在做报表这种,我们经常会遇到各种各样的需求,按周统计就是一种。刚啊看到这个需求可能会一脸懵逼,不知如何下手。甚至有的人会利用最原始的方法,将客户所选日期拆分成N周,每一周都获取一下周一和周天时间,然后每周查询一次。这样的haul执行效率非常的低下,那有没有更好的方法实现啦,肯定是有的,这个时候我们就要了解一下数据库自带的函数。
SELECT EXTRACT(DOW FROM CURRENT_DATE); 执行结果如下。
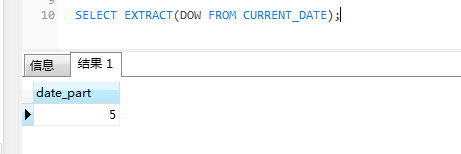
这个SQL语句的意思就是计算当前日期是一周中的第几天。
EXTRACT(DOW FROM CURRENT_DATE) 函数的返回值,0表示星期天,6表示星期六。
因为外国人的习惯是一周从周日开始,二我们中国人的习惯一周的开始是星期一。
下面我们就来讲一下按周统计的思路,如果我们能够将表中的时间字段,都改造成对应时间的周一时间。那我们就可以实现。
示例。那我们只需要按这个日期分组统计就可以实现按周统计。
例如今天2019-01-11,是星期五,我么把他变成对应这周星期一的时间2018-01-07
同样2019-01-10,星期四,改成对应的周一时间2018-01-07。依次将所有日期改造,就可以实现按周统计
那么如何将日期字段,改造成对应周一时间就是一个问题。
以上我们通过 EXTRACT(DOW FROM CURRENT_DATE)可以知道当前时间对应在一周找那个的天数。如果我们能够用对应时间往前推他在一周的天数。例如今天2019-01-11号星期五,如果我们把时间往前推4天,我就可以得到对应这天周一的天数,首先我们需要改造一下EXTRACT(DOW FROM CURRENT_DATE)函数,以适应我们国人周一为一周的开始。
SELECT (EXTRACT(DOW FROM CURRENT_DATE)-1) diffday; 明显周一与周五之间相差4天。我们用当前日期往前推4天便得到星期一的日期
SELECT CURRENT_DATE-(EXTRACT(DOW FROM CURRENT_DATE)-1||'day')::interval diffday;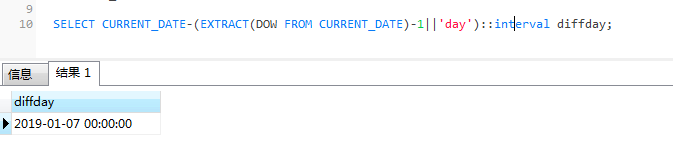
2019-01-07便是星期一的日器。下面我们一表为基础实现

一共6条数据,我们统计每周的数量
select
row_time::DATE-(extract(dow from row_time::TIMESTAMP)-1||'day')::interval monday,
count(*) amount
from acd_details
where 1=1
GROUP BY row_time::DATE-(extract(dow from row_time::TIMESTAMP)-1||'day')::interval下面看一下上面语句的执行效果
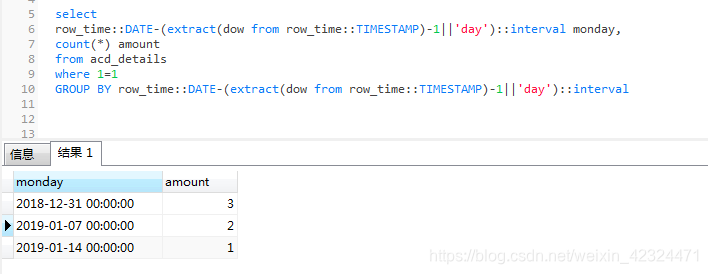
显示的日期为每周周一的时间,总共六条数据,第一周(2018-12-31-2019-01-06) 3条
第二周(2019-01-07-2019-01-13) 2条,第三周(2019-01-14-2019-01-20) 1条。,至此大功告成。