1、MVCC介绍
1.1、事务隔离级别
MVCC,Multi-version Concurrency Control ,顾名思义指的是多版本并发控制。在介绍MVCC之前我们先来简单了解下事务的隔离级别:
- read uncommitted:脏读,一个事务可以读到另外一个事务未提交的数据,大多数关系型数据库不支持。
- read committed:提交读,一个事务可以读到其他事务已经提交的数据,大多数数据库的缺省模式。
- repeatable read:一个事务执行过程中访问的数据是一致的,也就是一个事务中多次读到的数据不会变化。
- serializable:序列化,事务串行化执行,避免不一致。代价很大,OLTP系统中很少使用。
在大多数关系型数据库中默认的事务隔离级别都是read committed(mysql中默认是repeatable read)。我们也可以根据业务场景的需要去选择合适的隔离级别,例如在一个事务中,使用select for update来避免读到不一致的数据,如果不是为了排他性的锁定,用RR事务隔离级别来代替可以获得更好的性能。
关于事务隔离级别更多详细介绍见:一文彻底读懂PostgreSQL事务隔离级别
1.2、并发控制介绍
常见的并发控制有:
- MVCC:Multi-version Concurrency Control (多版本并发控制)。
- S2PL: Strict Two-Phase Locking(严格二阶段锁):读写互斥,保证串行。
- OCC:Optimistic Concurrency
Control(乐观并发控制):和悲观锁不同,乐观锁在提交前不加锁,提交时如果读取时的数据被其他事务修改并提交,则回退事务。
简单来说,在MVCC机制还没有出现之前,数据库中读写是互斥的,而通过MVCC机制使得读写不互斥。因此MVCC使关系型数据库并发读写能力得到很大的提高,而大多数OLTP系统中的85%以上是读操作。
2、oracle的MVCC实现方式
Oracle的多版本并发控制是基于块级的,利用Oracle UNDO/回滚段机制。在回滚段中保存了某个数据被修改之前的前映像的数据。
当我们在数据中查询之前版本的数据时,oracle是这样做的:首先查询的过程会在undo段中查找该数据块的前映像后,然后把前映像和current块合并形成了一个CR block,通过查询cr block就可以满足数据的一致性了。

正因为数据的前映像通过在DB BUFFER中的CR BLOCK来实现,所以数据无论修改多少次,都不会对存储数据的数据段产生负面的影响。而且一个CR BLOCK生成后,可以在缓冲区中较长时间内存在,供相关的事务使用。这个功能对于大并发的读操作来说,是十分有用的,可以大大提高相关操作的性能。
3、mysql的MVCC实现方式
mysql innodb引擎的MVCC也是通过undo段来实现的,但是和oracle不同的是:mysql的多版本并发控制是基于记录级的,mysql中通过undo来形成行的版本链。
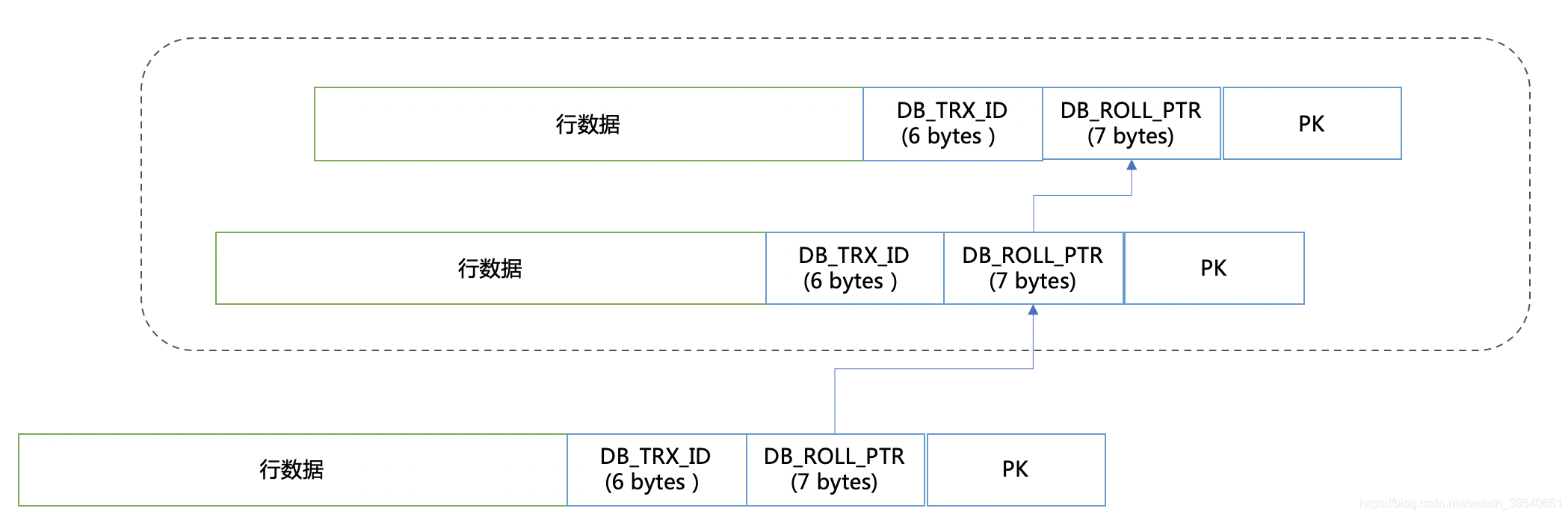
上图中的回滚指针(DB_ROLL_PTR)字段用来指写入回滚段(rollback segment)的 undo log record (撤销日志记录记录)。
而其具体做法就是通过两个隐含列来实现的:一个是db_trx_id,指出该行的事务ID,一个是db_roll_ptr,指出这条记录的pre-image数据在UNDO中的地址。
4、PostgreSQL的MVCC实现方式
最后我们再来看看PostgreSQL的MVCC机制,和oracle还有mysql中不同的是,pg中没有undo这一概念,pg中的多版本并发是通过在表中数据行的多个版本来实现的,例如在一张表中我们要更新一条记录,pg并不是直接修改该数据,而是通过插入一条全新的数据,同时对老数据加以标识。
在pg中一个page页结构大致如下图所示:
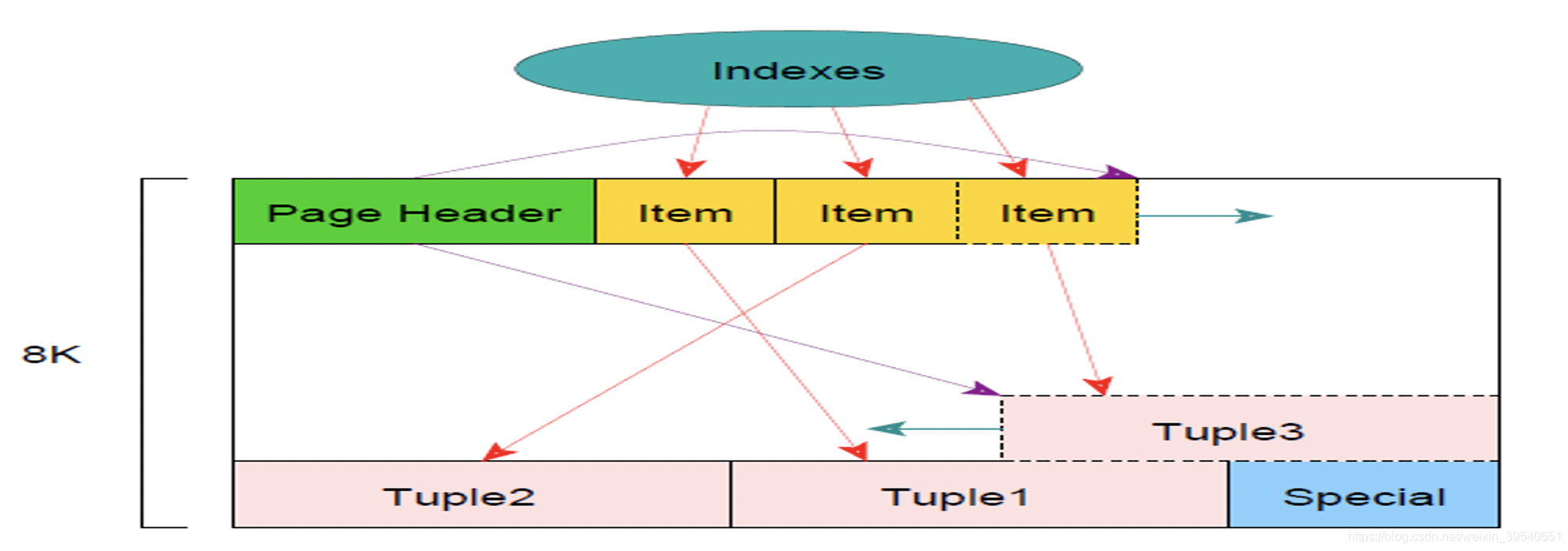
对应的数据结构为PageHeaderData:

而实现多版本是通过HeapTupleFields:

要想理解pg的多版本机制,首先要弄清楚几个关键的字段:
- t_xmin:插入该元组的事务的txid;
- t_xmax:删除或更新该元组的事务的txid,如果尚未删除或更新该元组,则t_xmax设置为0;
- t_cid:命令ID(cid),这表示从0开始在当前事务中执行此命令之前已执行了多少个SQL命令;
- t_ctid:指向自身或新元组的元组标识符(tid),当该元组被更新时,该元组的t_ctid指向新的元组,否则,t_ctid指向自身。
关于这些字段的详细介绍见:PostgreSQL表的系统字段。
我们可以通过一个简单的例子来看看:
bill=# select xmin,xmax,ctid,* from t;
xmin | xmax | ctid | id | info
------+------+-------+----+------
824 | 0 | (0,1) | 1 | a
(1 row)
更新该表中的数据:
可以看到新记录的xmin被置为823,ctid指向新的记录。
bill=# update t set info = 'b' where id=1;
UPDATE 1
bill=# select xmin,xmax,ctid,* from t;
xmin | xmax | ctid | id | info
------+------+-------+----+------
825 | 0 | (0,2) | 1 | b
(1 row)
5、总结

oracle和mysql都是通过undo来实现多版本并发控制,而oracle和mysql还有pg不同的是它的多版本并发控制是基于块级的,而mysql和pg是记录级别的,个人认为这也是为什么mysql中和pg中很难实现oracle中rac的原因——页级别的多版本记录在不同节点之间同步的效率必然比块级别差很多。
同时pg的多版本机制导致pg并不适合频繁update的场景,可能会带来表和索引的高水位大幅提升的问题(PostgreSQL中的“高水位” )。不过定期进行vacuum full等操作还是能够避免大部分问题的。