groupping函数是postgresql中一个分组聚合的函数,通过该函数可以一次查询中将多个不同级别或者多维度的报表,下面就来看看如何使用该函数。
1.构建测试数据
为方便便进行数据展示,在这里构建测试数据(fruit_sale表)用于演示,构建代码如下:
DROP TABLE IF EXISTS "fruit_sale";
CREATE TABLE "fruit_sale" (
"statistical_date" date,
"product" varchar(255) COLLATE "pg_catalog"."default",
"year" varchar(5) COLLATE "pg_catalog"."default",
"qty" numeric(8),
"amount" numeric(8),
"region" varchar(50) COLLATE "pg_catalog"."default"
)
;
INSERT INTO "fruit_sale" VALUES ('2018-01-01', '西瓜', '2018', 1721, 253541, '华南');
INSERT INTO "fruit_sale" VALUES ('2019-03-01', '西瓜', '2019', 3437, 104221, '华南');
INSERT INTO "fruit_sale" VALUES ('2019-05-01', '西瓜', '2019', 8963, 122630, '华南');
INSERT INTO "fruit_sale" VALUES ('2019-06-01', '苹果', '2019', 1274, 150122, '华南');
INSERT INTO "fruit_sale" VALUES ('2019-05-01', '苹果', '2019', 6319, 282352, '华南');
INSERT INTO "fruit_sale" VALUES ('2018-11-01', '苹果', '2018', 8614, 170263, '华南');
INSERT INTO "fruit_sale" VALUES ('2018-02-01', '西瓜', '2018', 5530, 129644, '华南');
INSERT INTO "fruit_sale" VALUES ('2018-07-01', '西瓜', '2018', 4711, 129644, '华南');
INSERT INTO "fruit_sale" VALUES ('2018-08-01', '西瓜', '2018', 9187, 220605, '华南');
INSERT INTO "fruit_sale" VALUES ('2018-05-01', '西瓜', '2018', 5678, 129644, '华南');
INSERT INTO "fruit_sale" VALUES ('2018-09-01', '西瓜', '2018', 4029, 119187, '华南');
INSERT INTO "fruit_sale" VALUES ('2018-10-01', '西瓜', '2018', 3129, 137928, '华南');
INSERT INTO "fruit_sale" VALUES ('2018-03-01', '西瓜', '2018', 4496, 203471, '华中');
INSERT INTO "fruit_sale" VALUES ('2018-04-01', '西瓜', '2018', 7359, 206686, '华中');
INSERT INTO "fruit_sale" VALUES ('2018-12-01', '西瓜', '2018', 8646, 267718, '华中');
INSERT INTO "fruit_sale" VALUES ('2018-01-01', '苹果', '2018', 5559, 269419, '华中');
INSERT INTO "fruit_sale" VALUES ('2018-04-01', '苹果', '2018', 5590, 182167, '华中');
INSERT INTO "fruit_sale" VALUES ('2018-07-01', '苹果', '2018', 3852, 130764, '华中');
INSERT INTO "fruit_sale" VALUES ('2018-06-01', '西瓜', '2018', 7434, 206686, '华中');
INSERT INTO "fruit_sale" VALUES ('2019-01-01', '苹果', '2019', 5558, 156995, '华中');
INSERT INTO "fruit_sale" VALUES ('2018-08-01', '苹果', '2018', 8625, 235426, '华中');
INSERT INTO "fruit_sale" VALUES ('2018-11-01', '西瓜', '2018', 2633, 175737, '华东');
INSERT INTO "fruit_sale" VALUES ('2019-01-01', '西瓜', '2019', 1223, 113053, '华东');
INSERT INTO "fruit_sale" VALUES ('2019-02-01', '西瓜', '2019', 9079, 200716, '华东');
INSERT INTO "fruit_sale" VALUES ('2019-06-01', '西瓜', '2019', 1991, 167150, '华东');
INSERT INTO "fruit_sale" VALUES ('2018-02-01', '苹果', '2018', 5832, 142631, '华东');
INSERT INTO "fruit_sale" VALUES ('2018-05-01', '苹果', '2018', 1392, 249027, '华东');
INSERT INTO "fruit_sale" VALUES ('2018-06-01', '苹果', '2018', 9694, 179832, '华东');
INSERT INTO "fruit_sale" VALUES ('2018-09-01', '苹果', '2018', 7249, 286565, '华东');
INSERT INTO "fruit_sale" VALUES ('2019-04-01', '西瓜', '2019', 6524, 206686, '华东');
INSERT INTO "fruit_sale" VALUES ('2019-03-01', '苹果', '2019', 6545, 238608, '华东');
INSERT INTO "fruit_sale" VALUES ('2018-12-01', '苹果', '2018', 2140, 139439, '华东');
INSERT INTO "fruit_sale" VALUES ('2018-10-01', '苹果', '2018', 3490, 125275, '华东');
INSERT INTO "fruit_sale" VALUES ('2019-04-01', '苹果', '2019', 9992, 157696, '华中');
INSERT INTO "fruit_sale" VALUES ('2018-03-01', '苹果', '2018', 5276, 120441, '华东');
INSERT INTO "fruit_sale" VALUES ('2019-02-01', '苹果', '2019', 2246, 216573, '华东');
部分数据截图如下:
2.进行数据聚合
2.1 正常的聚合
-- 普通聚合
SELECT
product,
YEAR,
SUM ( qty ) qty
FROM
fruit_sale
GROUP BY
product,
YEAR;
运行效果如下:
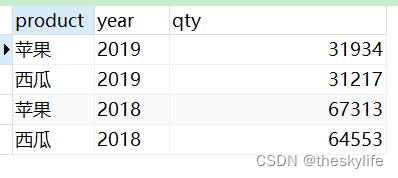
2.2 groupping sets
2.2.1 多维度
按照多个维度进行聚合,聚合代码如下:
--grouping set 多维度
SELECT
product,
YEAR,
SUM ( qty ) qty
FROM
fruit_sale
GROUP BY
GROUPING SETS ( product, YEAR );
实现结果见下图:
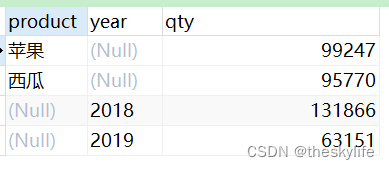
2.2.2 多维度、汇总
通过改变set后的参数,可以来控制聚合的维度和级别,通过以下代码来进行多维度和合计:
-- grouping set 多维度+汇总
SELECT
product,
YEAR,
SUM ( qty ) qty
FROM
fruit_sale
GROUP BY
GROUPING SETS ( product, YEAR, ( ) );
代码执行效果见下图:
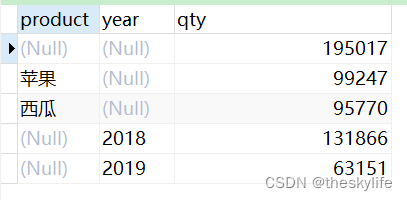
2.2.3 多维度、不同级别
通过改变set后的参数,可以来控制聚合的维度和级别,通过以下代码来进行多维度和不同级别的聚合:
-- grouping set 多维度+不同级别
SELECT
product,
YEAR,
SUM ( qty ) qty
FROM
fruit_sale
GROUP BY
GROUPING SETS ( product, YEAR, ( product, YEAR ) );
代码执行效果见下图:
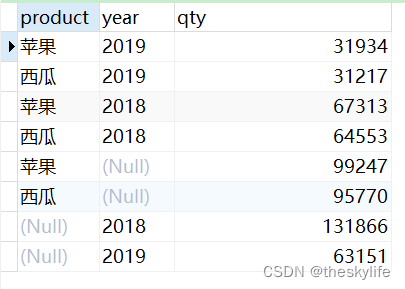
2.3 cube
在使用cube时,会按照指定的字段上生成所有的分组集,如果指定字段的数量是n,就会有2的n次方个组合(分组)。
2.3.1 部分cube
代码如下:
-- 部分cube
SELECT GROUPING
( product ) category_id,
product,
YEAR,
SUM ( qty ) qty
FROM
fruit_sale
GROUP BY
YEAR,
CUBE ( product );
代码运行结果,如下:
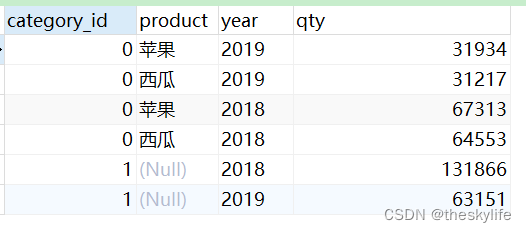
2.3.2 整体cube
对产品和年进行聚合,可以观察到类别共有2的2次方(4)个,代码如下:
-- 整体cube
SELECT GROUPING
( product, year ) category_id,
product,
YEAR,
SUM ( qty ) qty
FROM
fruit_sale
GROUP BY
CUBE ( product, year )
ORDER BY
GROUPING ( product, year );
运行结果,部分截图如下图:
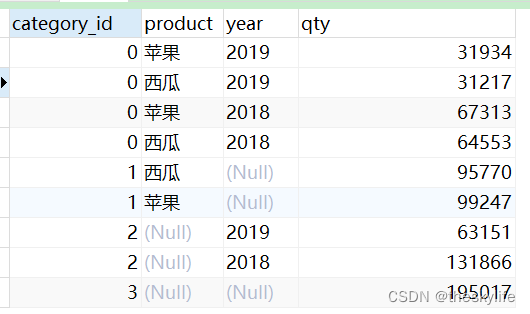
对产品、年和区域进行聚合,可以观察到类别共有2的3次方(8)个,代码如下:
--3字段cube
SELECT GROUPING
( product, year,region ) category_id,
product,
YEAR,
region,
SUM ( qty ) qty
FROM
fruit_sale
GROUP BY
CUBE ( product, year,region )
ORDER BY
GROUPING ( product, year,region );
代码执行后,部分结果如下图:
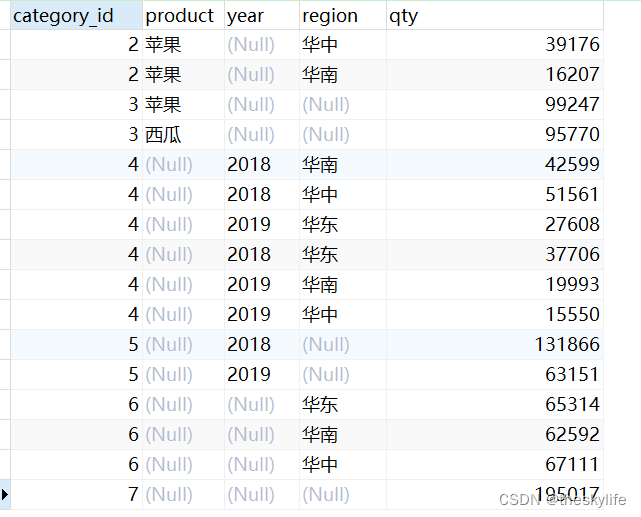
2.4.rollup
使用rollup时,会根据指定的组合字段,按照顺序生成具有层次结构的分组数据。如指定A,B,C字段,会分别生成A、A-B、A-B-C层次的分组数据。
2.4.1 部分rollup
可以进行部分rollup,以下为对应的代码
--部分rollup
SELECT GROUPING
( product, YEAR ) category_id,
region,
product,
YEAR,
SUM ( qty ) qty
FROM
fruit_sale
GROUP BY
region,
ROLLUP ( product, YEAR );
运行效果如下图:
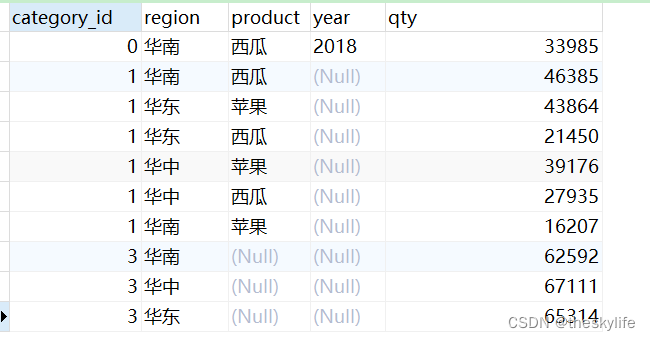
2.4.2 整体rollup
在进行rollup时,依据字段顺序的不同,可以生成不同的结果。
先按照(region, product, YEAR)字段进行整体的rollup,以下为对应的代码:
SELECT GROUPING
( region, product, YEAR ) category_id,
region,
product,
YEAR,
SUM ( qty ) qty
FROM
fruit_sale
GROUP BY
ROLLUP ( region, product, YEAR )
ORDER BY
GROUPING ( region, product, YEAR );
以上代码运行后,部分结果截图如下,红框中数据是与2.4.1中代码的不同:
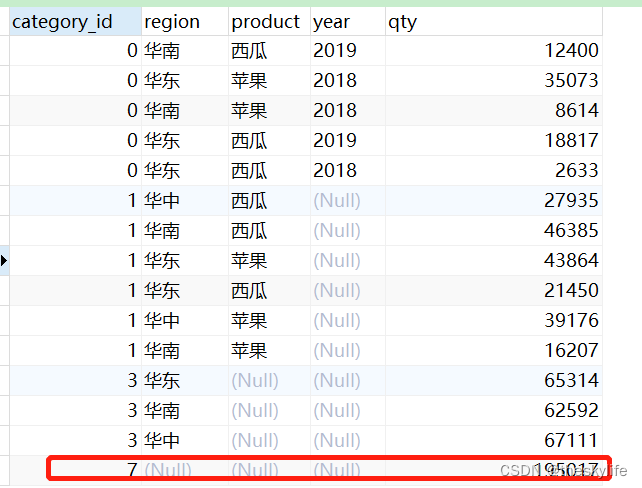
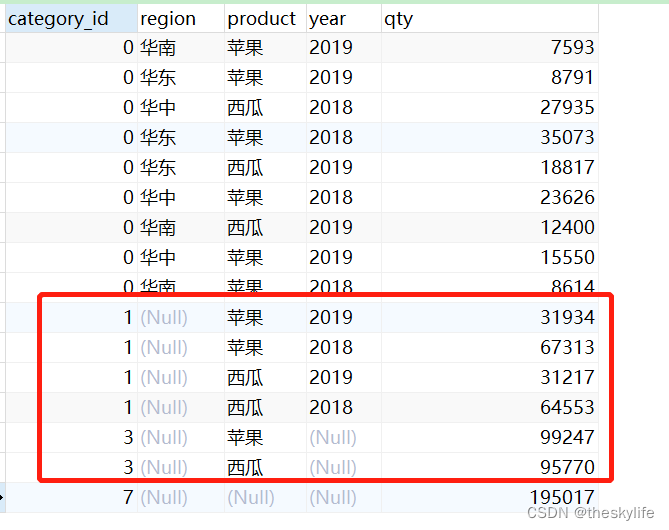
再按照( product, YEAR, region )字段进行整体的rollup,以下为对应的代码:
--(product, YEAR, region)组合进行rollup
SELECT GROUPING
( product, YEAR, region ) category_id,
region,
product,
YEAR,
SUM ( qty ) qty
FROM
fruit_sale
GROUP BY
ROLLUP ( product, YEAR, region )
ORDER BY
GROUPING ( product, YEAR, region );
依据上述代码,生成的结果部分截图如下,红框中的数据是rollup( product, YEAR, region )与rollup(region, product, YEAR)的区别: