定下来作为泛化权重,仅微调敏感权重来学习新任务。这样的分解策略在小样本学习中很有意义,泛化权重可以保证模型在学习过程中始终具备泛化能力,避免过拟合的发生,与此同时,需要微调的参数量极大地减少了,意味着学习过程更容易收敛。
-
(2)借助一个额外的记忆模块来更有效地初始化基础学习器。在元学习阶段,模型通过微调敏感权重来学习新任务,借助一个记忆模块将任务信息与敏感权重信息关联起来,并存储于记忆中,随着网络对任务的学习进行同步更新。每当遇到新任务时,记忆模块便根据当前任务在记忆中查找最相关的任务,来获取最相关任务对应的敏感权重,并用该敏感权重来初始化当前模型的参数,使得初始化参数具备任务相关性,有效地避免了新任务偏离整体趋势时,初始化状态难以支撑微调的情况,进一步提升微调效果。
1 小样本学习
1.1 小样本学习方法
小样本学习问题取得的研究进展主要为以下几个方向:数据增强,度量学习以及元学习。最近,转导学习同样获得了不少的关注由于其在分类效果上的提升。
小样本学习的关键问题是缺乏足够的训练样本,故数据增强方法是解决小样本问题最自然的方法。由于标准的数据增强方法,如裁剪、旋转、加噪等方法,生成的图片与原始图片存在着极大的视觉相似性,很难在小样本学习中起作用,故在小样本问题中,数据增强方法往往需要借助额外数据,从中获取可迁移的知识来扩充训练数据。Zhang等人[11]提出通过两个特征提取器分别提取图像的前景特征与背景特征,通过将不同的前景与背景进行组合,来生成更多的合成图像,以此实现数据集的扩充。Wang 等人[12]则是在特征域构建一个生成器,通过对特征进行加噪,来生成新的实例。Chen 等人[9]进一步将视觉特征映射到语义空间,在语义空间中借助语义信息进行数据扩充,通过将扩充数据映射回视觉空间来获得更多的扩充样例。
度量学习方法将样本映射到一个低维的嵌入空间中,在这个空间中样本的特征变得更具有辨别力,通过度量的方法对样本进行分类。Koch 等人[13]借助孪生网络结构来学习两个输入样本之间的相似度,通过对相似度分数排序来实现分类。Vinyals 等人[14]在样本到嵌入空间的映射过程中加入了注意力机制,并首次提出了episodes 训练策略。Snell 等人[15]提出在嵌入空间中,各个类别都以各自的类别原型表示,查询样本通过计算与各个类别原型之间的欧式距离作为与各个类别的相似度,最后基于相似度进行分类。Sung等人[16]采用神经网络来学习距离度量的方式而不是固定的度量方式。Li等人[17]通过比较查询样本与各个类别之间的局部描述子来寻找最接近的类别。Li等人[18]使用协方差矩阵来表示每个类别,同时提出协方差度量方式来进行距离的度量。
元学习方法通过学习一系列相关任务来归纳出这些任务的本质规律,当面对新的任务时,可以根据习得的知识快速拟合与泛化。Finn 等人[10]通过元学习器积累任务的总体趋势,以此来更新基础学习器的参数,使得基础学习器在遇到新的学习任务时,具有快速拟合的能力。Ravi 等人[19]用基于LSTM 的元学习器来模拟梯度下降的过程,LSTM通过其细胞状态来更新分类器网络的参数,最后在新的任务中来指导分类器网络的更新。Li 等人[20]提出不仅学习基础学习器的梯度下降过程,而且还学习基础学习器的更新方向和学习速率。
转导学习方法提出将所有的待预测样本送入网络并同时进行预测,以此来学习所有样本(包含带标签样本与不带标签样本)之间的关系。Liu 等人[21]利用所有的样本来进行转导推理,在这一过程中将标签从带标签的样本传递至不带标签的样本。Ye 等人[22]提出通过自注意力机制将任务无关的样本特征转换成任务相关的样本特征,从而更好地进行分类。Li等人[23]借助样本实例与其邻居实例之间的关系来实现对该样本的特征增强。
1.2 迁移学习
迁移学习的目标是将在某些任务上学习到的知识或经验应用到不同但相关的任务中。对于深度模型,一种行之有效的迁移学习方法是将预训练模型应用于新任务,称之为微调。在小样本学习中,迁移学习通过微调在大量任务上预训练的模型实现在新任务上快速学习,这些任务之间需要存在一定的相关性,如共享的特征、相似的语义属性或是相关的上下文信息。在度量学习[14-15]中,通过将在源数据域上习得的度量空间迁移到新类别的方法取得了不错的效果。元学习方法[10,19]往往也依赖于迁移学习,元学习器习得了跨任务的知识后,指导基础学习器学习新任务的过程往往采取微调的方法。比如MAML 在每一次迭代中,元学习器都会指导基础学习器的初始化,当遇到一个新任务时,基础学习器通过微调的方法来快速适应这个任务。
1.3 记忆网络
在小样本学习中,元学习方法在解决小样本问题时的核心思路是用源数据域上的可迁移知识来帮助新类的学习,因此记忆网络常作为知识迁移的媒介应用于元学习方法中。记忆网络的一个应用是作为注意力模块来帮助网络进行学习。如MN(matching nets)[14]基于LSTM 提供注意力机制来尝试挖掘查询样本与训练样本之间的联系,以此使得查询样本在嵌入空间中更具有辨识性。记忆网络的另一个应用是作为一个存储信息的记忆模块,在训练时将先验知识存储到记忆模块中,在测试时使用这些信息进行预测。Santoro 等人[24]提出借助神经图灵机(NTMs)将特征信息与对应标签关联起来,以此实现特征向量准确分类。He等人[25]提出在学习过程中将大量特征和标签存储于记忆中,当学习新类时,借助记忆中的信息对当前任务的特征进行增强。
2 方法
基于记忆的迁移学习方法最核心的思想是借助一个记忆模块来给元学习器(分类器)提供一个最优的初始化状态,从而实现在新任务上的快速学习。如图1是整体的网络结构。支持集样本经过特征提取器后输出对应的特征表示,之后在记忆模块中,所有的特征表示会被下采样为一个任务级别的表示,在接收到任务表示后,读控制器输出与当前任务最相关的权重信息,这些权重信息可以有效地初始化分类器网络中的敏感权重。最后敏感权重经过简单微调后,与泛化权重共同作用组成分类网络权重对样本特征进行分类。每个任务完成学习后,更新后的敏感权重信息与当前的任务信息会进行配对存储进记忆中。

2.1 问题定义
对于N-way K-shot的小样本分类任务,每个任务T 由支持集与查询集两部分实例集合组成。其中,支持集S={( x1,1,y1),( x1,2,y1),…,( xN,K,yN )}由N 个类别中每个类别采样K 个带标签的实例构成,其中xi,j 表示第i 个类别中第j 个样本,yi ∈{ }1,2,…,N 表示所属类别,查询集Q={q1,q2,…,qN×M}由与支持集相同的N个类别中采样除支持集S 以外的不带标签的实例构成,即S ∩Q=∅,qi 表示第i 个查询样本。小样本学习的最终目标是挖掘支持集S 的先验知识,并用其预测查询集Q 中样本的类别。
然而,由于训练样本极度缺乏,直接进行预测的方式会面临严重的过拟合风险。普遍的方案是借助一个辅助的元训练集 Dbase 学习可迁移的知识来提升网络的泛化能力。Dbase 由大量属于Nbase 类别的带标签样本构成,并且与目标小样本任务的标签空间不相交,即Nbase ∩Ntarget=∅。与此同时,使用episodes训练策略[14]来训练网络,这个训练策略被广泛地应用于小样本学习的论文中,并取得了不错的效果。即在元训练过程中,对于每一个episode T̂ ,从Nbase 类别中采样N 个类别,每个类别采样K 个带标签的样本作为支持集Ŝ,同样取这些类别中除Ŝ之外的一部分样本作为Q̂。显然,每个训练episode都是在模仿N-way K-shot的目标小样本任务。训练模型时的目标定义为:

其中,θ 是模型的参数,Pθ( y|x,Ŝ )表示样本x 属于类别y 的概率。通过大量episodes的学习之后,模型会具有很好的泛化性。
2.2 权重分解
在小样本学习中,很多方法借助微调预训练模型来达到快速学习的目的。然而,相对于需要微调的参数量,可用的数据量仍然过少,故微调的效果往往会受到限制,为了解决这一问题,提出权重分解策略。具体而言,将网络中部分卷积层的权重分解为泛化权重与敏感权重。在预训练过程中,网络忽略敏感权重,仅学习泛化权重的参数,在经过大量任务的迭代后,泛化权重具备了很强的泛化能力。在元训练过程中,网络冻结泛化权重,仅学习敏感权重的参数,通过敏感权重与泛化权重的共同作用,来拟合特定任务。
将分类器的卷积层权重分解为泛化权重φ 与敏感权重W 两部分。在预训练阶段,为了与其他小样本学习方法公平比较,该模型仅在小样本学习的训练集上预训练。例如,在miniImageNet[14]数据集上,训练集Dbase中总共包含64 个类别,每个类别600 个样本,模型在预训练时训练一个64类别的分类网络。首先随机初始化特征提取器参数θ 以及分类器参数φ,然后通过梯度下降法对他们进行优化:

其中α 表示学习率,l 为交叉熵损失。在这个阶段学习特征提取器参数θ 以及分类器参数φ,同时在验证集上验证网络的泛化能力。预训练结束后,将θ 与φ 固定下来,作为泛化权重。在元训练过程中,特征提取器参数保持不变,分类器参数由泛化权重φ 与敏感权重W 共同组成。
在元训练阶段,分类器冻结泛化权重,之后我们用带标签的支持集S 对敏感权重W 进行微调,通过梯度下降法对W 进行优化:

其中,β为学习率,l为交叉熵损失。通过对W 进行微调,使得W具有任务相关性。权重更新的示意图如图2所示。



2.3 记忆模块
在N-way K-shot 的设置下,给定一个支持集S,对于一个样本xn,k ,特征提取器输出其对应的特征图en,k ∈RD。将任务中所有样本的特征图组成的特征图e ∈RN×K×D 作为下采样模块的输入,以此来对e 进行任务级别的下采样:



2.4 训练过程
模型在预训练阶段,在Dbase 训练集上进行传统的分类任务,由公式(2)进行优化,保留在验证集上效果最优的模型,将其权重固定下来作为泛化权重。在元训练阶段,根据episodes训练策略,每个episode在Dbase 随机采样出N-way K-shot的批次,送入网络进行训练。在通过特征提取器后,根据公式(4)获得任务级别的特征,再根据公式(5)、公式(6)在记忆中查找最相关任务的索引,根据索引提取出相关任务对应的敏感权重信息,经过reshape 后,用其来初始化分类网络的敏感权重。之后根据公式(3),对分类网络进行微调。最后将任务级别的特征作为任务信息,微调后的敏感权重reshape后作为敏感权重信息,组成键值对存入记忆,完成一个episode的学习。
在上述的训练过程中,每个训练批次的设置都是完全匹配N-way K-shot的元测试形式,旨在模仿小样本的测试情景。然而,这种匹配机制意味着训练出来的模型只适合N-way K-shot 的情景,很难泛化到N-way K′-shot 的情况。因此为了增强网络在K′-shot 上的泛化性,提出混合训练策略,即在元训练阶段,每个训练批次由不同的shots 数组成,学习一个统一的结构以此来适应推理阶段不同shots 的任务。由于在记忆模块中,经过任务级别的下采样后,N-way K-shot的样本组成的特征表示e ∈RN×K×D 被压缩为RN×C 的统一形式,故记忆能接受任意shots数的任务。因此在执行混合训练策略时,网络仍然是一个统一的模型,与输入批次中的shots数无关。
3 实验
3.1 数据集
miniImageNet数据集被广泛用于小样本学习中,它是ImageNet[26]数据集的子集。它包含100 个不同的类别,每个类别有600 张图片。按照前人的工作[19]中广泛使用的设置,同样从数据集中划分出64个类别作为训练集,16个类别作为验证集,剩下的20个类别作为测试集。
tieredImageNet[27]数据集同样是ImageNet 数据集的子集,与miniImageNet 不同的是,它是一个更新更大的数据集。在数据量上,它包含608 个类别,且平均每个类别有1 281个样本;在语义结构上,它将数据集划分成34个父级类别来确保类别之间的语义差距。在小样本学习中,将高层的34 个父类划分出20 个父类作为训练集(对应351 个最终类别),6个父类作为验证集(对应97 个最终类别)以及8个父类作为测试集(对应160 个最终类别)。这种基于语义层次结构的划分方式,使得不同集合中的数据在语义上更加不相关,更加能够考验模型的泛化性能。
CUB[28]数据集是关于鸟的细粒度分类数据集。它包含200个鸟的类别对应于鸟的物种,共包含11 788张图片。根据先前的设置[29],选择100个类别作为训练集,50 个类别作为验证集,50 个类别作为测试集。对于CUB 数据集中的所有图片,根据提供的目标框裁剪出目标区域作为预处理操作[27]。
最后,所有数据集的图片都统一为84×84像素的尺寸再输入到网络中。
3.2 实验设置
为了对比的公平性,采用通用的四层卷积网络作为特征提取器,它包括4 个卷积块,每个卷积块由64 通道的3×3 卷积,批归一化[30],LeakyReLU 非线性激活函数以及2×2的最大池化组成。在分类器部分,采用相似的卷积块与一个全连接分类层组成,分类器部分的卷积层采用更多通道的卷积核来获得更多的通道级别的信息。
采用Adam算法[31]训练网络。在预训练阶段初始学习率设为0.1,并且每10 个epoch 学习率下降为之前的0.1倍。在元训练过程中,对泛化权重进行固定,仅学习敏感权重,此时学习率设为0.001,每个任务迭代100 次来进行迁移学习。在元测试过程中,测试600 个epoch来计算模型的准确率,在每个epoch 中,每个类别选取15个样本组成查询集。
3.3 实验结果
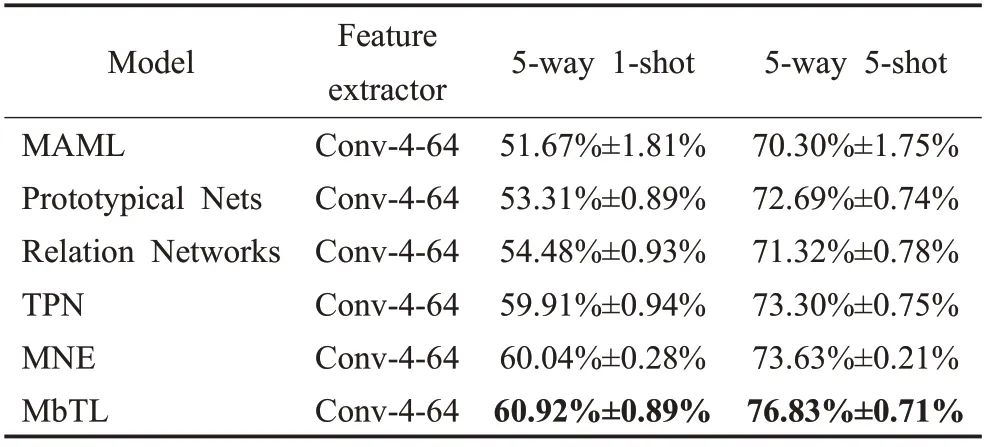
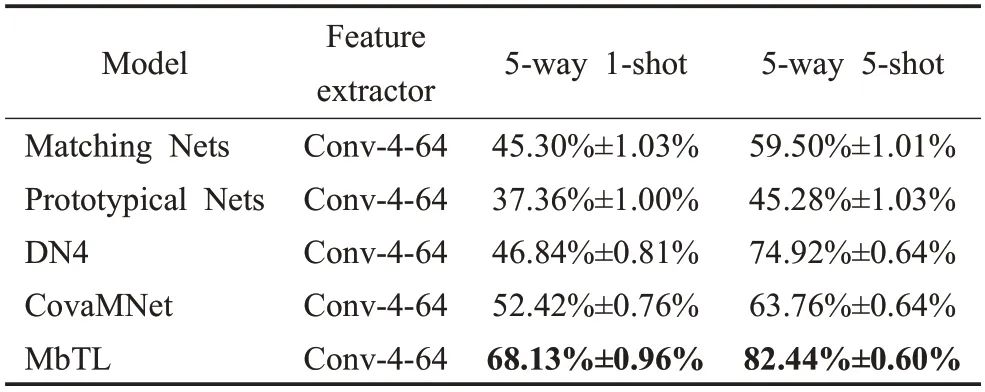
在miniImageNet、tieredImageNet 以及CUB 数据集上进行对比实验。为了验证MbTL方法的有效性,将其与一些小样本学习方法进行对比,包括Matching Nets[14]、MAML[10]、Meta-learner LSTM[19]、Prototypical Nets[15]、Relation Networks[16]、TPN[21]、DN4[17]、CovaMNet[18]、MNE[23]、FEAT[22]。Table1、Table2 以及Table3 是分类结果,这里模型的特征提取器都采用传统的4层卷积块,输出的特征图的通道数有64 和32,分别使用Conv-4-64 和Conv-4-32标出,最优的效果加粗标出。可以发现我们的方法明显优于大多数的小样本学习方法,并且在tieredImageNet和CUB数据集上,在5-way 1-shot和5 way 5-shot设定下都取得了最好的分类效果。
表1 展示了在miniImageNet 数据集上的实验结果。对比于TPN,本文方法在5-way 1-shot的设置下提升了接近0.8 个百分点,而在5-way 5-shot 的设置下提升了接近2.7 个百分点。对比于MNE 和FEAT,在5-way 1-shot 的设置下,同样memory-based 的MNE 取得了最优的效果,在5-way 5-shot 的设置下,本文方法略微领先。表2 展示了在CUB 数据集上的实验结果。在5-way 1-shot 的设置下,对比于CovaMNet,本文方法有着接近16 个百分点的显著提升。在5-way 5-shot 的设置下,对比于DN4,本文方法仍然有着大约7.5个百分点的显著提升。这些结果表明了本文方法对细粒度分类也同样有效。表3 展示了在tieredImageNet 数据集上的实验结果。对比于TPN 和MNE,在5-way 1-shot 的设置下,本文方法有着大约1 个百分点的提升,5-way 5-shot的设置下,本文方法有着3个百分点的明显提升。

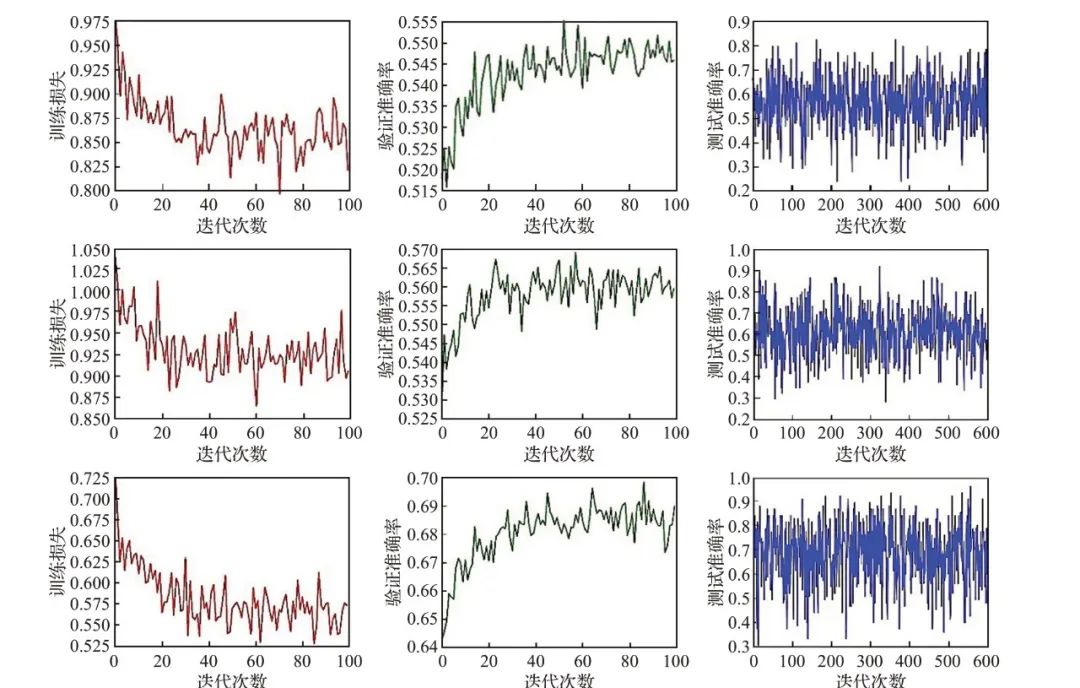
如图3 展示了在5-way 1-shot 的设置下,模型在miniImageNet、tieredImageNet、CUB 数据集上的训练损失,验证准确率以及测试准确率。可以看出随着epoch的迭代,训练损失总体上逐渐下降,验证准确率对应逐渐上升。由于经过了预训练,模型处于一个较优的状态,训练损失与验证准确率的变化范围不大。选择在验证准确率最大时对应的模型来进行效果测试,并给出在测试集上的测试效果。
3.4 消融实验
为了验证本文方法的有效性,并对权重分解、记忆模块的效果进行进一步评估,在miniImageNet、tieredImageNet以及CUB上开展了一系列消融实验。消融实验的结果如表4所示。

3.4.1 权重分解的效果
为了验证权重分解策略的效果,暂时屏蔽记忆模块来消除其对结果影响。如表4所示,“MAML”的微调方式是对基础学习器(分类器)中的所有权重参数进行微调,而“MAML+权重分解”则是先将基础学习器(分类器)中权重分解为泛化权重与敏感权重,通过冻结泛化权重,仅微调敏感权重的方式来学习新任务。“MAML+权重分解”相对于“MAML”,在miniImageNet数据集上,权重分解策略在1-shot与5-shot上分别提升了2.78个百分点与4.14个百分点;在tieredImageNet 数据集上,权重分解策略在1-shot与5-shot上分别提升了2.99个百分点与1.07个百分点。由此可以得出,权重分解策略对于基础学习器(分类器)的微调是有效的。
3.4.2 记忆模块的效果
在网络的学习过程中,记忆模块存储任务信息与敏感权重信息,在后续任务中,通过读取记忆模块中的这些先验知识来帮助网络快速地进行迁移学习。如表4所示,“MAML+权重分解+记忆模块”是本文方法,相对于“MAML+权重分解”,1-shot与5-shot在miniImageNet数据集上分别提升4.82 个百分点与5.30 个百分点,在tieredImageNet 数据集上分别提升6.26 个百分点与5.46个百分点,在CUB 数据集上分别提升3.93 个百分点与6.41个百分点。由此可见,记忆模块通过给分类器提供一个更好的初始化状态对模型的微调有积极作用。
4 结论
在本文中,提出了一个基于记忆模块的元学习方法致力于解决小样本学习问题。相对于传统的元学习方法做了两处改进。首先,针对于基础学习器在微调过程中出现的待微调参数过多,提出了一种权重分解策略,来将基础学习器的权重分解为冻结权重与可学习权重,冻结权重用来保证模型的泛化能力,可学习权重用来学习新任务,这样的策略在小样本学习中更为有效。其次,针对于基础学习器的初始化状态不佳,借助了一个记忆模块来保存先前的任务与权重信息,根据当前任务读取记忆中的先验知识来更有效地初始化基础学习器,以此帮助基础学习器快速学习新任务。在miniImageNet、tieredImageNet以及CUB 数据集上与其他方法进行效果对比,从实验结果上看,对比于较先进的方法,本文方法在小样本分类以及细粒度分类任务上取得了具有竞争力的表现。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。