1.删除txt文件中重复的值
def remove_duplicates():
f_read=open('./newFile.txt','r',encoding='utf-8') #将需要去除重复值的txt文本重命名text.txt
f_write=open('./test.txt','w',encoding='utf-8') #去除重复值之后,生成新的txt文本 后的文本.txt”
data=set()
for a in [a.strip('\n') for a in list(f_read)]:
if a not in data:
f_write.write(a+'\n')
data.add(a)
f_read.close()
f_write.close()
remove_duplicates()
print('Done')示例:
原文件如图:有相同内容,且txt文件只有一列
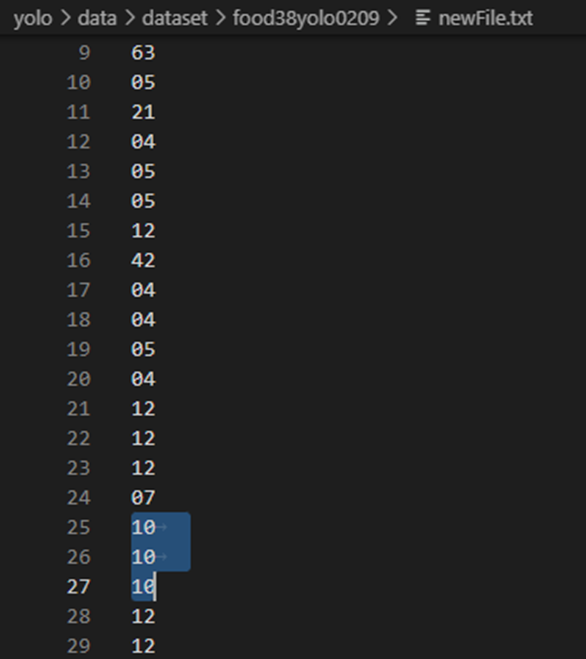
删除后,这列没有重复一样的数字

2.提取批量txt文件中的一列保存到一个新的txt文件
代码解释:展平文件夹内的所有txt文件,读取文件想要的部分并写入新文件
import glob
files = glob.glob("/workspace/yolo/data/dataset/labels0208/*.txt") #dir表示文件所在的目录,代码意思为获取该目录下所有以txt作为后缀的文件
newFile = open("newFile.txt",'w') #新建文件,默认在你运行的目录下生成
for file in files:
with open(file,'r') as FA:
for line in FA:
line = line.strip().split(" ") #默认你文件里的分割符为\t,其他的话可以替换。
newFile.write(line[0]+'\t' +'\n') #填写文件的第1列信息
#newFile.write(line[0]+'\t'+ file +'\n') #填写文件的第1列信息,和文件名称
newFile.close()示例:
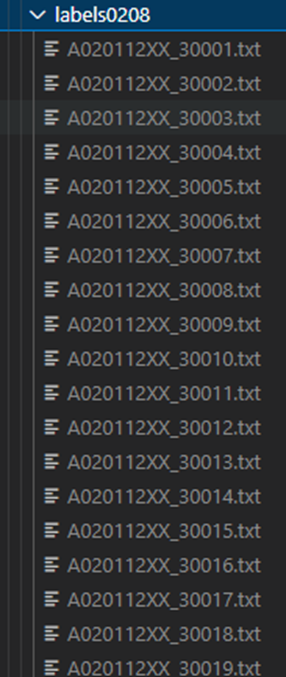
运行后的生成文件内容
