本篇博客所有示例使用Jupyter NoteBook演示。
Python数据处理系列笔记基于:Python数据科学手册电子版 下载密码:ovnh
示例代码 下载密码:02f4
目录

一、Pandas简介
Pandas是在NumPy基础上建立的新程序库,提供了DataFrame数据结构,支持相同类型数据和缺失值的多维数组,为数据科学家们处理耗时的“数据清理”任务提供了捷径,pandas的操作对处理数据库框架和电子表格数据很方便。


二、Pandas对象简介
从底层观察Pandas对象,可以把它看成增强版的Numpy结构化数组,行列不再是简单的整数索引,还可以带上标签。Pandas的三个基本数据结构:Series、DataFrame和Index。
1.Pandas的Series对象
Pandas的Series对象是一个带索引数据构成的一维数组。可以用数组创建Series对象:

Series对象将一组数据和一组索引绑定,可以分别通过values(数组类型)和index(Index类型)属性获取数据:

和数组一样可通过[]+索引的方式进行访问:

- Series是通用的NumPy数组
NumPy数组是通过隐式定义的整数索引来获取数值,Pandas的Series对象使用一种显示定义的索引与数值关联。
显示定义索引,索引不再仅仅是整数,可以是任意类型:

- Series是特殊的字典
可以把Series对象看作是一种特殊的Python字典,,字典是一种将任意键映射到一组任意值的数据结构,忘记的同学可以看我的另一篇博客复习一下 Python字典。
Series其实也是一种将类型键映射到一组类型值的数据结构。就像NumPy数组的某些操作比Python列表更高效一样,Series对象的某些操作也比Python字典更高效。

- 创建Series对象
Series对象创建的形式:
pd.Series(data,index=index)data参数支持多种数据类型,index是一个可选的参数:

每一种形式都可以通过显示指定索引筛选需要的结果;

2.Pandas的DataFrame对象
- DataFrame是通用的NumPy数组
如果说Series是一个带灵活索引的一维数组,那么DataFrame就是一种既有灵活的行索引,又有灵活列名的二维数组;可以把DataFrame对象看成是若干有序排列的Series对象,这些Series对象有相同的索引:
DataFrame对象有index和columns属性,可以分别获得索引和列名,都是Index类型:

可以把DataFrame看作一种通用的NumPy二维数组,可以通过索引和列名,获取相应的行或列。
- DataFrame是特殊的字典
字典是一个键映射一个值,而DataFrame是一列映射一个Series的数据。

- 创建DataFrame对象
通过单个Series对象创建,DataFrame是一组Series对象的集合,可用单个Series创建一个单列的DataFrame:

通过字典列表创建:

即使字典中有些键不存在,Pandas会用缺失值NaN(Not a Number)表示:

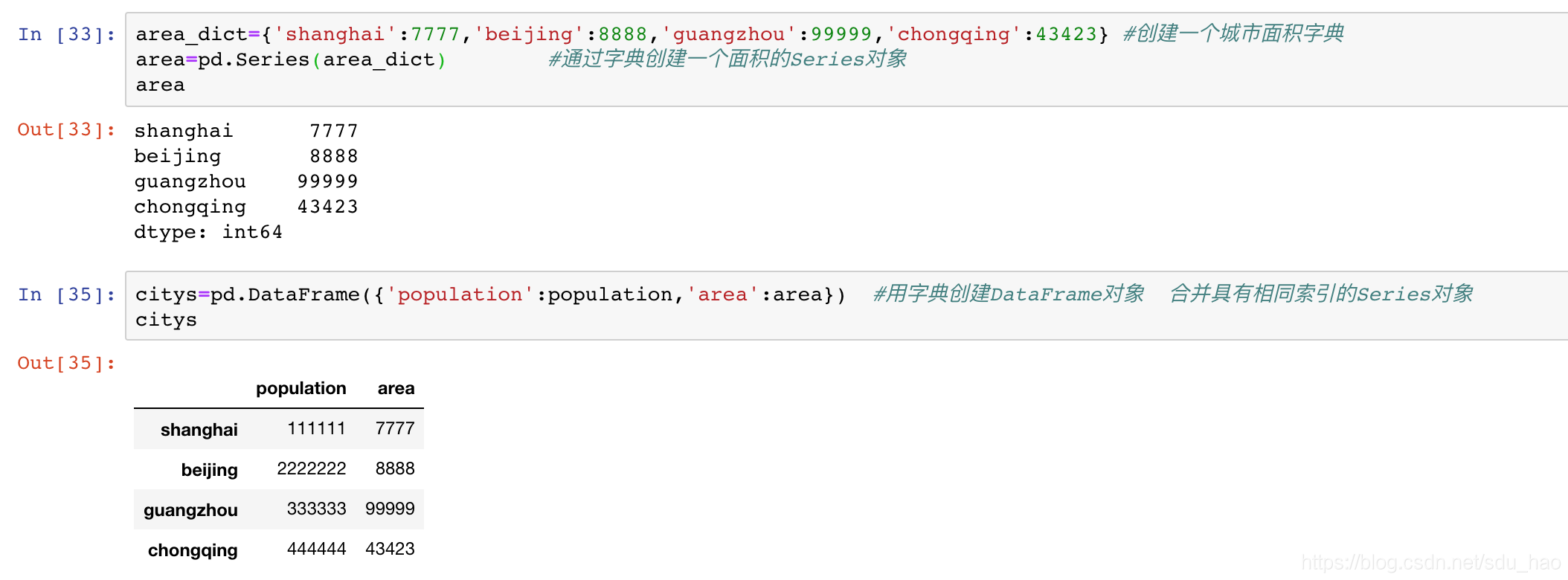
通过具有相同行索引的Series对象字典创建:

通过NumPy二维数组创建。指定行/列索引,不指定默认为整数索引:

通过NumPy结构化数组创建:

最后,也可以通过读入Excel表格或csv文件来转化成DataFrame格式。
3.Pandas的Index对象
Series和DataFrame都使用便于引用和调整的显式索引。可以把Index对象看作是一个不变的数组或有序集合(允许有重复值)。
可以用列表来创建一个Index对象:

-
将Index看作不可变数组
Index可以像数组那样通过简单索引取值或进行切片操作:

Index也有与数组类似的属性:

Index与数组的不同在于,他的索引值是不可改变的:

Index对象的不可变使得多个DataFrame和数组之间进行索引共享时更加安全,可以避免修改索引时大意而导致的副作用。
- 将Index看作有序集合(允许有重复值)
连接数据集时,会涉及许多集合操作。Index对象遵循Python集合数据结构(set)的许多习惯用法,包括并/交/差集等。

三、数据取值与选择
1.Series数据选择方法
- 将Series看作字典
Series和字典一样提供了键值对的映射:

可以用python字典的表达式和方法来检测键/索引和值:

可以像字典那样,增加新的索引来扩展Series:

- 将Series看作一维数组
Series不仅具备和字典一样的接口,还具备和NumPy数组一样的数据选择功能,包括简单索引、切片、掩码、花哨的索引等:

注意:当使用显示索引作切片时,结果包含最后一个索引;当使用隐式索引作切片时,结果不包含最后一个索引。
- 索引器:loc、iloc和ix
切片和取值的习惯用法容易造成混乱。如:你的Series是显式整数索引,data[1]这种取值操作会使用显示索引;而data[1:3]这种切片操作则会使用隐式索引。

由于整数索引容易引起混淆,Pandas提供了一些索引器属性来作为取值的方法:
第一种索引器是loc属性,表示切片和取值都是显式的:

第二种是iloc属性,切片和取值都是Python形式的隐式索引(从0开始,左闭右开):

第三种是ix属性,主要针对DataFrame对象,后面会讲。
使用loc和iloc可以让代码更容易维护,特别是处理整数索引的对象时,建议使用,可以避免切片和取值的索引原则不同而产生的bug。
2.DataFrame数据选择方法
- 将DataFrame看作字典
可以把DataFrame当作一个由若干具有相同行索引的Series对象构成的字典。用城市面积和人口数据来演示:

可以通过列名来获取数据(字典形式):

可以通过列名来获取数据(属性形式):

比较同一个对象用上述两种形式获取的列数据:

虽然属性形式很方便,但并不是通用的。如果列名不是纯字符串或列名与DataFrame的方法同名,那么就不能用属性索引:

注意:应避免对属性形式选择的列直接赋值,可以用data['pop']=2,不可以用data.pop=2.
如果要增加一列可以这样做:

- 将DataFrame看作二维数组
可以用values属性查看数值,会返回一个数组对象:

可以把许多数组操作用在DataFrame上,如行列转置:

使用单个行索引,获取一行数据:

使用单个列索引,获取一列数据:

进行数组形式的取值时,需要用到索引器:


使用ix索引器,可以实现一种混合效果:

注意:ix处理整数索引时,和之前Series中介绍的一样会引起混淆。
任何用于处理NumPy形式数据的方法都可以用于这些索引器。如:loc索引器可以结合掩码和花哨的索引:

任何一种取值方法都可以修改值:

-
其他取值方法
对单个标签取值,直接选择那一列即可:

对多个标签取值,就用切片选择行:

切片也可以使用隐式索引,选择行数:
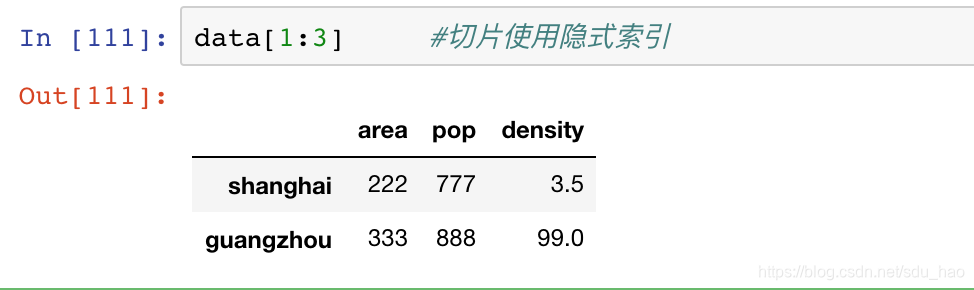
掩码操作可以直接对每一行进行过滤,而不需要使用loc索引器:
注意:掩码操作不能使用iloc索引器。

四、Pandas数值运算方法
1.保留索引
之前学过的NumPy通用函数都适用于Pandas的Series和DataFrame对象,并且运算后会保留索引:

对上述两个Pandas对象使用NumPy通用函数,生成的结果是另一个保留索引的Pandas对象:

上一篇博客介绍的NumPy通用函数都可以按照类似的方式使用。
2.索引对齐
当两个Series或DataFrame对象进行二元计算时,Pandas会自动对齐两个对象的索引。处理不完整数据时,非常方便:
- Series索引对齐

结果的索引是两个Series对象索引的并集:

任何缺失值用NaN填充,表示此处无数。索引对齐是通过Python内置的集合运算规则实现的:

如果NaN不是我们想要的结果,可以设置参数自定义缺失的数据:

- DataFrame索引对齐
两个DataFrame对象运算时,也有类似的索引对齐规则:
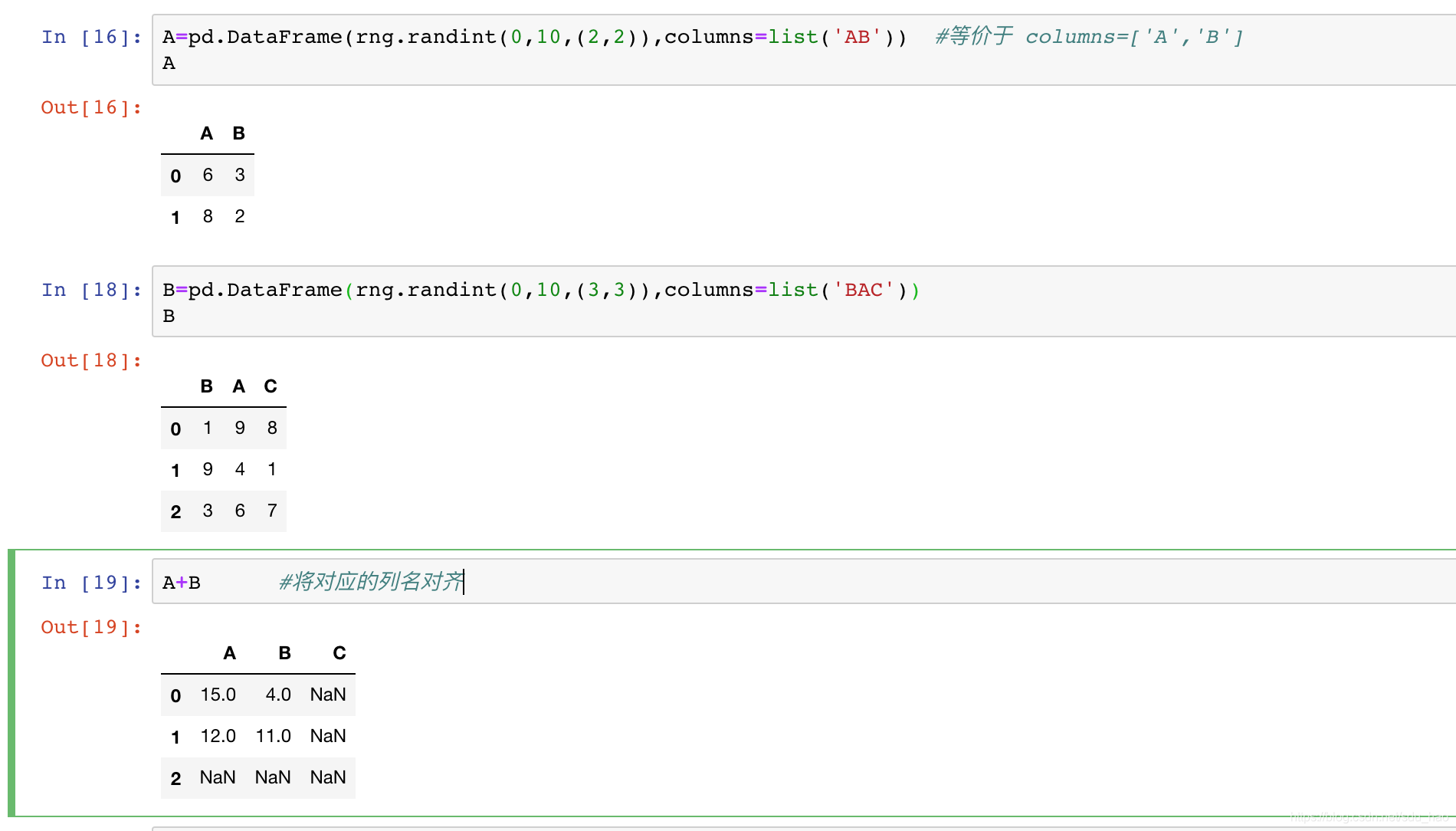
可以发现,参与运算的两个对象的索引可以是不同顺序的,结果的索引会自动排序。
也可以设置参数自定义缺失值,比如用A的均值来填充:

Python运算符和Pandas对象方法的映射关系:


3.DataFrame与Series的运算
我们可能要对一个DataFrame对象和一个Series对象进行运算,行列对齐方式与之前类似。
相当于NumPy中二维数组和一维数组进行运算,需要用到广播:

Pandas中也是利用广播规则:

DataFrame和Series的运算和之前介绍的一样,结果的索引都会自动对齐:

五、处理缺失值
1.选择处理缺失值的方法
- 通过一个覆盖全局的掩码表示缺失值
- 用一个标签值便是缺失值
2.Pandas的缺失值
- None:Python对象类型的缺失值
None是一个Python对象,不能作为任何NumPy/Pandas数组类型的缺失值,只能用于‘object’数组类型。

对象类型比其他原生类型数组要消耗更多资源:

对一个包含None的数组进行累计操作,如sum(),min()等,通常会出现类型错误:

Python没有定义整型和None之间的加法。
- NaN:数值类型的缺失值
NaN(Not a Number),是一种兼容的特殊浮点数:

无论与NaN进行何种操作,最终结果都是NaN:

此时进行聚合操作,是不会报异常的,但并非总是有效:

NumPy提供了一些特殊的聚合函数,可以忽略缺失值的影响:

NaN是一种特殊的浮点数,不是整数、字符串以及其他数据类型。
- Pandas中NaN和None的差异
pandas中2者适当时候可以替换:

Pandas会把None转换为NaN,会把整型向上转型为浮点型:

Pandas对不同类型缺失值的转换规则:

注意:Pandas中字符串类型通常是用Object类型存储的。
3.处理缺失值
- 发现缺失值
isnull()和notnull(),都返回布尔类型的掩码数据,适用于Series和DataFrame:

- 剔除缺失值dropna()

在DataFrame中使用时,需要设置一些参数:

有时你可能想提出全是缺失值的行或列,或者大部分是缺失值的行或列:

设置行或列中非缺失值的最小数量:

-
填充缺失值

DataFrame操作与Series类似,填充时需要设置坐标轴参数axis:

六、层级索引
之前接触的一维和二维数据,用Pandas的Series和DataFrame对象就可以存储。但我们经常会遇到存储多维数组的需求,数据索引超过两个键。一种比较直观的形式是使用层级索引配合多个有不同等级的一级索引一起使用,从而把高维数组转换为一维Series和二维DataFrame对象的形式。
1.多级索引Series
用一维Series对象表示二维数据:
- 笨办法
如果要分析各个城市两个年份的数据,可能会用一个元组表示索引:

通过元组构成多级索引,和之前一样可以通过简单索引或切片查询:

但这样非常不方便,如果你想要所有2000年的数据,处理起来比较复杂:

-
使用Pandas多级索引
使用元组创建一个多级索引:

levels属性表示索引的等级,可以把城市名和年份作为每个数据的不同标签。
将之前创建的Series对象population的索引重置为层级索引:

前两列表示Series的多级索引,第三列是数据。第一列数据有些缺失值,每个缺失值与上面的索引相同。
可以直接利用第二个索引,获取所有2001年的数据:

-
高维数据的多级索引
其实我们完全可以使用一个带有行列索引的DataFrame代替之前的多级索引:


我们可以利用Series或DataFrame便是三维甚至更高维的数据,如再增加一列<18岁的人口数量指标:

之前介绍的通用函数和其他功能同样适用于层级索引。
计算18岁以下的人口占总人口的比例:

2.多级索引的创建方法
为Series或DataFrame创建多级索引最直接的办法就是将index参数设置为至少二维的索引数组:

MultiIndex的创建工作在后台完成。
将元组作为键的字典传给Pandas对象,会默认转换为MultiIndex:

-
显式创建多级索引
可以通过一个有不同等级的若干简单数组组成的列表来构建MultiIndex:

也可以通过包含多个索引值的元组构成的列表创建MultiIndex:

还可以用两个索引的笛卡尔积创建MultiIndex:

还可以直接提供levels和labels值来创建MultiIndex:

创建Series或DataFrame时,可以将这些对象作为Index的参数或通过reindex方法更新Series或DataFrame的索引。
- 多级索引的等级名称
为不同等级的索引加上名称会为一些操作提供便利,处理复杂数据时,给不同的索引等级设置名称,是管理多个索引值的好办法:

-
多级列索引
之前介绍了多级行索引,同理也会有多级列索引:

上例创建了一个多级行列索引,一个四维数据,四个维度分别为被检查人姓名、检查项目、检查年份和检查次数。
可以在列索引的第一级查询姓名,从而包含这个人全部检查信息的DataFrame:

3.多级索引的取值和切片
- Series多级索引
可以通过多个级别的索引值获取单个元素:

多级索引局部取值,即只取索引的某个层级,返回结果是一个新的Series:

局部切片,不过要求MultiIndex是按顺序排列的:

之前索引没有按字典顺序排序,所以报错,可以排列索引后,再使用切片:

如果索引已经排序,那么可以使用较低层级的索引取值,第一层级用空切片:

其他取值和数据选择方法在这都适用,如通过布尔掩码选择数据:

也可以使用花哨的索引:

-
DataFrame多级索引
用体检数据进行演示:

DataFrame的基本索引是列索引(默认):

多级索引与单索引一样,可以使用索引器iloc,loc,ix:

loc和iloc可以传递多级索引的索引元组,把多维数据当作二维数据处理:

不过在元组中使用切片会导致语法错误,可以用slice函数获取想要的切片:

4.多级索引行列互换
- 有序索引和无序索引
MultiIndex不是有序的索引,大多数切片操作会失败:

对索引进行局部切片会报错:

问题在于索引没有按序排列,接下来对索引按字典序排列:

-
索引stack与unstack
之前提到过,我们可以把一个2级索引的Series,转换为简单的2维形式:

stack()和unstack()互为逆操作,同时使用数据保持不变:

-
索引的设置与重置
层级数据维度转换的另一种方法是行列标签转换,可以通过reset_index()实现。
对人口数据Series使用该方法,会生成一个列标签中包含之前行索引标签city和year的DataFrame。

如果能将上述类似的原始输入DataFrame数据的列直接转成MultiIndex,通常很有用(对原始数据集重建索引)。
可以通过set_index()方法,返回一个带多级索引的DataFrame:

5.多级索引的数据累计方法
对于层级索引数据,可以设置参数level实现对数据子集的聚合操作:

再增加axis参数,就能对列索引进行聚合操作了:

七、合并数据集:Concat与Append操作
定义一个能够创建DataFrame的函数:

1.NumPy数组合并

2.通过pd.concat实现简易合并

和合并数组一样,pd.concat()可以简单的合并一维Series或DataFrame对象:

也可以用来合并高维数据:

默认情况下,DataFrame的合并都是逐行进行的(axis=0),也可以沿x轴方向合并:

-
索引重复
p d.concat与np.concatenate最大的差异是,Pandas在合并时会保留索引,即使索引是重复的:

捕捉索引重复的错误:

合并时忽略索引,合并后会重新创建一个新的整数索引:

增加多级索引:

-
类似join的合并
合并的两部分的列名不完全相同,缺失部分会补NaN:


直接确定结果使用的列名:

- append()方法
df1.append(df2)等价于pd.concat([df1,df2]),只不过append只能沿y轴方向逐行合并,没有axis参数。

八、合并数据集:合并与连接
1.关系代数
2.数据连接的类型
3.设置数据合并的键
4.设置数据连接的集合操作规则
5.重复列名:suffixes参数
6.案例:美国各州统计数据
九、累计与分组
1.行星数据
2.Pandas的简单累计功能
3.GroupBy:分割、应用和组合
十、数据透视表
1.演示数据透视表
2.手工制作数据透视表
3.数据透视表语法
4.案例:美国人的生日
十一、向量化字符串操作
1.Pandas字符串操作简介
2.Pandas字符串方法列表
3.案例:食谱数据集
十二、处理时间序列
1.Python的日期与时间工具
2.Pandas时间序列:用时间作索引
3.Pandas时间序列数据结构
4.时间频率与偏移量
5.重新取样、迁移和窗口
6.更多学习资料
7.案例:美国西雅图自行车统计数据的可视化
十三、高性能Pandas:eval()与query()
1.query()和eval()的设计动机:复合代数式
2.用pandas.eval()实现高性能运算
3.用DataFrame.eval()实现列间运算
4.DataFrame.query()方法
5.性能决定使用时机