【GAN图像生成】使用GAN(生成对抗网络)进行图像生成
文章目录
1. 前言
主要使用 DCGAN 模型,在自建数据集上进行实验。本项目使用的数据集是裂缝数据:彩色裂缝图像(三通道)、黑白裂缝图像(单通道)。
2. 先验知识
生成器和判别器用到的:有关卷积和逆卷积的知识。
nn.Conv2d与nn.ConvTranspose2d参数理解
nn.ConvTransposed2d()函数
nn.Conv2d()函数
3. 项目框架
说明:1代表的是针对彩色数据,2代表的是针对黑白图像。
-
这里以1为例,(三通道数据)进行说明:
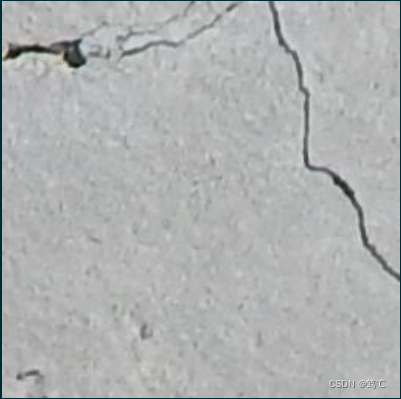
data1文件夹下的只有一个crack文件夹,而crack下保存的是原始的裂缝数据,这些裂缝数据由于是自建的,所以不太充足。因此需要进行传统方法扩充,进而进行深度扩充。经过传统扩充之后,得到data1_aug文件夹下的crack保存着扩充后的数据。
而aug1.py是针对data1的传统增广代码,gan1.py则是针对data1_aug的深度生成代码。 -
2的说明同1,只不过是黑白图像,也就是单通道。

4. 数据扩充
- 针对1(三通道裂缝图像)aug1.py
import skimage
import io,os
import matplotlib.pyplot as plt
from PIL import Image,ImageEnhance
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 彩色裂缝数据传统扩充
# 旋转
def rotation(img, angle):
img = Image.open(os.path.join(root_path, img_name))
rotation_img = img.rotate(angle) #旋转角度
return rotation_img
# 颜色变化
def randomColor(img): #随机颜色
random_factor = np.random.randint(9, 20) / 10. # 随机因子
result = ImageEnhance.Contrast(img).enhance(random_factor) # 调整图像对比度
random_factor = np.random.randint(0, 51) / 10. # 随机因子
result = ImageEnhance.Sharpness(result).enhance(random_factor) # 调整图像锐度
return result
#root_path为图像根目录,img_name为图像名字
root_path = 'data1/crack'
img_name = '1.jpg'
save_dir = 'data1_aug/crack/'
files_list = os.listdir(root_path)
begin = 0
angles = [0, 90, 180, 270]
for img_name in files_list:
cnt = begin
img = Image.open(os.path.join(root_path, img_name))
img = img.convert('L')
for angle in angles:
img1 = rotation(img, angle)
for _ in range(0, 8):
cnt += 1
img2 = randomColor(img1)
img2.save(save_dir+img_name+str(cnt)+'.jpg')
# img = Image.open(os.path.join(root_path, img_name))
# img = img.convert('1')
# plt.figure(figsize=(8,8))
# plt.imshow(img)
- 针对2(单通道裂缝图像)aug2.py
import skimage
import io,os
import matplotlib.pyplot as plt
from PIL import Image, ImageEnhance
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 黑白裂缝数据传统扩充
# 旋转
def rotation(img, angle):
img = Image.open(os.path.join(root_path, img_name))
rotation_img = img.rotate(angle)
return rotation_img
# 交叉、组合
def merge(img1, img2):
img1 = np.array(img1)
img2 = np.array(img2)
img = np.ones_like(img1)
img *= 255
img[img1 < 100] = 0
img[img2 < 100] = 0
img = Image.fromarray(img)
return img
root_path = 'data2/crack'
img_name = '1.jpg'
save_dir = 'data2_aug/crack/'
files_list = os.listdir(root_path)
begin = 0
angles = [0, 90, 180, 270]
n = len(files_list)
for img_name in files_list:
cnt = begin
img = Image.open(os.path.join(root_path, img_name))
img = img.convert('L')
for angle in angles:
img1 = rotation(img, angle)
cnt += 1
img1.save(save_dir+img_name+str(cnt)+'.jpg')
for _ in range(0, 1):
ind = np.random.randint(0, n)
img2 = Image.open(os.path.join(root_path, files_list[ind]))
img2 = img2.convert('L')
img = merge(img1, img2)
cnt += 1
img.save(save_dir+img_name+str(cnt)+'.jpg')
5. 准备操作、数据读入
-
- 导入包,及参数定义
from __future__ import print_function
#%matplotlib inline
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
# 设置一个随机种子,方便进行可重复性实验
manualSeed = 999
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
# 数据集所在路径,二选一
dataroot = "data1_aug/" # 三通道
# dataroot = "data2_aug/" # 单通道
# 数据加载的进程数
workers = 0
# Batch size 大小
batch_size = 128
# Spatial size of training images. All images will be resized to this
# size using a transformer.
# 图片大小
image_size = 128
# 图片的通道数
nc = 3
# Size of z latent vector (i.e. size of generator input)
nz = 100
# Size of feature maps in generator
ngf = 32
# Size of feature maps in discriminator
ndf = 32
# Number of training epochs
num_epochs = 301
# Learning rate for optimizers
lr = 0.0003
# Beta1 hyperparam for Adam optimizers
beta1 = 0.5
# Number of GPUs available. Use 0 for CPU mode.
ngpu = 1
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
print(device)
- 2.1 针对三通道(2.1和2.2二选一,一般都是三通道2.1,彩色图像)
# Create the dataset for 3 chanels
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
- 2.2 针对单通道
# Create the dataset for 1 chanels
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Grayscale(num_output_channels=1),
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5), (0.5)),
]))
-
- dataloader,工具函数
# Create the dataloader
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)
# 权重初始化函数,为生成器和判别器模型初始化
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
6. 生成器(G)
# Generator Code
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d(nz, ngf * 16, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 16),
nn.ReLU(True),
# state size. (ngf*16) x 4 x 4
nn.ConvTranspose2d(ngf * 16, ngf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 8 x 8
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 16 x 16
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 32 x 32
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 64 x 64
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 128 x 128
)
def forward(self, input):
return self.main(input)
7. 判别器(D)
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is (nc) x 128 x 128
# k s p
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 64 x 64
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 32 x 32
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 16 x 16
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 8 x 8
nn.Conv2d(ndf * 8, ndf * 16, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 16),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*16) x 4 x 4
nn.Conv2d(ndf * 16, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
8. 经过过程
# Create the generator
netG = Generator(ngpu).to(device)
# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netG.apply(weights_init)
# Create the Discriminator
netD = Discriminator(ngpu).to(device)
# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):
netD = nn.DataParallel(netD, list(range(ngpu)))
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netD.apply(weights_init)
# Print the model
# print(netD)
# Initialize BCELoss function
criterion = nn.BCELoss()
# Create batch of latent vectors that we will use to visualize
# the progression of the generator
fixed_noise = torch.randn(128, nz, 1, 1, device=device)
# Establish convention for real and fake labels during training
real_label = 1.0
fake_label = 0.0
# Setup Adam optimizers for both G and D
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
# Lists to keep track of progress
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
for epoch in range(num_epochs):
import time
start = time.time()
# For each batch in the dataloader
for i, data in enumerate(dataloader, 0):
# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))+++++++++++++++++++
## Train with all-real batch------------------
netD.zero_grad()
# Format batch
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, device=device)
# Forward pass real batch through D
output = netD(real_cpu).view(-1)
# Calculate loss on all-real batch
errD_real = criterion(output, label)
# Calculate gradients for D in backward pass
errD_real.backward()
D_x = output.mean().item()
## Train with all-fake batch-------------------
# Generate batch of latent vectors
noise = torch.randn(b_size, nz, 1, 1, device=device)
# Generate fake image batch with G
fake = netG(noise)
label.fill_(fake_label)
# Classify all fake batch with D
output = netD(fake.detach()).view(-1)
# Calculate D's loss on the all-fake batch
errD_fake = criterion(output, label)
# Calculate the gradients for this batch
errD_fake.backward()
D_G_z1 = output.mean().item()
# Add the gradients from the all-real and all-fake batches
errD = errD_real + errD_fake
# Update D
optimizerD.step()
# (2) Update G network: maximize log(D(G(z)))++++++++++++++++++++++++++++++++++
netG.zero_grad()
label.fill_(real_label) # fake labels are real for generator cost
# Since we just updated D, perform another forward pass of all-fake batch through D
output = netD(fake).view(-1)
# Calculate G's loss based on this output
errG = criterion(output, label)
# Calculate gradients for G
errG.backward()
D_G_z2 = output.mean().item()
# Update G
optimizerG.step()
# Output training stats
if epoch%1 == 0 and i == len(dataloader)-1:
print('time:', time.time() - start, end='')
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# Save Losses for plotting later
G_losses.append(errG.item())
D_losses.append(errD.item())
# Check how the generator is doing by saving G's output on fixed_noise
if epoch%1 == 0 and i == len(dataloader) - 1:
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
i = vutils.make_grid(fake, padding=2, normalize=True)
fig = plt.figure(figsize=(8, 8))
plt.imshow(np.transpose(i, (1, 2, 0)))
plt.axis('off') # 关闭坐标轴
plt.savefig("out_1/%d_%d.jpg" % (epoch, iters))
plt.close(fig)
iters += 1
9. 最终效果
- 三通道,彩色的效果保存在out1中

不断变清晰,效果明显。

- 单通道,黑白的效果保存在out2中

