一、算法分类
在介绍机器学习算法之前,先来明确两个概念:离散型数据和连续性数据
离散型数据:
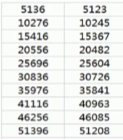
上图是一组离散型数据,它是由记录不同类别个体的数目所得到的数据,又称计数数据,例如人口数、班级数量、特定范围内的汽车数量……所有这些数据全部都是整数,而且不能再细分,也不能进一步提高他们的精确度.
连续性数据:
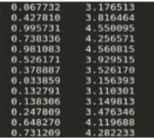
变量可以在某个范围内取任一数,即变量的取值可以是连续的,如,长度、时间、质量值等,这类整数通常是非整数,含有小数部分。
明确了上述概念,我们来看机器算法的分类:
大致可以分为两种:监督学习和无监督学习
他们的区别就在于,监督学习的数据含有特征值和目标值,无监督学习只有特征值
监督学习的算法包括
分类:k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
回归:线性回归、岭回归……
其中,分类对应的目标值数据为离散型数据,回归对应的数据为连续性数据,例如在分类中,我们预测一个图片是什么动物,在之前所说的特征处理中,我们可以将这些动物类别处理为1,2,3…
回归对应的目标值数据为连续性数据
无监督学习包括:
聚类k-means等
监督学习输入数据有特征有标签,即有标准答案
无监督学习输入数据有特征无标签,无标准答案
分类是监督学习的一个核心问题,在监督学习中,当输出变量取有限个离散值时,预测问题变成为分类问题。最基础的便是二分类问题,即判断是非,从两个类别中选择一个作为预测结果;
分类在于根据其特性将数据“分门别类”,所以在许多领域都有广泛的应用
·在银行业务中,构建一个客户分类模型,按客户按照贷款风险的大小进行分类
·图像处理中,分类可以用来检测图像中是否有人脸出现,动物类别等
·手写识别中,分类可以用于识别手写的数字
·文本分类,这里的文本可以是新闻报道、网页、电子邮件、学术论文
回归是监督学习的另一个重要问题。回归用于预测输入变量和输出变量之间的关系,输出是连续型的值。回归在多领域也有广泛的应用房价预测,根据某地历史房价数据,进行一个预测金融信息、每日股票走向等
来看几个例子,看看他们是分类问题还是回归问题
1、预测明天的气温是多少度?(回归)
2、预测明天是阴、晴还是雨?(分类)
二、开发流程
1.获取数据,明确要用数据干什么
2.数据基本处理:pd处理数据(缺失值、合并表……)
3.特征工程
4.找到合适算法进行预测/分析
那么模型是什么呢?不必深究,理解成
模型 = 算法 + 数据
5.模型评估
判定模型效果的好坏